

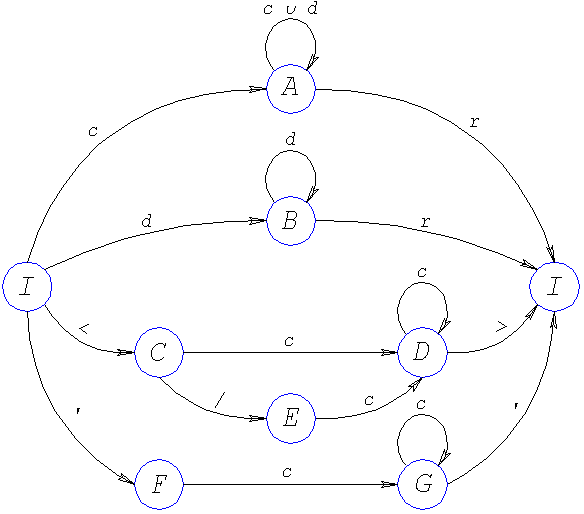
3.1. Грамматика лексических единиц и структура лексем
1. Грамматика идентификатора
I cA
A cA
AdA
A rI
c– буква
d– цифра
r– разделитель (‘,’ , ’ ‘ , ’<’)
2. Грамматика числа
I dB
BdB
B rB
d– цифра
r– разделитель (‘,’ , ’ ‘ , ’<’)
3. Грамматика служебного слова
I<C
C /E
E cD
CcD
DcD
D>I
c– буква
4. Грамматика констант
I’F
FcG
GcG
G’I
c– буква
3.2. Диаграмма состояний лексического анализатора

3.3. Структуры данных и символы действия
При работе лексический анализатор формирует таблицы идентификаторов, чисел и лексем, имеющие определенную структуру. Он также использует и готовые (заранее известные таблицы). К заранее известным можно отнести такие таблицы как таблица служебных слов, таблица разделителей, таблицы констант. Все заранее известные таблицы представим в памяти в виде массивов, а неизвестные таблицы будем формировать в процессе работы лексического анализатора в виде линейных односвязных списков записей (структур). Последовательность лексем тоже представим в виде линейного односвязного списка.
Структуры данных:
{ Таблица служебных слов }
TSSl: array[1..16] of StrType = ('char','/char','boolean','/boolean',
'arr','/arr','earr','/earr','ass','/ass',
'and','/and','or','/or','not','/not');
{ Таблица логических констант }
TLog: array[1..2] of StrType = ('true','false');
{ Таблица символьных констант }
TChr: array[1..36] of Char =('a','b','c','d','e','f','g','h','i','j','k','l',
'm','n','o','p','q','r','s','t','u','v','w','x',
'y','z','0','1','2','3','4','5','6','7','8','9');
{ Таблица разделителей }
TRzd = ',';
type
TPerem=(TChar,TBool); { - Возможный тип переменной }
TIdent=string[16]; { - Макс. длина идентификатора }
TypeLx=(Idt,Num,SSl,Log,Chr,Rzd);
{ - Типы лексем:
Idt - идентификатор - a, b[2] Num - целое число (б/зн) - 12, 2341
Rzd – разделитель - "," SSl - служебное слово - <and>, </or>
Log - логическая константа - true, false Chr - символьная константа - 'a', 'c' }
{ Типы, определяющие: }
TAdrTP =^TElTP; { - таблицу переменных - ТП }
TAdrTSP =^TElTSP; { - таблицу симв. представления - ТСП }
TAdrTZ =^TElTZ; { - таблицу значений - ТЗ (ячейки памяти)}
TAdrTN =^TElTN; { - таблицу чисел - ТЧ }
TAdrTL =^TElTL; { - таблицу лексем - ТЛ }
TElTP= record { Тип эл-та ТП: }
TypeP :TPerem; { - тип переменной (TBool, TChar) }
PointTSP:TAdrTSP; { - указатель на эл-т ТСП }
PointTZ :TAdrTZ; { - указатель на эл-т ТЗ }
Dim :Word; { - кол-во эл-тов (+1) в ТЗ
если Dim > 0 , то это - массив }
NextP :TAdrTP; { - указатель на след. эл-т ТП }
end;
TElTSP= record { Тип эл-та ТСП: }
SimvP :TIdent; { - идентификатор (симв. представление) }
NextS :TAdrTSP; { - указатель на след. эл-т ТСП }
end;
TElTN= record { Тип эл-та ТЧ: }
Numer :Word; { - значение : 0..65535 }
NextN :TAdrTN; { - указатель на след. эл-т ТЧ }
end;
TElTZ= record { Тип эл-та ТЗ: (ячейки памяти) }
TypeZ :TPerem; { - тип хранимого значения }
Value :Byte; { - значение - 1 байт (char,bool) }
NextZ :TAdrTZ; { - указатель на след. эл-т ТЗ }
end;
TElTL= record { Тип эл-та ТЛ: }
LenL :Byte; { - длина лексемы }
NextL :TAdrTL; { - указатель на след. эл-т ТЛ }
case TypeL:TypeLx of
{ варианты }
Idt: (PointPer :TAdrTP); { - для ид-ра }
Num: (PointNum :TAdrTN); { - для числа }
SSl,Log,Chr : (Index :Byte ); { - для служ. слов,констант}
Rzd: (); { - для разделителя "," }
end;
Количество таблиц определено количеством типов лексем. В нашем случае их шесть –
четыре заранее известных и две формируемых в процессе работы лексического анализатора.
