

Закон противоречия:
![]()
Все операции алгебры логики определяются таблицами истинности значений. Таблица истинности определяет результат выполнения операции для всех возможных логических значений исходных высказываний. Количество вариантов, отражающих результат применения операций, будет зависеть от количества высказываний в логическом выражении, например:
таблица истинности одноместной логической операции состоит из двух строк: два различных значения аргумента — «истина» (1) и «ложь» (0) и два соответствующих им значения функции;
в таблице истинности двуместной логической операции — четыре строки: 4 различных сочетания значений аргументов — 00, 01, 10 и 11 и 4 соответствующих им значения функции;
Если число высказываний в логическом выражении n, то таблица истинности будет содержать 2n строк, так как существует 2n различных комбинаций возможных значений аргуме Приоритет логических операций
1) Инверсия 2) конъюнкция 3) дизъюнкция 4) импликация и эквивалентность
нтов.
Алгоритм построения таблицы истинности:
подсчитать количество переменных n в логическом выражении;
определить число строк в таблице m = 2n;
подсчитать количество логических операций в формуле;
установить последовательность выполнения логических операций с учетом скобок и приоритетов;
определить количество столбцов в таблице: число переменных плюс число операций;
выписать наборы входных переменных ;
провести заполнение таблицы истинности по столбикам, выполняя логические операции в соответствии с установленной в п.4 последовательностью
20. Равносильные формулы, равносильное преобразование формул, законы преобразования формул, дизъюнктивная и конъюнктивная нормальные формы, составление ДНФ и КНФ по таблице истинности.
Определение. Две формулы алгебры логики А и В называются равносильными, если они принимают одинаковые логические значения на любом наборе значений входящих в формулы элементарных высказываний.
Равносильность формул будем обозначать знаком =- , а запись А =- В означает, что формулы А и В равносильны.
Равносильные преобразования используются для доказательства равносильностей, для приведения формул к заданному виду, для упрощения формул.
Формула А считается проще равносильной ей формулы В, если она содержит меньше букв, меньше логических операций. При этом обычно операции эквивалентность и импликация заменяются операциями дизъюнкции и конъюнкции, а отрицание относят к элементарным высказываниям.
Определение: Элементарная конъюнкция, есть конъюнкция, составленная из попарно различных переменных или отрицаний переменных. (x,y,¬x&y&¬z)
Дизъюнктивная нормальная форма (ДНФ) – есть дизъюнкция, составленная из попарно различных элементарных конъюнкций. (xy?¬xy¬z?¬x¬y¬z)
Элементарная дизъюнкция есть дизъюнкция, составленная из попарно различных переменных или отрицаний переменных.
Конъюнктивная нормальная форма (КНФ) – есть конъюнкция попарно различных элементарных дизъюнкций.
Пусть формула А содержит только операции конъюнкции, дизъюнкции и отрицания. Операция конъюнкции называется двойственной для операции дизъюнкции, а операция дизъюнкции называется двойственной для операции конъюнкции.
21. Понятие алгоритма. Свойства алгоритма: массовость, дискретность, детерминированность, результативность, формальность, конечность. Способы описания алгоритма: словесный, псевдокод, графический, язык программирования (примеры). Основные графические символы блок-схемы.
Алгоpитм - заранее заданное понятное и точное пpедписание возможному исполнителю совеpшить определенную последовательность действий для получения решения задачи за конечное число шагов. Алгори́тм — набор инструкций, описывающих порядок действий исполнителя для достижения результата решения задачи за конечнон время.
• Массовость – алгоритм решения задачи разрабатывается в общем виде, то есть, он должен быть применим для некоторого класса задач, различающихся только исходными данными. При этом исходные данные могут выбираться из некоторой области, которая называется областью применимости алгоритма.
• Дискретность (прерывность, раздельность) – алгоритм должен представлять процесс решения задачи как последовательное выполнение простых (или ранее определенных) шагов. Каждое действие, предусмотренное алгоритмом, исполняется только после того, как закончилось исполнение предыдущего.
Детерминированность (от лат. determinate – определенность, точность) указывает, что любое действие алгоритма должно быть строго и недвусмысленно определено в каждом случае. Многократное применение одного алгоритма к одному и тому же набору исходных данных должно всегда давать один и тот же результат.
Результативность требует, чтобы в алгоритме не было ошибок, т.е. при точном исполнении всех команд процесс решения задачи должен прекратиться за конечное число шагов и при этом должен быть получен определенный постановкой задачи результат (ответ).
Формальность. Алгоритм не должен допускать неоднозначности толкования действий для исполнителя.
