

1.7. Реляционные системы управления базами данных
Использование физических указателей было одновременно и сильной, и слабой стороной иерархических и сетевых систем управления базами данных. Сильной, поскольку они позволяли извлекать данные, связанные определенными отношениями. Слабой, поскольку эти отношения должны быть определены до запуска системы. Извлечь данные на основе других отношений было сложно, если вообще возможно.
В 1970 году Е.Ф. Кодд опубликовал революционную по содержанию статью (Codd, 1970), которая всерьез поколебала устоявшиеся представления о базах данных. Он выдвинул идею, что данные нужно связывать в соответствии с их внутренними логическими возможностями, а не физическими указателями. Таким образом, пользователи смогут копировать данные из разных источников, если логическая информация, необходимая для такого комбинирования, присутствует в исходных данных. Это открыло новые возможности для информационно-управляющих систем, поскольку запросы к базам данных теперь не были ограничены физическими указателями.

Рис. 1.11. Логическая связь, не поддерживаемая физическим указателем
Для того чтобы понять, какие недостатки присущи системам, основанным на физических указателях, рассмотрим рис. 1.11. На нем показано, что файлы CUSTOMER, INVOICE и INVOICE LINE связаны физическими указателями. Файлы MANUFACTURER (ИЗГОТОВИТЕЛЬ) и PRODUCT тоже связаны. Пунктирная линия между INVOICE LINE и PRODUCT обозначает, что между ними существует логическая связь, поскольку каждая строка счета относится к конкретному товару. Однако предположим, что файл PRODUCT не привязан к файлу INVOICE LINE физическим указателем. Как тогда, составить следующий отчет?
Для каждого клиента перечислить изготовителей приобретенных им товаров.
Для составления такого отчета требуется двигаться от файла CUSTOMER через INVOICE и INVOICE LINE к PRODUCT и затем к MANUFACTURER. Но поскольку между файлами INVOICE LINE и PRODUCT нет физической связи, то обычными средствами базы данных такой путь проделать невозможно. Для того чтобы все-таки получить такую информацию, придется пользоваться древними и неуклюжими способами работы с файлами. Это потребует искусного длительного программирования. Те же информационные системы, использующие базы данных, которые поддерживают извлечение данных на основе логических связей, легко ответят на такой вопрос.
В своей статье Кодд предложил простую модель данных, согласно которой все данные сведены в таблицы, состоящие из строк и столбцов. Эти таблицы получили название реляций, а модель стала называться соответственно реляционной. Кодд также предложил пользоваться для работы с данными в таблице двумя языкам: реляционной алгеброй и реляционным исчислением (о них мы поговорим и в главе 6). Оба эти языка обеспечивают работу с данными на основе логических характеристик, а не физических указателей, которыми пользовались в иерархических и сетевых моделях.
Рассматривая данные с концептуальной, а не физической точки зрения, Кодд предложил еще одну революционную идею. В реляционных системах баз данных целые файлы данных могут обрабатываться одной командой, тогда как в традиционных системах за один раз обрабатывается только одна запись. Подход Кодда чрезвычайно повысил эффективность программирования в базах данных.
Логический подход к данным сделал также возможным создание языков запросов, более доступных для пользователей, не являющихся специалистами по компьютерам. Хотя создать язык, которым могли бы пользоваться все, независимо от опыта работы с компьютером, довольно сложно, однако реляционные языки запросов сделали базы данных доступными для более широкого круга пользователей, чем раньше.
Публикация работ Кодда в начале семидесятых вызвала взрыв активности как среди ученых, так и среди разработчиков коммерческих систем по созданию реляционной системы управления базами данных. Результатом этой деятельности явилось создание во второй половине семидесятых реляционных систем, которые поддерживали такие языки, как Structured Query Language (SQL, язык структурированных запросов), Query Language (Quel, язык запросов) и Query-by-Example (QBE, запросы по образцу). С широким распространением персональных компьютеров в восьмидесятые годы также появились реляционные базы данных для микрокомпьютеров. В 1986 году SQL был принят в качестве стандарта ANSI языков реляционных баз данных. Этот стандарт обновлялся в 1989 и в 1992 годах.
Все эти новшества сильно расширили возможности систем управления базами данных и повысили доступность информации в корпоративных базах данных. Реляционный подход оказался весьма плодотворным. Более того, продолжающиеся исследования обещают значительный прогресс с точки зрения понимания интересов пользователей систем управления базами данных.
Сегодня реляционные базы данных рассматриваются как стандарт для современных коммерческих систем работы с данными. Разумеется, файловые системы, иерархические и сетевые базы данных все еще многочисленны и во многих случаях именно их применение является наиболее выгодным. Тем не менее, среди компаний прослеживается очевидная тенденция при первой же возможности переходить на реляционные системы.
