

Функции сравнения строк
strcmp() strncmp() |
strcasecmp() strncasecmp() |
strnatcmp() strnatcasecmp() |
similar_text() levenshtein() |
strcmp()
Синтаксис:
int strcmp(string str1, string str2)
Эта функция сравнения строк. Она сравнивает две строки и возвращает:
0 - если строки полностью совпадают;
1 - если, строка str1 лексикографически больше str2;
1 – если, наоборот, строка str1 лексикографически меньше str2
Функция является чувствительной к регистру, т.е. регистр символов влияет на результаты сравнений (поскольку сравнение происходит побайтово).
Пример:
<?
$str1 = "ttt";
$str2 = "tttttttttt";
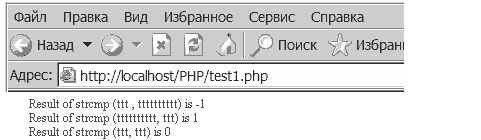
echo("Result of strcmp ($str1 , $str2) is ");
echo(strcmp (str1, str2)); echo("<br>");
echo("Result of strcmp ($str2, $str1)> is ");
echo(strcmp (str2, str1)); echo("<br>");
echo("Result of strcmp ($str1 , $str1) is ");
echo(strcmp (str1,str1));
?>
Результат:
strncmp()
Синтаксис:
int strncmp(string str1, string str2, int len)
Эта функция отличается от strcmp() тем, что сравнивает начала строк, а точнее первые len байтов. Если len меньше длины наименьшей из строк, то строки сравниваются целиком.
В остальном функция ведет себя аналогично strcmp(), т.е. возвращает:
0 - если строки полностью совпадают;
1 - если, строка str1 лексикографически больше str2;
1 – если, наоборот, строка str1 лексикографически меньше str2
Сравнение также проводится побайтово, поэтому функция чувствительна к регистру.
strcasecmp()
Синтаксис:
int strcasecmp(string str1, string str2)
Функция работает аналогично strcmp(), только при работе не учитывается регистр букв.
strncasecmp()
Синтаксис:
int strncasecmp(string str1, string str2, int len)
Функция strncasecmp() cравнивает начала строк без учета регистра.
strnatcmp()
Синтаксис:
int strnatcmp(string str1, string str2)
Производит так называемое "естественное" сравнение строк.
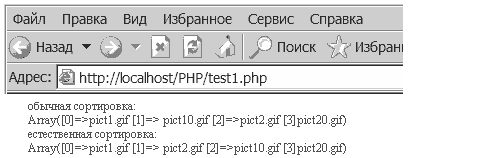
Об этой функции поговорим поподробнее. Данная функция является имитатором сравнение строк человеком, т.е. она сравнивает строки так, как их сравнивал бы человек. Т.е., если, к примеру, мы будем сравнивать файлы с названиями pict1.gif, pict20.gif, pict2.gif, pict10.gif, то обычное сравнение приведет к следующему их расположению: pict1.gif, pict10.gif, pict2.gif, pict20.gif. Естественная же сортировка даст результат, который нам более привычен: pict1.gif, pict2.gif, pict10.gif, pict20.gif.
В примере использования этой функции мы опять забежим вперед и прибегнем к функциям работы с массивами. Поэтому мы советуем Вам после прочтения главы о массивах еще раз взглянуть на этот пример, и использовать его, когда Вам надо отсортировать все то, что связано со строками, к примеру, названия файлов.
<?
$array1 = $array2 = array("pict10.gif", "pict2.gif", "pict20.gif", "pict1.gif");
echo("обычная сортировка:"); echo ("<br>");
usort ($array1, strcmp);
print_r ($array1);
echo ("<br>"); echo("естественная сортировка:"); echo("<br>");
usort ($array2, strnatcmp);
print_r ($array2);
?>
Этот скрипт выведет следующее:
strnatcasecmp()
Синтаксис:
int strnatcasecmp(string str1, string str2)
Производит "естественное" сравнение строк без учета регистра. Функция выполняет то же самое, что и strnatcmp(), только без учета регистра.
similar_text()
Синтаксис:
int similar_text(string str_first, string str_second [, double percent])
Эта функция производит определение схожести двух строк.
Функция similar_text() определяет схожесть двух строк по алгоритму Оливера. Функция возвращает число символов, совпавших в строках str_first и str_second. Третий необязательный параметр передается по ссылке и в нем сохраняется процент совпадения строк.
Вместо стека, как в алгоритме Оливера, эта функция использует рекурсивные вызовы. Сложность алгоритма этой функции равна O((max(n,m))3), что делает эту функцию медленной. (Грубо говоря, скорость выполнения этой функции пропорциональна N3, где N – длина наибольшей строки.
Пример:
<?
$str1 = "Hello, world!";
$str2 = "Hello!";
$var = similar_text($str1,$str2);
$var1 = similar_text($str1, $str2, &$tmp);
// параметр $tmp передаем по ссылке
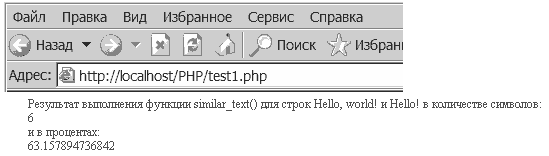
echo("Результат выполнения функции similar_text()
для строк $str и $str1 в количестве символов:");
echo("<br>"); echo("$var"); echo("<br>");
echo("и в процентах:"); echo("<br>");
echo($tmp); // для вывода информации в процентах обращаемся к $tmp
?>
Результат:
levenshtein()
Функция выполняет определение различия Левенштейна двух строк.
Синтаксис:
int levenshtein(string str1, string str2)
int levenshtein(string str1, string str2, int cost_ins, int cost_rep, int cost_del)
int levenshtein(string str1, string str2, function cost)
Под понятием "различие Левенштейна" понимается минимальное число символов, которое требовалось бы заменить, вставить или удалить для того, чтобы превратить строку str1 в str2.
Сложность алгоритма этой функции равна O(m*n), т.е. пропорциональна произведению длин строк str1 и str2, поэтому эта функция намного более быстрая, чем функция similar_text().
Как видим, у функции три вида синтаксиса. В первом случае функция возвращает число необходимых операций над символами строк для преобразования str1 в str2:
<?
$str1 = "Hello, world!";
$str2 = "Hello!";
$var = levenshtein($str1,$str2);
echo($var); // вернет 7
?>
Во втором случае добавляется три дополнительных параметра: стоимость операции вставки cost_ins, замены cost_rep и удаления cost_del. Естественно, функция в этом случае становится менее быстродействующей. Возвращается интегральный показатель сложности трансформации (ИПСТ).
<?
$str1 = "Hello, world!";
$str2 = "Hello!";
$var = levenshtein($str1,$str2,3,3,3);
echo($var); // вернет 21
?>
Число 21, между прочим, это 7*3 :). Т.е. ИПСТ равен произведению количества символов, необходимых для замены (а как мы посчитали в предыдущем примере их надобно 7) на стоимость, в этом случае, одной из операций. В этом примере, поскольку стоимость одинакова, не имеет значения, какую операцию брать. В случае, если стоимости различны, при вычисления ИПСТ берется наибольший. Т.е., если мы напишем в этом примере
$var = levenshtein($str1, str2 ,2,3,6);
то функция вернет нам значение 42.
Третий вариант позволяет указать функцию, используемую для расчета сложности трансформации.