

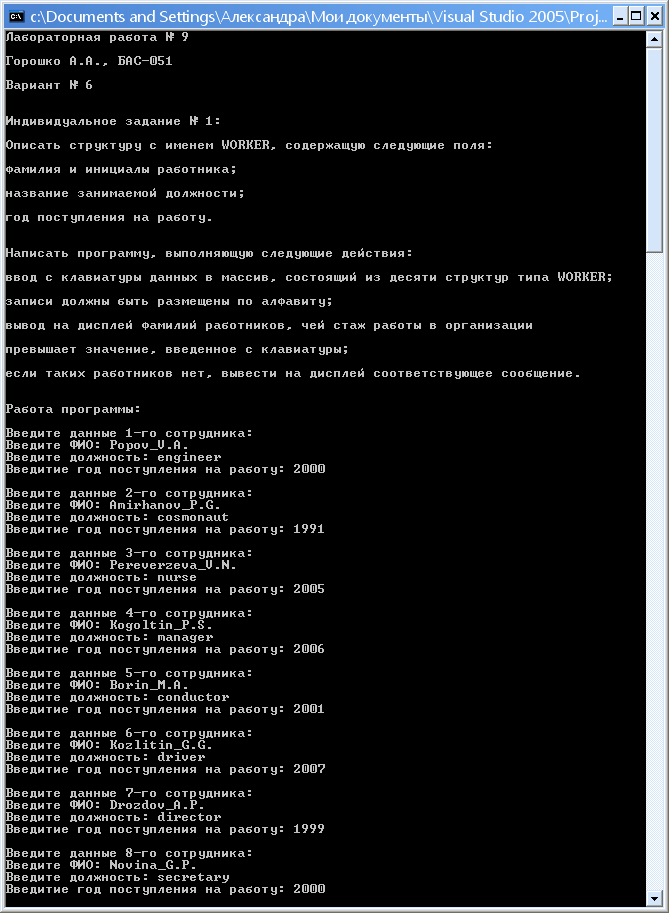
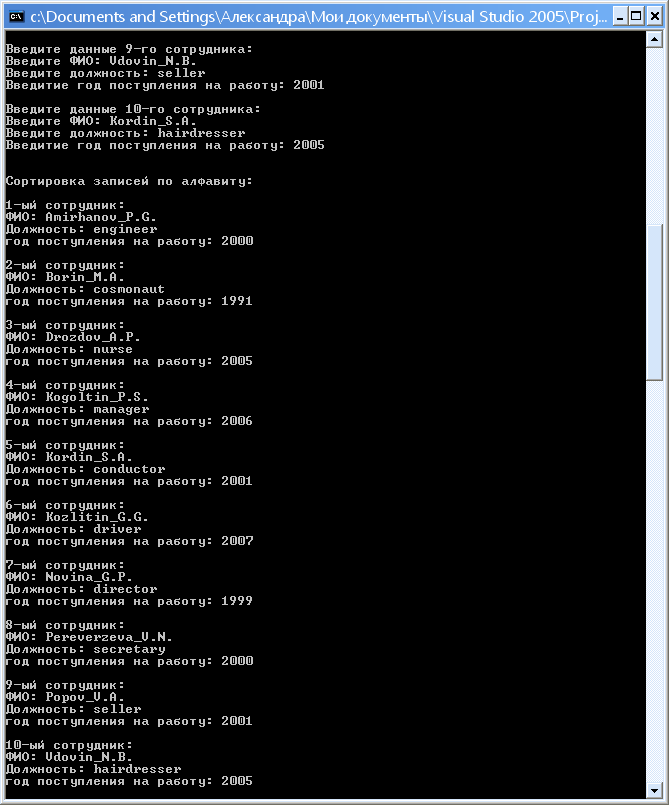
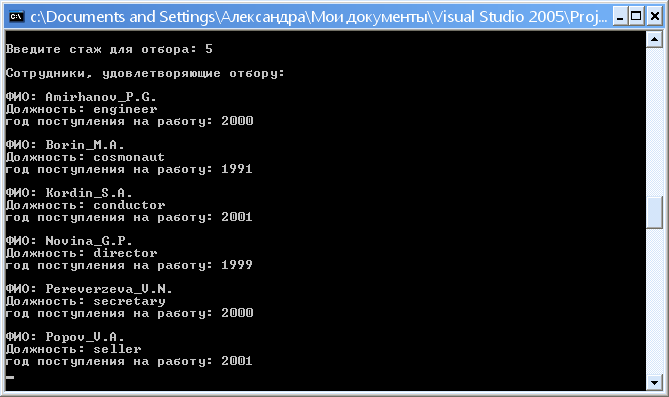
2.4. Результаты работы программы:
Лабораторная работа №10. Классы в языке C++
Цель работы и содержание: закрепление знаний о классах, составление программ с классами.
Ход работы
Структура программы на объектно-ориентированном языке. Структура программы на объектно-ориентированном языке состоит из трех пунктов:
В основе лежит базовый класс (класс – это абстрактный тип данных) – он самый простой;
Классы могут быть независимыми;
Строится иерархия наследования, связь классов, порождающиеся классы является более сложными.
В результате имеем следующую иерархию:
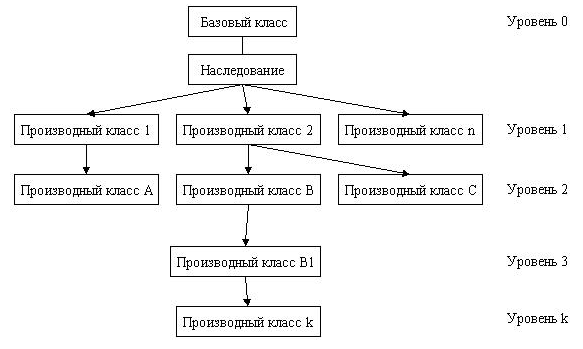
Базовый класс является простейшим из всех классов. Базовых классов может быть несколько и их можно добавлять в процессе эксплуатации. Сложность класса увеличивается с номером уровня. Внизу иерархии стоят самые сложные функции.
Свойства:
Статика (обычно не меняется);
Динамика (меняется).
Пример:
Дата – абстракция
Статика:
число,
месяц,
год.
+ класс
Динамика:
помнить следующую дату,
помнить предыдущую дату,
вычисление промежутков между датами.
Понятие объекта. Понятие объекта в ООП во многом приближено к привычному определению понятия объекта в реальном мире. Рассмотрим физические объекты, которые нас окружают. Про любой из физических объектов можно сказать, что он:
- имеет какое-то состояние (или находится в каком-то состоянии). К примеру, про собаку можно сказать, что она имеет имя, окраску, возраст, голодна она или нет и т.д.
- имеет определенное поведение. Т.е., та же собака может вилять хвостом, есть, лаять, прыгать и т.д.
Объект в ООП состоит из следующих трех частей:
- имя объекта;
- состояние (переменные состояния);
- методы (операции).
Объект ООП - это совокупность переменных состояния и связанных с ними методов (операций). Эти методы определяют как объект взаимодействует с окружающим миром.
Возможность управлять состояниями объекта посредством вызова методов в итоге и определять поведение объекта. Эту совокупность методов часто называют интерфейсом объекта.
Синтаксис декларации объектов аналогичен базовому типу.
Обычно, если объекты соответствуют конкретным сущностям реального мира, то классы являются некими абстракциями, выступающими в роли понятий. На данном этапе можно воспринимать класс как шаблон объекта. Для формирования какого-либо реального объекта необходимо иметь шаблон, на основании которого и строится создаваемый объект. При рассмотрении основ ООП часто смешивается понятие объекта и класса. Дело в том, что класс - это некоторое абстрактное понятие. Для проведения аналогий или приведения примеров оно не очень подходит. На много проще приводить примеры, основываясь на объектах из реального мира, а не на абстрактных понятиях. Поэтому, говоря, к примеру, про наследование мы прежде всего имеем ввиду наследование классов (шаблонов), а не объектов, хотя часто и применяем слово объект. Скажем так: объект - это физическая реализация класса (шаблона).
Понятие класса. Понятие класс (class) относится ко всем объектам, которые ведут себя одинаково. Например, все окружности имеют вполне определенную форму, они обладают такими атрибутами, как местоположение, цвет, диаметр. Объект – это конкретный экземпляр данного класса. Например, Земля имеет размер, цвет и местоположение, отличные от аналогичных параметров для Луны или Солнца. Связь между классом и объектами в сущности такая же, как между типом и переменными этого типа.
Класс (class) - это группа данных и методов(функций) для работы с этими данными. Это шаблон. Объекты с одинаковыми свойствами, то есть с одинаковыми наборами переменных состояния и методов, образуют класс.
Каждый класс объектов может реагировать на строго определенные сообщения. Так происходит потому, что каждый класс обладает набором функций, которые связаны с объектами класса. Функции являются частью этого класса объектов – его членами. На рисунке показан объект, содержащий функции-члены. Программа посылает этому объекту сообщения (messages), которые вызывают функции-члены (member functions) данного объекта. Затем эти функции-члены обрабатывают объект.
Эти функции
называются функциями-членами, поскольку
принадлежат 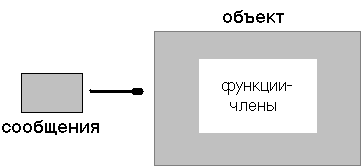 классу,
то есть являются его членами. Функции-члены
программируются так же, как обычные
функции, однако объявляются в классе и
могут использоваться только с объектами
этого класса.
классу,
то есть являются его членами. Функции-члены
программируются так же, как обычные
функции, однако объявляются в классе и
могут использоваться только с объектами
этого класса.
Примерная структура класса (не привязанная к какому-либо языку ООП):
Class имя_класса [ от кого унаследован]
{
private:
. . . . . . .
public:
. . . . . . .
protected:
. . . . . . .
}
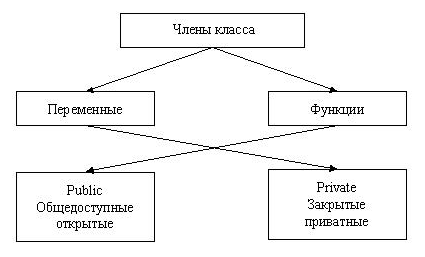
Класс должен иметь уникальное имя. Если он наследован из другого, то надо указать имя родительского(их) класса(ов). Обычно у класса бывают три раздела: private, public, protected. Указание на начало раздела private часто опускается и, если не объявлено начало ни одного из других разделов описания класса, считается, что данные относятся к разделу private.
Методы в классе могут быть объявлены как дружественные (friend) или виртуальные (virtual). Иногда встречается объявление перегружаемых (overload) функций. Каждое из этих понятий более подробно мы рассмотрим отдельно.
Private (частный) раздел описания класса обычно находится вначале описания класса и содержит данные, доступ к которым закрыт из внешнего мира. Это и есть та самая "строго охраняемая" зона класса, доступ к которой можно получить только из методов самого класса. Она скрыта от внешнего мира глухой непробиваемой стеной и доступ к данным раздела private обеспечивается только с помощью, специально описанных в других разделах, методов. Скрытые в этом разделе данные также не доступны для всех производных классов.
Если бы все данные, описанные в базовом (родительском) классе, были доступны для производных классов, то можно было бы просто создать супер-класс, а затем из производных классов получать свободный доступ ко всем данным родительского класса. В то же время это перечеркнуло бы все наши старания по скрытию и защите данных. По этой причине, производные (наследуемые) классы автоматически не получают доступ к данным родительского класса (раздел private). Но бывают такие случаи, когда необходимо автоматически наследовать некоторые данные из родительского класса так, чтобы они вели себя так, как будто они описаны в производном классе . Именно для этих целей и существует раздел protected(защищенный) описания класса.
Protected (защищенный) - раздел описания класса содержит данные и методы, доступ к которым закрыт из внешней среды, но они напрямую доступны производным классам.
