

Дерево вывода.
Выводам контекстно-свободной грамматики соответствуют деревья разбора (derivation tree, parse tree) – это некоторые упорядоченные деревья, вершины которых помечены символами алфавита или нетерминального, или терминального множества, корень дерева – начальный символ. Каждому символу некоторого W1, на который заменяется начальный символ на первом шаге вывода, ставится в соответствующую вершину дерева, и к ней приводится дуга из корня. Полученные таким образом потомки корня упорядочены. Например:
<Пр>

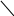
<П> <с>
| |
<ис> <ГФ>
| |
кот лежит
Если хотя бы одна сентенциальная форма имеет более одного синтаксического дерева, то грамматику называют неоднозначной.
Задача разбора
Это задача, обратная задаче вывода. Преобразование строки языка обратное порождению, в терминологии формальной грамматики называют приведением (сведение или редукция строки).
Например: В грамматике строка «кот лежит» прямо приводима к строке <ис>лежит… и в конце концов она приводима к <Пр>.
Основная задача разбора – это вывод, но прослеженный в обратном порядке, на базе готовой формальной грамматики.
Таким образом, основная задача синтаксического анализа состоит в отыскании разбора или вывода для заданного предложения входного языка. Если разбор или вывод существует, то предложение синтаксически правильное и является сентенциальной формой, его разбор выдает специфическую структуру – синтаксическое дерево, и в прикладной лингвистике используют два основных вид дерева: дерево непосредственно составляющих и дерево зависимостей.
По существу, термины «синтаксический анализ», «задача разбора» и «задача распознавания входной строки» это синонимы, а алгоритмы, решающие такие задачи, называются анализатором или распознавателем.
Стратегии синтаксического анализа
Существует две основных стратегии синтаксического анализа:
нисходящая (top-down), когда для данного предложения, исходя из начального символа грамматики, строят вывод;
восходящая, когда данного предложения, исходя из символов самого предложения (терминалов), строят разбор.
Таким образом, различают нисходящие и восходящие анализаторы.
Для того, чтобы представить, как это работает технически, на базе нашего примера рассмотрим как работает нисходящий анализ. Для этого нашу грамматику заменим сокращенной эквивалентной грамматикой типа 3:
<Пр>→кот<с>
<Пр>→пес<с>
<Пр>→он<с>
<с>→идет
<с>→лежит
Распознавание сентенциальной формы в нашем языке можно выполнить алгоритмом, который реализуется конечным автоматом, а распознаватель для нашего языка с конечным числом состояний можно представит в виде таблицы с двумя входами, которая представляет собой специфическую запись набора порождающих правил, причем число строк состояний таблицы равно числу нетерминальных символов, а число столбцов – числу терминальных символов грамматики. Исходное состояние – начальный символ грамматики. В клетках таблицы записаны следующие состояния для данной пары входов, пустые клетки – ошибки.
Входной
с
состояние |
кот |
пес |
он |
идет |
лежит |
<Пр> |
<с> |
<с> |
<с> |
|
|
<с> |
|
|
|
+ |
+ |
 имвол
имвол
Отличительная черта нисходящего анализа – это целенаправленность. На каждом шаге анализа нисходящие распознаватели формируют цель – найти вывод, начинающийся с некоторого нетерминального символа и порождающий часть входной строки. Распознаватель пытается достичь этой цели путем направленного перебора различных возможностей. Основная идея нисходящего анализа в следующем: начиная процесс анализа входной строки S1, S2…,Sn, распознаватель исходит из предположения, что эта строка является предложением входного языка. Отсюда вытекает главная цель анализа – найти вывод (построить дерево)
S S1, S2…,Sn S – начальный символ
Если существует такой вывод, то существуют и промежуточные порождающие правила, но для каждого нетерминального символа в грамматике может быть несколько правил с разными правыми частями и какое именно правило следует применить, заранее не известно. При неудачном выборе правила, вспомогательная цель может оказаться недостижимой, тогда нужно попытаться применить другое правило. Возможны случаи, когда для какой-либо вспомогательной цели все правила приводят к неудаче. Описание процесса завершается, когда найден конечный вывод (цепочка) или когда установлено, что этого вывода не существует, т.е. входная строка не является предложением этого языка. Обычно нисходящий распознаватель просматривает символа входящей строки и символы правой части применяя правило «слева – направо». Такие распознаватели называют левосторонними. (Например БНФ)
В памяти машины правила формальной грамматики могут храниться в виде синтаксических таблиц. Пусть требуется найти вывод для предложения «Он идет» и построить синтаксическое дерево. В качестве главной цели выбираем начальный символ формальной грамматики <Пр> . первая наша вспомогательная цель – это первый символ правой части правила (<П>), вторая вспомогательная цель - <ис>. Непосредственная проверка показывает, что вспомогательная цель «он» недостижима через <ис>, поэтому вместо <ис> выбирают новую вспомогательную цель - <М>…
<Пр>
<П> <с>

<М> <ГФ>
| |
он идет
Соответственно строится вторая ветка.
