

И к w2 , если

Такая процедура минимизирует ожидаемую стоимость ошибочной классификации
q1C(2|1)Pr(2|1)+q2 C(1|2)Pr(1|2).
Для обобщенной байесовской процедуры вероятности ошибочной классификации имеют вид

и

где
![]()
Решение системы (1) можно записать в матричных обозначениях
a = e-1( m1-m2 ) ,
где a = ( a1 , ... , ap )T.
Расстояние Махалонобиса
D2 = ( m1-m2 ) T e-1( m1-m2 ) .
Классификация в случае двух многомерных нормальных групп при неизвестных параметрах
Пусть имеется объект , которому соответствует вектор наблюдений X. Требуется отнести его на основе этих наблюдений к группе W1 с распределением
![]()
или к W2 :
![]()
Предполагается , что известны априорные информации и стоимости ошибочной классификации , но средние m1 и m2 и матрица ковариаций e неизвестны. Если
x11, ... , x1n1 и x21 , ... , x2n2 - независимые случайные выборки из групп W1 , ... , W2 соответственно , то можно оценить mi выборочным вектором средних x~=( xi1 , ... , xip )T,
i=1,2 , а e - объединенной выборочной ковариационной матрицей S = ( sjk ) , где j,k=1,...,p.
В такой ситуации невозможно найти процедуру классификации, которая была бы оптимальной в смысле стоимости ошибочной классификации. Однако можно показать, что если параметры в обобщенной байесовской процедуре заменить их состоятельными оценками , то в результате ожидаемая стоимость ошибочной классификации будет убывать при n1 и n2 стремящихся к бесконечности. Поскольку приведенные выше оценки состоятельны, обобщенная процедура байесовской классификации на основе оценок параметров заключается в следующем :
1) решается система уравнений (1) с заменой mij на x~ij i=1,2 , j=1,...,p, и заменой s jm на sjm,
m=1,...,p.
2) полученные оценки коэффициентов a 1 ,..., a p ( обозначим их через a 1 , ... , a p ) используется для определения значения дискриминантной функции zil для каждого вектора наблюдений Xil , l = 1,..,n i . Далее, z i оцениваются величинами

а sz2 - величиной

Таким образом, обобщенная байесовская процедура оценивания состоит в отнесении
X=( x1 , ... , xp )T к W1 , если

и к W2 - в обратном случае.
Выборочное расстояние Махалонобиса

является оценкой для D2 .
В результате работы программ дискриминантного анализа, как правило получаем следующее:
1) оценки коэффициентов дискриминантной функции a 1 , ... , a p ;
2) значение дискриминантной функции zil для каждого вектора наблюдений Xil , i=1,2 ,
l=1,.., n i
3) выборочные средние z~1 и z~2
4) выборочное расстояние Махалонобиса D 2 .
Эта информация достаточна для классификации.
Замечания.
1) В результате работы программ дискриминантного анализа обычно выводится значение F-статистики
![]()
которое можно использовать для проверки гипотезы H0 : D2 = 0. Числа степеней свободы F равны p и n 1 + n 2 - p - 1
2) Выборочная оценка D 2 расстояния Махалонобиса является смещенной. Несмещенная оценка имеет вид
![]()
Классификация в случае k групп с произвольными известными распределениями.
Пусть f i (X) означает плотность распределения X в Wi и q i - априорную вероятность того, что вектор наблюдения X принадлежит группе Wi, i = 1 , ... , k . Обозначим стоимость отнесения наблюдений Wj к Wi через C( i | j ), а вероятность отнесения наблюдения из Wj к Wi - через Pr( i | j ), i,j = 1 , ... , k , i<>j. Полагая, что все параметры известны, можно показать, что обобщенная байесовская процедура классификации относит вектор X к Wi, если величина
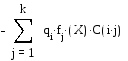 i
# j
i
# j
является максимальной, i = 1 , ... , k. (Если одинаковый максимум достигается как в i 1 , так и в i 2 , то X относится к Wi 1 или Wi 2 ). Эта величина называется значением дискриминантной функции для i-й группы. Байесовская процедура минимизирует ожидаемую стоимость ошибочной классификации
 i
# j
i
# j
Когда стоимость ошибочной классификации не имеет значения, все C( i | j ) полагаются равными и процедура Байеса относит X к Wi, если
q i f i (X) (4)
имеет максимальное значение, i = 1 , ... , k. Таким образом, минимизируется ожидаемая вероятность ошибочной классификации
 i
# j
i
# j
Заметим, что это эквивалентно отнесению X к Wi, если апостериорная вероятность