Таким образом, раздел protected используется для описания данных и методов, которые будут доступны только из производных классов. А в производных классах эти данные и методы воспринимаются, как если бы они были описаны в самом производном классе.
Название раздела public для англо-язычной публики говорит само за себя. Переводится как публичный, я бы сказал, открытый раздел. Методы описанные в разделе public доступны в пределах области видимости объекта и для производных классов. Таким образом, можно получить свободный доступ к методам, описанным в разделе public, из любого места программы (объект должен быть виден) и из любого производного класса. Методы, входящие в этот раздел, образуют интерфейс класса, с помощью которого и осуществляется взаимодействие экземпляра класса с внешним миром. Это единственный раздел, доступ к которому из внешней среды никак не ограничен.
Пример простейшего класса данных:
Class date
{
private:int,day,year
}
public: int, input (int,char,int);
int output (int, char*, int);
int sum1 (int,char*, int);
int sum2 (int, char*, int);
int min1 (int, Char*,int);
int min n (int,char*, int);
int koi (int, char*,int,int,char*,int,int)
При указании базового(родительского) класса в описании класса в С++ требуется указать ключевое слово public. Указание этого ключевого слова позволит получить свободный доступ ко всем методам класса, как если бы они были описаны в самом производном классе. В противном же случае, мы не сможем получить доступ к методам родительского класса.
Пример описания наследования классов на С++:
class A
{
. . . . .
}
class B : public A
{
. . . . .
}
Классы предоставляют программисту возможность моделировать объекты, которые имеют атрибуты (представленные как данные элементы) и варианты поведения или операции (представленные как функции элементы). Типы, содержащие данные-элементы и функции-элементы, обычно определяются в C++ с помощью ключевого слова class.
Пример 10.1. Использование абстрактного типа данных Time с помощью класса Time
Class Time
{
public:
Time();
void setTime(int, int, int);
void printMilitary();
void printStandard();
private:
int hour;//0-23
int minute;//0-59
int second;//0-59
};
Листинг 10.1
//FIG6_3.cpp
//Класс Time
#include <iostream.h>
//Определение абстрактного типа данных (АТД) Time
class Time
{
public:
Time();
void setTime(int, int, int);//установка часов, минут и секунд
void printMilitary();//печать времени в военном формате
void printStandard();//печать времени в стандартном формате
private:
int hour; //0-23
int minute;//0-59
int second;//0-59
};
//Конструктор Time присваивает нулевые начальные значения каждому элементу данных. Обеспечивает согласованое начальное состояние всех объектов Time
Time::Time() {hour = minute = second = 0;}
//Задание нового значения Time в виде военного времени.
//Проверка правильности значений данных.
//Обнуление неверных значений.
void Time::setTime(int h, int m, int s)
{
hour = (h >= 0 && h < 24) ? h : 0;
minute = (m >= 0 && m < 60) ? m : 0;
second = (s >= 0 && s < 60) ? s : 0;
}
//Печать времени в военном формате
void Time::printMilitary()
{
cout << (hour < 10 ? "0":"")<<hour<<":"<<(minute < 10 ? "0" : "")<<minute << ":"<<(second < 10 ? "0" : "") << second;
}
//Печать времени в стандартном формате
void Time::printStandard()
{
cout << ((hour == 0 || hour == 12) ? 12 : hour % 12)<<":"<<(minute < 10 ? "0" :"")<<minute <<":" <<(second < 10 ? "0" : "") << second << (hour < 12 ? "AM" : " PM");
}
//Формирование проверки простого класса Time
main()
{
Time t; //определение экземпляра объекта t класса Time
cout << "Начальное значение военного времени равно ";
t.printMilitary();
cout << endl << "Начальное значение стандартного времени равно ";
t.printStandard();
t.setTime(13,27,6);
cout << endl << endl << "Военное время после setTime равно ";
t.printMilitary();
cout<<endl<<"Стандартное время после setTime равно ";
t.printStandard();
t.setTime(99,99,99);//попытка установить неправильные значения
cout << endl << endl <<"После попытки неправильной установки: " << endl << "Военное время: ";
t.printMilitary();
cout << endl << "Стандартное время: ";
t.printStandard();
cout << endl;
return 0;
}
Инкапсуляция. Инкапсуляция - это механизм, который объединяет данные и методы, манипулирующие этими данными, и защищает и то и другое от внешнего вмешательства или неправильного использования. Когда методы и данные объединяются таким способом, создается объект.
Применяя инкапсуляцию, мы, защищаем данные, принадлежащие объекту, от возможных ошибок, которые могут возникнуть при прямом доступе к этим данным. Кроме того, применение этого принципа очень часто помогает локализовать возможные ошибки в коде программы. А это на много упрощает процесс поиска и исправления этих ошибок. Можно сказать, что инкапсуляция подразумевает под собой скрытие данных (data hiding), что позволяет защитить эти данные.
Переменные состояния объекта скрыты от внешнего мира. Изменение состояния объекта (его переменных) возможно ТОЛЬКО с помощью его методов (операций).
Этот принцип позволяет защитить переменные состояния объекта от неправильного их использования. Это существенно ограничивает возможность введения объекта в недопустимое состояние и/или несанкционированное разрушение этого объекта.
Хорошим примером применения принципа инкапсуляции являются команды доступа к файлам. Обычно доступ к данным на диске можно осуществить только через специальные функции. Вы не имеете прямой доступ к данным, размещенным на диске. Таким образом, данные, размещенные на диске, можно рассматривать скрытыми от прямого Вашего вмешательства. Доступ к ним можно получить с помощью специальных функций, которые по своей роли схожи с методами объектов. При этом, хотелось бы отметить два момента, которые важны при применении этого подхода. Во-первых, Вы можете получить все данные, которые Вам нужны за счет законченного интерфейса доступа к данным. И, во-вторых, Вы не можете получить доступ к тем данным, которые Вам не нужны. Это предотвращает случайную порчу данных, которая возможна при прямом обращении к файловой системе. Кроме того, это предотвращает получение неверных данных, т.к. специальные функции обычно используют последовательный доступ к данным.
Применение этого метода ведет к снижению эффективности доступа к элементам объекта. Это обусловлено необходимостью вызова методов для изменения внутренних элементов(переменных) объекта. Однако, при современном уровне развития вычислительной техники, эти потери в эффективности не играют существенной роли.
Абстрактный тип данных - это группа тесно связанных между собой данных и методов (функций), которые могут осуществлять операции над этими данными.
Поскольку подразумевается, что эта структура защищена от внешнего влияния, то она считается инкапсулированной структурой. Важным же отличием от других аналогичных структур является то, что данные заключенные в этой структуре, тесно связанны и активно взаимодействуют между собой внутри структуры. Подобные структуры имеют слабые связи с внешним миром посредством ограниченного интерфейса. Суть подобных структур довольно проста: данные имеют тесные взаимосвязи внутри структуры, но слабые связи с внешним миром посредством ограниченного числа методов. Таким образом, структуры подобного рода имеют достаточно простой, но эффективный интерфейс, что позволяет их легко интегрировать в программах.
Наследование (Inheritance). Наследование - это процесс, посредством которого один объект может наследовать свойства другого объекта и добавлять к ним черты, характерные только для него.
Смысл и универсальность наследования заключается в том, что не надо каждый раз заново (с нуля) описывать новый объект, а можно указать родителя (базовый класс) и описать отличительные особенности нового класса. В результате, новый объект будет обладать всеми свойствами родительского класса плюс своими собственными отличительными особенностями.
В описаниях языков ООП принято класс, из которого наследуют называть родительским классом (parent class) или основой класса (base class). Класс, который получаем в результате наследования называется порожденным классом (derived or child class). Родительский класс всегда считается более общим и развернутым. Порожденный же класс всегда более строгий и конкретный, что делает его более удобным в применении при конкретной реализации.
Новый, или производный класс может быть определен на основе уже имеющегося, или базового. При этом новый класс сохраняет все свойства старого: данные объекта базового класса включаются в данные объекта производного, а методы базового класса могут быть вызваны для объекта производного класса, причем они будут выполняться над данными включенного в него объекта базового класса. Иначе говоря, новый класс наследует как данные старого класса, так и методы их обработки.
Наследование нужно, для того чтобы расширить уже созданные абстрактные классы новыми свойствами или действиями. Есть несколько правил наследования классов:
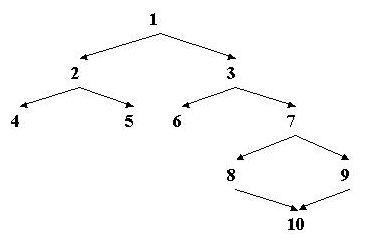
Создаётся иерархия классов, где классы стоящие ниже по иерархии могут иметь доступ к переменным и функциям выше стоящих классов.
Классы стоящие ниже по иерархии- производные классы, относительно классов, которые стоят выше них (4,5 - производные относительно 2, а 8,9 - производные относительно 7).
Классы , которые состоят выше по иерархиям являются базовыми для ниже стоящих классов (1 - базовый для 2 и 3).
Понятие базового и производного класса не предполагают относительность уровня иерархи, т.е. то множество классов, которое стоят на один уровень выше и являются базовыми.
Каждый производный класс имеет множество непосредственных родителей, т.е. то множество классов, которые стоят на один уровень выше и являются базовыми.
Соответственно: если родитель один- простое наследование, в другом же случае- множественное наследование.
Начало иерархии компьютера - это класс, один или более, которые называются протоклассом плюс корень дерева. Обычно бывает 2 или 3 протокласса на практике. Обычно протокол являются пустыми или состоят из пустых виртуальных функций. (Виртуальной называется функция ,сущность которой определяется во время выполнения программы.)
Классы стоящие ниже по иерархии имеют дополнительные свойства и функции относительно вышестоящих классов.
Концепция наследования позволяет создавать новые классы, которые используют переменные и функции уже существующих его класса, но не содержит их в своём теле.
Когда один класс наследуется другим, используется следующая форма записи:
class имя_производного_класса: сп_доступа имя_базового_класса
{
//….
}
Здесь сп_доступа – это одно из трех ключевых слов: public, private или protected. Спецификатор доступа определяет, как элементы базового класса наследуются производным классом. Если спецификатором доступа наследуемого базового класса является ключевое слово public, то все открытые члены базового класса остаются открытыми и в производном. Если спецификатором доступа наследуемого базового класса является ключевое слово private, то все открытыте члены базового класса в производном классе становятся закрытыми. В обоих случаях все закрытые члены базового класса в производном классе остаются закрытыми и недоступными. Важно понимать, что если спецификатором доступа является ключевое слово private, то хотя открытые члены базового класса становятся закрытыми в производном, они остаются доступными для функций – членов производного класса.
Технически сецификатор доступа необязателен.
Пример 10.2. Реализация принципа наследования классов
Написать программу, которая реализует принцип наследования классов. При этом она создает объект одного класса, но для полной реализации поставленной задачи берет часть функций представленных в базовом классе.
Листинг 10.2
#include <iostream.h>
class Subtraction
{
public:
int funct_Sub(int a, int b);
};
class Sum:public Subtraction
{
public:
int funct_Sum(int a, int b);
};
int Subtraction::funct_Sub(int a, int b)
{
return a - b;
}
int Sum::funct_Sum(int a, int b)
{
return a + b;
}
main()
{
Sum s;
int a = 5;
int b = 3;
cout << "Raznost " << s.funct_Sub(a,b) << endl;
cout << "Summa " << s.funct_Sum(a,b) << endl;
return 0;
}
Полиморфизм. Полиморфизм - это свойство, которое позволяет одно и тоже имя использовать для решения нескольких технически разных задач.
В общем смысле, концепцией полиморфизма является идея "один интерфейс, множество методов". Это означает, что можно создать общий интерфейс для группы близких по смыслу действий.
Преимуществом полиморфизма является то, что он помогает снижать сложность программ, разрешая использование одного интерфейса для единого класса действий. Выбор конкретного действия, в зависимости от ситуации, возлагается на компилятор.