Конечность определяет, что каждое действие в отдельности и алгоритм в целом должны иметь возможность завершения.
Способы описания алгоритмов. Правила выполнения блок схем.
Для строгого задания различных структур данных и алгоритмов их обработки требуется иметь такую систему формальных обозначений и правил, чтобы смысл всякого используемого предписания трактовался точно и однозначно. Соответствующие системы правил называют языками описаний.
К средствам описания алгоритмов относятся следующие основные способы их представления: словесный; графический; псевдокоды; программный. На практике используются также и табличный способ.
Словесный способ записи алгоритмов представляет собой последовательное описание основных этапов обработки данных и задается в произвольномьизложении на естественном языке.
Псевдокод представляет собой систему обозначений и правил, предназначенную для единообразной записи алгоритмов.
Псевдокод занимает промежуточное место между естественным и формальным языками. С одной стороны, он близок к обычному естественному языку, поэтому алгоритмы могут на нем записываться и читаться как обычный текст. С другой стороны, в псевдокоде используются некоторые формальные конструкции и математическая символика, что приближает запись алгоритма к общепринятой математической записи.
В псевдокоде не приняты строгие синтаксические правила для записи команд, присущие формальным языкам, что облегчает запись алгоритма на стадии его проектирования и дает возможность использовать более широкий набор команд, рассчитанный на абстрактного исполнителя.
Графический способ представления алгоритмов является более компактным и наглядным по сравнению со словесным. При графическом представлении алгоритм изображается в виде последовательности связанных между собой функциональных блоков, каждый из которых соответствует выполнению одного или нескольких действий.
Такое графическое представление называется схемой алгоритма или блок-схемой. В блок-схеме каждому типу действий (вводу исходных данных, вычислению значений выражений, проверке условий, управлению повторением действий, окончанию обработки и т. п.) соответствует геометрическая фигура, представленная в виде блочного символа. Блочные символы соединяются линиями переходов, определяющими очередность выполнения действий. Для начертания этих схем используется набор символов, определяемых ГОСТ 19.701-90 (ИСО 5807.
Символы блок-схемы
Процесс Вычислительное действие или последовательность действий
![]()
Решение Проверка условий

Модификация Начало цикла
Предопределенный процесс Вычисления по подпрограмме, стандартной подпрограмме

Ввод-вывод Ввод-вывод в общем виде

Пуск-остановка
![]() Начало,
конец алгоритма, вход и выход в подпрограмму
Начало,
конец алгоритма, вход и выход в подпрограмму
Документ Вывод результатов
22. Основные алгоритмические конструкции: линейная, разветвляющаяся (полная, неполная), циклическая (с параметром, с предусловием, с постусловием). Тело цикла. Примеры конструкций в виде блок-схем.
Структура следование. Образуется последовательностью действий, следующих одно за другим:
. Структура ветвление. В зависимости от результата проверки условия («да» или «нет») осуществляет выбор одного из альтернативных путей работы алгоритма. Каждый из путей ведёт к общему выходу, поэтому работа алгоритма будет продолжаться независимо от того, какой путь будет выбран. Структура «ветвление» бывает четырёх видов: «если-то»; «если-то-иначе»; «выбор»; «выбор-иначе».
Структура цикл. Обеспечивает многократное выполнение некоторой совокупности действий, которая называется телом цикла. Циклы бывают трёх видов: с предусловием «пока-делай», с постусловием «делай-пока», со счётчиком «для».
Цикл с предусловием («пока-делай» ). Предписывает выполнять тело цикла до тех пор, пока выполняется условие, записанное после слова пока.
Цикл с постусловием («делай-пока»). Предписывает выполнять тело цикла до тех пор, пока не выполняется условие (на Паскале until), записанное после слова пока. В отличие от цикла,«пока-делай» тело цикла выполняется хотя бы один раз.
Цикл со счетчиком («для»). Предписывает выполнять тело цикла для всех значений переменной (параметр цикла) в заданном диапазоне.
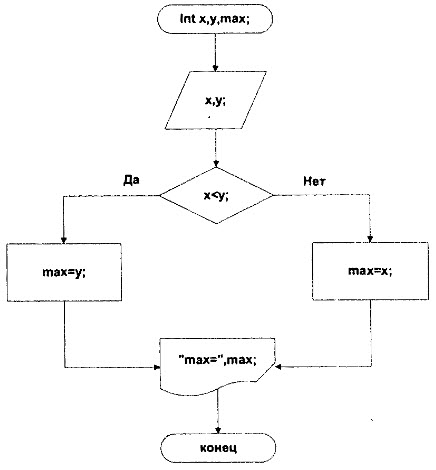
Для примера приведем блок-схемы алгоритма нахождения максимального из двух значений:
23. Языки программирования (ЯП): компьютерная программа, машинный код, ассемблер, мнемоники, алфавит, синтаксис, семантика, уровень ЯП, ЯП высокого уровня, компилятор и интерпретатор. Фазы компиляции: лексический анализ, синтаксический анализ, семантический анализ, оптимизация, генерация кода. Интерпретатор компилирующего типа, байт-код.