Трансляторы широко применяют комбинацию нисходящих и восходящих методов синтаксического анализа. Например, нисходящий анализ выделяет относительно крупные синтаксические конструкции (различные описания, операторы), каждый из которых затем анализируется подробнее методами восходящего анализа.
Восходящий анализ
Методы восходящего анализа нашли широкое применение в действующих трансляторах. Общая идея восходящего анализа состоит в следующем: входная программа рассматривается как строка символов, распознаватель описывает часть строки, которую можно свести к нетерминальному символу, такую часть строки называют фразой. Фразу, прямо приводимую к нетерминальному символу, называют непосредственно приводимой. В большинстве восходящих распознавателях отыскивается самая левая непосредственно приводимая фраза, называемая основой. Основа заменяется нетерминальным символом, во вновь полученной строке опять отыскивается основа, которая также заменяется нетерминальным символом и т.д. процесс продолжается либо до получения начального символа, либо до установления невозможности приведения строки к начальному символу. Последовательность промежуточных строк, которая заканчивается начальным символом образует разбор. Если строка не приводима к начальному символу, то входная программа синтаксически некорректна, т.е. не является формой этого языка.
Пусть требуется определить принадлежность нашему языку следующие формы: «он кот». Для этой строки в нашей грамматике фразами являются «он» и «кот», причем «он» - это основа. Приведение он→ <М> дает строку <М> и <кот>, причем основа → <М>:
он→<М>
<
 М>
кот, <П><кот>, <П><ис>, <П><П>
- некорректно.
М>
кот, <П><кот>, <П><ис>, <П><П>
- некорректно.
Автоматическое индексирование. Автоматическое аннотирование и реферирование. Автоматическая классификация документов. Пример программ автоматического реферирования, принцип работы. Модели, Методы и программы реферирования.
Автоматическое аннотирование и реферирование (summarization)
Реферирование подразделяют на несколько категорий в зависимости от целей составления реферата:
- повествовательный реферат (формируется по классическому способу извлечения информации и имеет достаточный объем);
- информативный реферат (главная цель - выборка основной информации из текста, объем 5 - 30% от исходного текста. сюда же относится аннотация: 1 - 5% исходной информации);
- критический реферат (предполагает сокращение информации и выражает определенное мнение об этой информации. например, в виде критического обзора статьи).
Основные методы систем автоматического реферирования базируются на трех основных этапах работы:
1. анализ исходного текста (на базе статистики)
2. определение его характерных фрагментов
3. формирование статистического метода по тексту.
При этом существует два основных метода реферирования
a) метод "составления выдержек", который основывается на линейной модели представления текста и предполагает выделение характерных фрагментов текста для определения темы и ключевых понятий данного текста. Таким образом, создание итогового документа - это сборка выбранных фрагментов.
Лингвистическая модель для этого метода на модели лингвистических весовых коэффициентов. При этом используется процедура незнания весовых коэффициентов для каждого слова, предложения или блока текста. В соответствии с такими характеристиками, как расположение этого объекта в оригинале, частота появления в тексте соответствующих ключевых слов, показатели статистической значимости тех или иных ключевых конструкций. При этом весовой коэффициент - это численное значение, определяемое значимостью ключевых слов документа.
