

Управление транзакциями в среде ms sql Server. Sql Server предлагает множество средств управления поведением транзакций.
По умолчанию управление транзакциями выполняется на уровне соединения. Когда транзакция начинает соединение, все выполняемые во время этого соединения инструкции языка Transact-SQL становятся частью транзакции до ее завершения.
Транзакция определяется на уровне соединения с базой данных и при закрытии соединения автоматически закрывается. Если пользователь попытается установить соединение снова и продолжить выполнение транзакции, то это ему не удастся. Когда транзакция начинается, все команды, выполненные в соединении, считаются телом одной транзакции, пока не будет достигнут ее конец.
Если в одном соединении изменяется режим транзакций, он не влияет на режимы транзакций других соединений.
SQL Server поддерживает три вида определения транзакций:
явное (Явный запуск транзакции через функцию API или посредством инструкции BEGIN TRANSACTION языка Transact-SQL);
Когда пользователю понадобится создать транзакцию, включающую несколько команд, он должен явно указать транзакцию
автоматическое (Режим по умолчанию для компонента Database Engine). Каждая отдельная инструкция языка Transact-SQL фиксируется после завершения. Нет необходимости указывать какие-либо инструкции для управления транзакциями;
По умолчанию SQL Server работает в режиме автоматического начала транзакций, когда каждая команда рассматривается как отдельная транзакция. Если команда выполнена успешно, то ее изменения фиксируются. Если при выполнении команды произошла ошибка, то сделанные изменения отменяются и система возвращается в первоначальное состояние.
Следующая инструкция автоматически запускает новую транзакцию. После завершения этой транзакции следующая инструкция языка Transact-SQL запускает новую транзакцию.
неявное - пользователю необходимо явно выполнить в конце транзакции фиксацию или откат.
Установка неявного режима транзакции либо через функцию API, либо через инструкцию языка Transact-SQL SET IMPLICIT_TRANSACTIONS ON.
SET IMPLICIT_TRANSACTIONS { ON | OFF }
Присвоение параметру SET IMPLICIT_TRANSACTIONS значения ON устанавливает для соединения режим неявных транзакций.
Для транзакций, автоматически открываемых в результате присвоения этому параметру значения ON, пользователю необходимо явно выполнить в конце транзакции фиксацию или откат. Иначе после отключения пользователя будет выполнен откат транзакции и будут потеряны все сделанные ей изменения данных.
Значение OFF возвращает соединение в режим с автоматической фиксацией транзакций.
После фиксации транзакции выполнение одной из указанных инструкций (см. таблицу) начнет новую транзакцию.
Когда соединение находится в режиме неявных транзакций, выполнение любой из следующих инструкций начнет транзакцию.
ALTER TABLE |
FETCH |
REVOKE |
CREATE |
GRANT |
SELECT |
DELETE |
INSERT |
TRUNCATE TABLE |
DROP |
OPEN |
UPDATE |
Если соединение уже начало транзакцию, эти инструкции не начинают новую транзакцию.
Транзакция продолжает оставаться активной до тех пор, пока не будет выдана инструкция COMMIT или ROLLBACK (см. далее). После фиксации или отката первой транзакции экземпляр компонента Database Engine автоматически запускает новую транзакцию каждый раз, когда на соединении выполняется какая-либо из этих инструкций. Для запуска таких транзакций ничего делать не нужно; необходимо только фиксировать или выполнять откат каждой транзакции. Режим неявных транзакций формирует непрерывную цепь транзакций.
Экземпляр продолжает формировать цепь неявных транзакций до тех пор, пока не будет выключен режим неявных транзакций.
Режим неявных транзакций остается в силе, пока в соединении не будет выполнена инструкция SET IMPLICIT_TRANSACTIONS OFF, которая вернет соединение в режим автоматической фиксации.
Явными транзакциями являются транзакции, для которых явно назначаются запуск и остановка. Явные транзакции требуют, чтобы пользователь указал начало и конец транзакции.
Для определения явных транзакций используются инструкции Transact-SQL BEGIN TRANSACTION, COMMIT TRANSACTION, COMMIT WORK, ROLLBACK TRANSACTION, ROLLBACK WORK и SAVE TRANSACTION.
BEGIN TRANSACTION - отмечает точку запуска явной транзакции для соединения.
BEGIN { TRAN | TRANSACTION }
[ { transaction_name | @tran_name_variable }
[ WITH MARK [ 'description' ] ]
]
[ ; ]
transaction_name – имя, присвоенное транзакции. Аргумент transaction_name должен соответствовать правилам для идентификаторов, однако не допускаются идентификаторы длиннее 32 символов. Имена транзакций используются только для самых внешних вложенных инструкций BEGIN...COMMIT или BEGIN...ROLLBACK.
@tran_name_variable - имя пользовательской переменной, содержащей допустимое имя транзакции. Переменная должна быть иметь тип данных char, varchar, nchar или nvarchar. Если переменной передается больше 32 символов, используются только 32 первых символа, а остальные усекаются.
WITH MARK [ 'description' ] - указывает, что транзакция отмечается в журнале. Значение аргумента description — это строка, описывающая отметку.
Если используется предложение WITH MARK, необходимо указать имя транзакции. Предложение WITH MARK позволяет восстановить журнал транзакций до именованной отметки.
COMMIT TRANSACTION или COMMIT WORK - используется для успешного завершения транзакции, если не было ошибок. Все изменения данных, сделанные в транзакции, становятся постоянной частью базы данных. Ресурсы, заблокированные транзакцией, высвобождаются.
Она сохраняет результаты всех операций, которые имели место после выполнения последней команды COMMIT или ROLLBACK.
COMMIT { TRAN | TRANSACTION } [ transaction_name | @tran_name_variable ] ]
[ ; ]
Инструкция BEGIN TRANSACTION предоставляет точку, где гарантируется логическая и физическая согласованность данных, на которые ссылается соединение. В случае ошибок для всех изменений после BEGIN TRANSACTION можно выполнить откат, чтобы вернуть данные к известному согласованному состоянию.
Каждая транзакция продолжается до тех пор, пока она не завершается без ошибок и выполняется инструкция COMMIT TRANSACTION, чтобы внести изменения в базу данных.
В случае возникновения ошибок все изменения удаляются с помощью инструкции ROLLBACK TRANSACTION.
ROLLBACK TRANSACTION или ROLLBACK WORK - используется для удаления транзакции, если были ошибки. Все измененные транзакцией данные возвращаются в то состояние, в котором они были в момент запуска транзакции. Ресурсы, заблокированные транзакцией, высвобождаются.
ROLLBACK { TRAN | TRANSACTION }
[ transaction_name | @tran_name_variable
| имя_точки_сохранения | @savepoint_variable ]
[ ; ]
Когда сервер встречает эту команду, происходит откат транзакции, восстанавливается первоначальное состояние системы и в журнале транзакций отмечается, что транзакция была отменена.
Она отменяет только те транзакции, которые были выполнены с момента выдачи последней команды COMMIT или ROLLBACK.
Команда SAVE предназначена для установки в транзакции особых точек, куда в дальнейшем может быть произведен откат (при этом отката всей транзакции не происходит).
SAVE { TRAN | TRANSACTION } { savepoint_name | @savepoint_variable }
[ ; ]
Она служит исключительно для создания точек сохранения среди операторов, предназначенных для изменения данных. Имя точки сохранения в связанной с ней группе транзакций должно быть уникальным.
Поскольку с помощью команды SAVEPOINT крупные транзакции могут быть разбиты на меньшие и поэтому более управляемые группы, ее применение является одним из способов управления транзакциями
Режим явной транзакции работает только во время выполнения транзакции. После завершения транзакции соединение возвращается в тот режим транзакции, в котором оно было до запуска явной транзакции, либо в неявный режим, либо в режим автоматической фиксации.
В следующем примере показано, как присвоить транзакции имя.
DECLARE @TranName VARCHAR(20);
SELECT @TranName = 'MyTransaction';
BEGIN TRANSACTION @TranName;
USE AdventureWorks;
DELETE FROM AdventureWorks.HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT TRANSACTION @TranName;
GO
В следующем примере показано, как пометить транзакцию. Транзакция CandidateDelete помечена.