Применительно к ООП, целью полиморфизма является использование одного имени для задания общих для класса действий. На практике это означает способность объектов выбирать внутреннюю процедуру (метод) исходя из типа данных, принятых в сообщении.
Компилятор при наличии нескольких функций последовательно проверяет шаблоны функций с одним и тем же именем пока не найдет подходящий.
Одна из разновидностей полиморфизма в языке C++ - перегрузка функций. Программирование с классами предоставляет еще две возможности: перегрузку операций и использование так называемых виртуальных методов. Перегрузка операций позволяет применять для собственных классов те же операции, которые используются для встроенных типов C++. Виртуальные методы обеспечивают возможность выбрать на этапе выполнения нужный метод среди одноименных методов базового и производного классов.
Операторы объектно-ориентированного программирования, связанные с применением классов:
1. Оператор доступа (.)
Синтаксис:
переменная типа класс.член класса ;
Доступ по этому оператору извне возможен только к октрытому классу public. Под “извне” понимается внешняя функция для класса
2. Оператор видимости (::)
Назначение оператора – определить к какому классу относиться конкретная функция.
Синтаксис:
Тип имя_класса :: имя_функции (список параметров с указанием типа)
{
тело функции
}
Оператор видимости трансформирует имя_функции в имя_класса + имя_функции.
3. Операция стрелка доступа к членам класса
Используется, если объект объявлен как указатель на класс.
y *obj;
obj input ( ); эквивалентно (*obj). input ( );
Синтаксис оператора “стрелка”:
адрес_объекта член_класса;
при объявлении объекта: имя_класса*имя_объекта.
4. Указатель this
Используется только в функциях членах класса. Указатель возвращает объект (адрес объекта), для которого функция применяется.
Конструкторы. Допустим, имеется объект класса Clock. При объявлении этого объекта, он автоматически инициализуется. Это означает, что при создании нового объекта класса Clock переменной timestarted присваивается текущее системное время. Кто (или вернее что) это делает?
Для этого нужно определить специальную функцию, которая будет специально вызываться при создании каждого объекта. В языке С++ это можно сделать при помощи специальной функции, которая называется конструктором (constructor).
Конструктор похож на любую другую функцию-член, за исключением следующего:
Имя конструктора совпадает с именем класса. Например, конструктором класса Clock является функция Clock().
При создании нового объекта конструктор вызывается автоматически. Например, если создать два объекта mine и yours класса Clock, то конструктор Clock() будет вызван дважды- один раз при создании объекта mine и другой при создании объекта yours.
Конструктор нельзя вызвать из программы напрямую. Например, нельзя написать инструкцию mine.Clock(); Конструктор вызывается только однажды – при создании объекта.
У конструктора нет возвращаемого типа. Возможно существование нескольких конструкторов с разными списками аргументов.
Простейшие правила проектирования класса:
Переменные класса находятся в разделе privat.
Для каждой переменной класса в классе должна быть функция установки.
Функции установки обычно являются открытыми.
Для каждой закрытой переменной класса в классе должна быть функция доступа.
Функция доступа (обычно) расположена в открытой части класса.
Встроенными функциями (in line) называются функции класса, описанные внутри класса, то есть тело функции находится внутри класса. Встроенными могут быть функции, которые не содержат сложных операций if, вложенных в цепи.
Простейший класс:
Class my:
{
public
int x,y;
publiс:
inline int funk 1(void)
{
retun(x+y);
}
int funk 2(void)
{
retun(x*y);
}
void set x(int var)
{
x = var;
}
void set y(int var)
{
y = var;
}
int ret x(void)
{
return x;
}
int ret y(void)
{
return y;
}
}
Функция узнается компилятором по двойным фигурным скобкам. Это объясняет их необходимость.
Описание конструктора составляет альтернативу использованию нескольких функций (перегруженных), который по заданному double создает complex.
Например:
class complex
{
// ...
complex(double r)
{
re = r;
im = 0;
}
};
Конструктор, требующий только один параметр, необязательно вызывать явно:
complex z1 = complex(23);
complex z2 = 23;
И z1, и z2 будут инициализированы вызовом complex(23).
Конструктор - это предписание, как создавать значение данного типа. Когда требуется значение типа, и когда такое значение может быть создано конструктором, тогда, если такое значение дается для присваивания, вызывается конструктор. Например, класс complex можно было бы описать так:
class complex
{
double re, im;
public:
complex(double r, double i = 0)
{
re = r;
im = i;
}
friend complex operator+(complex, complex);
friend complex operator*(complex, complex);
};
и действия, в которые будут входить переменные complex и целые константы, стали бы допустимы. Целая константа будет интерпретироваться как complex с нулевой мнимой частью. Например, a = b*2 означает:
a = operator*( b, complex( double(2), double(0) ) )
Определенное пользователем преобразование типа применяется неявно только тогда, когда оно является единственным.
Объект, сконструированный с помощью явного или неявного вызова конструктора, является автоматическим и будет уничтожен при первой возможности, обычно сразу же после оператора, в котором он был создан.
Операции Преобразования. Использование конструктора для задания преобразования типа является удобным, но имеет следствия, которые могут оказаться нежелательными:
1. Не может быть неявного преобразования из определенного пользователем типа в основной тип (поскольку основные типы не являются классами);
2. Невозможно задать преобразование из нового типа в старый, не изменяя описание старого;
3. Невозможно иметь конструктор с одним параметром, не имея при этом преобразования.
Последнее не является серьезной проблемой, а с первыми двумя можно справиться, определив для исходного типа операцию преобразования. Функция член X::operator T(), где T - имя типа, определяет преобразование из X в T.
Например, можно определить тип tiny (крошечный), который может иметь значение только в диапазоне 0...63, но все равно может свободно сочетаться в целыми в арифметических операциях:
class tiny
{
char v;
int assign(int i)
{
return v = (i&~63) ? (error("ошибка диапазона"),0) : i;
}
public:
tiny(int i)
{
assign(i);
}
tiny(tiny& i)
{
v = t.v;
}
int operator=(tiny& i)
{
return v = t.v;
}
int operator=(int i)
{
return assign(i);
}
operator int()
{
return v;
}
}
Диапазон значения проверяется всегда, когда tiny инициализируется int, и всегда, когда ему присваивается int. Одно tiny может присваиваться другому без проверки диапазона. Чтобы разрешить выполнять над переменными tiny обычные целые операции, определяется tiny::operator int(), неявное преобразование из int в tiny. Всегда, когда в том месте, где требуется int, появляется tiny, используется соответствующее ему int. Например:
void main()
{
tiny c1 = 2;
tiny c2 = 62;
tiny c3 = c2 - c1; // c3 = 60
tiny c4 = c3; // нет проверки диапазона (необязательна)
int i = c1 + c2; // i = 64
c1 = c2 + 2 * c1; // ошибка диапазона: c1 = 0 (а не 66)
c2 = c1 -i; // ошибка диапазона: c2 = 0
c3 = c2; // нет проверки диапазона (необязательна)
}
Тип вектор из tiny может оказаться более полезным, поскольку он экономит пространство. Чтобы сделать этот тип более удобным в обращении, можно использовать операцию индексирования.
Другое применение определяемых операций преобразования - это типы, которые предоставляют нестандартные представления чисел (арифметика по основанию 100, арифметика с фиксированной точкой, двоично-десятичное представление и т.п.). При этом обычно переопределяются такие операции, как + и *.
Функции преобразования оказываются особенно полезными для работы со структурами данных, когда чтение (реализованное посредством операции преобразования) тривиально, в то время как присваивание и инициализация заметно более сложны.
Типы istream и ostream опираются на функцию преобразования, чтобы сделать возможными такие операторы, как while (cin>>x) cout<>x выше возвращает istream&. Это значение неявно преобразуется к значению, которое указывает состояние cin, а уже это значение может проверяться оператором while. Однако определять преобразование из оного типа в другой так, что при этом теряется информация, обычно не стоит.
Неоднозначности. Присваивание объекту (или инициализация объекта) класса X является допустимым, если или присваиваемое значение является X, или существует единственное преобразование присваиваемого значения в тип X.
В некоторых случаях значение нужного типа может сконструироваться с помощью нескольких применений конструкторов или операций преобразования. Это должно делаться явно; допустим только один уровень неявных преобразований, определенных пользователем. Иногда значение нужного типа может быть сконструировано более чем одним способом. Такие случаи являются недопустимыми. Например:
class x
{
/* ... */ x(int); x(char*);
};
class y
{
/* ... */ y(int);
};
class z
{
/* ... */ z(x);
};
overload f;
x f(x);
y f(y);
z g(z);
f(1); // недопустимо: неоднозначность f(x(1)) или f(y(1))
f(x(1));
f(y(1));
g("asdf"); // недопустимо: g(z(x("asdf"))) не пробуется
g(z("asdf"));
Определенные пользователем преобразования рассматриваются только в том случае, если без них вызов разрешить нельзя. Например:
class x
{
/* ... */ x(int);
}
overload h(double), h(x);
h(1);
Вызов мог бы быть проинтерпретирован или как h(double(1)), или как h(x(1)), и был бы недопустим по правилу единственности. Но первая интерпретация использует только стандартное преобразование. Правила преобразования не являются ни самыми простыми для реализации и документации, ни наиболее общими из тех, которые можно было бы разработать. Возьмем требование единственности преобразования. Более общий подход разрешил бы компилятору применять любое преобразование, которое он сможет найти; таким образом, не нужно было бы рассматривать все возможные преобразования перед тем, как объявить выражение допустимым. К сожалению, это означало бы, что смысл программы зависит от того, какое преобразование было найдено. В результате смысл программы неким образом зависел бы от порядка описания преобразования.
Поскольку они часто находятся в разных исходных файлах (написанных разными людьми), смысл программы будет зависеть от порядка компоновки этих частей вместе. Есть другой вариант - запретить все неявные преобразования. Нет ничего проще, но такое правило приведет либо к неэлегантным пользовательским интерфейсам, либо к бурному росту перегруженных функций, как это было в предыдущем разделе с complex.
Самый общий подход учитывал бы всю имеющуюся информацию о типах и рассматривал бы все возможные преобразования. Например, если использовать предыдущее описание, то можно было бы обработать aa=f(1), так как тип aa определяет единственность толкования. Если aa является x, то единственное, дающее в результате x, который требуется присваиванием, - это f(x(1)), а если aa - это y, то вместо этого будет использоваться f(y(1)). Самый общий подход справился бы и с g("asdf"), поскольку единственной интерпретацией этого может быть g(z(x("asdf"))). Сложность этого подхода в том, что он требует расширенного анализа всего выражения для того, чтобы определить интерпретацию каждой операции и вызова функции. Это приведет к замедлению компиляции, а также к вызывающим удивление интерпретациям и сообщениям об ошибках, если компилятор рассмотрит преобразования, определенные в библиотеках и т.п.
Константы. Константы классового типа определить невозможно в том смысле, в каком 1.2 и 12e3 являются константой типа double. Вместо них, однако, часто можно использовать константы основных типов, если их реализация обеспечивается с помощью функций членов. Общий аппарат для этого дают конструкторы, получающие один параметр. Когда конструкторы просты и подставляются inline, имеет смысл рассмотреть в качестве константы вызов конструктора. Если, например, в есть описание класса comlpex, то выражение zz1*3+zz2*comlpex(1,2) даст два вызова функций, а не пять. К двум вызовам
функций приведут две операции *, а операция + и конструктор, к которому обращаются для создания comlpex(3) и comlpex(1,2), будут расширены inline.
