

Часть II
Основы языка
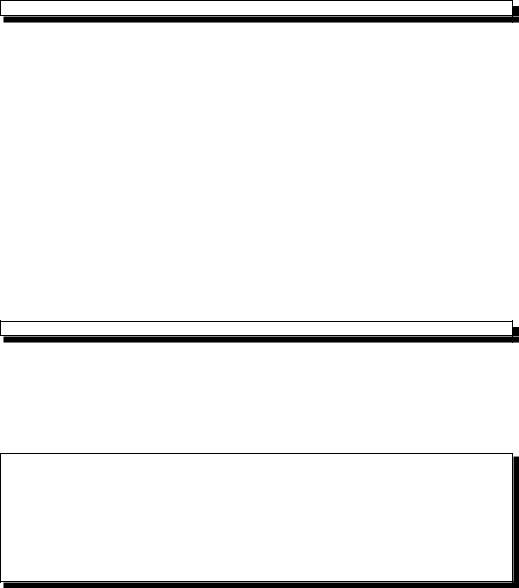
Код программы и данные, которыми программа манипулирует, записываются в память компьютера в виде последовательности битов. Бит – это мельчайший элемент компьютерной памяти, способная хранить либо 0, либо 1. На физическом уровне это соответствует электрическому напряжению, которое, как известно, либо есть , либо нет. Посмотрев на содержимое памяти компьютера, мы увидим что-нибудь вроде:
00011011011100010110010000111011 ...
Очень трудно придать такой последовательности смысл, но иногда нам приходится манипулировать и подобными неструктурированными данными (обычно нужда в этом возникает при программировании драйверов аппаратных устройств). С++ предоставляет набор операций для работы с битовыми данными. (Мы поговорим об этом в главе 4.)
Как правило, на последовательность битов накладывают какую-либо структуру, группируя биты в байты и слова. Байт содержит 8 бит, а слово – 4 байта, или 32 бита. Однако определение слова может быть разным в разных операционных системах. Сейчас начинается переход к 64-битным системам, а еще недавно были распространены системы с 16-битными словами. Хотя в подавляющем большинстве систем размер байта одинаков, мы все равно будем называть эти величины машинно-зависимыми.
Так выглядит наша последовательность битов, организованная в байты. Рис 1.
Адресуемая машинная память
Теперь мы можем говорить, например, о байте с адресом 1040 или о слове с адресом 1024 и утверждать, что байт с адресом 1032 не равен байту с адресом 1040.
Однако мы не знаем, что же представляет собой какой-либо байт, какое-либо машинное слово. Как понять смысл тех или иных 8 бит? Для того чтобы однозначно интерпретировать значение этого байта (или слова, или другого набора битов), мы должны знать тип данных, представляемых данным байтом.
С++ предоставляет набор встроенных типов данных: символьный, целый, вещественный – и набор составных и расширенных типов: строки, массивы, комплексные числа. Кроме того, для действий с этими данными имеется базовый набор операций: сравнение, арифметические и другие операции. Есть также операторы переходов, циклов, условные операторы. Эти элементы языка С++ составляют тот набор кирпичиков, из которых можно построить систему любой сложности. Первым шагом в освоении С++ станет изучение перечисленных базовых элементов, чему и посвящена часть II данной книги.
Глава 3 содержит обзор встроенных и расширенных типов, а также механизмов, с помощью которых можно создавать новые типы. В основном это, конечно, механизм классов, представленный в разделе 2.3. В главе 4 рассматриваются выражения, встроенные операции и их приоритеты, преобразования типов. В главе 5 рассказывается об инструкциях языка. И наконец глава 6 представляет стандартную библиотеку С++ и контейнерные типы – вектор и ассоциативный массив.
3. Типы данных С++
В этой главе приводится обзор встроенных, или элементарных, типов данных языка С++. Она начинается с определения литералов, таких, как 3.14159 или pi, а
затем вводится понятие переменной, или объекта, который должен принадлежать к одному из типов данных. Оставшаяся часть главы посвящена подробному описанию каждого встроенного типа. Кроме того, приводятся производные типы данных для строк и массивов, предоставляемые стандартной библиотекой С++. Хотя эти типы не являются элементарными, они очень важны для написания настоящих программ на С++, и нам хочется познакомить с ними читателя как можно раньше. Мы будем называть такие типы данных расширением базовых типов С++.
3.1. Литералы
В С++ имеется набор встроенных типов данных для представления целых и вещественных чисел, символов, а также тип данных “символьный массив”, который служит для хранения символьных строк. Тип char служит для хранения отдельных символов и небольших целых чисел. Он занимает один машинный байт. Типы short, int и long предназначены для представления целых чисел. Эти типы различаются только диапазоном значений, которые могут принимать числа, а конкретные размеры перечисленных типов зависят от реализации. Обычно short занимает половину машинного слова, int – одно слово, long – одно или два слова. В 32-битных системах int и long, как правило, одного размера.