BEGIN TRANSACTION CandidateDelete
WITH MARK N'Deleting a Job Candidate';
GO
USE AdventureWorks;
GO
DELETE FROM AdventureWorks.HumanResources.JobCandidate
WHERE JobCandidateID = 13;
GO
COMMIT TRANSACTION CandidateDelete;
GO
СУБД сохраняет состояние БД в текущей точке и присваивает сохраненному состоянию имя точки сохранения;
Пример. Использование точек сохранения
BEGIN TRAN
SAVE TRANSACTION point1
В точке point1 сохраняется первоначальное состояние таблицы Товар
DELETE FROM Товар WHERE КодТовара=2
SAVE TRANSACTION point2
В точке point2 сохраняется состояние таблицы Товар без товаров с кодом 2.
DELETE FROM Товар WHERE КодТовара=3
SAVE TRANSACTION point3
В точке point3 сохраняется состояние таблицы Товар без товаров с кодом 2 и с кодом 3.
DELETE FROM Товар WHERE КодТовара<>1
ROLLBACK TRANSACTION point3
Происходит возврат в состояние таблицы без товаров с кодами 2 и 3, отменяется последнее удаление.
SELECT * FROM Товар
Оператор SELECT покажет таблицу Товар без товаров с кодами 2 и 3.
ROLLBACK TRANSACTION point1
Происходит возврат в первоначальное состояние таблицы.
SELECT * FROM Товар
COMMIT
Первоначальное состояние сохраняется.
Вложенные транзакции
Вложенными называются транзакции, выполнение которых инициируется из тела уже активной транзакции.
Для создания вложенной транзакции пользователю не нужны какие-либо дополнительные команды. Он просто начинает новую транзакцию, не закрыв предыдущую.
Завершение транзакции верхнего уровня откладывается до завершения вложенных транзакций.
Если транзакция самого нижнего (вложенного) уровня завершена неудачно и отменена, то все транзакции верхнего уровня, включая транзакцию первого уровня, будут отменены.
Кроме того, если несколько транзакций нижнего уровня были завершены успешно (но не зафиксированы), однако на среднем уровне (не самая верхняя транзакция) неудачно завершилась другая транзакция, то в соответствии с требованиями ACID произойдет откат всех транзакций всех уровней, включая успешно завершенные.
Только когда все транзакции на всех уровнях завершены успешно, происходит фиксация всех сделанных изменений в результате успешного завершения транзакции верхнего уровня.
Каждая команда COMMIT TRANSACTION работает только с последней начатой транзакцией. При завершении вложенной транзакции команда COMMIT применяется к наиболее "глубокой" вложенной транзакции.
Даже если в команде COMMIT TRANSACTION указано имя транзакции более высокого уровня, будет завершена транзакция, начатая последней.
Если команда ROLLBACK TRANSACTION используется на любом уровне вложенности без указания имени транзакции, то откатываются все вложенные транзакции, включая транзакцию самого высокого (верхнего) уровня.
В команде ROLLBACK TRANSACTION разрешается указывать только имя самой верхней транзакции. Имена любых вложенных транзакций игнорируются, и попытка их указания приведет к ошибке.
Таким образом, при откате транзакции любого уровня вложенности всегда происходит откат всех транзакций.
Если же требуется откатить лишь часть транзакций, можно использовать команду SAVE TRANSACTION, с помощью которой создается точка сохранения.
Дополнительная информация.
Функция @@TRANCOUNT возвращает количество активных транзакций.
Функция @@NESTLEVEL возвращает уровень вложенности транзакций.
Пример. Вложенные транзакции.
BEGIN TRAN
INSERT Товар (Название, остаток)
VALUES ('v',40)
BEGIN TRAN
INSERT Товар (Название, остаток)
VALUES ('n',50)
BEGIN TRAN
INSERT Товар (Название, остаток)
VALUES ('m',60)
ROLLBACK TRAN
Здесь происходит возврат на начальное состояние таблицы, поскольку выполнение команды ROLLBACK TRAN без указания имени транзакции откатывает все транзакции.
Пример: Этот пример создает таблицу, формирует три уровня вложенных транзакций и затем фиксирует вложенные транзакции. Хотя каждая инструкция COMMIT TRANSACTION имеет аргумент transaction_name, не существует связи между инструкциями COMMIT TRANSACTION и BEGIN TRANSACTION.
Аргументы transaction_name удобны для понимания и помогают программисту удостовериться в том, что закодировано верное количество фиксированных транзакций и чтобы уменьшить значение параметра @@TRANCOUNT до 0 и таким образом зафиксировать внешнюю транзакцию.
IF OBJECT_ID(N'TestTran',N'U') IS NOT NULL
DROP TABLE TestTran;
GO
CREATE TABLE TestTran (Cola INT PRIMARY KEY, Colb CHAR(3));
GO
--Этот оператор устанавливает значение @@TRANCOUNT на 1
BEGIN TRANSACTION OuterTran;
GO
PRINT N'Количество активных транзакций после BEGIN OuterTran = '
+ CAST(@@TRANCOUNT AS NVARCHAR(10));
GO
INSERT INTO TestTran VALUES (1, 'aaa');
GO
--Этот оператор устанавливает значение @@TRANCOUNT на 2
BEGIN TRANSACTION Inner1;
GO
PRINT N'Количество активных транзакций после BEGIN Inner1 = '
+ CAST(@@TRANCOUNT AS NVARCHAR(10));
GO
INSERT INTO TestTran VALUES (2, 'bbb');
GO
-- Этот оператор устанавливает значение @@TRANCOUNT на 3.
BEGIN TRANSACTION Inner2;
GO
PRINT N'Количество активных транзакций после BEGIN Inner2 = '
+ CAST(@@TRANCOUNT AS NVARCHAR(10));
GO
INSERT INTO TestTran VALUES (3, 'ccc');
GO
--Этот оператор изменяет @@TRANCOUNT на 2.
-- Ничто не совершается.
COMMIT TRANSACTION Inner2;
GO
PRINT N'Количество активных транзакций после COMMIT Inner2 = '
+ CAST(@@TRANCOUNT AS NVARCHAR(10));
GO
--Этот оператор изменяет @@TRANCOUNT на 1.
-- Ничто не совершается.
COMMIT TRANSACTION Inner1;
GO
PRINT N'Количество активных транзакций после COMMIT Inner1 = '
+ CAST(@@TRANCOUNT AS NVARCHAR(10));
GO
-- Этот оператор уменьшает @@TRANCOUNT до 0
-- завершая выполнение внешней транзакции OuterTran.
COMMIT TRANSACTION OuterTran;
GO
PRINT N'Количество активных транзакций после COMMIT OuterTran = '
+ CAST(@@TRANCOUNT AS NVARCHAR(10));
GO
Результат работы:
Количество активных транзакций после BEGIN OuterTran = 1
(строк обработано: 1)
Количество активных транзакций после BEGIN Inner1 = 2
(строк обработано: 1)
Количество активных транзакций после BEGIN Inner2 = 3
(строк обработано: 1)
Количество активных транзакций после COMMIT Inner2 = 2
Количество активных транзакций после COMMIT Inner1 = 1
Количество активных транзакций после COMMIT OuterTran = 0
Модели конкурентного доступа.
Когда пользователи обращаются к ресурсу одновременно, говорят, что они делают это параллельно. Параллельный доступ к данным требует наличия механизмов предотвращения нежелательных последствий, которые могут возникнуть при попытке пользователей изменить ресурсы, активно используемые другими.
Если в системе управления базами данных не реализованы механизмы блокирования, то при одновременном чтении и изменении одних и тех же данных несколькими пользователями могут возникнуть проблемы одновременного доступа.
В связи со свойством сохранения целостности БД транзакции являются подходящими единицами изолированности пользователей. Действительно, если каждый сеанс взаимодействия с базой данных реализуется транзакцией, то пользователь начинает с того, что обращается к согласованному состоянию базы данных – состоянию, в котором она могла бы находиться, даже если бы пользователь работал с ней в одиночку.