Заранее известные таблицы: 1. Таблица служебных слов
2. Таблица разделителей
3. Таблица констант типа Boolean
4. Таблица констант типа Char
Формируемые таблицы: 1. Таблица идентификаторов
2. Таблица чисел
Пример работы лексического анализатора:
Подадим на вход лексического анализатора цепочку:
<char> ch, <arr> ac1, 5 </arr></char> <boolean> b7 </boolean>
<ass> b7, <not> ‘true’ </not> </ass>
<ass> <earr> ac1, 3 </earr>, ‘C’ </ass>
В результате работы лексического анализатора получим таблицы:
Таблица служебных слов:
1 char 9 ass
2 /char 10 /ass
3 boolean 11 and
4 /boolean 12 /and
5 arr 13 or
6 /arr 14 /or
7 earr 15 not
8 /earr 16 /not
Таблица разделителей:
17 ‘,’
Таблица символьных констант:
18 ‘a’
19 ‘b’
…
43 ‘z’
44 ‘0’
45 ‘1’
…
53 ‘9’
Таблица логических констант:
54 ‘true’
55 ‘false’
Таблица идентификаторов:
56 ch
57 ac1
58 b7
Таблица чисел:
59 5
60 3
Таблица лексем:
|
№ |
Тип лексемы |
Длина лексемы |
Языковая конструкция |
Указатель |
|
1 |
SSl |
4 |
Служ. слово: char |
1 |
|
2 |
Idt |
2 |
Идентификатор: ch |
56 |
|
3 |
Rzd |
1 |
Разделитель: , |
17 |
|
4 |
SSl |
3 |
Служ. слово: arr |
5 |
|
5 |
Idt |
3 |
Идентификатор: ac1 |
57 |
|
6 |
Rzd |
1 |
Разделитель: , |
17 |
|
7 |
Num |
1 |
Число: 5 |
59 |
|
8 |
SSl |
4 |
Служ. слово: /arr |
6 |
|
9 |
SSl |
5 |
Служ. слово: /char |
2 |
|
10 |
SSl |
7 |
Служ. слово: boolean |
3 |
|
11 |
Idt |
2 |
Идентификатор: b7 |
58 |
|
12 |
SSl |
8 |
Служ. слово: /boolean |
4 |
|
13 |
SSl |
3 |
Служ. слово: ass |
9 |
|
14 |
Idt |
2 |
Идентификатор: b7 |
58 |
|
15 |
Rzd |
1 |
Разделитель: , |
17 |
|
16 |
SSl |
3 |
Служ. слово: not |
15 |
|
17 |
Log |
4 |
Лог. константа: true |
54 |
|
18 |
SSl |
4 |
Служ. слово: /not |
16 |
|
19 |
SSl |
4 |
Служ. слово: /ass |
10 |
|
20 |
SSl |
3 |
Служ. слово: ass |
9 |
|
21 |
SSl |
4 |
Служ. слово: earr |
7 |
|
22 |
Idt |
3 |
Идентификатор: ac1 |
57 |
|
23 |
Rzd |
1 |
Разделитель: , |
17 |
|
24 |
Num |
1 |
Число: 3 |
60 |
|
25 |
SSl |
5 |
Служ. слово: /earr |
8 |
|
26 |
Rzd |
1 |
Разделитель: , |
17 |
|
27 |
Chr |
1 |
Симв. константа: z |
43 |
|
28 |
SSl |
4 |
Служ. слово: /ass |
10 |
Символы действия (семантика анализа):
Семантика анализа заключается в проверке конструкций языка на допустимые значения их длины, на правильность написания и т.д., но лексический анализатор не отражает правила построения выходных величин. Введем некоторые ограничения на наши конструкции языка и сразу определим для семантических действий ряд процедур – символов действия.
Для идентификатора
Идентификатор должен начинаться с буквы и не должен иметь длину более 16 символов.