Основным недостатком этого метода являются так называемые "висячие слова": при реферировании происходит выборка предложений и их сборка в виде реферата в основном на базе частотности, соответственно возможна ситуация семантических пропусков.
b) метод формирования краткого изложения. Считается экспериментальным, т.е. в коммерческих системах он полностью не реализован. Более сложный, чем а), т.к. опирается на лингвистические значения (традиционные методы синтаксического разбора предложения и специальные структуры, моделирующие семантику текста).
Программы автоматического реферирования и технологии, лежащие в основе свертывания информации
Принцип работы большинства программ заключается в автоматическом определении ключевых слов (индексировании) и поиске фрагментов в тексте, содержащих данные слова. Затем происходит автоматическая выборка ключевых предложений и их объединение либо компилятивно, либо по смыслу, либо с помощью человека.
Большинство систем реферирования основано на представлении текста в виде семантических сетей, т.е. в виде списка понятий, слов или словосочетаний, связанных между собой каким-либо отношением. Узлами сети становятся наиболее частотные слова и для каждого из них программа формирует множество смыслов или ассоциативных связей, т.е. список других понятий, в сочетании с которыми данное слово встречается в тексте. Считается, что чем чаще встречается 2 понятия в тексте вместе, тем больше вероятность того, что они связаны по смыслу и являются словосочетанием.
Кроме того, из числа понятий семантической сети сразу исключаются общеупотребительные слова (стоп-слова). Понятие связи сети ранжируется "по весам", которые отражают степень значимости понятия в тексте и степень их смысловой связи друг с другом. Статистические данные о связи понятий и их распределение в тексте позволяет оценить вклад этих понятий в общее содержание текста и расставить темы согласно их информативности.
Обычно каждой теме сети также соответствует собственный тематический вес и максимально информативная тема имеет вес равный 100. по каждой из тем сети формируется набор связанных фрагментов текста, т.е. цитат, соответствующих данной теме. Таким образом формируется общий реферат или резюме текста.
Такие интеллектуальные системы реферирования и аннотирования (например, TextAnalyst) кроме семантических сетей по тексту позволяют получить специальное представление текста в виде его тематической структуры. То есть система автоматического реферирования документов позволяет получить данные о семантике текста и может быть использовано для автоматической обработки текста, для моделирования текстов ЕЯ и т.д. (в частности это активно используется для классификации и кластеризации данных).
Коммерческие системы реферирования
Российские: Аннотатор/Libretto (Медиа-Лингва), Russian-Context-Optimizer (Grand-Park-Internet), TextAnalyst (Microsystems - www.textanalyst.ru);
Зарубежные: Intelligent Text Miner (IBM), Context (Oracle) и др.
Например, TextAnalyst позволяет не только получить рефераты текстов, но и проводить их интеллектуальный анализ, например, для создания статистического тезауруса, для изучения терминологии, для поиска цитат и их подборки, для выборки авторских мыслей и обнаружении семантических несоответствий в тексте для анализа текстов и их фильтрации на основе эталонных семантических сетей.
Классификация и кластеризация текстов (Техt clustering/classification)
Классификация (syn: рубрикация) - отнесение каждого документа в определенный класс с заранее известными параметрами, полученными на этапе так называемого обучения. Число классов при этом строго ограниченно (обычно задается в виде тематических рубрик, топиков)
Кластеризация - разбиение множества документов на кластеры (рубрики), т.е. такие подмножества, параметры которых заранее не известны.
Методы автоматической классификации
Для автоматической классификации документов хорошо зарекомендовали себя три следующих метода:
Метод рубрикации на основе семантических образов рубрик.
Два метода основанных на дефинициях (1. метод рубрицирования по дефинициям и 2. метод расширенных дефиниций) наиболее простые, их применяют в первую очередь чтобы отсортировать максимально быстро большую часть документов. Суть метода заключается в следующем: метод похож на словарную статью в толковых словарях, т.к. многие тексты часто дают определение основных терминов уже во введении. (Тезаурус - это идеографический словарь…)
Методика состоит в том, что в документе выдается и анализируется основное понятие документа как на базе статистики, так и на базе его определения.
Метод семантических образов рубрик (самый популярный) позволяет более качественно классифицировать статьи любого содержания и размера. Семантический образ - это совокупность ключевых слов и словосочетаний с указанными для них определенными параметрами. Семантический образ документа создается вручную или с использованием статистических программ. Семантические образы рубрик также являются основой для дальнейшего разнесения обрабатываемых текстов по рубрикам.