Большие Объекты. При каждом применении для comlpex бинарных операций, описанных выше, в функцию, которая реализует операцию, как параметр передается копия каждого операнда. Расходы на копирование каждого double заметны, но с ними вполне можно примириться. К сожалению, не все классы имеют небольшое и удобное представление. Чтобы избежать ненужного копирования, можно описать функции таким образом, чтобы они получали ссылочные параметры. Например:
class matrix
{
double m[4][4];
public:
matrix();
friend matrix operator+(matrix&, matrix&);
friend matrix operator*(matrix&, matrix&);
};
Ссылки позволяют использовать выражения, содержащие обычные арифметические операции над большими объектами, без ненужного копирования. Указатели применять нельзя, потому что невозможно для применения к указателю смысл операции переопределить невозможно. Операцию плюс можно определить так:
matrix operator+(matrix&, matrix&);
{
matrix sum;
for (int i=0; i<4; i++)
for (int j=0; j<4; j++)
sum.m[i][j] = arg1.m[i][j] + arg2.m[i][j];
return sum;
}
Эта operator+() обращается к операндам + через ссылки, но возвращает значение объекта. Возврат ссылки может оказаться более эффективным:
class matrix
{
// ...
friend matrix& operator+(matrix&, matrix&);
friend matrix& operator*(matrix&, matrix&);
};
Это является допустимым, но приводит к сложности с выделением памяти. Поскольку ссылка на результат будет передаваться из функции как ссылка на возвращаемое значение, оно не может быть автоматической переменной. Поскольку часто операция используется в выражении больше одного раза, результат не может быть и статической переменной. Как правило, его размещают в свободной памяти. Часто копирование возвращаемого значения оказывается дешевле (по времени выполнения, объему кода и объему данных) и проще программируется.
Присваивание и Инициализация. Рассмотрим очень простой класс строк string:
struct string
{
char* p;
int size; // размер вектора, на который указывает p
string(int sz)
{
p = new char[size=sz];
}
~string()
{
delete p;
}
};
Строка - это структура данных, состоящая из вектора символов и длины этого вектора. Вектор создается конструктором и уничтожается деструктором.
Однако это может привести к неприятностям. Например:
void f()
{
string s1(10);
string s2(20);
s1 = s2;
}
будет размещать два вектора символов, а присваивание s1 = s2 будет портить указатель на один из них и дублировать другой. На выходе из f() для s1 и s2 будет вызываться деструктор и уничтожать один и тот же вектор с непредсказуемо разрушительными последствиями. Решение этой проблемы состоит в том, чтобы соответствующим образом определить присваивание объектов типа string:
struct string
{
char* p;
int size; // размер вектора, на который указывает p
string(int sz)
{
p = new char[size = sz];
}
~string()
{
delete p;
}
void operator = (string&)
};
void string::operator = (string& a)
{
if (this == &a) return; // остерегаться s =s;
delete p;
p = new char[size=a.size];
strcpy(p,a.p);
}
Это определение string гарантирует, и что предыдущий пример будет работать как предполагалось. Однако небольшое изменение f() приведет к появлению той же проблемы в новом облике:
void f()
{
string s1(10);
s2 = s1;
}
Теперь создается только одна строка, а уничтожается две. К неинициализированному объекту определенная пользователем операция присваивания не применяется. Беглый взгляд на string::operator = () объясняет, почему было неразумно так делать: указатель p будет содержать неопределенное и совершенно случайное значение. Часто операция присваивания полагается на то, что ее аргументы инициализированы. Для такой инициализации, как здесь, это не так по определению. Следовательно, нужно определить похожую, но другую, функцию, чтобы обрабатывать инициализацию:
struct string
{
char* p;
int size; // размер вектора, на который указывает p
string(int sz)
{
p = new char[size = sz];
}
~string()
{
delete p;
}
void operator = (string&)
string(string&);
};
void string::string(string& a)
{
P = new char[size = a.size];
strcpy(p,a.p);
}
Для типа X инициализацию тем же типом X обрабатывает конструктор X(X&).
Присваивание и инициализация – разные действия. Это особенно существенно при описании деструктора. Если класс X имеет конструктор, выполняющий нетривиальную работу вроде освобождения памяти, то скорее всего потребуется полный комплект функций, чтобы полностью избежать побитового копирования объектов:
class X
{
// ...
X(something); // конструктор: создает объект
X(&X); // конструктор: копирует в инициализации
operator=(X&); // присваивание: чистит и копирует
~X(); // деструктор: чистит
}
Есть еще два случая, когда объект копируется: как параметр функции и как возвращаемое значение. Когда передается параметр, инициализируется неинициализированная до этого переменная - формальный параметр. Семантика идентична семантике инициализации. То же самое происходит при возврате из функции, хотя это менее очевидно. В обоих случаях будет применен X(X&), если он определен:
string g(string arg)
{
return arg;
}
main()
{
string s = "asdf";
s = g(s);
}
Ясно, что после вызова g() значение s обязано быть "asdf". Копирование значения s в параметр arg сложности не представляет: для этого надо взывать string(string&). Для взятия копии этого значения из g() требуется еще один вызов string(string&); на этот раз инициализируемой является временная переменная, которая затем присваивается s. Такие переменные, естественно, уничтожаются как положено с помощью string::~string() при первой возможности.
Индексирование. Чтобы задать смысл индексов для объектов класса используется функция operator[]. Второй параметр (индекс) функции operator[] может быть любого типа. Это позволяет определять ассоциативные массивы и т.п.
Пример 10.2. Реализация принципа индексирования классов
Написать программу для подсчета числа вхождений слов в файл с применением ассоциативного массива и использованием функции.
Здесь определяется надлежащий тип ассоциативного массива:
struct pair
{
char* name;
int val;
};
class assoc
{
pair* vec;
int max;
int free;
public:
assoc(int);
int& operator[](char*);
void print_all();
}
В assoc хранится вектор пар pair длины max. Индекс первого неиспользованного элемента вектора находится в free. Конструктор выглядит так:
assoc::assoc(int s)
{
max = (s<16) ? s : 16;
free = 0;
vec = new pair[max];
}
При реализации применяется простой и неэффективный метод поиска, однако при переполнении assoc увеличивается:
Листинг 10.3
#include
int assoc::operator[](char* p)
/*
работа с множеством пар "pair":
поиск p,
возврат ссылки на целую часть его "pair"
делает новую "pair", если p не встречалось
*/
{
register pair* pp;
for (pp = &vec[free-1]; vec <= pp; pp--)
if (strcmp(p,pp->name)==0) return pp->val;
if (free == max) { // переполнение: вектор увеличивается
pair* nvec = new pair[max*2];
for (int i = 0; iname = new char [strlen(p)+1];i++);
strcpy(pp->name,p);
pp->val = 0; // начальное значение: 0
return pp->val;
}
Поскольку представление assoc скрыто, нужен способ его печати. Здесь воспользуемся простой функцией печати:
vouid assoc::print_all()
{
for (int i = 0; i>buf) vec[buf]++;
vec.print_all();
}
Вызов Функции. Вызов функции, то есть запись выражение(список_выражений), можно проинтерпретировать как бинарную операцию, и операцию вызова можно перегружать так же, как и другие операции. Список параметров функции operator() вычисляется и проверяется в соответствие с обычными правилами передачи параметров. Перегружающая функция может оказаться полезной главным образом для определения типов с единственной операцией и для типов, у которых одна операция настолько преобладает, что другие в большинстве ситуаций можно не принимать во внимание.
Для типа ассоциативного массива assoc мы не определили итератор. Это можно сделать, определив класс assoc_iterator, работа которого состоит в том, чтобы в определенном порядке поставлять элементы из assoc. Итератору нужен доступ к данным, которые хранятся в assoc, поэтому он сделан другом:
class assoc
{
friend class assoc_iterator;
pair* vec;
int max;
int free;
public:
assoc(int);
int& operator[](char*);
};
Итератор определяется как
class assoc_iterator
{
assoc* cs; // текущий массив assoc
int i; // текущий индекс
public:
assoc_iterator(assoc& s)
{
cs = &s; i = 0;
}
pair* operator()()
{
return (ifree)? &cs->vec[i++] : 0;
}
};
Надо инициализировать assoc_iterator для массива assoc, после чего он будет возвращать указатель на новую pair из этого массива всякий раз, когда его будут активизировать операцией (). По достижении конца массива он возвращает 0:
main() // считает вхождения каждого слова во вводе
{
const MAX = 256; // больше самого большого слова
char buf[MAX];
assoc vec(512);
while (cin>>buf) vec[buf]++;
assoc_iterator next(vec);
pair* p;
while ( p = next() )
cout << p->name << ": " << p->val << "\n";
}
Итераторный тип вроде этого имеет преимущество перед набором функций, которые выполняют ту же работу: у него есть собственные закрытые данные для хранения хода итерации. К тому же обычно существенно, чтобы одновременно могли работать много итераторов этого типа.
Конечно, такое применение объектов для представления итераторов никак особенно с перегрузкой операций не связано. Многие любят использовать итераторы с такими операциями, как first(), next() и last() (первый, следующий и последний).
Пример 10.3. Класс Строка
Написать программу с использованием класса string, в котором производится учет ссылок на строку с целью минимизировать копирование. В качестве констант применяются стандартные символьные строки C++.
Листинг 10.4
#include
#include
class string
{
struct srep
{
char* s; // указатель на данные
int n; // счетчик ссылок
};
srep *p;
public:
string(char *); // string x = "abc"
string(); // string x;
string(string &); // string x = string ...
string& operator=(char *);
string& operator=(string &);
~string();
char& operator[](int i);
friend ostream& operator<<(ostream&, string&);
friend istream& operator>>(istream&, string&);
friend int operator==(string& x, char* s)
{
return strcmp(x.p->s, s) == 0;
}
friend int operator==(string& x, string& y)
{
return strcmp(x.p->s, y.p->s) == 0;
}
friend int operator!=(string& x, char* s)
{
return strcmp(x.p->s, s) != 0;
}
friend int operator!=(string& x, string& y)
{
return strcmp(x.p->s, y.p->s) != 0;
}
};
Конструкторы и деструкторы просты (как обычно):
string::string()
{
p = new srep;
p->s = 0;
p->n = 1;
}
string::string(char* s)
{
p = new srep;
p->s = new char[ strlen(s)+1 ];
strcpy(p->s, s);
p->n = 1;
}
string::string(string& x)
{
x.p->n++;
p = x.p;
}
string::~string()
{
if (--p->n == 0)
{
delete p->s;
delete p;
}
}
Как обычно, операции присваивания очень похожи на конструкторы. Они должны обрабатывать очистку своего первого (левого) операнда:
string& string::operator=(char* s)
{
if (p->n > 1)
{ // разъединить себя
p-n--;
p = new srep;
}
else if (p->n == 1)
delete p->s;
p->s = new char[ strlen(s)+1 ];
strcpy(p->s, s);
p->n = 1;
return *this;
}
Благоразумно обеспечить, чтобы присваивание объекта самому себе работало правильно:
string& string::operator=(string& x)
{
x.p->n++;
if (--p->n == 0)
{
delete p->s;
delete p;
}
p = x.p;
return *this;
}
Операция вывода задумана так, чтобы продемонстрировать применение учета ссылок. Она повторяет каждую вводимую строку (с помощью операции <<, которая определяется позднее):
ostream& operator<<(ostream& s, string& x)
{
return s << x.p->s << " [" << x.p->n << "]\n";
}
Операция ввода использует стандартную функцию ввода символьной строки:
istream& operator>>(istream& s, string& x)
{
char buf[256];
s >> buf;
x = buf;
cout << "echo: " << x << "\n";
return s;
}
Для доступа к отдельным символам предоставлена операция индексирования. Осуществляется проверка индекса:
void error(char* p)
{
cerr << p << "\n";
exit(1);
}
char& string::operator[](int i)
{
if (i<0 || strlen(p->s)s[i];
}
Головная программа просто немного опробует действия над строками. Она читает слова со ввода в строки, а потом эти строки печатает. Она продолжает это делать до тех пор, пока не распознает строку done, которая завершает сохранение слов в строках, или не встретит конец файла. После этого она печатает строки в обратном порядке и завершается.
main()
{
string x[100];
int n;
cout << "отсюда начнем\n";
for (n = 0; cin>>x[n]; n++)
{
string y;
if (n==100) error("слишком много строк");
cout << (y = x[n]);
if (y=="done") break;
}
cout << "отсюда мы пройдем обратно\n";
for (int i=n-1; 0<=i; i--) cout << x[i];
}
Друзья и Члены. Теперь, наконец, можно обсудить, в каких случаях для доступа к закрытой части определяемого пользователем типа использовать члены, а в каких - друзей. Некоторые операции должны быть членами: конструкторы, деструкторы и виртуальные функции, но обычно это зависит от выбора.