Параллелизм:
Раздел |
Описание |
Эффекты параллелизма |
Различные уровни управления параллелизмом могут иметь разные побочные эффекты. Понимание этих эффектов важно для выбора подходящего уровня управления параллелизмом для приложения. |
Типы управления параллелизмом |
Оптимистичное управление параллелизмом предназначено для сведения к минимуму блокирования модуля чтения-записи. При применении оптимистичных способов управления параллелизмом операции считывания не используют блокировку считывания, запрещающую изменение данных. Пессимистичное управление параллелизмом обеспечивает работу операций считывания с текущими данными, которые не могут быть изменены. При применении пессимистичных способов управления параллелизмом операции считывания используют блокировку считывания, запрещающую изменение данных. Блокировки, устанавливаемые операциями считывания, снимаются по завершении операций. |
Уровни изоляции в ядре СУБД |
Уровни изоляции транзакций определяют, использует транзакция оптимистичное или пессимистичное управление параллелизмом, а также уровень защиты от других транзакций, одновременно обращающихся к данным. |
Теория управления параллелизмом предлагает два способа осуществления управления параллелизмом.
Пессимистическое управление параллелизмом
Система блокировок не допускает, чтобы изменение данных одними пользователями влияло на других пользователей. После того как действие пользователя приводит к блокировке, до тех пор пока инициатор ее не снимет, другие пользователи не могут выполнять действия, которые могут вызвать конфликт с блокировкой. Это называется пессимистическим управлением, поскольку в основном применяется в средах с большим количеством конфликтов данных, где затраты на защиту данных с помощью блокировок меньше затрат на откат транзакций в случае конфликтов параллелизма.
Оптимистическое управление параллелизмом
При оптимистическом управлении параллелизмом пользователи не блокируют данные на период чтения. Когда пользователь обновляет данные, система проверяет, вносил ли другой пользователь в них изменение после считывания. Если другой пользователь изменял данные, возникает ошибка. Как правило, при получении сообщения об ошибке пользователь откатывает транзакцию и начинает ее заново. Это называется оптимистическим управлением, поскольку в основном применяется в средах с небольшим количеством конфликтов данных, где затраты на периодический откат транзакции меньше затрат на блокировку данных при считывании.
Уровень изоляции транзакции определяет, могут ли другие (конкурирующие) транзакции вносить изменения в данные, измененные текущей транзакцией, а также может ли текущая транзакция видеть изменения, произведенные конкурирующими транзакциями, и наоборот (будут рассмотрены далее).
SQL Server 2005 Database Engine использует следующие механизмы для гарантии целостности транзакций и поддержания согласованности баз данных, когда несколько пользователей обращаются к одним и тем же данным в одно и то же время:
Блокирование (пессимистический конкурентный доступ)
Управление версиями строк (оптимистический конкурентный доступ)
Блокировка и управление версиями строк не дают пользователям считывать незафиксированные данные и не дают нескольким пользователям менять одни и те же данные в одно и то же время. Без этих механизмов запросы к таким данным могли бы возвращать непредвиденные результаты, например данные, которые еще не были зафиксированы в базе данных.
Если используется уровень изоляции на основе версий строк, компонент Database Engine хранит версии каждой измененной строки. Приложения могут указать, что транзакция будет использовать версии строк для просмотра данных, существовавших до ее начала или до начала запроса, вместо того, чтобы защищать все операции чтения блокировками.
При управлении версиями строк вероятность того, что операция чтения будет блокировать другие транзакции, значительно снижается. Конфликтная ситуация возникает только в том случае, когда две или более операции используют одни и те же данные. В этом случае генерируется ошибка, которая может быть обработана.
Блокирование.
Database Engine, как и все реляционные СУБД, использует блокировки (замки) для гарантии согласованности данных в базе данных в случае многопользовательского к ней доступа. Каждая программа приложения блокирует нужные ей данные, гарантируя этим, что никакая другая программа не может изменять те же самые данные. Когда другая программа приложения запрашивает модификацию заблокированных данных, система или останавливает эту программу, выдавая ошибку, или переводит программу в состояние ожидания.
Каждая транзакция запрашивает блокировку разных типов ресурсов, например строк, страниц или таблиц, от которых эта транзакция зависит. Блокировка не дает другим транзакциям изменять ресурсы, чтобы избежать ошибок в транзакции, запросившей блокировку. Каждая транзакция освобождает свои блокировки, если больше не зависит от блокируемого ресурса.
Компонент Microsoft SQL Server Database Engine блокирует ресурсы с помощью различных режимов блокировки, которые определяют доступ одновременных транзакций к ресурсам.
Пользователю чаще всего не нужно предпринимать никаких действий по управлению блокировками. Всю работу по установке, снятию и разрешению конфликтов выполняет специальный компонент сервера, называемый менеджером блокировок.
MS SQL Server поддерживает различные уровни блокирования объектов (или детализацию блокировок), начиная с отдельной строки таблицы и заканчивая базой данных в целом.
Менеджер блокировок автоматически оценивает, какое количество данных необходимо блокировать, и устанавливает соответствующий тип блокировки. Это позволяет поддерживать равновесие между производительностью работы системы блокирования и возможностью пользователей получать доступ к данным (блокирование на уровне строки, блокирование на уровне таблицы и др.).
Блокировка имеет несколько различных аспектов:
длительность блокировки;
режим блокировки;
гранулярность блокировки.
Длительность блокировки задает период времени, в течение которого заблокированы ресурсы. Длительность блокировки зависит от режима блокировки и выбранного уровня изоляции.
Режимы блокировки.
Режимы блокировки определяют различные виды замков. Выбор того, какой режим блокировки нужно применить, зависит от того ресурса, который нужно блокировать.
Рассмотрим сначала два основных режима блокировок - монопольную блокировку и совместимую или разделяемую.
Когда выполняется модификация данные, соответствующая транзакция запрашивает монопольную блокировку для ресурса данных, и, если получает, то удерживает этот режим до завершения транзакции.
Монопольные блокировки называют так, потому что нельзя получить монопольную блокировку для ресурса с любым другим режимом блокировки, установленным другой транзакцией, и нельзя установить для ресурса любой режим блокировки, если другая транзакция поддерживает монопольную блокировку ресурса. Это стандартный способ выполнения модификаций, и его нельзя изменить ни в отношении режима блокировки, требуемого для модификации ресурса данных (монопольный), ни в отношении продолжительности блокировки (до завершения транзакции).
При попытке чтения данных по умолчанию соответствующая транзакция запрашивает совместную или разделяемую блокировку ресурса данных и снимает ее, как только инструкция чтения данного ресурса выполнена. Этот режим блокировки называют совместным или разделяемым, т. к. множественные транзакции могут одновременно поддерживать совместные блокировки одного и того же ресурса данных.
Несмотря на то, что нельзя изменять режим блокировки и время, требуемое для модификации данных, при чтении данных можно управлять способом обработки блокировки (далее будут рассматриваться уровни изоляции).
Изменяющие данные инструкции, такие как INSERT, UPDATE или DELETE, соединяют как операции изменения, так и операции считывания. Чтобы выполнить необходимые операции изменения данных, инструкция сначала получает данные с помощью операций считывания. Поэтому, как правило, инструкции изменения данных запрашивают как совмещаемые, так и монопольные блокировки.
Например инструкция UPDATE может изменять строки в одной таблице, основанной на соединении данных из другой таблицы. В этом случае инструкция UPDATE кроме монопольной блокировки обновляемых строк запрашивает также совмещаемые блокировки для строк, считываемых в соединенной таблице.
Взаимодействие блокировок транзакций называют совместимостью блокировок.
Принципы блокирования ресурсов.
SQL Server способен блокировать ресурсы разных типов или уровней детализации. Могут блокироваться ресурсы следующих типов: RID1 или ключ (строка), страница, объект (например, таблица), база данных и др.
Для установки блокировки ресурса определенного типа, транзакция должна сначала установить предварительные или планируемые блокировки с тем же режимом на более крупные порций данных (находящиеся на более высоких уровнях иерархии блокируемых ресурсов, см. блокировки с намерением).
