

4.2 Прямая адресация; таблицы с прямой адресацией
Прямая адресация применима, если количество возможных ключей невелико. Пусть возможными ключами являются числа из множества U = {0,1,... ,m–1} (число т не очень велико). Предположим также, что ключи всех элементов различны.
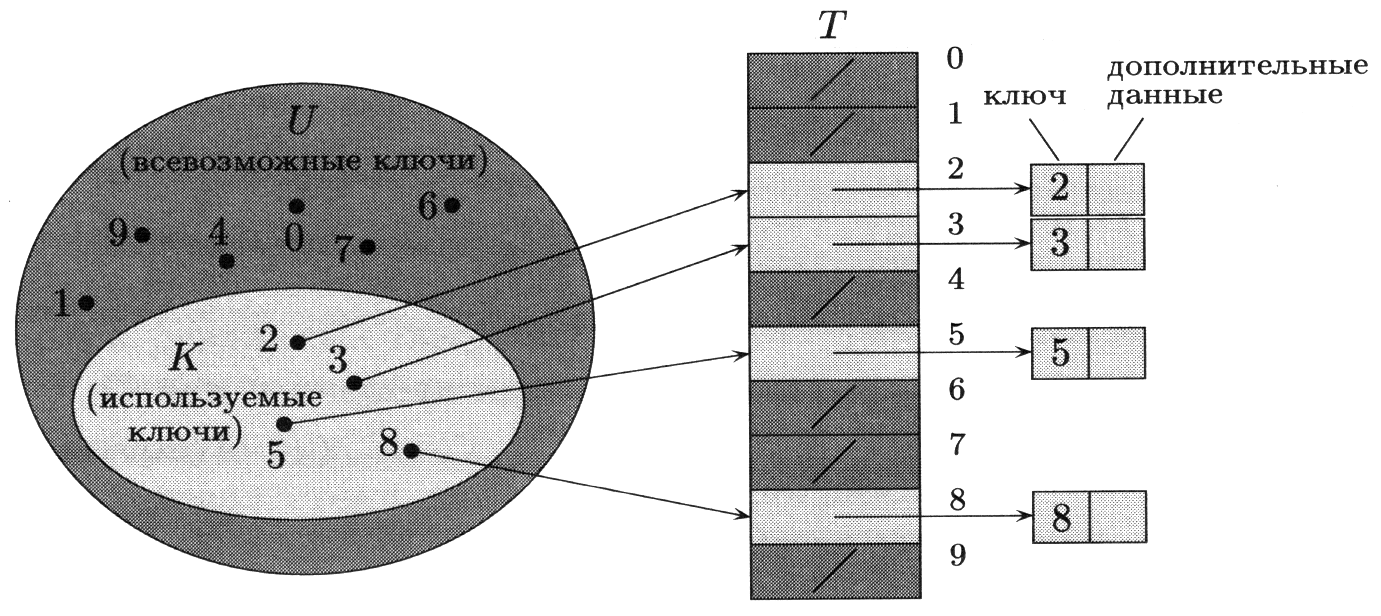
Рисунок 4.2 – Реализация динамического множества с помощью таблицы с прямой адресацией
Для хранения множества используется массив Т[0..т – 1], называемый таблицей с прямой адресацией (direct-address table). Каждая позиция, или ячейка, (position, slot) соответствует определённому ключу из множества U.
T[k] – место, предназначенное для записи указателя на элемент с ключом k; если элемента с ключом k в таблице нет, то T[k] = NIL). Реализация словарных операций тривиальна:

Листинг 4.1 – Словарные операции при прямой адресации
Каждая из этих операций требует времени O(1).
Иногда можно сэкономить место, записывая в таблицу Т не указатели на элементы множества, а сами эти элементы. Можно обойтись и без отдельного поля «ключ»: ключом служит индекс в массиве. Впрочем, если мы обходимся без ключей и указателей, то надо иметь способ указать, что данная позиция свободна.
4.3 Хеш – таблицы; возникновение коллизий и их разрешение
Прямая адресация обладает очевидным недостатком: если множество U всевозможных ключей велико, то хранить в памяти массив Т размером U непрактично, а то и невозможно. Кроме того, если число реально присутствующих е таблице записей мало по сравнению с |U|, то много памяти тратится зря.
Если количество записей в таблице существенно меньше, чем количество всевозможных ключей, то хеш-таблица занимает гораздо меньше места, чем таблица с прямой адресацией. Именно, хеш-таблица требует памяти объёмом Θ(|К|) где К – множество записей, при этом время поиска в хеш-таблице по-прежнему есть О(1) (единственное «но» в том, что на сей раз это – оценка в среднем, а не в худшем случае, да и то только при определённых предположениях).
В то время как при прямой адресации элементу с ключом k отводится позиция номер k, при хешировании этот элемент записывается в позицию номер h(k) в хеш-таблице (hash table) T[0..m – 1], где
h: U→ {0, l,...,m – l}
–некоторая функция, называемая хеш-функцией (hash function). Число h(k) называют хеш-значением (hash value) ключа k. Использование массива длины т, а не |U|, дает экономию памяти.
Однако, проблема заключается в том, что хеш-значения двух разных ключей могут совпасть. В таких случаях говорят, что случилась коллизия, или столкновение (collision). К счастью, эта проблема разрешима: хеш-функциями можно пользоваться и при наличии столкновений.
Хотелось бы выбрать хеш-функцию так, чтобы коллизии были невозможны. Но при |U| > т неизбежно существуют разные ключи, имеющие одно и то же хеш-значение. Так что можно лишь надеяться, что для фактически присутствующих в множестве ключей коллизий будет немного, и быть готовыми обрабатывать те коллизии, которые всё-таки произойдут.

Рисунок 4.3 – Использование хеш-функции для отображения ключей в позиции хеш-таблицы (хеш-значения ключей k2 и k5 совпадают – имеет место коллизия)
При выборе хеш-функции обычно не известно, какие именно ключи будут храниться. Но на всякий случай разумно сделать хеш-функцию в каком-то смысле «случайной», хорошо перемешивающей ключи по ячейкам (английский глагол "to hash" означает «мелко порубить, помешивая»). Разумеется, «случайная» хеш-функция должна всё же быть детерминированной в том смысле, что при ее повторных вызовах с одним и тем же аргументом она должна возвращать одно и то же хеш-значение.
В этом разделе будет рассмотрен простейший способ обработки (как говорят, «разрешения») коллизий с помощью цепочек (другим способом разрешения коллизий является открытая адресация, он будет рассмотрен в следующем подразделе).