Язы́к программи́рования — формальная знаковая система, предназначенная для записи компьютерных программ. Язык программирования определяет набор лексических, синтаксических и семантических правил, задающих внешний вид программы и действия, которые выполнит исполнитель (компьютер) под её управлением.
Каждый процессор имеет свою систему команд. Компьютер способен выполнять только последовательности команд, понятных процессору, — машинный код. Первоначально программы для компьютеров и писались с использованием машинного кода. Программирование в машинном коде — трудоемкий процесс, в ходе которого трудно избежать ошибок. Упростить этот процесс можно, если автоматизировать работу, поручив часть ее самому компьютеру.Сегодня для записи программ используют языки программирования. Язык программирования — это формальный язык для записи алгоритмов в виде, допускающем их автоматическую подготовку к выполнению на компьютере. Для преобразования программы в машинный код служит специальное программное средство — транслятор.Система обозначений для представления в удобочитаемом виде программ, записанных в машинном коде, — это уже язык программирования (язык ассемблера, или автокод). Языки для машинно-ориентированной записи программ называют языками низкого уровня.Инструкция языка ассемблера описывает ровно одну машинную команду. И наоборот: каждой команде в системе команд процессора соответствует инструкция языка (мнемоника). По сравнению с машинным кодом язык ассемблера имеет ряд преимуществ, облегчающих труд программиста.
Символические мнемоники запоминаются легче, чем шестнадцатеричные коды команд.
Для регистров и областей памяти также можно использовать символические имена.
Нет необходимости работать с физическими адресами памяти.
Числовые константы и строки представляются в программе в привычном виде.
Ассемблер, программа, преобразующая текст на языке ассемблера в машинные команды, — это простейший транслятор.
Языки низкого уровня сегодня применяют в тех случаях, когда имеются особые требования к скорости работы и компактности программы. Они также удобны, если нужен прямой доступ к аппаратным ресурсам.
Мнемоника- каждой команде в системе команд процессора соответствует инструкция языка (мнемоника).Алфавит языка — это набор символов, которые можно применять в инструкциях языка программирования. Другие символы допустимы только в особых случаях, например в строковых константах.
Синтаксис языка определяет правила построения операторов. Любой корректный оператор соответствует этим правилам. Правила синтаксиса — формальные. Проверка правильности исходного текста и поиск синтаксических ошибок могут быть выполнены автоматическиСемантика — это смысловое содержание операторов языка программирования. Семантические правила определяют действия, описываемые различными операторами, и, в итоге, сущность всего алгоритма.Существует два уровня языков программирования: языки низкого уровня и языки высокого уровня. Языки программирования высокого уровня заметно проще в изучении и применении. Программы, написанные с их помощью, можно использовать на любой компьютерной платформе, правда при условии, что для нее существует транслятор данного языка. Эти языки вообще никак не учитывают свойства конкретного процессора и не предоставляют прямых средств для обращения к нему. В некоторых случаях это ограничивает возможности программистов, но зато и оставляет меньше возможностей для совершения ошибок. Языки высокого уровня в большей степени ориентированы на человека; команды этих языков – понятные человеку английские слова. Чем выше уровень языка, тем больше приходится проделать операций для выполнения необходимой команды. С появлением языков высокого уровня программисты получили возможность больше времени уделять решению конкретной проблемы, не отвлекаясь особенно на весьма тонкие вопросы организации самого процесса выполнения задания на машине. Кроме того, появление этих языков ознаменовало первый шаг на пути создания программ, которые вышли за пределы научно-исследовательских лабораторий и финансовых отделов.
Компиляторы обрабатывают программу в несколько приемов. Сначала они несколько раз просматривают исходный текст (обычно он называется исходным кодом), находят общие места, Выполняют проверку на отсутствие ошибок синтаксиса и внутренних противоречий, и лишь потом переводят текст в машинный код. В результате программа получается компактной и эффективной.
Интерпретаторы работают как синхронные переводчики. Они берут один оператор из программы, транслируют его в машинный код (или в какой-то промежуточный код, близкий к машинному коду) и исполняют его. Если какой-то оператор многократно используется в программе, интерпретатор всякий раз будет добросовестно выполнять его перевод так, как будто встретил его впервые.