Например, для монопольной блокировки строки транзакция сначала должна установить предварительную монопольную блокировку для страницы, на которой находится строка, и предварительную монопольную блокировку для объекта, владеющего этой страницей.
Точно так же для установки совместной блокировки на определенном уровне иерархии ресурсов транзакции сначала необходимо установить предварительные совместные блокировки на более высоких уровнях иерархии этих ресурсов.
Задача предварительных блокировок — реальное обнаружение несовместимых запросов на блокировку на более высоких уровнях иерархии ресурсов и предотвращение предоставления подобных режимов.
Например, если одна транзакция поддерживает блокировку строки, а другая запрашивает несовместимый режим блокировки для целой страницы или таблицы, содержащей эту строку, SQL Server легко определит конфликт благодаря предварительным блокировкам, которые первая транзакция установила для страницы и таблицы.
Предварительные или планируемые блокировки не мешают запросам на блокировку на более низких уровнях иерархии ресурсов.
Например, предварительная блокировка страницы не помешает другим транзакциям установить несовместимые режимы блокировок строк, находящихся на этой странице.
SQL Server динамически определяет, ресурсы каких типов блокировать.
Для идеального параллелизма лучше всего блокировать только то, что нужно, а именно обрабатываемые строки. Но блокировкам требуются ресурсы оперативной памяти и затраты на внутреннее управление, поэтому при выборе типов блокируемых ресурсов SQL учитывает и параллелизм, и системные ресурсы.
SQL Server может сначала установить мелкие блокировки (например, строки или страницы) и затем в определенных обстоятельствах попытаться расширить мелкие блокировки до крупных (например, таблицы).
В следующей таблице показаны режимы блокировки ресурсов, применяемые компонентом Database Engine.
Режим блокировки |
Описание |
Совмещаемая блокировка (S) |
Используется для операций считывания, которые не меняют и не обновляют данные (инструкция SELECT). |
Блокировка обновления (U) |
Применяется к тем ресурсам, которые могут быть обновлены. Предотвращает возникновение распространенной формы взаимоблокировки, возникающей тогда, когда несколько сеансов считывают, блокируют и затем, возможно, обновляют ресурс. |
Монопольная блокировка (Х) |
Используется для операций модификации данных, таких как инструкции INSERT, UPDATE или DELETE. Гарантирует, что несколько обновлений не будет выполнено одновременно для одного ресурса. |
Блокировка с намерением |
Используется для создания иерархии блокировок. Типы намеренной блокировки: с намерением совмещаемого доступа (IS), с намерением монопольного доступа (IX), а также совмещаемая с намерением монопольного доступа (SIX). |
Блокировка схемы |
Используется во время выполнения операции, зависящей от схемы таблицы. Типы блокировки схем: блокировка изменения схемы (Sch-S) и блокировка стабильности схемы (Sch-M). |
Блокировка массового обновления (BU) |
Используется, если выполняется массовое копирование данных в таблицу и указана подсказка TABLOCK. |
Диапазон ключей |
Защищает диапазон строк, считываемый запросом при использовании уровня изоляции сериализуемой транзакции. Запрещает другим транзакциям вставлять строки, что помогает запросам сериализуемой транзакции уточнять, были ли запросы запущены повторно. |
Блокировки с намерением
В компоненте Database Engine блокировки с намерением применяются для защиты размещения совмещаемой (S) или монопольной (X) блокировки ресурса на более низком уровне иерархии. Блокировки с намерением называются так потому, что их получают до блокировок более низкого уровня, то есть они обозначают намерение поместить блокировку на более низком уровне.
Блокировка с намерением выполняет две функции:
предотвращает изменение ресурса более высокого уровня другими транзакциям таким образом, что это сделает недействительной блокировку более низкого уровня;
повышает эффективность компонента Database Engine при распознавании конфликтов блокировок на более высоком уровне гранулярности.
Например, в таблице требуется блокировка с намерением совмещаемого доступа до того, как для страниц или строк этой таблицы будет запрошена совмещаемая (S) блокировка.
Если задать блокировку с намерением на уровне страницы, то другим транзакциям будет запрещено получать монопольную (X) блокировку для таблицы, содержащей эту страницу.
Блокировка с намерением повышает производительность, поскольку компонент Database Engine проверяет наличие таких блокировок только на уровне таблицы, чтобы определить, может ли транзакция безопасно получить для этой таблицы совмещаемую блокировку. Благодаря этому нет необходимости проверять блокировки в каждой строке и на каждой странице, чтобы убедиться, что транзакция может заблокировать всю таблицу.
В состав блокировок с намерением входят блокировка с намерением совмещаемого доступа (IS), блокировка с намерением монопольного доступа (IX), а также совмещаемая блокировка с намерением монопольного доступа (SIX).
Следующие три типа замков используются для блокирования на уровне строк и на уровне страниц:
разделяемый (shared, S);
исключительный (exclusive, X)
обновление (update, U).
Разделяемая блокировка (shared, S) резервирует ресурс (страницу или строку) только для чтения. Другие процессы не могут изменять заблокированный ресурс, пока блокировка не будет снята. С другой стороны, отдельные процессы могут устанавливать разделяемую блокировку для этого ресурса в то же самое время, т. е. другие процессы могут читать ресурс, заблокированный при помощи разделяемой блокировки.
Исключительная блокировка (exclusive, X); резервирует страницу или строку для исключительного использования в одной транзакции. Она используется для операторов DML (INSERT, Update или DELETE), которые изменяют ресурс.
Исключительная блокировка не может быть установлена, если некоторый другой процесс сохраняет разделяемую или исключительную блокировку на этот ресурс, т. е. для ресурса может существовать только одна исключительная блокировка. Как только на страницу (или строку) устанавливается исключительная блокировка, никакая другая блокировка не может быть установлена на тот же самый ресурс.
Блокировка на уровне страницы также допускает целевую блокировку (см. далее).
Блокировка обновления (update, U) может быть установлена, только если не существует другой блокировки обновления или исключительной блокировки. При этом она может быть установлена на объекты, которые уже имеют разделяемую блокировку.
В этом случае блокировка обновления получает и другую разделяемую блокировку на тот же объект. Если транзакция, которая изменяет объект, подтверждается, блокировка обновления заменяется на исключительную блокировку, если для объекта не существует других блокировок.
Блокировка обновления предотвращает некоторые общие типы взаимных блокировок (см. далее).
В таблице показана матрица совместимости разделяемых, исключительных блокировок и блокировок обновления (на уровне строк и на уровне страниц).
|
Разделяемая блокировка |
Блокировка обновления |
Исключительная блокировка |
Разделяемая блокировка |
Да |
Да |
Нет |
Блокировка обновления |
Да |
Нет |
Нет |
Исключительная блокировка |
Нет |
Нет |
Нет |
Эта матрица интерпретируется следующим образом: предположим, транзакция Т1 имеет блокировку, как показано в первом столбце матрицы; предположим также, что некоторая другая транзакция Т2 запрашивает блокировку, как задано в соответствующем заголовке столбца. В этом случае "Да" означает, что блокировка для Т2 возможна, в то время как "Нет" указывает на конфликт с существующей блокировкой.
На уровне таблицы существуют пять различных типов блокировок:
разделяемая (shared, S)
исключительная (exclusive, X);
разделяемая блокировка с намерением (intent shared, IS);
исключительная блокировка с намерением (intent exclusive, IX);
разделяемая блокировка с намерением исключительного доступа (shared with intent exclusive, SIX).
Разделяемые и исключительные блокировки соответствуют блокировкам на уровне строки (или страницы) с тем же именем.
Как правило, блокировка с намерением показывает намерение установить блокировку на ресурс низкого уровня в иерархии объектов базы данных.
Поэтому блокировки с намерением помещаются в иерархии объектов на один уровень выше того объекта, который этот процесс намеревается заблокировать. Это эффективный способ выяснить, возможна ли подобная блокировка, здесь также устанавливается запрет другим процессам блокировать более высокий уровень до того, как нужная блокировка будет достигнута.
В таблице показана матрица совместимости всех видов блокировок на уровне таблиц.