Иногда списка ключевых слов недостаточно для рубрицирования. Ключевое слово может быть характерно только для одной рубрики, т.е. его вес равен 100, но чаще ключевое слово может входить в образы нескольких рубрик, тогда вероятность его принадлежности и вес уменьшаются.
Несмотря на внешнюю простоту, задача классификации и определения тематики документа (кластеризации) является очень сложной в реализации. На основе только ключевых слов и весов удовлетворительно решить задачу нельзя. Существующие коммерческие системы по сравнению с человеческой оценкой обеспечивают точность классификации 10 - 60%.
Перевод как прикладная лингвистическая дисциплина. Лингвистические проблемы перевода. Переводческие соответствия (виды). Метод сопоставительного анализа и его компьютерная реализация (Параллельные корпусы и конкордансы).
Перевод как прикладная лингвистическая дисциплина.
Перевод – самый древний вид коммуникационной деятельности, основная задача которого – поддержка коммуникации между двумя людьми или социальной группой, говорящих на разных языках.
Лингвистические проблемы перевода.
Выделяют 3 основных вида:
Семантические.
Относят различия в категоризации понятий, так как в каждом языке существует определенная картина мира, которая закрепилась на лингвистическом уровне. Например, деление на время суток – у нас утро, вечер, ночь; у них – morning (с 12 ночи до 12 дня), afternoon (с 12-17), evening (17-20), night (20-00).
Грамматические различия. Являются существенным для двух языков в том случае, если какая-то грамматическая информация влияет на смысл предложения. Например, артикли (the – данный), служебные слова (since – с тех пор как), модальности (but – но, а).
Проблемы, связанные с классом слов, которые называются «ложные друзья переводчика», например,
Синтаксические.
a) ряд проблем, связанных с грамматическими ролями английского языка. По мнению многих ученых, синтаксические языки, т.е. склонные к использованию синтаксических ролей, отвлеченных от семантических ролей. Английский язык имеет более автономный синтаксис, чем немецкий язык и русский язык. Например, для английского языка нетипичным явлением будет то, когда неодушевленные предметы являются активными. Пример: fig and shows the graph of this unit.
b) проблема лексической сочетаемости, которая объясняет сложившиеся языковые традиции или оттенками семантического смысла слов. Пример: rich sunlight – яркий свет, to be deadly serious – очень серьезный.
Прагматические.
Относят, например, проблемы, связанные с повторным упоминанием объектов. В русском языке это считается тавтологией. В английском языке намного мягче и в нем тоже + особенности стиля, и приходится использовать различные стилистические синонимы слов. В научных текстах и учебниках используют формулировки общего плана, например, по нашему мнению. В английском языке обязательно личное упоминание + использование пассивных конструкций.
Переводческие соответствия (виды).
1. Единичные соответствия – межъязыковой эквивалент и наиболее устойчивый способ перевода данной единицы языка, используемых во всех случаях ее проявления и независимо от контекста.
Наиболее полно передают значение слова и раскрывают его семантику. Это, в основном, имена собственные, термины, иногда обиходные слова.
Термины
Это слово или словосочетание, обозначающее понятие (предмет, явление, свойство, отношение, процесс) специфическое для данной отрасли науки, техники или сферы общественной жизни. Такое отличие от слов обиходной семантики однозначно у терминов, как правило, нет синонимов.
Для правильного перевода терминов рекомендуют разграничивать их по группам:
Термины, обозначающие понятия иностранной действительности идентичные понятиям российской действительности. Rector – ректор.
Термины, обозначающие понятия иной действительности, которые отсутствуют в русской действительности, но имеющие общеупотребимый русский эквивалент. FBI-ЦРУ
Термины, обозначающие понятия иностранной действительности, но не имеющие русского эквивалента. Ph.D – Doctor of Philosophy (кандидат наук).
2. Вариантные соответствия.
Это несколько регулярных способов перевода данной единицы языка, выбор которой определяется контекстом. Понятие ВС тесно связано с понятием лингвистики и ситуативного контекста, т.е. контекст слова – это совокупность слов, грамматических форм и конструкций, в окружении которых используется данное слово.
