

Глава 6 обучение без учителя и группировка
6.1. Введение
До сих пор мы предполагали, что обучающие выборки, используемые для создания классификатора, были помечены, чтобы показать, к какой категории они принадлежат. Процедуры, использующие помеченные выборки, называются процедурами с учителем. Теперь рассмотрим процедуры без учителя, использующие непомеченные выборки. То есть мы посмотрим, что можно делать, имея набор выборок без указания их классификации.
Возникает вопрос: целесообразна ли такая малообещающая задача и возможно ли в принципе обучить чему-либо по непомеченным выборкам. Имеются три основные причины, по которым мы интересуемся процедурами без учителя. Во-первых, сбор и пометка большого количества выборочных образов требуют много средств и времени. Если классификатор можно в первом приближении создать на небольшом помеченном наборе выборок и после этого его «настроить» на использование без учителя на большом непомеченном наборе, мы сэкономим много труда и времени. Во-вторых, во многих практических задачах характеристики образов медленно изменяются во времени. Если такие изменения можно проследить классификатором, работающим в режиме обучения без учителя, это позволяет повысить качество работы. В-третьих, на ранних этапах исследования иногда бывает интересно получить сведения о внутренней природе или структуре данных. Выделение четких подклассов или основных отклонений от ожидаемых характеристик может значительно изменить подход, принятый при создании классификатора.
Ответ на вопрос, можно или нельзя в принципе обучить чему-либо по непомеченным данным, зависит от принятых предположений—теорему нельзя доказать без предпосылок. Мы начнем с очень ограниченного предположения, что функциональный вид плотностей распределения известен, и единственное, что надо узнать,— это значение вектора неизвестных параметров. Интересно, что формальное решение этой задачи оказывается почти идентичным решению задачи об обучении с учителем, данному в гл. 3. К сожалению, в случае обучения без учителя решение наталкивается на обычные проблемы, связанные с параметрическими предположениями, не способствующими простоте вычислений. Это приводит нас к различным попыткам дать новую формулировку задачи как задачи разделения данных в подгруппы, или кластеры. Хотя некоторые из результирующих процедур группировки и не имеют большого теоретического значения, они являются одним из наиболее полезных средств решения задач распознавания образов.
6.2. Плотность смеси и идентифицируемость
Начнем с предположения, что мы знаем полную вероятностную структуру задачи, за исключением лишь значений некоторых параметров. Более точно, мы делаем следующие предположения:
1. Выборки производятся из известного числа с классов.
2. Априорные вероятности Р (j) для каждого класса известны, j=1, .. ., с.
3. Вид условных по классам плотностей р (х|j, ) известен, j =1,. . ., с.
4. Единственные неизвестные — это значения с параметрических векторов 1, . . . , c.
Предполагается, что выборки получены выделением состояния природы j с вероятностью Р (j) и последующим выделением х в соответствии с вероятностным законом р (х|j, ).
Т![]() аким
образом, функция плотности распределения
выборок определяется как
аким
образом, функция плотности распределения
выборок определяется как
где =(1, . . ., с). Функция плотности такого вида называется плотностью смеси. Условные плотности р(х|j,j) называются плотностями компонент, а априорные вероятности Р (j) — параметрами смеси. Параметры смеси можно включить и в неизвестные параметры, но на данный момент мы предположим, что неизвестно только .
Наша основная цель — использовать выборки, полученные согласно плотности смеси, для оценки неизвестного вектора параметров . Если мы знаем , мы можем разложить смесь на компоненты, и задача решена. До получения явного решения задачи выясним, однако, возможно ли в принципе извлечь из смеси. Предположим, что мы имеем неограниченное число выборок и используем один из непараметрических методов гл. 4 для определения значения р(х|) для каждого х. Если имеется только одно значение , которое дает наблюденные значения для р (х|), то в принципе решение возможно. Однако если несколько различных значений могут дать одни и те же значения для р(х|), то нет надежды получить единственное решение.