Фазы компиляции Лексический анализ (сканирование)
Синтаксический анализ (разбор, „парсинг“)
Семантический анализ
Обнаружение ошибок. Лексические, синтаксические и семантические ошибки.
Генерация промежуточного кода
Оптимизация кода
Генерация кода (основное - назначение переменных регистрам)
Входом компилятора служит программа на исходном языке программирования. С точки зрения компилятора это просто последовательность символов. Задача первой фазы компиляции, лексического анализатора (lexical analysis) , заключается в разборе входной цепочки и выделении некоторых более "крупных" единиц, лексем, которые удобнее для последующего разбора. Примерами лексем являются основные ключевые слова, идентификаторы, константные значения (числа, строки, логические) и т.п.На этапе лексического анализа обычно также выполняются такие действия, как удаление комментариев и обработка директив условной компиляции.
Синтаксический анализ является одной из наиболее формализованных и хорошо изученных фаз компиляции. После синтаксического анализа можно считать, что исходная программа преобразована в некоторое промежуточное представление. Некоторые распространенные формы промежуточного представления программы будут рассмотрены в лекции 9. Пока же мы остановимся на одной форме промежуточного представления, которая будет использована в нашем курсе, - на дереве разбора программы (иногда его также называют синтаксическим деревом). В дереве разбора программы внутренние узлы соответствуют операциям, а листья представляют операнды.
Видозависимый анализ (type checking) , иногда также называемый семантическим анализом (semantic analysis) , обычно заключается в проверке правильности типов данных, используемых в программе. Кроме того, на этом этапе компилятор должен также проверить, соблюдаются ли определенные контекстные условия входного языка. В современных языках программирования одним из примеров контекстных условий может служить обязательность описания переменных: для каждого использующего вхождения идентификатора должно существовать единственное определяющее вхождение. Другой пример контекстного условия: число и атрибуты фактических параметров вызова процедуры должны быть согласованы с определением этой процедуры.
Основная цель фазы оптимизации (code optimization) заключается в преобразовании промежуточного представления программы в целях повышения эффективности результирующей объектной программы. Отметим, что существуют различные критерии эффективности, например, скорость исполнения или объем памяти, требуемый программе. Очевидно, что все преобразования, осуществляемые на фазе оптимизации, должны приводить к программе, эквивалентной исходной.
Наконец, по оптимизированной версии промежуточного представления генерируется объектная программа. Эту задачу решает фаза генерации кода (code generator) Интерпрета́тор — программа (разновидность транслятора) или аппаратное средство, выполняющее интерпретацию.[1]
Интерпрета́ция — пооператорный (покомандный, построчный) анализ, обработка и тут же выполнение исходной программы или запроса (в отличие от компиляции, при которой программа транслируется без её выполнения)
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, Tcl, Perl (используется байт-код[источник не указан 1089 дней]), REXX (сохраняется результат парсинга исходного кода[5]), а также в различных СУБД (используется p-код[источник не указан 1089 дней]).
Байт-код или байтко́д (англ. byte-code), иногда также используется термин псевдоко́д — машинно-независимый код низкого уровня, генерируемый транслятором и исполняемый интерпретатором. Большинство инструкций байт-кода эквивалентны одной или нескольким командам ассемблера. Трансляция в байт-код занимает промежуточное положение между компиляцией в машинный код и интерпретацией.
Байт-код называется так, потому что длина каждого кода операции — один байт, но длина кода команды различна. Каждая инструкция представляет собой однобайтовый код операции от 0 до 255, за которым следуют такие параметры, как регистры или адреса памяти. Это в типичном случае, но спецификация байт-кода значительно различается в разных языках.
24. Классификация языков программирования: процедурные, объектно-ориентированные, декларативные (функциональные и логические), языки программирования баз данных. Нисходящее и модульное проектирование. Принципы ООП. Интегрированная среда разработки. Примеры языков.
Существуют различные классификации языков программирования.По наиболее распространенной классификации все языки программирования, в соответствии с тем, в каких терминах необходимо описать задачу, делят на языки низкого и высокого уровня.Если язык близок к естественному языку программирования, то он называется языком высокого уровня, если ближе к машинным командам, – языком низкого уровня.Языки программирования также можно классифицировать на процедурные и непроцедурные.В процедурных языках программа явно описывает действия, которые необходимо выполнить, а результат задается только способом получения его при помощи некоторой процедуры, которая представляет собой определенную последовательность действий.
