

Лабораторная работа №2
Использование структур данных, представленных бинарными деревьями, при проектировании программ
Цель работы: приобретение навыков использования структур данных, представленных бинарными деревьями, при проектировании программ.
Краткие теоретические сведения
Дерево – конечное множество T, состоящее из одного или более узлов, таких, что:
а) имеется один специально обозначенный узел, называемый корнем данного дерева;
б) остальные узлы (исключая корень) содержатся в m>=0 попарно не пересекающихся множествах T1,T2,…,Tm , каждое из которых в свою очередь является деревом. Деревья T1,T2,…,Tm называются поддеревьями данного дерева.
Наиболее важным типом деревьев являются бинарные деревья.
Бинарное дерево (БД) – конечное множество узлов, которое либо пусто, либо состоит из двух непересекающихся бинарных деревьев, называемых правым поддеревом и левым поддеревом. Среди БД наиболее известно дерево, упорядочивающее набор чисел (ключей). Кроме ключа, в узле БД возможны и другие данные, т.е. узел – это запись. Рассмотрим бинарное дерево (рис. 1).






 1-й ярус
1-й ярус









 2-й ярус
2-й ярус






 последний, h-й
ярус (h=3)
последний, h-й
ярус (h=3)

сюда будет включена запись “12”
Рис 1. Бинарное дерево.
В нем для каждого узла X выполняется правило: в левом поддереве ключи, меньшие X, в правом – большие или равные X. Указанные неравенства не только устанавливают порядок сыновей, но и вовлекают в него отца, т.е. на рис.1 приведено всецело упорядоченное БД (БДУ).
БДУ используют как динамическую структуру, включая в него записи и исключая их по ходу использования БДУ. Ключ новой записи сравнивается с корнем и по результату сравнения направляется в левое или правое поддерево, где сравнивается с его корневым узлом и т.д. Проходится некоторая трасса, пока новая запись не будет направлена в пустое поддерево, где и занимает место его корня. На рис.1 показано, что новая запись «12» сравнивается с «22», «10», «14» и становится левым поддеревом узла «14».
От очередности включения узлов зависит форма дерева. Например, если начнем построение БД с ключа «45», а прочие ключи будем брать в порядке не возрастания, БДУ примет форму цепи, заканчивающейся листом «3».
Форма БД. Пусть h-высота БД. Выровненное БД – это БД, в которм не иметь сыновей (одного или обоих) позволительно лишь узлам h-го и (h-1)-го ярусов (см. рис.1). Другими словами, в нем заполнены все ярусы, кроме, возможно последнего. Дерево называют полным, если все узлы 1..h-1 ярусов имеют и левого и правого сына. В полном дереве точно (2h+1 – 1) узлов, поэтому больший практический смысл имеют выровненные сбалансированные) деревья; полное – частный случай.
Среднее число действий при включении (исключении), а также поиска узла в выровненном дереве определяется величиной log n, т.е. относительно невелико.
Следствием упорядоченности БДУ является существование правил обхода узлов – способа «методичного» исследования узлов узлов дерева, при котором каждый узел исследуется (обрабатывается) точно один раз. Выделяют несколько стандартных вариантов обхода. Их именуют в зависимости от того порядка, в котором посещаются (исследуются) корень дерева и узлы левого и правого поддеревьев. Например, при КЛП - обходе сначала посещается корень, затем обходятся в КЛП - порядке последовательно левое и правое поддеревья. Такой принцип обхода называют еще прямым. В нашем примере КЛП - обход дает последовательность ключей
22,10,3,5,14,19,45,31,45.
Принцип концевого обхода (ЛПК - обхода) БДУ «сначала левое поддерево, потом правое, затем корень» дает в нашем примере последовательность
5,3,19,10,31,45,45,22.
Принцип обратного обхода (ЛКП - обхода) «сначала левое поддерево, затем - корень и правое поддерево» также применяется в каждом узле БДУ, поэтому, чтобы взять левое поддерево корня, надо сначала взять левое поддерево левого сына, а в нем – следующее меньшее левое поддерево и т.д., вплоть до «левейшего» поддерева, хотя бы листа. Этот лист (или узел, имеющий лишь правого сына) и будет первым в обходе дерева. Далее попадая в его правое поддерево (если есть), делаем то же самое (рекурсия).
Обнаружением пустой ссылки на правого сына завершается обход одного или нескольких поддеревьев; в этот момент мы должны обрабатывать узел, левым поддеревом которого является вся пройденная часть и войти в правое поддерево этого узла. Обход слева (обратный обход) можно описать без явной рекурсии:
Взять «левейший» узел, используя для достижения узла путь от корня дерева, проходящий лишь через левых сыновей.
Обработать узел (некоторым образом использовать).
Перейти к правому сыну (если есть), а затем – к левейшему его потомку (если имеется).
Если переход к первому сыну (п.3) состоялся, вновь перейти к п.2, иначе к п.5.
Вернуться к узлу, левым поддеревом которого является обработанная часть дерева.
Если узла, указанного в п.5 нет, закончить обход, т.к. все дерево пройдено, иначе перейти к п.2.
Примечание: при обратном (или ЛКП) обходе можно обработать записи в неубывающей последовательности их ключей.
При использовании данного алгоритма работы с БДУ возможно несколько вариантов организации программы. Рассмотрим вариант с запоминанием ссылок на узлы, упомянутые в п.5. алгоритма, в стеке. В этом случае перед переходом от отца к левому сыну ссылка на отца запоминается. После использования ссылки в п.5, она «выталкивается» из стека, освобождая память, которая впоследствии может быть заняты другими ссылками.
Пример1.
Процедура обхода бинарного дерева-списка слева (ЛКП - обход).
Тип pt ссылок на элементы БДУ должен быть описан следующим образом:
Type pt=^uzl; uzl=Record lson, rson:pt; kl:byte End;
здесь uzl - тип узла БДУ, содержащего ссылку lsоn на левого и rson – на правого сына, ключ kl и, возможно, иные данные (тогда нужно добавить поля в тип uzl).
Блок обход (Obhod) имеет один параметр ss, который задают как ссылку на корень БДУ. Пользователь описывает применение данных каждого узла в блоке Obrab. Для проверки блока Obhod используем блок, имитирующий обработку (см. файл Prim_5.pas).
В неупорядоченном БД порядка в частных множествах узлов нет, т. е. сыновья узла не различаются как “ левый “ и “ правый “. Если используется принцип “ сын не больше отца “, в корне БД находится наибольший ключ и на всех трассах, идущих к листьям, значения ключа не возрастают. Для таких БД обычно используют представление в виде массива с формулой доступа, позволяющей проходить трассы. Его называют обычно поясной проекцией БД. Линейные представления (и обходы) требуют упорядоченности БД, поэтому в проекции какой-то сын узла искусственно становится левым, а другой – правым. БД должно быть выровненным, причем в последнем ярусе могут быть не заполненными только правые позиции, иначе в проекции возникнут “пустоты “.
Представлением дерева