-
разделяемая (shared, S)
исключительная (exclusive, X);
разделяемая блокировка с намерением (intent shared, IS);
разделяемая блокировка с намерением исключительного доступа (shared with intent exclusive, SIX).
исключительная блокировка с намерением (intent exclusive, IX);
разделяемая (shared, S)
ДА
НЕТ
ДА
НЕТ
НЕТ
исключительная (exclusive, X);
НЕТ
НЕТ
НЕТ
НЕТ
НЕТ
разделяемая блокировка с намерением (intent shared, IS);
ДА
НЕТ
ДА
ДА
ДА
разделяемая блокировка с намерением исключительного доступа (shared with intent exclusive, SIX).
НЕТ
НЕТ
ДА
НЕТ
НЕТ
исключительная блокировка с намерением (intent exclusive, IX);
НЕТ
НЕТ
ДА
НЕТ
ДА
Гранулярность блокировок
Гранулярность блокировок указывает, какой блокируется ресурс в одной попытке блокирования. Система автоматически выбирает гранулярность блокировки.
Database Engine может блокировать такие ресурсы как:
строка;
страница;
индексный ключ или диапазон индексных ключей;
таблица;
экстент;
сама база данных.
Строка является наименьшим ресурсом, который может быть заблокирован. Поддержка блокировки на уровне строки включает и данные строк, и записи индексов. Блокировка на уровне строки означает, что блокируется только та строка, к которой осуществляется доступ приложения. Следовательно, все другие строки, принадлежащие той же странице, являются свободными и могут использоваться другими приложениями. Database Engine также может блокировать страницу, на которой хранится строка, которая должна быть заблокирована.
Если таблица является кластеризованной, то страницы данных хранятся на уровне листьев (кластеризованной) индексной структуры и поэтому блокируются именно они вместе с индексными ключами, а не строки.
Блокировка также выполняется для участков диска, называемых экстентами, которые имеют размер 64 Кбайт. Блокировка экстента устанавливается автоматически, когда растет таблица (или индекс) и требуется дополнительное дисковое пространство.
Гранулярность блокировок влияет на конкурентный доступ. Обычно, чем больше гранулярность блокировки, тем больше сокращается возможность одновременного доступа к данным. Это означает, что блокировка на уровне строки максимизирует конкурентный доступ, потом что она блокирует только одну строку, оставляя все другие свободными.
С другой стороны, накладные расходы системы увеличиваются, потому что каждая заблокированная строка требует одного замка.
Блокировка на уровне страницы (и блокировка на уровне таблицы) ограничивает доступность данных, но уменьшает накладные расходы системы.
Укрупнение блокировок
Если установлено много блокировок с одной и той же гранулярностью в процессе выполнения транзакции, Database Engine автоматически преобразует эти блокировки в блокировку на уровне таблицы. Этот процесс конвертирования множества блокировок уровней страницы, строки или индекса в блокировку уровня таблицы называется укрупнением блокировки.
Начало укрупнения определяется системой динамически и не требует конфигурирования. (В настоящий момент значением границы укрупнения является 5000 блокировок).
Основной проблемой, связанной с укрупнением блокировки, является то, сервер базы данных принимает решение, когда следует укрупнять конкретную блокировку, а это решение может не быть оптимальным для приложения с различными потребностями.
По этой причине SQL Server 2008 расширяет синтаксис оператора alter table, предоставляя возможность изменять механизм укрупнения блокировок.
Этот оператор теперь поддерживает опцию table со следующим синтаксисом:
SET ( LOCK_ESCALATION = { TABLE | AUTO | DISABLE } )
Опция table является значением по умолчанию; она задает, что укрупнение блокировки будет устанавливаться на уровне грануляции таблицы (как и в SQL Server 2005.).
Опция auto позволяет Database Engine выбрать гранулярность укрупнения блокировки, которая будет лучше подходить для таблицы схемы.
Наконец, опция disable позволяет отменить в большинстве случаев укрупнение блокировки.
Для воздействия на блокировки можно использовать или подсказки блокировок, или опцию lock_timeout в операторе set.
Подсказки блокировки
Подсказки блокировки задают тип блокировки, используемый Database Engine для блокировки данных таблицы. Подсказки блокировки на уровне таблицы могут быть использованы, когда запрашивается точная регулировка типов блокировки для требуемого ресурса. Подсказки блокировки перекрывают текущий уровень изоляции транзакции для данной сессии.
Все подсказки блокировки записываются как часть предложения from в операторе select.
Например, можно использовать подсказку блокировки updlock (устанавливает блокировку обновлений для каждой строки таблицы в процессе операций чтения). Все блокировки обновлений сохраняются до завершения транзакции.
О других подсказках блокировки см. справочную систему.
Отображение информации блокировки
Информация о блокировке может быть отображена динамически управляемым представлением, называемым sys.dm_tran_locks.
Представление sys.dm_tran_locks возвращает информацию о текущей активной блокировке менеджера ресурсов. Каждая строка отображает активный в настоящий момент запрос на блокировку, которая была предоставлена или предоставление которой ожидается.
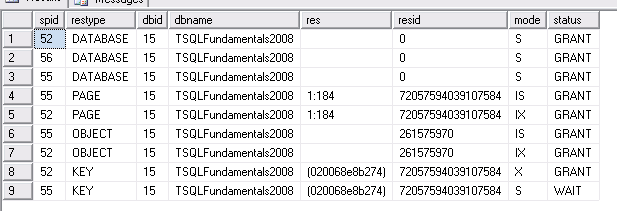
Столбцы этого представления соответствуют двум группам: ресурсам и запросам. Группа ресурсов, описывает ресурсы, которым предоставлена блокировка на основании запросов, а группа запросов описывает запросы на блокировку. Наиболее важными столбцами этого представления являются следующие:
resource_type указывает тип ресурса;
resource_database_id задает идентификатор базы данных, в которой находится этот ресурс;
request_mode задает режим запроса;
request_status задает текущее состояние запроса.
Пример: запрос для отображения всех блокировок, которые находятся в состоянии ожидания.
SELECT resource_type, DB_NAME(resource_database_id) as db_name,
request_session_id, request_mode, request_status FROM sys.dm_tran_locks
WHERE request_status = 'WAIT;'
Пример:
Для данного запроса обновления строки используется Соединение 1 и транзакция, для которой установлена монопольная блокировка на обновление данных, не завершена (остается открытой).
USE TSQLFundamentals2008;
-- Соединение 1
BEGIN TRAN;
UPDATE Production.Products
SET unitprice = unitprice + 1.00
WHERE productid = 2;
Для Соединения 2 запрашиваем ту же самую строку (этот сеанс блокируется)
-- Соединение 2
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Для Соединения 3 обращаемся к представлению sys.dm_tran_locks
SELECT
request_session_id AS spid,
resource_type AS restype,
resource_database_id AS dbid,
DB_NAME(resource_database_id) AS dbname,
resource_description AS res,
resource_associated_entity_id AS resid,
request_mode AS mode,
request_status AS status
FROM sys.dm_tran_locks;
Полученный результат:
Взаимная блокировка
Взаимная блокировка является особой проблемой одновременной paботы с базой данных, при которой две транзакции блокируют выполнение друг друга. Первая транзакция имеет блокировку на некоторый объект базы данных, к которому другая транзакция ожидает доступа, и наоборот. (Обычно несколько транзакций могут вызвать взаимную блокировку, когда они создают циклические зависимости.)
Взаимоблокировка возникает, когда две и более задач постоянно блокируют друг друга в ситуации, когда у каждой задачи заблокирован ресурс, который пытаются заблокировать другие задачи. На следующем графике приведена общая схема состояния взаимоблокировки, в которой:
Задача T1 блокирует ресурс R1 (изображается в виде стрелки, направленной от R1 к T1) и запросила блокировку ресурса R2 (изображается в виде стрелки, направленной от T1 к R2).
Задача T2 блокирует ресурс R2 (изображается в виде стрелки, направленной от R2 к T2) и запросила блокировку ресурса R1 (изображается в виде стрелки, направленной от T2 к R1).