Рассмотрим простой класс X:
class X
{
// ...
X(int);
int m();
friend int f(X&);
};
Внешне не видно никаких причин делать f(X&) другом дополнительно к члену X::m() (или наоборот), чтобы реализовать действия над классом X. Однако член X::m() можно вызывать только для "настоящего объекта", в то время как друг f() может вызываться для объекта, созданного с помощью неявного преобразования типа. Например:
void g()
{
1.m(); // ошибка
f(1); // f(x(1));
}
Поэтому операция, изменяющее состояние объекта, должно быть членом, а не другом. Для определяемых пользователем типов операции, требующие в случае фундаментальных типов операнд lvalue (=, *=, ++ и т.д.), наиболее естественно определяются как члены. И наоборот, если нужно иметь неявное преобразование для всех операндов операции, то реализующая ее функция должна быть другом, а не членом. Это часто имеет место для функций, которые реализуют операции, не требующие при применении к фундаментальным типам lvalue в качестве операндов (+, -, || и т.д.).
Если никакие преобразования типа не определены, то оказывается, что нет никаких существенных оснований в пользу члена, если есть друг, который получает ссылочный параметр, и наоборот. В некоторых случаях программист может предпочитать один синтаксис вызова другому. Например, оказывается, что большинство предпочитает для обращения матрицы m запись m.inv().
Конечно, если inv() действительно обращает матрицу m, а не просто возвращает новую матрицу, обратную m, ей следует быть другом.
При прочих равных условиях выбирайте, чтобы функция была членом: никто не знает, вдруг когда-нибудь кто-то определит операцию преобразования.
Невозможно предсказать, потребуют ли будущие изменения изменить статус объекта. Синтаксис вызова функции члена ясно указывает пользователю, что объект можно изменить; ссылочный параметр является далеко не столь очевидным. Кроме того, выражения в члене могут быть заметно короче выражений в друге. В функции друге надо использовать явный параметр, тогда как в члене можно использовать неявный this. Если только не применяется перегрузка, имена членов обычно короче имен друзей.
Композиция классов. Включение нескольких объектов других классов в данный класс с тем, чтобы данный класс мог брать нужные сведения из других классов называется композицией.
Пример 10.4. Реализация принципа композиции классов
Написать программу для вывода на экран определенных значений.
Листинг 10.5
#include <iostream.h>
class One
{
public:
One(int = 1);//конструктор по умолчанию
void print();
private:
int a;
};
class Two
{
public:
Two(int = 1);//конструктор по умолчанию
void print();
private:
int a;
};
class OnePlusTwo_Three
{
public:
OnePlusTwo_Three(int=1, int=1);//конструктор по умолчанию
void print();
private:
One o;
Two t;
};
One::One(int a1)
{
a = a1;
}
void One::print()
{
cout << a << endl;
}
void Two::print()
{
cout << a << endl;
}
Two::Two(int a2)
{
a = a2;
}
OnePlusTwo_Three::OnePlusTwo_Three(int a1, int a3):o(a1),t(a3)
{
}
void OnePlusTwo_Three::print()
{
o.print();
t.print();
}
main()
{
OnePlusTwo_Three opt(6,8);
opt.print();
return 0;
}
В этой программе определено три класса: One, Two, OnePlusTwo_Three.
Композиция классов в этом примере реализована в том, что мы включили под директивой private в классе OnePlusTwo_Three, два объекта классов: Two t, One o. А также посмотрев на определение конструктора класса OnePlusTwo_Three мы видим, что он содержит параметры, помогающие определить конструкторы классов One и Two.
Использование дружественных функций и указателя this. Дружественные функции определяются вне области действия этого класса, но имеют право доступа к закрытым элементам private данного класса. Функция или класс в целом могут быть объявлены другом (friend) другого класса.
Дружественные функции используются для повышения производительности.
Чтобы объявить функцию как друга (friend) класса, перед ее прототипом в описании класса ставится ключевое слово friend. Чтобы объявить класс ClassTwo как друга класса ClassOne, запишите объявление в форме friend ClassTwo в определении класса ClassOne.
Дружественность требует разрешения, то есть чтобы класс B стал другом класса A, класс A должен объявить, что класс B - его друг. Таким образом дружественность не обладает ни свойством симметричности, ни свойством транзитивности, то есть если класс A друг класса B , а класс B - друг класса C, то от сюда не следует, что класс B друг класса A, что класс C друг класса B, или что класс A - друг класса C.
Ниже приведенная программа демонстрирует объявление и использование дружественной функции setX для установки закрытого элемента данных x класса count. Заметим, что объявление friend появляется первым (по соглашению) в объявлении класса, даже раньше объявления закрытых функций элментов.
Пример 10.5. Реализация дружественности классов
Написать программу, выводящую на экран целое значение.
Листинг 10.6
#include <iostream.h>
class One
{
friend class Two;
public:
One(int = 1);
private:
int a;
};
class Two
{
public:
int ret_value(One o1, int v);
};
One::One(int a1)
{
a = a1;
}
int Two::ret_value(One o1, int v)
{
o1.a = v;
return v;
}
main()
{
Two t;
One o1;
int v, r;
cout << "Enter the number what you want to see later! " << endl;
cin >> v;
r = t.ret_value(o1,v);
cout << endl;
cout << r << endl;
return 0;
}
В этой программе класс Two является другом для класса One. Поэтому, даже если мы определяем объект класса One внутри функции описываемой в классе Two, то мы все равно имеем право на доступ к закрытым членам класса One. По этой причине, иногда говорят, что дружественность нарушает объектно-ориентированный подход.
Когда функция элемент ссылается на другой элемент какого-то объекта данного класса, имеется ввиду соответствующий объект. Это происходит благодаря тому, что каждый объект сопровождается указателем на самого себя - называемым указателем this - это неявный аргумент во всех ссылках на элементы внутри этого объекта. Указатель this можно использовать также и явно. Каждый объект может определить свой собственный адрес с помощью ключевого слова this.
Указатель this неявно используется для ссылки как на данные элементы так и на функции - элементы объекта. Тип указателя this зависит от типа объекта и от того, объявлена ли функция элемент, в которой используется this, как const. Например, в не константной функции-элементе класса Employee указатель this имеет тип Employee *const(константный указатель на объект Employee). В константной функции-элементе класса Employee указатель this имеет тип const Employee *const(константный указатель на объект Employee, который тоже константный).
Пример 10.6. Использование указателя this
Написать программу, которая демонстрирует явное использование указателя this, чтобы дать возможность функции элементу класса Test печатать закрытую переменную x объекта Test.
Листинг 10.7
#include <iostream.h>
class Test
{
public:
Test (int = 0);
void print() const;
private:
int x;
};
Test::Test(int a) {x = a;}//конструктор
void Test::print() const
{
cout <<”x = “<< x << endl <<”this->x = “ << this -> x<<endl <<”(*this).x=”<<(*this).x<<endl;
}
main()
{
Test a(12);
a.print();
return 0;
}
Перегрузка операций. Любая операция, определенная в C++, может быть перегружена для созданного класса. Это делается с помощью функций специального вида, называемых функциями-операциями (операторными функциями). Общий вид такой функции:
возвращаемый_тип operator # (список параметров)
{
тело функции
}
где вместо знака # ставится знак перегруаемой операции.
Функция-операция может быть реализована либо как функция класса, либо как внешняя (обычно дружественная) функция. В первом случае количество параметров у функции-операции на единицу меньше, так как первым операндом при этом считается сам объект, вызвавший данную операцию.
Например, два варианта перегрузки операции сложения для класса Point: первый вариант - в форме метода класса:
class Point
{
double x. у: public:
//...
Point operator +(Point&);
};
Point Point::operator +(Point& p)
{
return Point(x + p.x, у + р.у);
}
Второй вариант - в форме внешней глобальной функции, причем функция, как правило, объявляется дружественной классу, чтобы иметь доступ к его закрытым элементам:
class Point
{
double x, у;
public:
//. . .
friend Point operator +(Point&. Point&);
};
Point operator +(Point& p1. Points p2)
{
return Point(p1.x + p2.x. p1.у + p2.y);
}
Независимо от формы реализации операции «+» можно теперь написать:
Point pl(0, 2), р2(-1, 5);
Point рЗ = p1 + р2;
Встретив выражение pi + р2, компилятор в случае первой формы перегрузки вызовет метод p1.operator + (p2), а в случае второй формы перегрузки - глобальную функцию operator + (p1, р2).
Результатом выполнения данных операторов будет точка рЗ с координатами х = -1, у = 7.
Итак, если операция может перегружаться как внешней функцией, так и функцией класса, следует использовать перегрузку в форме метода класса, если нет каких-либо причин, препятствующих этому. Например, если первый аргумент (левый операнд) относится к одному из базовых типов (к примеру, int), то перегрузка операции возможна только в форме внешней функции.
Перегрузка операций инкремента (декремента). Операция инкремента (декремента) имеет две формы: префиксную и постфиксную. Для первой формы сначала изменяется состояние объекта в соответствии с данной операцией, а затем он (объект) используется в том или ином выражении. Для второй формы объект используется в том состоянии, которое у него было до начала операции, а потом уже его состояние изменяется.
Чтобы компилятор смог различить эти две формы операции инкремента (декремента), для них используются разные сигнатуры, например:
Point& operator ++(); // префиксный инкремент
Point operator ++(int); // постфиксный инкремент
Реализация данных операций на примере класса Point:
Point& Point::operator ++()
{
x++;
y++;
return *this;
}
Point Point::operator ++(int)
{
Point old = *this;
X++;
y++;
return old;
}
В префиксной операции осуществляется возврат результата по ссылке. Это предотвращает вызов конструктора копирования для создания возвращаемого значения и последующего вызова деструктора. В постфиксной операции инкремента возврат по ссылке не подходит, поскольку необходимо вернуть первоначальное состояние объекта, сохраненное в локальной переменной old. Таким образом, префиксный инкремент является более эффективной операцией, чем постфиксный инкремент.
Использование префиксного инкремента (декремента) для параметра цикла for дает более эффективный программный код.
Перегрузка операции присваивания. Если не определить эту операцию в некотором классе, то компилятор создаст операцию присваивания по умолчанию, которая выполняет поэлементное копирование объекта. В этом случае возможно появление тех же проблем, которые возникают при использовании конструктора копирования по умолчанию. Поэтому если в классе требуется определить конструктор копирования, то его верной спутницей должна быть перегруженная операция присваивания, и наоборот.
Операция присваивания может быть определена только в форме метода класса и она, в отличие от всех остальных операций, не наследуется.
Например, для класса Man перегрузку операции присваивания можно определить следующим образом:
// Man.h (интерфейс класса) class Man
{
public:
// . . .
Man& operator =(const Man&): //операция присваивания private:
char* pName;
II . . .
};
// Маn.срр (реализация класса) // ...
Man& Man::operator =(const Man& man)
{
if (this == &man) return *this; // проверка на самоприсваивание
delete [] pName; //уничтожить предыдущее значение
pName = new char[strlen(man.pName) + 1];
strcpy(pName. man.pName);
birth_year = man.birth_year;
pay = man.pay;
return *this;
}
Моменты реализации операции присваивания:
- убедитесь, что не выполняется присваивание вида х = х. Если левая и правая части ссылаются на один и тот же объект, то делать ничего не надо. Если не перехватить этот особый случай, то следующий шаг уничтожит значение, на которое указывает pName, еще до того, как оно будет скопировано;
- удалите предыдущие значения полей в динамически выделенной памяти;
- выделите память под новые значения полей;
- скопируйте в нее новые значения всех полей;
- возвратите значение объекта, на которое указывает this (то есть *this).