Среди процедурных языков выделяют в свою очередь структурные и операционные языки. В структурных языках одним оператором записываются целые алгоритмические структуры: ветвления, циклы и т.д. В операционных языках для этого используются несколько операций. Широко распространены следующие структурные языки: Паскаль, Си, Ада, ПЛ/1. Среди операционных известны Фортран, Бейсик, Фокал.
Можно выделить еще один класс языков программирования – объектно–ориентированные языки высокого уровня. На таких языках не описывают подробной последовательности действий для решения задачи, хотя они содержат элементы процедурного программирования. Объектно–ориентированные языки, благодаря богатому пользовательскому интерфейсу, предлагают человеку решить задачу в удобной для него форме. Первый объектно-ориентированный язык программирования Simula был создан в 1960-х годах Нигаардом и Далом.
Декларативные языки программирования
К ним относятся функциональные и логические языки программирования. В этих языках не производится алгоритмического действия явно, то есть алгоритм не задается прграммистом, а строится самой программой. В декларативных языках задается, производится построение какой-либо структуры или системы, то есть декларируются (объявляются) какие-то свойства создаваемого объекта. Эти языки получили широкое применение в системах автоматизированного проектирования (САПР), в так называемых CAD-пакетах, в моделировнии, системах исккусственного интеллекта
Для работы с базами данных используются специальные языки баз данных. Чаще всего выделяется два языка:
– язык определения данных (ЯОД) – служит для определения логической структуры БД;
– язык манипулирования данными (ЯМД) – содержит набор операторов манипулирования данными (добавление данных в БД, удаление, модификация, выборка и т.д.).
Во многих СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных.
Стандартным языком реляционных СУБД является язык SQL (Structured Query Language, query – вопрос) – структурированный язык запросов, оперирует не отдельными записями, а группами записей. Реляционные СУБД (relation – отношение): 1970 г., показана возможность управления данными благодаря их описанию в терминах математической теории отношений – гибкая и простая реляционная модель данных стала доминирующей среди разработчиков и пользователей СУБД. Объектно-реляционные БД – объектно-ориентированные возможности (определение новых типов данных и функций их обработки) встраиваются в реляционное основание. Язык SQL сочетает средства ЯОД и ЯМД, то есть позволяет определять схему реляционной БД и манипулировать данными.
Нисходящее проектирование
Метод нисходящего проектирования предполагает последовательное разложение общей функции обработки данных на простые функциональные элементы ("сверху-вниз").
В результате строится иерархическая схема, отражающая состав и взаимоподчиненность отдельных функций, которая носит название функциональная структура алгоритма (ФСА) приложения.
Последовательность действий по разработке функциональной структуры алгоритма приложения:
определяются цели автоматизации предметной области и их иерархия (цель-подцель);
устанавливается состав приложений (задач обработки), обеспечивающих реализацию поставленных целей;
уточняется характер взаимосвязи приложений и их основные характеристики (информация для решения задач, время и периодичность решения, условия выполнения и др.);
определяются необходимые для решения задач функции обработки данных;
выполняется декомпозиция функций обработки до необходимой структурной сложности, реализуемой предполагаемым инструментарием.
Подобная структура приложения (рис. 18.2) отражает наиболее важное - состав и взаимосвязь функций обработки информации для реализации приложений, хотя и не раскрывает логику выполнения каждой отдельной функции, условия или периодичность их вызовов.
Разложение должно носить строго функциональный характер, т.е. отдельный элемент ФСА описывает законченную содержательную функцию обработки информации, которая предполагает определенный способ реализации на программном уровне.
Функции ввода-вывода информации рекомендуется отделять от функций вычислительной или логической обработки данных.
По частоте использования функции делятся на:
однократно выполняемые;
повторяющиеся.
Степень детализации функций может быть различной, но иерархическая схема должна давать представление о составе и структуре взаимосвязанных функций и общем алгоритме обработки данных. Широко используемые функции приобретают ранг стандартных (встроенных) функций при проектировании внутренней структуры программного продукта.
МОДУЛЬНОЕ ПРОГРАММИРОВАНИЕ
Свойства модуля
Модульное программирование основано на понятии модуля - логически взаимосвязанной совокупности функциональных элементов, оформленных в виде отдельных программных модулей.
Модуль характеризуют: один вход и один выход - на входе программный модуль получает определенный набор исходных данных, выполняет содержательную обработку и возвращает один набор результатных данных, т.е. реализуется стандартный принцип IPO (Input - Process - Output) - вход-процесс-выход;
функциональная завершенность - модуль выполняет перечень регламентированных операций для реализации каждой отдельной функции в полном составе, достаточных для завершения начатой обработки;
логическая независимость - результат работы программного модуля зависит только от исходных данных, но не зависит от работы других модулей;
слабые информационные связи с другими программными модулями - обмен информацией между модулями должен быть по возможности минимизирован;
обозримый по размеру и сложности программный элемент.