Контекст можно различать по видам:
Лингвистический (синтаксический/лексический)
Ситуативный
Условие контекста влияет на перевод и часто заставляет переводчика отказываться от регулярных общепринятых соответствий, в том числе и от единичных.
Сопоставительный анализ переводов обнаруживает такие лексические единицы, для которых в языке перевода нет ни вариантных ни единичных соответствий. Такая лексика называется безэквивалентной. Отражая реалии той или иной страны, различные неологизмы, новые термины.
Безэквивалентная лексика может быть и грамматической – артикли.
В области безэквивалентной лексики различают следующие соответствия:
Заимствование. Воспроизводит форму слова с помощью транскрипции и транслитерации.
Калька. Воспроизводит морфемный состав слова
Аналоги. Создаются с помощью поиска ближайших по значению единиц.
Лингвистическая замена. Создается при передачи значения безэквивалентного выражения в контексте с помощью одного из видов переводческих трансформаций. I came here with the spouse – супругой/супругом.
Выполняется с помощью описательного перевода, когда перевод 4-го вида не проходит, переводим с помощью развернутого высказывания, что характерно для перевода научно-технической литературы, в том числе и передаче культурных реалий.
Метод сопоставительного анализа и его компьютерная реализация (Параллельные корпусы и конкордансы)
Конкордансы.
Компьютерные конкордансы не являются заменой таких средств как словари и глоссарии, а предоставляют дополнительный способ обработки текстов при переводе. Это программы по обработке текстов, выдающие список всех случаев употребления цепочки букв в определённом корпусе, с целью предоставления пояснительных примеров. Цепочка букв может быть частью слова, например, приставкой или суффиксом, целым словом или группой слов. Особой функцией конкордансов является предоставление статистических данных о количестве слов или предложений, классификация слов и т.д. по частоте употребления или в алфавитном порядке, а также, что, пожалуй, наиболее важно, определение точного контекста, в котором употребляется слово. Информация может накапливаться и храниться по мере перевода текстов, образуя базу данных, доступную для пользования в любое время.
Конкордансы особенно ценны для перевода специальных текстов с устойчивой лексикой и выражениями, имеющими чётко определенное значение. Они помогают придерживаться терминологии, обеспечивая переводчику больший контроль над текстом, независимо от его длины и сложности. Однако, они не настолько полезны для переводчиков художественной литературы, которые постоянно сталкиваются с проблемами, связанными с многозначностью и метафорическим употреблением слов. Тем не менее, некоторые переводчики художественной литературы используют конкордансы, поскольку они, несомненно, играют потенциальную роль во всех видах перевода.
Онлайновые параллельные тексты.
Параллельный корпус, как правило, состоит из текста на входном языке и его перевода, предварительно выполненного профессиональным переводчиком. Документы такого рода, которые хранятся в электронном виде, называются би-текстами. Они облегчают перевод последующих текстов, предлагая готовые переводы устойчивых выражений, автоматизируя, таким образом, часть процесса. Расширение рынка переводческих услуг привело к повышению интереса со стороны компаний и международных организаций к накоплению текстов на различных языках, которые хранятся в систематизированном виде on-line и доступны для непосредственного пользования.
Технология translation memory.
Технология translation memory является одним из наиболее важных приложений онлайновых параллельных текстов, её история уходит к началу 80-ых гг. 20в., когда появилась первая система TSS компании ALPS, позднее Alpnet. Эта технология была успешно реализована в начале 90-ых в таких программах, как Translator Manager, Translator's Workbench, Optimizer, Dйjа Vu, Trados and Eurolang и др. В упрощённом виде технология представляет собой базу данных, в которой переводчик хранит переводы для дальнейшего повторного использования, либо в этом же тексте, либо в других. В основном программа записывает двуязычные пары: отрезок на входном языке (обычно предложение) и отрезок на выходном языке. Если позднее поступает идентичный или похожий отрезок на входном языке, программа translation memory находит ранее переведенный отрезок и автоматически предлагает его для нового перевода.