Статические элементы класса. До сих пор одноименные поля разных объектов одного и того же класса были уникальными. Но что делать, если необходимо создать переменную, значение которой будет общим для всех объектов конкретного класса? Если воспользоваться глобальной переменной, то это нарушит принцип инкапсуляции данных. Модификатор static как раз и позволяет объявить поле в классе, которое будет общим для всех экземпляров класса. Кроме объявления статического поля в классе, необходимо также дать его определение в глобальной области видимости программы, например:
class Coo
{
static int count: // объявление в классе // остальной код
};
int Coo::count = 1; // определение и инициализация
// int Coo::count; // по умолчанию инициализируется нулем
Аналогично статическим полям могут быть объявлены и статические методы класса (с модификатором static). Они могут обращаться непосредственно только к статическим полям и вызывать только другие статические методы класса, потому что им не передается скрытый указатель this. Статические методы не могут быть константными (const) и виртуальными (virtual). Обращение к статическим методам производится так же, как к статическим полям - либо через имя класса, либо, если хотя бы один объект класса уже создан, через имя объекта.
Пример 10.7. Класс треугольников
Для некоторого множества заданных координатами своих вершин треугольников найти треугольник максимальной площади (если максимальную площадь имеют несколько треугольников, то найти первый из них). Предусмотреть возможность перемещения треугольников и проверки включения одного треугольника в другой.
Для реализации этой задачи составить описание класса треугольников на плоскости. Предусмотреть возможность объявления в клиентской программе (main) экземпляра треугольника с заданными координатами вершин. Предусмотреть наличие в классе методов, обеспечивающих: 1) перемещение треугольников на плоскости; 2) определение отношения > для пары заданных треугольников (мера сравнения - площадь треугольников); 3) определение отношения включения типа: «Треугольник 1 входит в (не входит в) Треугольник 2».
Программа должна содержать меню, позволяющее осуществить проверку всех методов класса.
Применим гибридный подход: разработку главного клиента main( ) проведем по технологии функциональной декомпозиции, а функции-серверы, вызываемые из main(), будут использовать объекты.
Начнем с выявления основных понятий/классов. Первый очевидный класс Triangle необходим для представления треугольников (через три точки, задающие его вершины). Точку на плоскости представим с помощью пары вещественных чисел, задающих координаты точки по осям х и у.
Таким образом, с понятием точки связывается как минимум пара атрибутов. В принципе, этого уже достаточно, чтобы подумать о создании класса Point. Если же представить, что можно делать с объектом типа точки - например, перемещать ее на плоскости или определять ее вхождение в заданную фигуру, - то становится ясным, что такой класс Point будет полезен.
Итак, объектно-ориентированная декомпозиция дала нам два класса: Triangle и Point.
Если класс В является «частным случаем» класса А, то говорят, что В is а А (напри мер, класс треугольников есть частный вид класса многоугольников: Triangle is a Polygon).
Если класс А содержит в себе объект класса В, то говорят, что A has а В (например, класс треугольников может содержать в себе объекты класса точек: Triangle has a Point).
Порядок перечисления вершин особо важен, так как в дальнейшем, решая подзадачу определения отношения включения одного треугольника в другой, мы будем рассматривать стороны треугольника как векторы. Условимся, что вершины треугольника перечисляются в направлении по часовой стрелке.
Займемся теперь основным клиентом - main(). Здесь мы применяем функциональную декомпозицию, или технологию нисходящего проектирования. В соответствии с данной технологией основной алгоритм представляется как последовательность нескольких подзадач. Каждой подзадаче соответствует вызываемая серверная функция. На начальном этапе проектирования тела этих функций могут быть заполнены «заглушками» - отладочной печатью. Если при этом в какой-то серверной функции окажется слабое сцепление, то она в свою очередь разбивается на несколько подзадач.
То же самое происходит и с классами, используемыми в программе: по мере реализации подзадач они пополняются необходимыми для этого методами. Такая технология облегчает отладку и поиск ошибок, сокращая общее время разработки программы.
На первом этапе мы напишем код для начального представления классов Point и Triangle, достаточный для того, чтобы создать несколько объектов типа Triangle и реализовать первый пункт меню - вывод всех объектов на экран.
Этап 1
///////////////////////////////////////////////////
// Проект Task1_2
/////////Point.h #ifndef POINT_H #define POINT_H
class Point
{
public:
// Конструктор
Point(double _x = 0. double _y = 0) : x(_x), y(_y) {}
// Другие методы
void Show() const; public:
double x, y:
};
#endif /* POINT_H */
///////////////////////////////////////////////////
// Point.cpp
#include <iostream>
#include "Point.h"
using namespace std;
void Point::Show() const
{
cout « " (" «x « ","« у <<")";
}
///////////////////////////////////////////////////
Triangle.h #ifndef TRIANGLE_H #define TRIANGLE_H
#include "Point.h"
class Triangle
{
public:
Triangle(Point, Point, Point, const char*); // конструктор
Triangle(const char*); // конструктор пустого (нулевого) треугольника
~Triangle( ); // деструктор
Point Get_vl() const
{
return vl;
} // Получить значение vl
Point Get_v2() const
{
return v2;
} // Получить значение v2
Point Get_v3() const
{
return v3;
} // Получить значение v3
char* GetName( ) const
{
return name;
} // Получить имя объекта
void Show() const; // Показать объект
void ShowSideAndArea() const; // Показать стороны и площадь объекта
public:
static int count; // кол-во созданных объектов
private:
char* objID; // идентификатор объекта char* name; // наименование треугольника Point vl, v2, v3; // вершины double a; // сторона, соединяющая vl и v2 double b; // сторона, соединяющая v2 и v3
double с; // сторона, соединяющая vl и v3
};
#endif /* TRIANGLE_H */
////////////////////////////////////////////////////
//Triangle.cpp
// Реализация класса Triangle
#include <math.h>
#include <iostream>
#inc1ude <iomanip>
#include <cstring>
//#include "CyrIOS.h". // for Visual C++ 6.0
#include "Triangle.h"
using namespace std;
// Конструктор
Triangle: :Triangle(Point _v1. Point _v2, Point _v3, const char* ident)
: vl'(_vl), v2(_v2). v3(_v3)
{
char buf[16];
objID = new char[strlen(ident) + 1];
strcpy(objID. ident);
count++;
sprintf(buf. "Треугольник %d", count);
name = new char[strlen(buf) + 1];
strcpy(name, buf);
a = sqrt((vl.x - v2.x) * (vl.x - v2.x) + (vl.y - v2.y) * (vl.y - v2.y));
b = sqrt((v2.x - v3.x) * (v2.x - v3.x) + (v2.y - v3.y) * (v2.y - v3.y));
с = sqrt((vl.x - v3.x) * (vl.x - v3.x) + (vl.y - v3.y) * (vl.y - v3.y));
cout « "Constructor_1 for: " « objID « " (" « name « ")" « endl; // отладочный вывод
}
// Конструктор пустого (нулевого) треугольника Triangle::Triangle(const char* ident)
{
char buf[16];
objID = new char[strlen(ident) +1];
strcpy(objID. ident);
count++;
sprintf(buf, "Треугольник %d", count);
name = new char[strlen(buf) +1];
strcpy(name, buf);
a = b = с = 0;
cout « "Constructor_2 for: " « objID « " (" « name « ")" « endl; // отладочный вывод
}
// Деструктор
Triangle::~Triangle()
{
cout « "Destructor for: " « objID « endl;
delete [] objID;
delete [] name;
}
// Показать объект
void Triangle::Show() const
{
cout « name «":";
vl.Show(): v2.Show(): v3.Show();
cout « endl;
}
// Показать стороны и площадь объекта
void Triangle::ShowSideAndArea() const
{
double p = (a + b + c) / 2;
double s = sqrt(p * (p - a) * (p - b) * (p - c);
cout « " " « endl;
cout « name « ":";
cout.precision(4);
cout « " a= " « setw(5) «a;
cout « ", b= " « setw(5) « b;
cout « ", c= " « setw(5) « c;
cout « ":\ts= " « s « endl;
}
////////////////////////////////////////////////
// Main.cpp
#include <iostream>
#include "Triangle.h"
//#include "CyrIOS.h" // for Visual C++ 6.0
using namespace std;
int Menu();
int GetNumber(int, int);
void ExitBack();
void Show(Triangle* [], int);
void Move(Triangle* [], int);
void FindMax(Triangle* [], int);
void IsIncluded(Triangle* [], int);
// Инициализация глобальных переменных
int Triangle::count =0;
// главная функция
int main()
{
// Определения точек
Point pl(0, 0); Point p2(0.5, 1);
Point p3(l, 0); Point p4(0, 4.5);
Point p5(2. 1); Point p6(2. 0);
Point p7(2, 2); Point p8(3, 0);
// Определения треугольников
Triangle triaA(pl, p2, рЗ, "triaA");
Triangle triaB(pl. p4, p8, "triaB");
Triangle triaC(pl. p5. p6. "triaC");
Triangle triaD(pl. p7. p8. "triaD");
// Определение массива указателей на треугольники
Triangle* pTria[] = { &triaA, &triaB. &triaC, &triaD }; int n = sizeof (pTria) / sizeof (pTria[0]);
// Главный цикл
bool done = false: whfie (!done)
{
switch (Menu())
{
case 1: Show(pTria, n); break:
case 2: Move(pTria, n); break;
case 3: FindMax(pTria, n); break;
case 4: IsIncluded(pTria, n); break;
case 5: cout « "Конец работы." « endl;
done = true; break;
}
}
return 0;
}
II вывод меню
int Menu()
{
cout « "\n===== Главное меню =====" « endl;
cout « "1 - вывести все объекты\t 3 - найти максимальный" « endl;
cout « "2 - переместить\t\t 4 - определить отношение включения" « endl;
cout « "\t\t 5 - выход" « endl;
return GetNumber(1, 5);
}
// ввод целого числа в заданном диапазоне
int GetNumber(int min, int max)
{
int number = min - 1; while (trye)
{
cin » number;
if ((number >= min) && (number <= max) && (cin.peek() == '\n'));
break;
else
{
cout « "Повторите ввод (ожидается число от " « min « " до " « max « "):" « endl; cin.clear();
while (cin.get() != '\n') {};
}
}
return number;
}
// возврат в функцию с основным меню
void ExitBack()
{
cout « "Нажмите Enter." « endl;
cin.get(); cin.get();
}
// вывод всех треугольников
void Show(Triangle* p_tria[]. int k)
{
cout « "=== Перечень треугольников ===" « endl;
for (int i = 0; i < k: ++i) p_tria[i]->Show();
for (i = 0; i < k; ++i)
p_tria[i]->ShowSideAndArea();
ExitBack();
II перемещение
void Move(Triangle* p_tria[], int k)
{
cout « "======= Перемещение ======" « endl;
// здесь будет код функции...
ExitBack();
}
// поиск максимального треугольника
void FindMax(Triangle* p_tria[], int k)
{
cout « "= Поиск максимального треугольника =" « endl;
// здесь будет код функции...
ExitBack();
}
// определение отношения включения
void Islncluded(Triangle* p_tria[], int k)
{
cout « "===== Отношение включения =====" « endl;
// здесь будет код функции...
ExitBack();
}
// конец проекта Task1_2
//////////////////////////////////////////////
Рекомендуем вам обратить внимание на следующие моменты в проекте Task1_2.
1. Класс Point (файлы Point.h, Point.cpp).
Реализация класса Point пока что содержит единственный метод Show(), назначение которого очевидно: показать объект типа Point на экране. Здесь следует заметить, что при решении реальных задач в какой-либо графической оболочке метод Show() действительно нарисовал бы нашу точку, да еще в цвете. Но мы-то изучаем «чистый» C++, так что придется удовольствоваться текстовым выводом на экран основных атрибутов точки - ее координат.
2. Класс Triangle (файлы Triangle.h, Triangle.cpp).