Типы float, double и long double предназначены для чисел с плавающей точкой и различаются точностью представления (количеством значащих разрядов) и диапазоном. Обычно float (одинарная точность) занимает одно машинное слово, double (двойная точность) – два, а long double (расширенная точность) – три.
char, short, int и long вместе составляют целые типы, которые, в свою очередь, могут быть знаковыми (signed) и беззнаковыми (unsigned). В знаковых типах самый левый бит служит для хранения знака (0 – плюс, 1 – минус), а оставшиеся биты содержат значение. В беззнаковых типах все биты используются для значения. 8-битовый тип signed char может представлять значения от -128 до 127, а unsigned char – от 0 до
255.
Когда в программе встречается некоторое число, например 1, то это число называется литералом, или литеральной константой. Константой, потому что мы не можем изменить его значение, и литералом, потому что его значение фигурирует в тексте программы. Литерал является неадресуемой величиной: хотя реально он, конечно, хранится в памяти машины, нет никакого способа узнать его адрес. Каждый литерал имеет определенный тип. Так, 0 имеет тип int, 3.14159 – тип double.
Литералы целых типов можно записать в десятичном, восьмеричном и шестнадцатеричном виде. Вот как выглядит число 20, представленное десятичным, восьмеричным и шестнадцатеричным литералами:
20 // десятичный
024 // восьмеричный 0х14 // шестнадцатеричный
Если литерал начинается с 0, он трактуется как восьмеричный, если с 0х или 0Х, то как шестнадцатеричный. Привычная запись рассматривается как десятичное число.
По умолчанию все целые литералы имеют тип signed int. Можно явно определить целый литерал как имеющий тип long, приписав в конце числа букву L (используется как прописная L, так и строчная l, однако для удобства чтения не следует употреблять
строчную: ее легко перепутать с 1). Буква U (или u) в конце определяет литерал как unsigned int, а две буквы – UL или LU – как тип unsigned long. Например:
128u 1024UL 1L 8Lu
Литералы, представляющие действительные числа, могут быть записаны как с десятичной точкой, так и в научной (экспоненциальной) нотации. По умолчанию они имеют тип double. Для явного указания типа float нужно использовать суффикс F или f, а для long double - L или l, но только в случае записи с десятичной точкой. Например:
|
3.14159F |
0/1f |
12.345L 0.0 |
|
|
|
|
||||
|
3el |
1.0E-3E 2. |
1.0L |
|
|
|
|
|
|
|
|
Слова true и false являются литералами типа bool.
Представимые литеральные символьные константы записываются как символы в одинарных кавычках. Например:
'a' '2' ',' ' ' (пробел)
Специальные символы (табуляция, возврат каретки) записываются как escape- последовательности . Определены следующие такие последовательности (они начинаются с символа обратной косой черты):
новая строка \n горизонтальная табуляция \t
забой |
\b |
вертикальная табуляция |
\v |
возврат каретки |
\r |
прогон листа |
\f |
звонок |
\a |
обратная косая черта |
\\ |
вопрос |
\? |
одиночная кавычка |
\' |
двойная кавычка |
\" |
escape-последовательность общего вида имеет форму \ooo, где ooo – от одной до трех восьмеричных цифр. Это число является кодом символа. Используя ASCII-код, мы можем написать следующие литералы:
|
\7 |
(звонок) |
\14 (новая строка) |
|
|
|
|||
|
\0 |
(null) |
\062 ('2') |
|
|
|
|
|
|
Символьный литерал может иметь префикс L (например, L'a'), что означает специальный тип wchar_t – двухбайтовый символьный тип, который применяется для хранения символов национальных алфавитов, если они не могут быть представлены обычным типом char, как, например, китайские или японские буквы.
Строковый литерал – строка символов, заключенная в двойные кавычки. Такой литерал может занимать и несколько строк, в этом случае в конце строки ставится обратная косая черта. Специальные символы могут быть представлены своими escape- последовательностями. Вот примеры строковых литералов:
"" (пустая строка) "a"
"\nCC\toptions\tfile.[cC]\n" "a multi-line \
string literal signals its \ continuation with a backslash"
Фактически строковый литерал представляет собой массив символьных констант, где по соглашению языков С и С++ последним элементом всегда является специальный символ с кодом 0 (\0).
Литерал 'A' задает единственный символ А, а строковый литерал "А" – массив из двух элементов: 'А' и \0 (пустого символа).
Раз существует тип wchar_t, существуют и литералы этого типа, обозначаемые, как и в случае с отдельными символами, префиксом L:
L"a wide string literal"
Строковый литерал типа wchar_t – это массив символов того же типа, завершенный нулем.
Если в тесте программы идут подряд два или несколько строковых литералов (типа char или wchar_t), компилятор соединяет их в одну строку. Например, следующий текст
"two" "some"
породит массив из восьми символов – twosome и завершающий нулевой символ.
// this is not a good idea
Результат конкатенации строк разного типа не определен. Если написать:
"two" L"some"
то на каком-то компьютере результатом будет некоторая осмысленная строка, а на другом может оказаться нечто совсем иное. Программы, использующие особенности реализации того или иного компилятора или операционной системы, являются непереносимыми. Мы крайне не рекомендуем пользоваться такими конструкциями.
Упражнение 3.1
(a)'a', L'a', "a", L"a"
(b)10, 10u, 10L, 10uL, 012, 0*C
Объясните разницу в определениях следующих литералов:
(c) 3.14, 3.14f, 3.14L
Упражнение 3.2