Таким образом, модули содержат определение доступных для обработки данных, операции обработки данных, схемы взаимосвязи с другими модулями.
Каждый модуль состоит из спецификации и тела.Спецификации определяют правила использования модуля, а тело - способ реализации процесса обработки.
Модульная структура программных продуктов
Принципы модульного программирования программных продуктов во многом сходны с принципами нисходящего проектирования. Сначала определяются состав и подчиненность функций, а затем - набор программных модулей, реализующих эти функции.
Однотипные функции реализуются одними и теми же модулями. Функция верхнего уровня обеспечивается главным модулем; он управляет выполнением нижестоящих функций, которым соответствуют подчиненные модули.
При определении набора модулей, реализующих функции конкретного алгоритма, необходимо учитывать следующее:
каждый модуль вызывается на выполнение вышестоящим модулем и, закончив работу, возвращает управление вызвавшему его модулю;
принятие основных решений в алгоритме выносится на максимально "высокий" по иерархии уровень; для использования одной и той же функции в разных местах алгоритма создается один модуль, который вызывается на выполнение по мере необходимости. В результате дальнейшей детализации алгоритма создается функционально-модульная схема (ФМС) алгоритма приложения, которая является основой для программирования
Некоторые функции могут выполняться с помощью одного и того же программного модуля (например, функции Ф1 и Ф2).
Функция Ф3 реализуется в виде последовательности выполнения программных модулей.
Функция Фm реализуется с помощью иерархии связанных модулей.
Модуль n управляет выбором на выполнение подчиненных модулей.
Функция Фx реализуется одним программным модулем.
Состав и вид программных модулей, их назначение и характер использования в программе в значительной степени определяются инструментальными средствами. Например, применительно к средствам СУБД отдельными модулями могут быть:
экранные формы ввода и/или редактирования информации базы данных;
отчеты генератора отчетов;
макросы;
стандартные процедуры обработки информации;
меню, обеспечивающее выбор функции обработки и др.
Алгоритмы большой сложности обычно представляются с помощью схем двух видов:
обобщенной схемы алгоритма - раскрывает общий принцип функционирования алгоритма и основные логические связи между отдельными модулями на уровне обработки информации (ввод и редактирование данных, вычисления, печать результатов и т.п.);
детальной схемы алгоритма представляет содержание каждого элемента обобщенной схемы с использованием управляющих структур в блок-схемах алгоритма, псевдокода либо алгоритмических языков высокого уровня.
Объе́ктно-ориенти́рованное, или объектное, программи́рование (в дальнейшем ООП) — парадигма программирования, в которой основными концепциями являются понятия объектов и классов. В случае языков с прототипированием вместо классов используются объекты-прототипы.
Объектно-ориентированное программирование базируется на трех важнейших принципах, придающих объектам новые свойства. Этими принципами являются инкапсуляция, наследование и полиморфизм.
1. Инкапсуляция - это объединение в единое целое данных и алгоритмов обработки этих данных. В рамках ООП данные называются полями объекта (свойствами), а алгоритмы - объектными методами или просто методами.
Инкапсуляция позволяет в максимальной степени изолировать объект от внешнего окружения. Она существенно повышает надежность разрабатываемых программ, т.к. локализованные в объекте алгоритмы обмениваются с программой сравнительно небольшими объемами данных, причем количество и тип этих данных обычно тщательно контролируются. В результате замена или модификация алгоритмов и данных, инкапсулированных в объект, как правило, не влечет за собой плохо прослеживаемых последствий для программы в целом (в целях повышения защищенности программ в ООП почти не используются глобальные переменные).
Другим немаловажным следствием инкапсуляции является легкость обмена объектами, переноса их из одной программы в другую.
2. Наследование - есть свойство объектов порождать своих потомков. Объект-потомок автоматически наследует от родителя все поля и методы, может дополнять объекты новыми полями и заменять (перекрывать) методы родителя или дополнять их.
Принцип наследования решает проблему модификации свойств объекта и придает ООП в целом исключительную гибкость. При работе с объектами программист обычно подбирает объект, наиболее близкий по своим свойствам для решения конкретной задачи, и создает одного или нескольких потомков от него, которые "умеют" делать то, что не реализовано в родителе.