Назначение большинства полей и методов очевидно из их имен и комментариев.
Поле static int count играет роль глобального счетчика создаваемых объ ектов; мы сочли удобным в конструкторах генерировать имена треугольни ков автоматически: «Треугольник 1», «Треугольник 2» и т. д., используя текущее значение count (возможны и другие способы именования тре угольников).
Поле char* objID избыточно для решения нашей задачи - оно введено исключительно для целей отладки и обучения; вскоре вы увидите, что благодаря отладочным операторам печати в конструкторах и деструкторе удобно наблюдать за созданием и уничтожением объектов.
Метод ShowSideAndArea() введен также только для целей отладки, - убедившись, что стороны треугольника и его площадь вычисляются правильно (с помощью калькулятора), в дальнейшем этот метод можно удалить.
Конструктор пустого (нулевого) треугольника предусмотрен для создания временных объектов, которые могут модифицироваться с помощью присваивания.
Метод Show() - см. комментарий выше по поводу метода Show() в классе Point. К сожалению, здесь нам тоже не удастся нарисовать треугольник на экране; вместо этого печатаются координаты его вершин.
3. Основной модуль (файл Main.cpp).
Инициализация глобальных переменных: обратите внимание на оператор int Triangle::count = 0: - если вы забудете это написать, компилятор очень сильно обидится.
Функция main ():
- определения восьми точек p1,..., р8 выбраны произвольно, но так, чтобы из них можно было составить треугольники;
- определения четырех треугольников сделаны тоже произвольно, впоследствии на них будут демонстрироваться основные методы класса; однако не забывайте, что вершины в каждом треугольнике должны перечисляться по часовой стрелке;
- далее определяются массив указателей Triangle* pTria[] с адресами объявленных выше треугольников и его размер n; в таком виде удобно передавать адрес pTria и величину n в вызываемые серверные функции;
- главный цикл функции довольно прозрачен и дополнительных пояснений не требует.
Функция Menu () - после вывода на экран списка пунктов меню вызывается функция GetNumber(), возвращающая номер пункта, введенный пользователем с клавиатуры.
Функция Show() пpocто выводит на экран перечень всех треугольников. В завершение вызывается функция ExitBack(), которая обеспечивает заключительный диалог с пользователем после обработки очередного пункта меню.
Остальные функции по обработке оставшихся пунктов меню выполнены в виде заглушек, выводящих только наименование соответствующего пункта.
Тестирование и отладка первой версии программы
После компиляции и запуска программы вы должны увидеть на экране следующий текст:
Constructor_1 for: triaA (Треугольник 1)
Constructor_1 for: tnaB (Треугольник 2)
Constructor_1 for: triaC (Треугольник 3)
Constructor_1 for: triaD (Треугольник 4)
=============== Главное меню===============
- вывести все объекты 3 - найти максимальный
- переместить 4 - определить отношение включения
5 - выход
Введите с клавиатуры цифру 12. Программа выведет:
1 ======= Перечень треугольников ========
Треугольник 1: (0. 0) (0.5. 1) (1, 0)
Треугольник 2: (0, 0) (0. 4.5) (3. 0)
Треугольник 3: (0. 0) (2. 1) (2. 0)
Треугольник 4: (0. 0) (2. 2) (3, 0)
Треугольник 1: а=1.118. b=1.118, с= 1: s=0.5
Треугольник 2: а=4.5, b=5.408, с=3: s= 6.75
Треугольник 3: а=2.236, b=1, с=2: s= 1
Треугольник 4: а=2.828, b=2.236, с=3: s=3
Нажмите Enter.
После ввода числовой информации всегда подразумевается нажатие клавиши Enter. Выбор первого пункта меню проверен. Нажмите Enter. Программа выведет:
=========== Главное меню ===========
Теперь проверим выбор второго пункта меню. Введите с клавиатуры цифру 2. На экране должно появиться:
2
================== Перемещение ===============
Нажмите Enter.
Выбор второго пункта проверен. Нажмите Enter. Программа выведет:
============ Главное меню =============
Теперь проверим ввод ошибочного символа. Введите с клавиатуры любой буквенный символ, например w, и нажмите Enter. Программа должна выругаться:
Повторите ввод (ожидается число от 1 до 5):
Проверяем завершение работы. Введите цифру 5. Программа выведет:
5
Конец работы.
Destructor for: triaD
Destructor for: triaC
Destructor for: triaB
Destructor for: triaA
Тестирование закончено. Обратите внимание на то, что деструкторы объектов вызываются в порядке, обратном вызову конструкторов.
Продолжим разработку программы. На втором этапе мы добавим в классы Point и Triangle методы, обеспечивающие перемещение треугольников, а в основной модуль - реализацию функции Move(). Кроме этого, в классе Triangle мы удалим метод ShowSideAndArea(), поскольку он был введен только для целей отладки и свою роль уже выполнил.
Этап 2
Внесите следующие изменения в тексты модулей проекта.
1. Модуль Point.h: добавьте сразу после объявления метода Show() объявление операции-функции «+=», которая позволит нам впоследствии реализовать метод перемещения Move() в классе Triangle:
void operator +=(Point&);
2. Модуль Point.cpp. Добавьте код реализации данной функции:
void Point::operator +=(Point& p)
{
x += p.x: у += р.у:
}
3. Модуль Triangle.h.
Удалите объявление метода ShowSideAndArea().
Добавьте объявление метода:
void Move(Point);
4. Модуль Triangle.cpp. Удалите метод ShowSideAndArea().
Добавьте код метода Move():
// Переместить объект на величину (dp.x. dp.у) void Triangle: :Move(Point dp)
{
vl += dp;
v2 += dp;
v3 += dp;
}
5. Модуль Main.cpp.
В список прототипов функций в начале файла добавьте сигнатуру:
double GetDouble();
Добавьте в файл текст новой функции GetDouble() либо сразу после функции Show(), либо в конец файла. Эта функция предназначена для ввода вещественного числа и вызывается из функции Move(). В ней предусмотрена защита от ввода недопустимых (например, буквенных) символов аналогично тому, как это решено в функции GetNumber():
// ввод вещественного числа
double GetDouble()
{
double value; while (true)
{
cin » value;
if (cin.peek() == '\n') break;
else
{
cout « "Повторите ввод (ожидается вещественное число):" « endl; cin.clear();
while (cin.get() != '\n') {};
}
}
return value;
}
Замените заглушку функции Move() следующим кодом:
// перемещение
void Move(Triangle* p_tria[]. int k)
{
cout « "========= Перемещение =========" « endl;
cout « "Введите номер треугольника (от 1 до " « к « "): ";
int i = GetNumber(d, k) - 1;
p_tria[i]->Show();
Point dp;
cout « "Введите смещение по х: ";
dp.x = GetDouble(): cout « "Введите смещение по у: ";
dp.у = GetDouble();
p_tria[i]->Move(dp);
cout « "Новое положение треугольника:" « endl;
p_tria[i]->Show();
ExitBack();
}
Выполнив компиляцию проекта, проведите его тестирование аналогично тестированию на первом этапе. После выбора второго пункта меню и ввода данных, задающих номер треугольника, величину сдвига по х и величину сдвига по у, вы должны увидеть на экране примерно следующее:
2
============= Перемещение =============
Введите номер треугольника (от 1 до 4): 1
Треугольник 1: (0. 0) (0.5. 1) (1, 0)
Введите смещение по х: 2.5
Введите смещение по у: -7
Новое положение треугольника:
Треугольник 1: (2.5, -7) (3, -6) (3.5, -7)
Нажмите Enter.
Продолжим разработку программы.
Этап 3
На этом этапе мы добавим в класс Triangle метод, обеспечивающий сравнение треугольников по их площади, а в основной модуль - реализацию функции FindMax(). Внесите следующие изменения в тексты модулей проекта:
1. Модуль Triangle. h: добавьте объявление функции-операции:
bool operator >(const Triangle&) const;
2. Модуль Triangle.cpp: добавьте код реализации функции-операции:
// Сравнить объект (по площади) с объектом tria
bool Triangle:: operator >(const Triangles tria) const
{
double p = (a + b + c) / 2;
double s = sqrt(p * (p - a) * (p - b) * (p - c));
double p1 = (tria a + tria b + tria c) / 2;
double s1 = sqrt(pl * (p1 - tria.a) * (p1 - tria.b) * (pi - tria.c));
if (s > s1) return true;
else
return false;
}
3. Модуль Main.cpp: замените заглушку функции FindMax() следующим кодом:
// поиск максимального треугольника
void FindMaxCTriangle* p_tria[]. int k)
{
cout « "= Поиск максимального треугольника =" « endl;
// Создаем объект triaMax, который по завершении поиска будет
// идентичен максимальному объекту.
// Инициализируем его значением 1-го объекта из массива объектов.
Triangle triaMax("triaMax"):
triaMax = *p_tria[0];
// Поиск
for (int i = 1:" i < 4: ++i) if (*p_tria[i] > triaMax) triaMax = *p_tria[i];
cout « "Максимальный треугольник: " « triaMax.GetName() « endl;
ExitBack();
}
Откомпилируйте программу и запустите. Выберите третий пункт меню. На экране должно появиться:
3
=== Поиск максимального треугольника ==
Constructor_2 for: triaMax (Треугольник 5)
Максимальный треугольник: Треугольник 2
Нажмите Enter.
Как видите, максимальный треугольник найден правильно. Нажмите Enter. Появится текст:
Destructor for: triaB
============ Главное меню==============
- вывести все объекты 3 - найти максимальный
- переместить 4 - определить отношение включения
5 - выход
Чтобы завершить работу, введите цифру 5 и нажмите Enter. На передний план выскочит диалоговая панель с жирным белым крестом на красном кружочке и с сообщением об ошибке:
Debug Assertion Failed!
Program: C:\.. . . MAIN.EXE File: dbgdel.cpp Line 47
Программа выведет на экран следующее:
5
Конец работы.
Destructor for: triaD
Destructor for: triaC
Destructor for: ННННННННННээээЭЭЭЭЭЭЭЭЭЭО
В предыдущем выводе нашей программы после того как функция FindMax() выполнила основную работу и вывела на экран сообщение
Максимальный треугольник: Треугольник 2
программа пригласила пользователя нажать клавишу Enter. Это приглашение выводится функцией ExitBack(). А вот после нажатия клавиши Enter на экране появился текст:
Destructor for: triaB
после которого опять было выведено главное меню.
Значит, деструктор для объекта triaB был вызван в момент возврата из функции FindMax(). Внутри функции объявлен объект triaMax, и мы даже видели работу его конструктора:
Constructor_2 for: triaMax (Треугольник 5)
А где же вызов деструктора, который по идее должен произойти в момент возврата из функции FindMax()? Объект triaMax после своего объявления неоднократно модифицируется с помощью операции присваивания. Последняя такая модификация происходит в цикле, причем объекту triaMax присваивается значение объ- екта triaB. А теперь давайте вспомним, что если мы не перегрузили операцию присваивания для некоторого класса, то компилятор сделает это за нас, но в такой «операции присваивания по умолчанию» будут поэлементно копироваться все поля объекта. При наличии же полей типа указателей возможны проблемы, что мы и получили.
В поля objID и name объекта triaMax были скопированы значения одноименных полей объекта triaB. В момент выхода из функции FindMax() деструктор объекта освободил память, на которую указывали эти поля. А при выходе из основной функции main() деструктор объекта triaB попытался еще раз освободить эту же память. Это делать нельзя, потому что этого делать нельзя никогда.
Нужно добавить в класс Triangle перегрузку операции присваивания, а заодно и конструктор копирования.
Внесите следующие изменения в тексты модулей проекта:
1. Модуль Triangle.h.
Добавьте объявление конструктора копирования:
Triangle(const Triangle&); // конструктор копирования
Добавьте объявление операции присваивания:
Triangle& operator =(const Triangle&);
2. Модуль Triangle. cpp.