Неверным, однако, было бы полагать, что современные реляционные системы управления базами данных являются последним словом в развитии СУБД. Реляционные базы данных продолжают совершенствоваться, и их внутренняя природа значительно меняется, предоставляя пользователям возможность решать все более сложные задачи. По нашему мнению, наиболее существенные из таких перемен происходят в области объектно-ориентированных баз данных. Еще одно чрезвычайно важное новшествопереход организаций к работе с базами данных на технологию клиент/сервер. Этот принцип мы рассмотрим в следующем разделе.
На рис. 1.12 представлена временная шкала, описывающая историческое развитие способов доступа к данным, о котором мы говорили. В таблице 1.1 приведены сравнительные характеристики различных способов доступа к данным.
Таблица 1.1. Сравнительная характеристика способов
обращения к данным
|
Способ доступа к данным |
Характеристика |
|
Файлы последовательного доступа |
Записи должны обрабатываться в последовательном порядке |
|
Файлы произвольного доступа |
Поддерживают прямой доступ к конкретной записи. Сложно обращаться к нескольким записям, связанным с одной |
|
Иерархическая база данных |
Поддерживает доступ к нескольким записям, связанным с одной. Отношения между данными ограничиваются иерархическими. Зависит от предопределенных физических указателей |
|
Сетевая база данных |
Поддерживает иерархические и неиерархические отношения между данными. Зависит от предопределенных физических указателей |
|
Реляционная база данных |
Поддерживает все логические отношения между данными. Логический доступ к данным, не зависящий от физической реализации |
Появление в 1981 году IBM PC сделало настольный компьютер обычным явлением в офисе. Программы обработки текстов, работы с таблицами и многие другие сами по себе оправдывали использование таких машин. Кроме того, было вполне естественно связывать компьютеры в сеть, чтобы пользователи могли общаться по электронной почте и работать с общими ресурсами, такими как принтеры и диски. Вначале серверы были созданы для управления печатью и доступом к файлам. Это были серверы печати и файловые серверы. Например, в ответ на запрос клиента на доступ к конкретному файлу, файловый сервер пересылал этот файл через сеть на клиентский компьютер (рис. 1.13). Сегодня же большинство серверов составляют серверы баз данных — программы, которые запускаются на серверной машине и обслуживают доступ клиентов к базе данных (рис. 1.14). Например, клиент запускает прикладную программу, и ему требуется запросить базу данных. Для этого он обращается к серверу за нужными ему данными, сервер выполняет запрос и возвращает результат клиенту. Прикладная программа может также посылать данные на сервер с требованием обновить базу данных. Сервер вносит необходимые изменения.
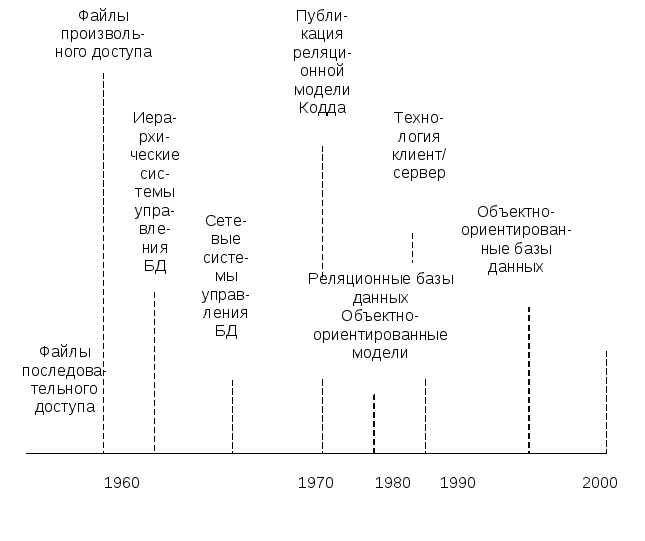
Рис. 1.12. Развитие систем управления базами данных
Система клиент/серверлокальная сеть, состоящая из клиентских компьютеров, которые обслуживает компьютер-сервер.
Сервер базы данных,программа, которая запускается на машине-сервере и обслуживает доступ клиентов к базе данных.
В основе продуктивности системы клиент/сервер лежит принцип разделения труда. Клиент это та машина, с которой работает пользователь. Она управляется графическим пользовательским интерфейсом и производит вычисления и другую работу, необходимую непосредственно конечному пользователю. Сервер находится «за сценой» и выполняет работу, общую для нескольких клиентовдоступ к базе данных, обновление базы данных и т.д.
Графическийпользовательскийинтерфейс. Графические средства доступа конечного пользователя к компьютерной системе.
В концептуальном плане принцип клиент/сервер это часть понятия открытой системы, объединяющего все те способы, которыми можно связать и заставить согласованно работать на благо пользователя компьютеры, операционные системы, сетевые протоколы и другое оборудование, и программное обеспечение. Однако на практике заставить вместе работать разнообразные операционные системы, сетевые протоколы, базы данных и т.д. не слишком просто. Цель открытых системдобиться возможности взаимодействия (совместимости), когда две или более различных системы обмениваются информацией и каждая из них вносит свой вклад в решение общей задачи.