У переводчика есть выбор: принять его без изменения, отредактировать его в соответствии с контекстом или отказаться от предложенного варианта. Большинство программ находит не только полные соответствия, но и частично совпадающие отрезки. Данный способ автоматизированного перевода особенно эффективен при работе с текстами, обладающими следующими характеристиками:
Терминологическая однородность: значение терминов не меняется.
Фразеологическая однородность: понятия или действия выражены или описаны одинаковыми словами.
Короткие, простые предложения: это увеличивают вероятность повторов и устраняет двусмысленность.
Программы Translation Memory работают в 2-х режимах:
1. В диалоговом режиме: переводимый текст представлен на экране компьютера, и переводчик выбирает один за другим отрезки для перевода. Каждый раз, когда он делает выбор, программа ищет в памяти идентичные или похожие отрезки и выдаёт возможные переводы в отдельном окне. Переводчик принимает, изменяет или отклоняет предложения.
2. В автоматическом режиме: программа автоматически обрабатывает весь текст на входном языке и выдаёт перевод тех отрезков, которые были найдены в памяти. Этот способ более эффективен при наличии большого количества повторений, т. к. не требуется просматривать каждый сегмент отдельно.
Таким образом, программы Translation Memory основаны на накоплении и хранении знаний, которые используются заново по мере необходимости, автоматизируя использование терминологии и доступ к словарям. Когда задачи перевода повторяются, программа экономит ценное время переводчика: например, при переводе некоторых текстов использование клавиатуры может быть сокращено до 70 %. Однако, Translation Memory работает с текстами упрощённо, только с языковыми фрагментами; в отличие от профессионального переводчика, они не могут воспринимать текст в целом, с учётом общей идеи. Другим недостатком технологии является то, что для её эффективного применения необходимо время обучения, и даже после этого некоторое время уходит на создание обширной базы данных. Наконец, необходимо подчеркнуть следующее: программы translation memory предназначены для увеличения качества и эффективности процесса перевода, что касается, прежде всего, специализированных текстов с чётким языком и устоявшимися грамматическими конструкциями, однако полностью заменить профессионального переводчика они не могут.
Заключение: влияние новых технологий на переводчиков.
Долгое время обсуждался вопрос, превратятся ли переводчики с появлением машинного и автоматизированного перевода в простых редакторов, став менее важными по сравнению с компьютерными программами. Подобные опасения привели к тому, что некоторые переводчики отказывались от новых технологий не только из-за возможной потери работы и профессионального престижа, но также и из-за беспокойства по поводу снижения качества производства. Некоторые переводчики полностью отвергают машинный перевод, придерживаясь точки зрения, что перевод - просто еще один рыночный продукт, основанный на подсчёте инвестиций и прибыли. Они определяют перевод как искусство со своими собственными эстетическими критериями, не имеющими никакого отношения к прибыли и убыткам, а в большей степени связанное с творческим потенциалом и силой воображения. Однако, это относится главным образом к определенным видам перевода, например, литературных текстов, где полисемия, смысловые оттенки и стиль играют ключевую роль. Ясно, что при переводе таких текстов компьютеры никак не могут заменить профессиональных переводчиков. И как показывают наши исследования роли и возможностей машинного и автоматизированного перевода, даже при работе с другими видами текстов, ни один из них не является достаточно эффективным и точным, чтобы устранить потребность в профессиональных переводчиках. В сущности, так называемый машинный перевод точнее было бы также назвать автоматизированным переводом. Переводчики должны признать и научиться использовать потенциал новых технологий без каких-либо опасений.
Некоторые люди спрашивают, создали ли новые технологии новую профессию. Можно сказать, что средства, ставшие доступными переводчику с развитием информационных технологий, подразумевают изменения в отношениях между переводчиком и текстом, то есть можно говорить о новом способе перевода, а не о появлении новой профессии в результате. Перевод с помощью компьютера определенно не то же самое, что работа исключительно на бумаге и с книжными изделиями типа обычных словарей, поскольку компьютерные средства позволяют нам находиться в гораздо более гибких отношениях с текстом, чем при простом построчном чтении. Кроме того, Интернет со своими возможностями всеобщего доступа к информации и постоянного общения пользователей, предоставил переводчикам физическую и географическую свободу, что было невообразимо в прошлом