Добавьте реализацию конструктора копирования:
// Конструктор копирования
Triangle::Triangle(const Triangle& tria): vl(tria.vl), v2(tria.v2),
v3(tria.v3)
{
cout « "Copy constructor for: " « tria.objID « endl ; // отладочный вывод
objID = new char[strlen(tria.objID) + strlen(копия)") + 1];
strcpy(objID, tria.objID): strcat(objID, "(копия)");
name = new char[strlen(tria.name) +1]: strcpy(name. tria.name); a = tria.a; b = tria.b; с = tria.с;
}
Добавьте реализацию операции присваивания:
// Присвоить значение объекта tria
Triangle& Triangle::operator =(const Triangle& tria)
{
cout « "Assign operator: " « objID « " = " « tria.objID « endl; // отладочный вывод
if (&tria == this) return *this; delete [] name;
name = new char[strlen(tria.name) + 1]; strcpy(name, tria.name);
a = tria.a; b = tria.b; с = tria.с;
return *this;
}
И в конструкторе копирования, и в операторе присваивания перед копированием содержимого полей, на которые указывают поля типа char*, для них выделяется новая память. Обратите внимание, что в конструкторе копирования после переписи поля objID мы добавляем в конец этой строки текст «(копия)». А в операции присваивания это поле, идентифицирующее объект, вообще не затрагивается и остается в своем первоначальном значении. Все это полезно для целей отладки.
Откомпилируйте и запустите программу. Выберите третий пункт меню. На экране должен появиться текст:
3
=== Поиск максимального треугольника ==
Constructor_2 for: triaMax (Треугольник 5)
Assign operator: triaMax = triaA
Assign operator: triaMax = triaB
Максимальный треугольник: Треугольник 2
Нажмите Enter.
Обратите внимание на отладочный вывод операции присваивания. Продолжим тестирование. Нажмите Enter. Программа выведет:
Destructor for: triaMax
============== Главное меню===============
- вывести все объекты 3 - найти максимальный
- переместить4 - определить отношение включения
5 - выход
Обратите внимание на то, что был вызван деструктор для объекта triaMax, а не triaB. Продолжим тестирование. Введите цифру 5. Программа выведет:
5
Конец работы.
Destructor for: triaD
Destructor for: triaC
Destructor for: triaB
Destructor for: triaA
Осталось теперь решить самую сложную подзадачу - определение отношения включения одного треугольника в другой.
Этап 4
Из многочисленных подходов к решению этой подзадачи наш выбор остановился на алгоритме, в основе которого лежит определение относительного положения точки и вектора на плоскости1. Вектор - это направленный отрезок прямой линии, начинающийся в точке beg_p и заканчивающийся в точке end_p. При графическом изображении конец вектора украшают стрелкой. Теперь призовите ваше пространственное воображение или вооружитесь карандашом и бумагой, чтобы проверить следующее утверждение. Вектор (beg_p, end_p) делит плоскость на пять непересекающихся областей:
все точки слева от воображаемой бесконечной прямой1, на которой лежит наш вектор (область LEFT),
все точки справа от воображаемой бесконечной прямой, на которой лежит наш вектор (область RIGHT),
все точки на воображаемом продолжении прямой назад от точки beg_p в бесконечность (область BEHIND),
4) все точки на воображаемом продолжении прямой вперед от точки end_p в бесконечность (область AHEAD),
5) все точки, принадлежащие самому вектору (область BETWEEN).
Для выяснения относительного положения точки, заданной некоторым объектом класса Point, добавим в класс Point перечисляемый тип:
enum ORIENT { LEFT. RIGHT. AHEAD. BEHIND, BETWEEN }:
а также метод C1assify(beg_p, end_p), возвращающий значение типа ORIENT для данной точки относительно вектора (beg_p, end_p).
Обладая этим мощным методом, совсем нетрудно определить, находится ли точка внутри некоторого треугольника. Мы договорились перед началом решения задачи, что треугольники будут задаваться перечислением их вершин в порядке изображения их на плоскости по часовой стрелке. То есть каждая пара вершин образует вектор, и эти векторы следуют один за другим по часовой стрелке. При этом условии некоторая точка находится внутри треугольника тогда и только тогда, когда ее ориентация относительно каждой вектора-стороны треугольника имеет одно из двух значений: либо RIGHT, либо BETWEEN. Эту подзадачу будет решать метод InTriangle() в классе Point.
Изложим по порядку, какие изменения нужно внести в тексты модулей. 1. Модуль Point.h.
Добавьте перед объявлением класса Point объявление нового типа ORIENT, а также упреждающее объявление типа Triangle, чтобы имя типа Triangle было известно компилятору в данной единице трансляции, так как оно используется в сигнатуре метода InTriangle().:
enum ORIENT
{
LEFT. RIGHT. AHEAD, BEHIND, BETWEEN
};
class Triangle;
Добавьте внутри класса Point объявления функций:
Point operator +(Point&);
Point operator -(Point&);
double Length() const; // определяет длину вектора точки в полярной системе координат
ORIENT Classify(Point&, Point&) const; // определяет положение точки относительно вектора, заданного двумя точками bool InTriangle(Triangle&) const; // определяет, находится ли точка внутри треугольника
Функция-операция «-» и метод Length() будут использованы при реализации метода Classify(), а функция-операция «+» добавлена для симметрии. Метод Classify(), в свою очередь, вызывается из метода InTriangle(). 1. Модуль Point.cpp.
Добавьте после директивы #include <iostream> директиву #include <math.h>.
Она необходима для использования функции sqrt(x) из математической библиотеки C++ в алгоритме метода Length().
Добавьте после директивы #include «Point. h» директиву #include «Triangle. h».
Последняя необходима в связи с использованием имени класса Triangle в данной единице трансляции.
Добавьте реализацию функций-операций:
Point Point::operator +(Point& p)
{
return Point(x + p.x, у + р.у);
}
Point Point::operator -(Points p)
{
return Point(x - p.x, у - p.у);
}
Добавьте реализацию метода Length():
double Point::Length() const
{
return sqrt(x*x + y*y);
}
Добавьте реализацию метода Classify():
ORIENT Point::Classify(Point& beg_p. Points end_p) const
{
Point p0 = *this; Point a = end_p - beg_p; Point b = p0 - beg_p; double sa = a.x * b.y - b.x * a.y;
if (sa > 0.0) return LEFT;
if (sa < 0.0) return RIGHT;
if ((a.x * b.x < 0.0) || (a.y * b.y < 0.0)) return BEHIND;
if (a. Length О < b. Length()) return AHEAD;
return BETWEEN;
}
Аргументы передаются в функцию по ссылке - это позволяет избежать вызова конструктора копирования.
Добавьте реализацию метода InTriangle():
bool Point::InTriangle(Triangle& tria) const
{
ORIENT orl = Classify(tria.Get_vl(), tria.Get_v2O); ORIENT or2 = Classify(tria.Get_v2(), tria.Get_v3O): ORIENT огЗ = Classify(tria.Get_v3(), tria.Get_vl());
if ((orl == RIGHT || orl == BETWEEN)
&& (or2 == RIGHT || or2 == BETWEEN)
&& (оrЗ == RIGHT || оrЗ == BETWEEN)) return true;
else return false;
}
2. Модуль Triangle.h: добавьте в классе Triangle объявление дружественной функции (все равно, в каком месте):
friend bool TriaInTna(Triangle, Triangle); // Определить, входит ли один треугольник во второй
3. Модуль Triangle.cpp: добавьте в конец файла реализацию внешней дружественной функции:
// Определить, входит ли треугольник trial в треугольник tria2
bool TriaInTria(Triangle trial, Triangle tria2)
{
Point v1 = trial.Get_v1();
Point v2 = trial.Get_v2();
Point v3 = trial.Get_v3();
return (vl.InTriangle(tria2) && v2.InTriangle(tria2) && v3.InTriangle(tria2));
return true;
}
Результат, возвращаемый функцией, основан на проверке вхождения каждой вершины первого треугольника (trial) во второй треугольник (tria2).
4. Модуль Main.cpp: замените заглушку функции IsIncluded() следующим кодом:
// определение отношения включения
void IsIncluded(Triangle* p_tria[]. int k)
{
cout « "==== Отношение включения ====" « endl;
cout « "Введите номер 1-го треугольника (от 1 до " « к « "): ";
int i1 = GetNumber(1. к) - 1;
cout « "Введите номер 2-го треугольника (от 1 до " « к «"):";
int i2 = GetNumber(1. к) - 1;
if (TriaInTria(*p_tria[il], *p_tria[i2]))
cout « p_tria[i1]->GetName() « " - входит в - " « p_tria[i2]->GetName() « endl;
else
cout « p_tria[i1]->GetName() « " - не входит в - " « p_tria[i2]->GetName() « endl; ExitBack();
}
Модификация проекта завершена. Откомпилируйте и запустите программу. Выберите четвертый пункт меню. Следуя указаниям программы, введите номера сравниваемых треугольников, например 1 и 2. Вы должны получить следующий результат:
4
======== Отношение включения ==========
Введите номер 1-го треугольника (от 1 до 4): 1 Введите номер 2-го треугольника (от 1 до 4): 2 Copy constructor for: triaB Copy constructor for: triaA Destructor for: triaA(копия) Destructor for: triaB(копия) Треугольник 1 - входит в - Треугольник 2 Нажмите Enter.
Аппаратура и материалы. Для выполнения лабораторной работы необходим персональный компьютер со следующими характеристиками: процессор Intel Pentium-совместимый с тактовой частотой 800 МГц и выше, оперативная память - не менее 64 Мбайт, свободное дисковое пространство - не менее 500 Мбайт, устройство для чтения компакт-дисков, монитор типа Super VGA (число цветов от 256) с диагональю не менее 15. Программное обеспечение - операционная система Windows2000/XP и выше, среда разработки приложений Microsoft Visual Studio.
Указания по технике безопасности. Техника безопасности при выполнении лабораторной работы совпадает с общепринятой для пользователей персональных компьютеров, самостоятельно не производить ремонт персонального компьютера, установку и удаление программного обеспечения; в случае неисправности персонального компьютера сообщить об этом обслуживающему персоналу лаборатории (оператору, администратору); соблюдать правила техники безопасности при работе с электрооборудованием; не касаться электрических розеток металлическими предметами; рабочее место пользователя персонального компьютера должно содержаться в чистоте; не разрешается возле персонального компьютера принимать пищу, напитки.
Методика и порядок выполнения работы. Перед выполнением лабораторной работы каждый студент получает индивидуальное задание. Защита лабораторной работы происходит только после его выполнения (индивидуального задания). При защите лабораторной работы студент отвечает на контрольные вопросы, приведенные в конце, и поясняет выполненное индивидуальное задание. Ход защиты лабораторной работы контролируется преподавателем. Порядок выполнения работы:
1. Проработать примеры, приведенные в лабораторной работе.
2. Реализовать класс Time.
3. Реализовать класс треугольников.
4. Решить задачу на двумерные массивы согласно своему варианту лабораторной работы №6 с использованием классов.
5. Реализовать класс многочленов и смоделировать операции над ними, принимая во внимание то, что многочлен – это объект, имеющий свойства: коэффициенты и степени.
Содержание отчета и его форма. Отчет по лабораторной работе должен состоять из:
1. Названия лабораторной работы.
2. Цели и содержания лабораторной работы.
3. Ответов на контрольные вопросы лабораторной работы.
4. Формулировки заданий и порядка их выполнения.
Отчет о выполнении лабораторной работы в письменном виде сдается преподавателю.
Вопросы для защиты работы
1. Какова структура программы на объектно-ориентированном языке?
2. Что такое объект ООП?
3. Что такое класс?
4. На какие разделы может делиться класс?
5. Назовите и охарактеризуйте три основных принципа в использовании классов.
6. Что такое конструктор и для чего он используется?
7. Как происходит индексирование объектов класса?
8. Как происходит вызов функции?
9. Что такое композиция классов?
10. Для чего и каким образом используются дружественные функции?
11. Для чего требуется указатель this?
12. Для чего используется модификатор static?