Так как ни одна из задач не может продолжиться до тех пор, пока не будет доступен ресурс, а ни один из ресурсов не может быть освобожден до тех пор, пока задание не продолжится, наступает состояние взаимоблокировки.
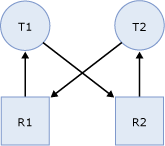
Рис.
"Мертвые", или тупиковые, блокировки характерны для многопользовательских систем. "Мертвая" блокировка возникает, когда две транзакции блокируют два блока данных и для завершения любой из них нужен доступ к данным, заблокированным ранее другой транзакцией. Для завершения каждой транзакции необходимо дождаться, пока блокированная другой транзакцией часть данных будет разблокирована. Но это невозможно, так как вторая транзакция ожидает разблокирования ресурсов, используемых первой.
Без применения специальных механизмов обнаружения и снятия "мертвых" блокировок нормальная работа транзакций будет нарушена. Если в системе установлен бесконечный период ожидания завершения транзакции (а это задано по умолчанию), то при возникновении "мертвой" блокировки для двух транзакций вполне возможно, что, ожидая освобождения заблокированных ресурсов, в тупике окажутся и новые транзакции.
Чтобы избежать подобных проблем, в среде MS SQL Server реализован специальный механизм разрешения конфликтов тупикового блокирования. Компонент SQL Server Database Engine автоматически обнаруживает цикл взаимоблокировки в SQL Server. Компонент Database Engine для устранения взаимоблокировки выбирает один из сеансов в качестве жертвы взаимоблокировки и прекращает выполнение текущей транзакции с ошибкой.
Для этих целей сервер снимает одну из блокировок, вызвавших конфликт, и откатывает инициализировавшую ее транзакцию. При выборе блокировки, которой необходимо пожертвовать, сервер исходит из соображений минимальной стоимости.
Полностью избежать возникновения "мертвых" блокировок нельзя. Хотя сервер и имеет эффективные механизмы снятия таких блокировок, все же при написании приложений следует учитывать вероятность их возникновения и предпринимать все возможные действия для предупреждения этого. "Мертвые" блокировки могут существенно снизить производительность, поскольку системе требуется достаточно много времени для их обнаружения, отката транзакции и повторного ее выполнения.
Для минимизации возможности образования "мертвых" блокировок при разработке кода транзакции следует придерживаться следующих правил:
выполнять действия по обработке данных в постоянном порядке, чтобы не создавать условия для захвата одних и тех же данных;
избегать взаимодействия с пользователем в теле транзакции;
минимизировать длительность транзакции и выполнять ее по возможности в одном пакете;
применять как можно более низкий уровень изоляции (см. далее).
Пример: ситуация взаимной блокировки между двумя транзакциями. Примечание: параллельность работы не может быть достигнута естественным образом при использовании малой по размерам базы данных sample, потому что каждая транзакция в ней выполняется очень быстро. В примере используется оператор waitfor DELAY для остановки выполнения транзакций на десять секунд для симуляции взаимной блокировки.
Первое соединение
BEGIN TRANSACTION
UPDATE employee
SET dept_no = 'd2'
WHERE emp_no = 9031
WAITFOR DELAY '00:00:10'
DELETE FROM works_on
WHERE emp_no = 18316
AND project_no = 'p2'
Система возвращает сообщение:
(1 row(s) affected)
Msg 1205, Level 13, State 45, Line 6
Transaction (Process ID 57) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
Второе соединение
BEGIN TRANSACTION
UPDATE works_on
SET job = 'Manager'
WHERE emp_no = 18316
AND project_no = 'p2'
WAITFOR DELAY '00:00:10'
UPDATE employee
SET emp_lname = 'Green'
WHERE emp_no = 9031
COMMIT
Можно повлиять на то, какая транзакция будет выбрана в качестве «жертвы», используя опцию deadlock_priority в операторе set. Существует 21 уровень приоритетов: значения от -10 до 10. Значение low соответствует -5, знание normal (значение по умолчанию) соответствует 0, a high соответствует 5. "Жертва'' сессии выбирается в соответствии с установленными в сессии приоритетами взаимных блокировок.
Уровни изоляции
В теории каждая транзакция должна быть полностью изолирована от всех других транзакций. Однако в подобном случае объем доступных данных значительно сокращается, потому что операции чтения в транзакции блокируются операциями записи в других транзакциях, и наоборот. Если доступность данных является важным требованием, это свойство должно быть ослаблено с использованием уровней изоляции.
Уровни изоляции задают степень, в которой обрабатываемые в транзакции данные будут защищены от изменений в других транзакциях.
Уровни изоляции определяют поведение параллельно работающих пользователей, читающих и записывающих данные.
Читающий процесс — это любая инструкция, извлекающая данные и применяющая по умолчанию совместную блокировку.
Пишущий процесс — это любая инструкция, модифицирующая таблицу и запрашивающая монопольную блокировку.
Нельзя управлять поведением пишущего процесса ни в отношении устанавливаемых блокировок, ни в отношении их продолжительности, но можно управлять читающими процессами.
Кроме того, управляя поведением читающей стороны, можно неявно влиять на поведение пишущей стороны. Делается это с помощью установки уровня изоляции, как на уровне сеанса с помощью параметра сеанса, так и на уровне запроса с помощью табличных рекомендаций или подсказок (table hint).
В стандарте определенны 4 уровня изоляции.
Каждый последующий уровень поддерживает требования предыдущего и налагает дополнительные ограничения:
уровень 0 – запрещение "загрязнения" данных. Этот уровень требует, чтобы изменять данные могла только одна транзакция; если другой транзакции необходимо изменить те же данные, она должна ожидать завершения первой транзакции;
уровень 1 – запрещение "грязного" чтения. Если транзакция начала изменение данных, то никакая другая транзакция не сможет прочитать их до завершения первой;
уровень 2 – запрещение неповторяемого чтения. Если транзакция считывает данные, то никакая другая транзакция не сможет их изменить. Таким образом, при повторном чтении они будут находиться в первоначальном состоянии;
уровень 3 – запрещение фантомов. Если транзакция обращается к данным, то никакая другая транзакция не сможет добавить новые или удалить имеющие строки, которые могут быть считаны при выполнении транзакции. Реализация этого уровня блокирования выполняется путем использования блокировок диапазона ключей. Подобная блокировка накладывается не на конкретные строки таблицы, а на строки, удовлетворяющие определенному логическому условию
Используя уровни изоляции, можно определить, какие проблемы конкурентного доступа могут появиться, а каких можно избежать.
Database Engine поддерживает следующие шесть уровней изоляции, которые управляют тем, как будут выполняться операции чтения данных:
read uncommitted;
read committed (по умолчанию);
repeatable read;
serializable;
snapshot (моментальный снимок);
read committed snapshot.
Уровни изоляции read uncommitted, repeatable read и serializable доступны только в пессимистической модели конкурентного доступа.
Уровень snapshot доступен только в оптимистической модели конкурентного доступа.
Уровень изоляции read committed доступен в обеих моделях.
Напоминание:
Пессимистическое управление параллелизмом
Система блокировок не допускает, чтобы изменение данных одними пользователями влияло на других пользователей. После того как действие пользователя приводит к блокировке, до тех пор пока инициатор ее не снимет, другие пользователи не могут выполнять действия, которые могут вызвать конфликт с блокировкой. Это называется пессимистическим управлением, поскольку в основном применяется в средах с большим количеством конфликтов данных, где затраты на защиту данных с помощью блокировок меньше затрат на откат транзакций в случае конфликтов параллелизма.
Управление оптимистическим параллелизмом
При оптимистическом управлении параллелизмом пользователи не блокируют данные на период чтения. Когда пользователь обновляет данные, система проверяет, вносил ли другой пользователь в них изменение после считывания. Если другой пользователь изменял данные, возникает ошибка. Как правило, при получении сообщения об ошибке пользователь откатывает транзакцию и начинает ее заново. Это называется оптимистическим управлением, поскольку в основном применяется в средах с небольшим количеством конфликтов данных, где затраты на периодический откат транзакции меньше затрат на блокировку данных при считывании.
Уровень изоляции snapshot логически эквивалентен уровню изоляции serializable с точки зрения проблем непротиворечивости данных, которые могут возникать.