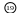



является проекция : 45 ; 45 14 – 1 ярус ; 22 31 10 5 - 2 ярус ; 19 3 12 – 3 ярус
1 2 3 4 5 6 7 8 9 10
Формула доступа: один сын занимает позицию 2j, другой – позицию 2j + 1, где j – номер позиции их отца.
Зная содержание БД, мы с помощью формулы доступа можем заполнить проекцию; если надо построить БД, имея “ хаотический “ исходный массив, также прибегают к формуле. Рассмотрим более простые процессы включения записи в БД и исключения записи из БД. Необходимо иметь резерв позиций в конце массива – проекции. Допустим в наше БД включается запись с ключом “39”. Заносим ее в первую свободную позицию и он автоматически становится сыном узла “31”. Принцип нарушен: сын больше отца. Поменяем местами сына и отца. Теперь новая запись стала сыном “45”; здесь порядок не нарушен. В общем случае может быть не один обмен; в итоге новая запись может оказаться и в корне БД.
При исключении больший сын исключаемой записи занимает ее позицию, в свою очередь его больший сын становится на его место и т. д. Вплоть до листа. Возникает проблема с положением последней освободившейся позиции. Если попытаться, например, исключить “22” из нашего БД – в его проекции возникнет “дырка” на месте “19”. Решение: временно замещаем исключаемую запись последним элементом проекции (“12”), который сравниваем с новым ее отцом “45”. Если здесь порядок нарушается, поступаем, как при включении, иначе сравниваем “12” с большим из “приемных детей” (“19”), если сравнение не в пользу отца (у нас именно так), производим обмен, снова сравниваем “12” с большим из сыновей и т. д. (в нашем примере дерева сравнивать ключ “12” уже не с чем , ибо ключ “19” не имеет сыновей).
Чаще всего исключение производят только в корне БД (см. пример 2), а это сравнительно простая ситуация.
Пример 2.
Взятие из БД, в котором n узлов , k наибольших элементов с одновременным исключением из БД.
Программную реализацию данного примера см. в файле Prim_6.pas.
Неупорядоченное БД имеет ряд очень полезных применений. В литературе такое БД называют сортдеревом, деревом Флойда.
Рассмотрим теперь сортлес, образованный сортдеревьями. В одном массиве можно совместить проекции S сортдеревьев: сначала размещаем S корней деревьев, затем – всех “детей” в том порядке , в котором записаны корни , потом – всех “внуков” , соблюдая тот же порядок , и т.д. Нетрудно проверить , что дети отца i занимают в этом массиве позиции 2i + S – 1 , 2i + S.
Преимуществом такого размещения является относительная равномерность распределения элементов-узлов по нескольким сортдеревьям. Данный вариант сортлеса применяется достаточно широко при построении алгоритмов сортировки данных в памяти ЭВМ.