достигает максимума.
Классификация в случае групп с многомерными нормальными распределениями.
Пусть группа Wi имеет распределение
![]()
с функцией плотности f i (X) , i = 1 , ... , k. Будем считать, что все параметры известны и стоимости ошибочных классификаций равны. Подставляя f i (X) в (4) , логарифмируя и исключая общие множители, получаем линейную дискриминантную функцию для i-й группы
di = ai1 * x1 + ... + aip * xp + gi *ln qi , i = 1 , ... , k. (5)
Итак, вектор наблюдений X относится к группе Wi, если значение di является максимальным среди всех i = 1 , ... , k. Апостериорная вероятность принимает вид

Предположение о том, что параметры распределений известны облегчает только теоретическую часть анализа. На практике, как правило, имеются независимые случайные выборки из k групп по которым можно получить оценки параметров. При этом не существует оптимальной процедуры классификации, но подстановкой состоятельных оценок в выражение (5) можно получить асимптотическую оптимальную процедуру.
Пусть n i - объем i-й выборки, x~i - ее вектор средних и Si - ковариационная матрица,
i = 1 , ... , k. Тогда в формуле (5) можно заменить mi на x~i и e - на объединенную ковариационную матрицу S :

Таким образом, оценка дискриминантной функции для i-й группы имеет вид
di = ai1 * x1 + ... + aip * xp + ci +ln qi , i = 1 , ... , k.
Вектор X классифицируется, как принадлежащий группе Wi, если величина di имеет наибольшее значение. При этом оценка апостериорной вероятности имеет вид

Резюме. Программы дискриминантного анализа предназначаются, как правило, для вычисления следующих величин :
1) объединенной матрицы ковариации S и ковариационных матриц Si для группы Wi,
i = 1 , ... , k ;
2) оценок для коэффициентов линейной дискриминантной функции ai1 , ... , aip и постоянной ci для группы Wi, i = 1 , ... , k ;
3) оценок значения линейной дискриминантной функции для каждого элемента xim выборки из Wi, m = 1 , ... , n , i = 1 , ... , k ;
4) оценки апостериорной вероятности для каждой группы Wj при заданном векторе xim , который является m-м элементом выборки из Wi , m = 1 , ... , ni , i , j = 1 , ... , k ;
5) номеров групп, к которым относится векторы - элементы выборки из Wi, m = 1 , ... , ni ,
i = 1 , ... , k ( тех групп для которых оценка апостериорной вероятности для дискриминантной функции достигает наибольшего значения ).
6) таблицы результатов классификации nij векторов xjm выборки из Wj отнесенных к Wi
m = 1 , ... , nj , j = 1 , ... , k . С помощью этой таблицы можно оценить вероятность ошибочной классификации Pr^( i | j ) = nij / nj , i , j = 1 , ... , k , i<>j.
7) обобщенного расстояния Махалонобиса V - обобщение величины D2 . Оно может быть использовано для проверки гипотезы H0 : m1 = ... = mk . Заметим, что проверка гипотезы H0 : m1 = ... = mk является многомерным аналогом однофакторного дисперсионного анализа. Многие программы выводят на печать так называемую U-статистику, которая является точной для проверки гипотезы H0 . В виду сложности распределения величины U на печать выводится ее F-аппроксимация и соответствующее число степеней свободы. Такой критерий является точным для p = 1,2 при любых k или же при k = 2 для любых p.