Уровень изоляции read committed snapshot логически эквивалентен уровню изоляции read committed с точки зрения проблем непротиворечивости данных, которые могут возникать.
Но читающие процессы, использующие уровни изоляции, основанные на моментальных снимках данных (snapshot), не порождают совместных блокировок и поэтому читающие процессы не ждут, пока запрашиваемые данные монопольно заблокированы.
Задать уровень изоляции всего сеанса можно с помощью следующей команды:
SET TRANSACTION ISOLATION LEVEL <уровень изоляции>.
Для установки уровня изоляции запроса можно применить табличную рекомендацию.
SELECT ... FROM <таблица> WITH (<уровень изоляции >);
В параметре сеанса, если уровень изоляции формируется из нескольких слов, задается пробел между словами, например, repeatable read.
В рекомендации запроса не вставляется пробел между словами — например, WITH (repeatableread) .
Кроме того, у некоторых названий уровней изоляции, применяемых как табличные рекомендации, есть синонимы. Например, nolock эквивалентно за readuncommitted.
Уровень изоляции по умолчанию — read committed. Переопределение используемого по умолчанию уровня изоляции повлияет как на параллельную работу пользователей базы данных, так и на непротиворечивость получаемых ими данных.
Для четырех уровней изоляции, доступных в версиях, предшествующих SQL Server 2005, чем выше уровень изоляции, тем жестче и продолжительней блокировки, запрашиваемые читающей стороной; следовательно, чем выше уровень изоляции, тем выше согласованность или непротиворечивость данных и тем ниже степень параллелизма в работе. Обратное также верно.
В случае двух уровней изоляции, основанных на моментальных снимках данных (snapshot и read committed snapshot), SQL Server может хранить предыдущие зафиксированные версии строк отдельно в базе данных tempdb. Если текущая версия строки не согласована в соответствии с ожиданиями читающих процессов, вместо запрашивания совместных блокировок они могут обеспечить предполагаемый уровень изоляции без ожидания за счет получения предыдущих версий строк.
Уровень изоляции READ UNCOMMITTED
READ UNCOMMITTED — низший доступный уровень изоляции. На этом уровне читающий процесс не запрашивает совместную блокировку.
Процесс, не запрашивающий совместную блокировку, никогда не будет конфликтовать с пишущим процессом, удерживающим монопольную блокировку. Это означает, что читающий процесс может прочесть незафиксированные изменения (этот вариант называют грязным чтением, см. выше). Кроме того, это означает, что читающий процесс не будет сталкиваться с пишущим процессом, который запрашивает монопольную блокировку. Т.е., пишущий процесс может изменять данные в то время, как читающий процесс с уровнем изоляции read uncommitted читает данные.
Пример: незафиксированное чтение (грязное чтение)
Используется два подключения (Connection 1 и Connection 2).
В окне Connection 1 для открытия транзакции, увеличения на 1.00 текущей цены единицы товара 2 (19.00) и последующего запроса строки товара выполняется следующий программный код:
BEGIN TRAN;
UPDATE Production.Products
SET unitprice = unitprice + 1.00
WHERE productid = 2;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Результат: выдается измененное значение
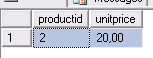
--ROLLBACK TRAN; Транзакция не завершена.
В окне Connection 2 выполняется запрос (управляем читающим процессом):
-- Connection 2
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Результат:
Т.е. считаны данные для незавершенной транзакции. Если выполнить откат транзакции в Connection 1 и выполнить запрос2!!!!!!!!
ROLLBACK TRAN;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
получим результат:
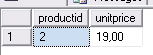
В Connection 2 значение 20, полученное считывающим процессом никогда не было зафиксировано. Это пример грязного чтения.
Уровень изоляции READ COMMITTED
Если нужно помешать чтению незафиксированных изменений, необходимо применять более высокий уровень изоляции.
Низший уровень изоляции, препятствующий грязному чтению, — read committed, служащий уровнем изоляции по умолчанию во всех версиях SQL Server.
Этот уровень изоляции позволяет читать только зафиксированные изменения. Он препятствует чтению незафиксированных изменений, требуя от читающего процесса получения совместной блокировки. Это означает, что если пишущий процесс удерживает монопольную блокировку, запрос читающего процесса на совместную блокировку вступит в конфликт с пишущим процессом, и читающий процесс будет вынужден ждать. Как только пишущая сторона зафиксирует транзакцию, читающая сможет получить совместную блокировку, и прочтет она только зафиксированные изменения.
Пример: показывает, что на уровне изоляции read committed, читающий процесс может прочесть только зафиксированные изменения.
В Соединении 1изменяем данные:
BEGIN TRAN;
UPDATE Production.Products
SET unitprice = unitprice + 1.00
WHERE productid = 2;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Результат: измененные данные, но транзакция не завершена
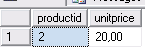
Соединение 2 не может прочетать незафиксированные данные (управляем читающим процессом):
USE TSQLFundamentals2008;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Результат: не выдается
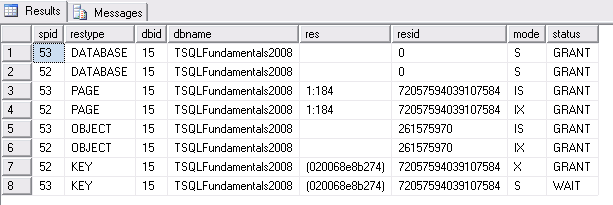
Используя системные представления можно получить информацию о процессах (запросы запускаются в соединении 3).
Выбор информации о блокировках:
-- Соединение 3
SELECT request_session_id AS spid,
resource_type AS restype,
resource_database_id AS dbid,
DB_NAME(resource_database_id) AS dbname,
resource_description AS res,
resource_associated_entity_id AS resid,
request_mode AS mode,
request_status AS status
FROM sys.dm_tran_locks;
Выбор информации о соединениях:
SELECT session_id AS spid,
connect_time,
last_read,
last_write,
most_recent_sql_handle
FROM sys.dm_exec_connections
WHERE session_id IN(52, 53);

Продолжение примера:
Откатим транзакцию в Соединении 1 (см. примечание 2):
Rollback Tran
Соединение 2 выдает результат исходных данных (т.к. транзакция не была завершена).
USE TSQLFundamentals2008;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
В отличие от read uncommitted на уровне изоляции read committed не получается грязных считываний. Читаются только зафиксированные изменений.
Что касается продолжительности блокировок, на уровне изоляции read committed читающий процесс только удерживает совместную блокировку на время работы с ресурсом. Блокировка не сохраняется до конца транзакции, в действительности она даже не сохраняется до завершения инструкции.
Это означает, что блокировка ресурса не сохраняется между двумя чтениями одного и того же ресурса данных в пределах одной транзакции. Следовательно, другая транзакция может модифицировать ресурс между этими двумя чтениями, и читающий процесс может получить разные значения в каждом из этих чтений. Подобную ситуацию называют чтениями без возможности повторения или несогласованной обработкой.
Уровень изоляции REPEATABLE READ
Если нужна уверенность в том, что никто не сможет изменить значения между двумя чтениями в пределах одной транзакции (запрещение неповторяемого чтения, см. выше), необходимо подняться до уровня изоляции REPEATABLE READ.
На этом уровне изоляции читающему процессу для чтения не только требуется совместная блокировка, но эта блокировка сохраняется до завершения транзакции.
Это означает, что как только установлена совместная блокировка ресурса данных для его чтения, никто не сможет получить монопольную блокировку для модификации этого ресурса до тех пор, пока читающий процесс не завершит транзакцию.
В этом случае гарантируется чтение с повторяемостью результатов или согласованная обработка.
Пример: чтение с повторяемостью результатов.
--Соединение 1
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN TRAN;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
--COMMIT TRAN;
Не завершаем транзакцию и выдается исходный результат:
Это соединение (Соединение 1) все еще удерживает совместную блокировку строки с товаром 2, поскольку на уровне изоляции repeatable read совместные блокировки удерживаются до конца транзакции.