Открытые системыпонятие, означающее согласованную работу объединенного вместе различного оборудования и программного обеспечения.
Взаимодействиережим, в котором две или более различных системы обмениваются информацией, внося свой вклад в решение общей задачи.

 Рис.
1.13. Извлечение целого файла с файлового
сервера
Рис.
1.13. Извлечение целого файла с файлового
сервера
В некотором смысле технология клиент/сервер наиболее яркое воплощение сочетания распределенной обработки данных с централизованным управлением и доступом к данным. Провидцы предсказывали неизбежное появление распределенных вычислений уже более двух десятилетий назад, однако в реальности они появились лишь недавно. Хотя многие сложные проблемы взаимодействия пока не решены, перспективы увеличения эффективности обработки данных и доступа к базам данных еще никогда не были столь радужными.
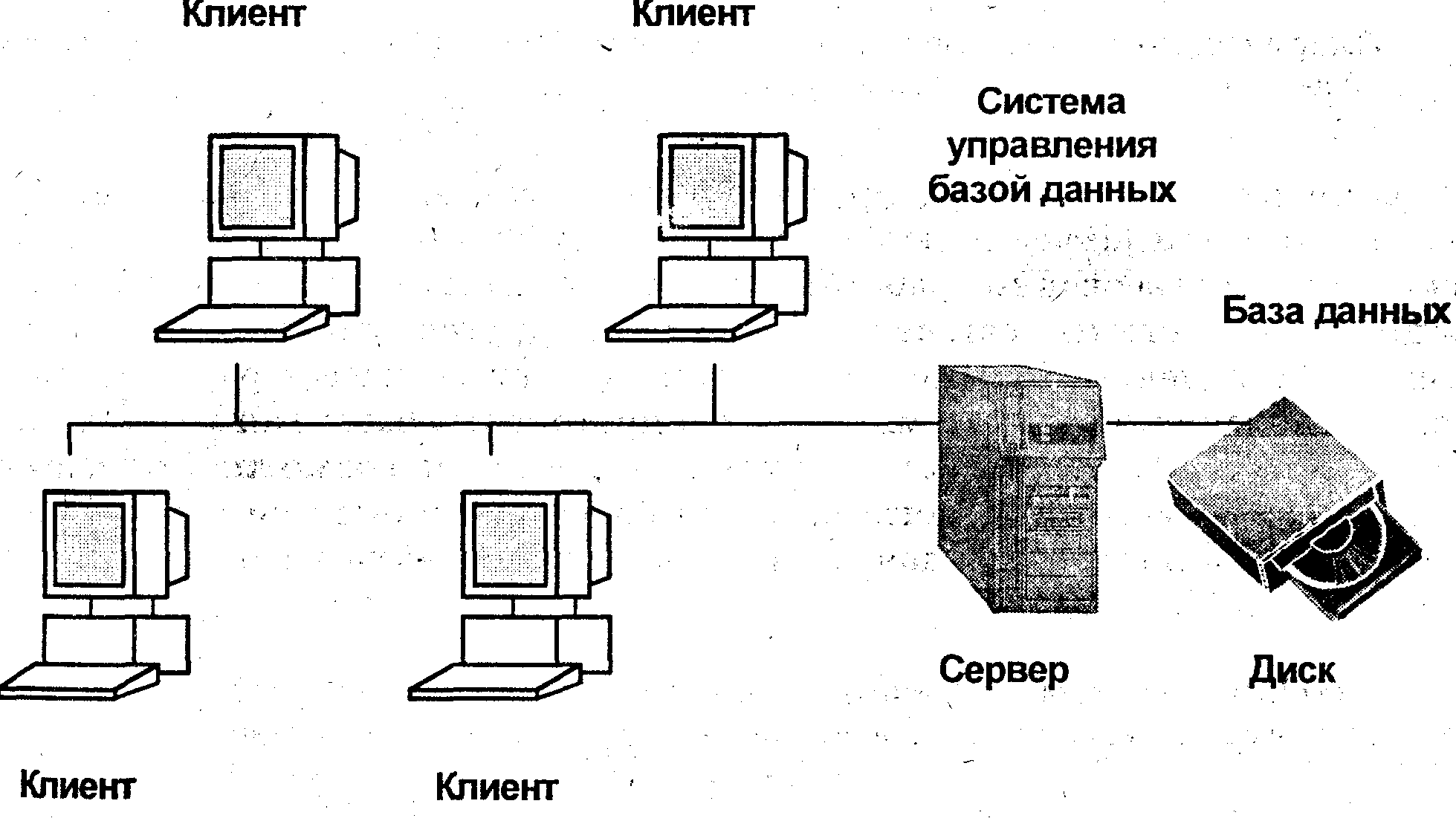
Рис. 1.14. Клиенты, взаимодействующие с сервером базы данных