

Составление имитаторов «сервисных» функций
Установка исходных данных. Для того чтобы каждая серия экспериментов проводилась при одинаковых и соответствующих объекту данных, в алгоритме необходимо предусмотреть блоки присвоения начальных значений переменным, например:
ti=0; tiосв=0; ti=0; tiож=0.
Сбор и обработка статистических данных. В системах обслуживания, как правило, необходимо определить случайную величину ( математическое ожидание), поэтому для ее поиска используется арифметические устройства статистической обработки данных в виде вычислителя математического ожидания случайной величины
![]() ,
,
где xi-значение случайной величины, полученное в i-м эксперименте;
n-число проведенных экспериментов.
Помимо математического ожидания определяется дисперсия случайной величины. Для этого необходим вычислитель дисперсии
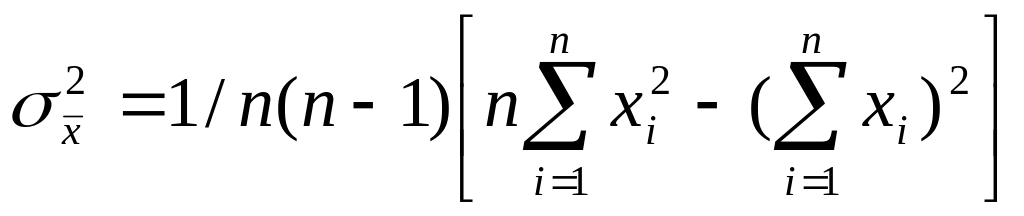 .
.
Следовательно, для сбора и обработки статистических данных необходимы сумматоры xi , сумматоры xi2, вычислители средних значений случайной величины и дисперсии случайной величины.
Проведение эксперимента. Для того чтобы получить статистически устойчивые данные, необходимо провести требуемое число экспериментов. Существуют три различных подхода для определения требуемого числа эксперимента.
1. Эксперимент считается законченным, если истекло модельное время T (tiT). Модельное время Т обычно задается при выборе оценок цели моделирования в виде времени, за которое определяется характеристика.
2. Эксперимент заканчивается, если выполнено требуемое число прогонов, при проведении которых погрешность результатов эксперимента не превышает заданное значение .
3. Число экспериментов определяется автоматически. Эксперимент заканчивается, если дисперсия искомой характеристики не превышает заданное значение.
Определение требуемого числа прогонов эксперимента
Если ранее не определенно число экспериментов, то ведется специальный расчет. Для этого используется два подхода.
1. Эмпирический подход используется, если искомая случайная величина не подчиняется нормальному закону распределения. Тогда на основе теории больших чисел для получения погрешности необходимо проводить по каждой характеристике не менее 30 прогонов.
2. Если случайная характеристика подчиняется нормальному закону распределения, то используются специальные распределения (t-распределение и 2-распределение) для нахождения требуемого числа прогонов, обеспечивающих заданную погрешность результатов.
Допустим, определяется случайная характеристика æ с допустимой погрешностью .
Пусть æ- математическое ожидание искомой случайной характеристики. Из математической статистики известно, что погрешность оценки мат. ожидания связана с t-распределением (Стьюдента) следующим соотношением
![]() ,
,
где t-случайная величина, подчиняющаяся t-распределению, задана таблично;
x-среднеквадратичное
отклонение, которое обычно задано или
определяется из полученного статистического
ряда по формуле
![]() ;
;
N-число прогонов.
Величина t определяется из таблицы по числу степеней свободы =N-1 и уровень доверия q=1-p/2, где p-доверительная вероятность.
Искомое число
прогонов определяется по формуле:
![]() .
.
Если в качестве æ выбирается дисперсия искомой случайной характеристики, то требуемое число прогонов вычисляется следующим образом. По известным из математической статистики формулам записывается выражение.
![]() ,
,
где
![]() -
погрешность
оценки дисперсии;
-
погрешность
оценки дисперсии;
![]() -случайная
величина, подчиняющаяся
-случайная
величина, подчиняющаяся
![]() -распределению
(Пирсона), задана таблично. Для выбора
из таблицы значения
необходимо
задать число степеней свободы =N-1
и два уровня доверия 1=1-p/2
и 2=1+p/2.
Далее по формуле находится такая степень
свободы ,
при которой
-распределению
(Пирсона), задана таблично. Для выбора
из таблицы значения
необходимо
задать число степеней свободы =N-1
и два уровня доверия 1=1-p/2
и 2=1+p/2.
Далее по формуле находится такая степень
свободы ,
при которой
![]() .
.
Требуемое число прогонов, при котором дисперсия будет определена с погрешностью меньше , вычисляется по формуле Nпр=+1.