Полиморфизм - это свойство родственных объектов (т.е. объектов, имеющих одного общего родителя) решать схожие по смыслу проблемы разными способами. В рамках ООП поведенческие свойства объекта определяются набором входящих в него методов. Изменяя алгоритм того или иного метода в потомках объекта, программист может придавать этим потомкам отсутствующие у родителя специфические свойства. Для изменения метода необходимо перекрыть его в потомке, то есть объявить в потомке одноименный метод и реализовать в нем нужные действия. В результате в объекте-родителе и объекте-потомке будут действовать два одноименных метода, имеющие разную алгоритмическую основу и, следовательно, придающие объектам разные свойства. Это и называется полиморфизмом объектов.
Многие современные языки специально созданы для облегчения объектно-ориентированного программирования. Однако следует отметить, что можно применять техники ООП и для не-объектно-ориентированного языка и наоборот, применение объектно-ориентированного языка вовсе не означает, что код автоматически становится объектно-ориентированным.
Современный объектно-ориентированный язык предлагает, как правило, следующий обязательный набор синтаксических средств:
Объявление классов с полями (данными — членами класса) и методами (функциями — членами класса).
Механизм расширения класса (наследования) — порождение нового класса от существующего с автоматическим включением всех особенностей реализации класса-предка в состав класса-потомка. Большинство ООП-языков поддерживают только единичное наследование.
Полиморфные переменные и параметры функций (методов), позволяющие присваивать одной и той же переменной экземпляры различных классов.
Полиморфное поведение экземпляров классов за счёт использования виртуальных методов. В некоторых ООП-языках все методы классов являются виртуальными.
Видимо, минимальным традиционным объектно-ориентированным языком можно считать язык Оберон, который не содержит никаких других объектных средств, кроме вышеперечисленных (в исходном Обероне даже нет отдельного ключевого слова для объявления класса, а также отсутствуют явно описываемые методы, их заменяют поля процедурного типа). Но большинство языков добавляют к указанному минимальному набору те или иные дополнительные средства. В их числе:
Конструкторы, деструкторы, финализаторы.
Свойства (аксессоры).
Индексаторы.
Интерфейсы (например, в Java используются также как альтернатива множественному наследованию — любой класс может реализовать сколько угодно интерфейсов).
Переопределение операторов для классов.
Средства защиты внутренней структуры классов от несанкционированного использования извне. Обычно это модификаторы доступа к полям и методам, типа public, private, обычно также protected, иногда некоторые другие.
Часть языков (иногда называемых «чисто объектными») целиком построена вокруг объектных средств — в них любые данные (возможно, за небольшим числом исключений в виде встроенных скалярных типов данных) являются объектами, любой код — методом какого-либо класса, и невозможно написать программу, в которой не использовались бы объекты. Примеры подобных языков — Smalltalk, Python, Java, C#, Ruby, AS3. Другие языки (иногда используется термин «гибридные») включают ООП-подсистему в исходно процедурный язык. В них существует возможность программировать, не обращаясь к объектным средствам. Классические примеры — C++, Delphi и Perl.
25. История развития ЭВМ: механический калькулятор Паскаля, арифмометр Лейбница, аналитическая машина Бэбиджа, табулятор Холлерита, 5 поколений ЭВМ, проблемы и достижения, МЭСМ, БЭСМ-6, PDP-8, мини ЭВМ, первые персональные компьютеры. Многопроцессорные супер ЭВМ.
1642: Блез Паскаль (Pascal, 1623-1662) – французский религиозный философ, писатель, математик и физик – разработал более компактное суммирующее устройство, которое стало первым в мире механическим калькулятором, выпускавшимся серийно (главным образом для нужд парижских ростовщиков и менял).
Важнейшим элементом в машинах Паскаля был автоматический перенос единицы в следующий, высший разряд при полном обороте колеса предыдущего разряда (так же, как при обычном сложении десятичных чисел в старший разряд числа переносят десятки, образовавшиеся в результате сложения единиц, сотни — от сложения десятков и т.д.). Именно это давало возможность складывать многозначные числа без вмешательства человека в работу механизма. Этот принцип использовался в течение почти трёхсот лет (середина 17 — начало 20 вв.) при построении арифмометров (приводимых в действие от руки) и электрических клавишных вычислительных машин (с приводом от электродвигателя).
Механический калькулятор был создан Лейбницем в 1673 году. Сложение чисел выполнялось при помощи связанных друг с другом колёс, так же как на вычислительной машине другого выдающегося учёного-изобретателя Блеза Паскаля — «Паскалине». Добавленная в конструкцию движущаяся часть (прообраз подвижной каретки будущих настольных калькуляторов) и специальная рукоятка, позволявшая крутить ступенчатое колесо (в последующих вариантах машины — цилиндры), позволяли ускорить повторяющиеся операции сложения, при помощи которых выполнялось деление и перемножение чисел. Необходимое число повторных сложений выполнялось автоматически.