{НИ}Начало идентификатора
– подготовка буфера для записи (очистка)
– установка длины = 1
{ФИ}Формирование идентификатора
– запись очередного входного символа в буфер
– увеличение длины на 1
– проверка счетчика длины на допустимое значение (≤ 16)
{КИ}Конец идентификатора
– поиск идентификатора в таблице идентификаторов (если его нет, то добавляем )
– добавляем лексему типа Idtс длиной идентификатора
– указатель лексемы ставим на соответствующую ячейку таблицы идентификаторов
Для числа
Число должно принадлежать диапазону от 0 до 65535 (word).
Следовательно, его длина не может быть больше, чем 5.
{НЧ} Начало числа
– подготовка буфера для записи (очистка)
– установка длины = 1
{ФЧ} Формирование числа
– запись очередного входного символа в буфер
– увеличение длины на 1
– проверка счетчика длины на допустимое значение (≤ 16)
{КЧ} Конец числа
– поиск числа в таблице чисел (если его нет, то добавляем )
– добавляем лексему типа Numс длиной числа
– указатель лексемы ставим на соответствующую ячейку таблицы чисел
Для служебного слова
Служебное слово должно быть точно описано в соответствии с языком.
{НС}Начало служебного слова
– подготовка буфера для записи (очистка)
– установка длины = 1
{ФС} Формирование служебного слова
– запись очередного входного символа в буфер
– увеличение длины на 1
{КС} Конец служебного слова
– поиск служебного слова в таблице служебных слов (если его нет, то ошибка )
– добавляем лексему типа SSlс длиной служебного слова
– указатель лексемы ставим на соответствующую ячейку таблицы служебных слов
Для константы (char, boolean)
Константы должны быть точно описаны в соответствии с языком.
{НК} Начало константы
– подготовка буфера для записи (очистка)
– установка длины = 1
{ФК} Формирование константы
– запись очередного входного символа в буфер
– увеличение длины на 1
{КК} Конец константы
– поиск константы в таблицах констант (char,boolean) (если ее нет, то ошибка)
– добавляем лексему типа LogилиChrс длиной константы
– указатель лексемы ставим на соответствующую ячейку соответствующей таблицы
Для разделителя
Разделители должны быть точно описаны в соответствии с языком.
{ФР} Формирование разделителя
– поиск разделителя в таблице разделителей (если его нет, то ошибка)
– добавляем лексему типа Rzdс длиной = 1
– указатель лексемы ставим на соответствующую ячейку таблицы разделителей
Дополнительные символы действия
{ФО}Формирование ошибки
– вывод информации об ошибке
{ЧС}Чтение символа
– чтение очередного входного символа из файла
Структура программы лексического анализатора
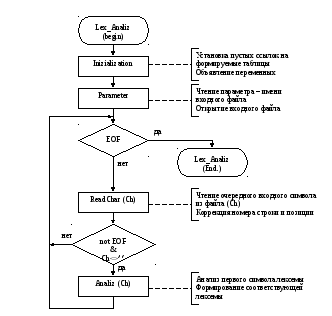
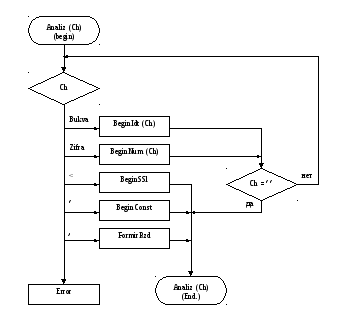
Спецификация процедур:
BeginIdt (Ch)
Процедура формирования идентификатора и лексемы типа Idt
Вход: первый символ идентификатора
Выход: символ, следующий во входном файле непосредственно за идентификатором
BeginNum (Ch)
Процедура формирования числа и лексемы типа Num
Вход: первый символ числа (цифра)
Выход: символ, следующий во входном файле непосредственно за числом
BeginSSl
Процедура распознавания служебного слова и формирование лексемы типа SSl
BeginConst
Процедура распознавания константы (симв. или лог.) и формирование лексемы типа ChrилиLog
FormirRzd
Процедура формирования лексемы типа Rzd(разделитель)
Семантика перевода
Синтаксически-управляемые схемы и транслирующие грамматики позволяют задавать соответствия между цепочками входного и выходного языков, называемые переводом. Такие соответствия отражают структурные или синтаксические свойства входных и выходных цепочек, но возникают значительные трудности при попытках их использования для описания контекстно-зависимых условий или смысла конструкций – семантики языков программирования.
Для задания семантики применяются различные приемы: W-грамматики, венский метаязык, аксиоматический и денотационный методы, а также атрибутные транслирующие грамматики (АТ – грамматики).
Рассматриваемые в настоящем разделе АТ – грамматики отличаются от транслирующих грамматик тем, что символам грамматики приписываются атрибуты, отражающие семантическую информацию, а правилам грамматики сопоставляются правила вычисления значений атрибутов.