Эти рассмотрения приводят нас к следующему определению:
плотность р(х|) считается идентифицируемой, если из `следует, что существует х, такой, что р(х|) р(х|`). Как можно ожидать, изучение случая обучения без учителя значительно упрощается, если мы ограничиваемся идентифицируемыми смесями. К счастью, большинство смесей с обычно встречающимися функциями плотности идентифицируемо. Смеси с дискретным распределением не всегда так хороши. В качестве простого примера рассмотрим случай, где х бинарен и р(х|) - смесь:
Е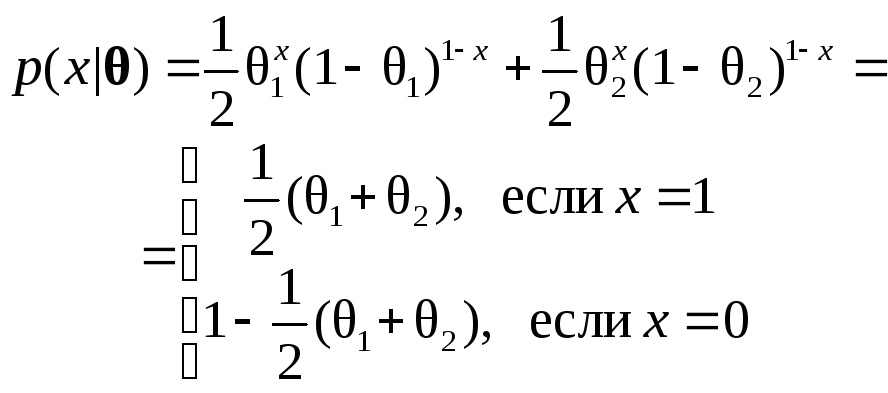 сли
мы знаем, например, что Р(х=1|)=0,6
и, следовательно, Р(x=0|)=0,4,
то мы знаем функцию Р
(х |)
,
но не можем определить
и поэтому не можем извлечь распределение
компонент. Самое большее, что мы можем
сказать,
— это что
1+2=1,2.
Таким образом, мы имеем случай, в котором
распределение смеси неидентифицируемо,
и, следовательно, это случай, в котором
обучение без учителя в принципе
невозможно.
сли
мы знаем, например, что Р(х=1|)=0,6
и, следовательно, Р(x=0|)=0,4,
то мы знаем функцию Р
(х |)
,
но не можем определить
и поэтому не можем извлечь распределение
компонент. Самое большее, что мы можем
сказать,
— это что
1+2=1,2.
Таким образом, мы имеем случай, в котором
распределение смеси неидентифицируемо,
и, следовательно, это случай, в котором
обучение без учителя в принципе
невозможно.
К![]() ак
правило, при дискретных распределениях
возникает такого рода проблема. Если в
смеси имеется слишком много компонент,
то неизвестных может быть больше, чем
независимых уравнений, и идентифицируемость
становится сложной задачей. Для
непрерывного случая задачи менее
сложные, хотя иногда и могут возникнуть
небольшие трудности. Таким образом,
в то время как можно показать, что смеси
с нормальной плотностью обычно
идентифицируемы, параметры в простой
плотности смеси
ак
правило, при дискретных распределениях
возникает такого рода проблема. Если в
смеси имеется слишком много компонент,
то неизвестных может быть больше, чем
независимых уравнений, и идентифицируемость
становится сложной задачей. Для
непрерывного случая задачи менее
сложные, хотя иногда и могут возникнуть
небольшие трудности. Таким образом,
в то время как можно показать, что смеси
с нормальной плотностью обычно
идентифицируемы, параметры в простой
плотности смеси
не могут быть идентифицированы однозначно, если P(1)=P(2), так как тогда 1 и 2 могут взаимно заменяться, не влияя на р(х|). Чтобы избежать таких неприятностей, мы признаем, что идентифицируемость является самостоятельной задачей, но в дальнейшем предполагаем, что плотности смеси, с которыми мы работаем, идентифицируемы.