

1.2 Построение моделей множественной регрессии
С целью математического описания конкретного вида зависимостей с использованием регрессионного анализа подбирают класс функций, связывающих результативный показатель y и аргументы x1, x2,…,хk , отбирают наиболее информативные аргументы, вычисляют оценки неизвестных значений параметров уравнения связи и анализируют точность полученного уравнения.
Функция f(x1, x2,…,хk ), описывающая зависимость условного среднего значения результативного признака у от заданных значений аргументов, называется функцией (уравнением) регрессии.
Для точного описания уравнения регрессии необходимо знать условный закон распределения результативного показателя у. В статистической практике такую информацию получить обычно не удается, поэтому ограничиваются поиском подходящих аппроксимаций для функции f( x1, x2,…,хk ), основанных на исходных статистических данных.
В рамках отдельных модельных допущений о типе распределения вектора показателей (у, x1, x2,…,хk ) может быть получен общий вид уравнения регрессии f(x)=M(y/x) x=( x1, x2,…,хk )T
Если многомерная случайная величина (у, x1, x2,…,хk ) подчиняется (k +1)-мерному нормальному закону распределения, то уравнение регрессии результативного показателя у по объясняющим переменным x1, x2,…,хk имеет линейный по X вид.
Однако в статистической практике обычно приходится ограничиваться поиском подходящих аппроксимаций для неизвестной истинной функции регрессии f(x), так как исследователь не располагает точным знанием условного закона распределения вероятностей анализируемого результатирующего показателя у при заданных эначениях аргументов х=х.
Рассмотрим взаимоотношение между истиной f(х)= M(y/x), модельной Y и оценкой X регрессии.
Пусть результативный показатель у связан с аргументом х соотношением::
y
=
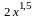 +
e
,
+
e
,
где e - случайная величина, имеющая нормальный закон распределения, причем М e = 0 и
D
e
=
 .
.
Истинная функция регрессии в этом случае имеет вид:
F(x)
= M(y/x)
= 2x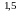 .
.
Предположим, что точный вид истинного уравнения регрессии нам не известен, но мы располагаем девятью наблюдениями над двумерной случайной величиной, связанной соотношением уi = 2x + ei, и предcтавленной на рисунке:
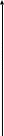 у
у
f(x)


 60
60
50
y
 30
30
20
 10
10
x

0 2 4 6 8 10 Взаимное расположение истинной f(x) и теоретической у модели регрессии.
Расположение точек на рисунке позволяет ограничиться классом линейных зависимостей вида: у = b0 + b1 x.
С помощью метода наименьших квадратов найдем оценку уравнения регрессии
у = b0 +b1 x.
Дли
сравнения на рисунке приводятся графики
истинной функции регрессии f{х)
=2x
,
теоретической
аппроксимирующей функции регрессии
 =
b0
+ b1
x.
К последней сходится по вероятности
оценка уравнения
регрессии
при
неограниченном увеличении объема
выборки (n
=
b0
+ b1
x.
К последней сходится по вероятности
оценка уравнения
регрессии
при
неограниченном увеличении объема
выборки (n ).
).
Поскольку мы ошиблись в выборе класса функции регрессии, что, к сожалению, достаточно часто встречается в практике статистических исследований, то наши статистические выводы и оценки не будут обладать свойством состоятельности, т.е., как бы мы не увеличивали объем наблюдений, наша выборочная оценка не будет сходиться к истинной функции регрессии f(х).
Если
бы мы правильно выбрали класс функций
регрессии, то неточность в описании
f(x)
с помощью
объяснялась бы только ограниченностью
выборки и, следовательно, она могла бы
быть сделана сколько угодно малой при
n
 .
.
С целью наилучшего восстановления по исходным статистическим данным условного значения результатирующего показателя у(х) и неизвестной функции регрессии f(x) = M(y/x) наиболее часто используют следующие критерии адекватности (функции потерь).
1.
Метод
наименьших квадратов,
согласно которому минимизируется
квадрат отклонения наблюдаемых значений
результативного показателя yi(i=1,2,…,n)
от модельных значений
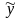 i
= f(xi,
b),
где b
= (b0,
b1,…,bk)
i
= f(xi,
b),
где b
= (b0,
b1,…,bk) -
коэффициенты уравнения регрессии, xi
–
значение вектора аргументов в i-м
наблюдении:
-
коэффициенты уравнения регрессии, xi
–
значение вектора аргументов в i-м
наблюдении:
 i-f(x1/β))2→minβ
i-f(x1/β))2→minβ
Решается
задача отыскания оценки
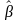 вектора b.
Получаемая регрессия называется
среднеквадратической.
вектора b.
Получаемая регрессия называется
среднеквадратической.
2.
Метод
наименьших модулей,
согласно которому минимизируется сумма
абсолютных отклонений наблюдаемых
значений результативного показателя
от модульных значений
 = f(xi,
b),
т.е.
= f(xi,
b),
т.е.
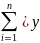 1-f(x1/β)|→minβ
1-f(x1/β)|→minβ
Получаемая регрессия называется среднеабсолютной (медианой).
3. Метод минимакса сводится к минимизации максимума модуля отклонения наблюдаемого значения результативного показателя yi от модельного значения f(xi, b), т.е.
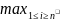 |y1-f(xi/β)|→minβ
|y1-f(xi/β)|→minβ
Получаемая при этом регрессия называется минимаксной.
В практических положениях часто встречаются задачи, в которых изучается случайная величина у, зависящая от некоторого множества переменных x1, x2,…,хk и неизвестных параметров bj(j=0,1,2,…,k). Будем рассматривать (у, x1, x2,…,хk ) как
(k +1) – мерную генеральную совокупность, из которой взята случайная выборка объемов n, где (уi,xi1,xi2,…,xik) результат i-го наблюдения i=1,2,…,n. Требуется по результатам наблюдений оценить неизвестные параметры bj(j=0,1,2,…,k).
Описанная выше задача относится к задачам регрессионного анализа.
Регрессионным анализом называется метод статистического анализа зависимости случайной величины у от переменных xj(j=1,2,…,k), рассматриваемых в регрессионном анализе как неслучайные величины, независимо от истинного закона распределения xj.