В окне Соединение 2 выполняется следующий программный код, чтобы попытаться модифицировать строку с товаром 2:
-- Соединение 2
UPDATE Production.Products
SET unitprice = unitprice + 1.00
WHERE productid = 2;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Попытка блокируется и результат не выдается (запрос обновляющего процесса на монопольную блокировку конфликтует с совместной блокировкой, предоставленной читающему процессу).
Если бы читающий процесс выполнялся на рассмотренных уровнях изоляции read uncommitted или read committed, в этот момент он не удерживал бы совместную блокировку, и попытка модификации строки завершилась бы успешно.
В Соединение 1 выполняем запрос и фиксируем транзакцию (Обратите внимание на использовании в этом запросе COMMIT TRAN без BEGIN TRAN):
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
COMMIT TRAN;
Результат:
Теперь транзакция читающего процесса зафиксирована, и совместная блокировка снята, модифицирующему процессу в окне Соединения 2 предоставлена монопольная блокировка, которой он дожидался, и процесс может модифицировать строку.
-- Соединение 2
UPDATE Production.Products
SET unitprice = unitprice + 1.00
WHERE productid = 2;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
Выдается результат:
Еще одна ситуация, возникновению которой препятствует уровень изоляции REPEATABLE READ, но не более низкие уровни изоляции, называется потерянным обновлением.
Потеря обновления происходит, когда две транзакции читают значение, выполняют вычисления, основанные на том, что они прочли, а затем обновляют значение. Поскольку на уровнях изоляции более низких, чем REPEATABLE READ после считывания блокировка ресурса не сохраняется, обе транзакции могут обновить значение, и "победит" та из них, которая запишет обновление последней, переопределив значение, обновленное другой транзакцией.
На уровне изоляции REPEATABLE READ обе стороны сохраняют свои совместные блокировки после первого чтения, поэтому позже никто не может установить монопольную блокировку для обновления. Ситуация приводит к взаимоблокировке или тупику и конфликт обновления устраняется.
Уровень изоляции serializable.
Выполняясь на уровне изоляции REPEATABLE READ, читающие процессы сохраняют совместные блокировки до конца транзакции. Следовательно, гарантируется повторяемость результатов при считывании строк, которые были прочитаны первый раз в транзакции.
Однако эта транзакция блокирует ресурсы (например, строки), которые запрос нашел в процессе выполнения в первый раз, а не строки, которых там не было во время выполнения запроса. Следовательно, второе чтение в той же самой транзакции может также вернуть и новые строки.
Эти новые строки называют фантомами или призраками, а подобные чтения — фантомными чтениям. Такая ситуация возникает, если между двумя чтениями другая транзакция добавляет новые строки, удовлетворяющие условию фильтра читающего запроса.
Для предотвращения фантомных считываний необходимо перейти к более высокому уровню изоляции serializable.
По большей части уровень изоляции serializable ведет себя так же, как и repeatable Read, а именно, для чтения он требует от читающего процесса получения совместной блокировки и сохранения ее до завершения транзакции.
Но уровень изоляции serializable добавляет еще один аспект — логически этот уровень изоляции заставляет Читающий процесс блокировать целый диапазон ключей (строк), которые удовлетворяют условию фильтрации запроса читающего процесса.
Это означает, что процесс блокирует не только существующие строки, удовлетворяющие условию фильтра запроса, но и будущие строки. Или более точно, он блокирует попытки других транзакций добавить строки, удовлетворяющие условию фильтра запроса читающей стороны.
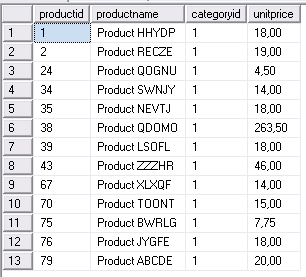
Пример:
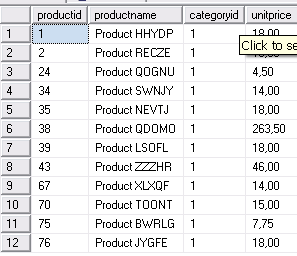
-- Соединение 1
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRAN
SELECT productid, productname, categoryid, unitprice
FROM Production.Products
WHERE categoryid = 1;
Результат:
В Соединении 2 выполняется добавление записи
INSERT INTO Production.Products
(productname, supplierid, categoryid,
unitprice, discontinued)
VALUES('Product ABCDE', 1, 1, 20.00, 0); --вставляется строка, соответствующая условию отбора в Соединении 1.
Попытка блокируется (процесс висит).
После фиксирования транзакции в Соединении 1 (COMMIT TRAN) будет выдан то же результат, без строк-фантомов.
После фиксирования транзакции читающего процесса в Соединении 1 совместная блокировка с диапазона строк снята, модифицирующий процесс в окне Соединения 2 получит монопольную блокировку, которой он дожидается, и вставит строку.
Результат:
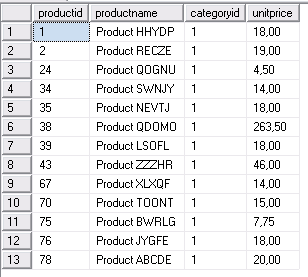
Рассмотрим этот процесс с уровнем изоляции REPEATABLE READ.
В Соединении 2 выполнена вставка, несмотря на незавершенную транзакцию в Соединении 1. После завершения транзакции в Соединении 1 выдается результат с добавленной строкой (фантомом).
Уровень изоляции SNAPSHOT
Нa уровне изоляции snapshot при чтении читающему процессу гарантируется получение последней зафиксированной версии строки, которая имеется в наличии в момент запуска транзакции.
Это означает, что обеспечено получение фиксированных и повторяемых считываний и отсутствие фантомных считываний, так же, как и на уровне изоляции SERIALIZABLE. Но вместо применения совместных блокировок этот уровень изоляции полагается на версии строк (хранятся в базе данных tempdb).
Для разрешения работы на уровне изоляции snapshot необходимо установить параметр на уровне базы данных (ALTER DATABASE имя_базы SET ALLOW_SNAPSHOT_ISOLATION ON;)
Уровень изоляции snapshot предотвращает конфликты обновления, но в отличие от уровней изоляции repeatable read и serializable, делающих это генерацией взаимоблокировки, он аварийно завершает транзакцию, указывая, что обнаружен конфликт обновления.
Уровень изоляции snapshot может находить конфликты обновления, просматривая хранилище версий. Он может определить, модифицировала ли другая транзакция данные между чтением и записью, выполнявшимися в транзакции.
Уровень изоляции READ COMMITTED SNAPSHOT
Уровень изоляции read committed snapshot также основан на версиях строк. Он отличается от уровня изоляции snapshot тем, что вместо последней зафиксированной версии строки, имевшейся в наличии при старте транзакции, читающий процесс получает последнюю зафиксированную версию строки, имевшуюся в момент старта инструкции.
Кроме того, уровень изоляции не обнаруживает конфликты обновления.
В результате его логическое поведение очень похоже на уровень изоляции read committed, за исключением того, что читающим процессам не нужно устанавливать совместные блокировки и ждать, если необходимый ресурс монопольно заблокирован.
Для разрешения работы на уровне изоляции read committed snapshot необходимо установить параметр на уровне базы данных.
Сводные данные об уровнях изоляции.
Сводная информация о логической непротиворечивости или согласованности данных, которые могут возникнуть на каждом уровне изоляции. Показано, обнаруживает ли уровень изоляции конфликты обновления и применяет ли версии строк.
-
Уровень изоляции
Незафиксированные считывания?
Повторяемость считываний?
Потерянные обновления?
Фантомные считывания
Обнаружение
конфликтов
обновления?
Использование версий строк?
READ UNCOMMITTED
Да
Да
Да
Да
Нет
Нет
READ COMMITTED
Нет
Да
Да
Да
Нет
Нет
READ COMMITTED SNAPSHOT
Нет
Да
Да
Да
Нет
Да
REPEATABLE READ
Нет
Нет
Нет
Да
Нет
Нет
SERIALIZABLE
Нет
Нет
Нет
Нет
Нет
Нет
SNAPSHOT
Нет
Нет
Нет
Нет
Да
Да