В 1834 году англичанин Чарльз Бэббидж изобрел аналитическую машину. Она состояла из "склада" для хранения чисел ("накопитель"), "мельницы" - для производства арифметических действий над числами ("арифметическое устройство"), устройство, управляющее в определенной последовательности операциями машины ("устройство управления"), устройство ввода и вывода данных.
В данной аналитической машине предусматривалось три различных способа вывода полученных результатов: печатание одной или двух копий, изготовление стереотипного отпечатка, пробивки на перфокартах. Аналитическая машина не была построена. Но Бэббидж сделал более 200 чертежей ее различных узлов и около 30 вариантов общей компоновки машины. При этом было использовано более 4 тысяч "механических обозначений". Аналитическая машина Бэббиджа - первый прообраз современных компьютеров.
29 февраля 1888 г.
124 года назад
Германом Холлеритом изобретена первая электрическая вычислительная машина. В основе устройства табулятора Холлерит использовал принципы идеи аналитической машины Бэббиджа с перфокартами. Фактически через 17 лет после смерти Бэббиджа идея создания электрической вычислительной машины нашла продолжение.
Это был следующий этап в развитии компьютеров. Идею использования перфокарт в работе табуляторов подсказал Холлериту чиновник бюро переписи Джон Шоу Биллингс. Он же был сподвижником Холлерита в работе над проектированием системы табуляторов.
Созданная Холлеритом счетная машина позволила завершить предварительные подсчеты за 6 недель. Изобретатель был удостоен нескольких премий и звания профессора Колумбийского университета.
Холлерит организовал фирму по производству табуляторов. В настоящее время эта фирма, претерпев несколько изменений и переименований, является крупнейшей в мире промышленной фирмой и носит известное всем пользователям компьютеров название International Business Machines Corporation или IBM.
ЭВМ первого поколения были ламповыми машинами 50-х годов. Их элементной базой были электровакуумные лампы. Эти ЭВМ были весьма громоздкими сооружениями, содержавшими в себе тысячи ламп, занимавшими иногда сотни квадратных метров территории, потреблявшими электроэнергию в сотни киловатт.
Например, одна из первых ЭВМ – ENIAC – представляла собой огромный по объему агрегат длиной более 30 метров, содержала 18 тысяч электровакуумных ламп и потребляла около 150 киловатт электроэнергии.
Для ввода программ и данных применялись перфоленты и перфокарты. Не было монитора, клавиатуры и мышки. Использовались эти машины, главным образом, для инженерных и научных расчетов, не связанных с переработкой больших объемов данных. В 1949 году в США был создан первый полупроводниковый прибор, заменяющий электронную лампу. Он получил название транзистор.
Транзисторы
В 60-х годах транзисторы стали элементной базой для ЭВМ второго поколения. Машины стали компактнее, надежнее, менее энергоемкими. Возросло быстродействие и объем внутренней памяти. Большое развитие получили устройства внешней (магнитной) памяти: магнитные барабаны, накопители на магнитных лентах.
В этот период стали развиваться языки программирования высокого уровня: ФОРТРАН, АЛГОЛ, КОБОЛ. Составление программы перестало зависеть от конкретной модели машины, сделалось проще, понятнее, доступнее.
В 1959 г. был изобретен метод, позволивший создавать на одной пластине и транзисторы, и все необходимые соединения между ними. Полученные таким образом схемы стали называться интегральными схемами или чипами. Изобретение интегральных схем послужило основой для дальнейшей миниатюризации компьютеров.
В дальнейшем количество транзисторов, которое удавалось разместить на единицу площади интегральной схемы, увеличивалось приблизительно вдвое каждый год.
Третье поколение ЭВМ создавалось на новой элементной базе – интегральных схемах (ИС).
Микросхемы
ЭВМ третьего поколения начали производиться во второй половине 60-х годов, когда американская фирма IBM приступила к выпуску системы машин IBM-360. Немного позднее появились машины серии IBM-370.
В Советском Союзе в 70-х годах начался выпуск машин серии ЕС ЭВМ (Единая система ЭВМ) по образцу IBM 360/370. Скорость работы наиболее мощных моделей ЭВМ достигла уже нескольких миллионов операций в секунду. На машинах третьего поколения появился новый тип внешних запоминающих устройств – магнитные диски.
Успехи в развитии электроники привели к созданию больших интегральных схем (БИС), где в одном кристалле размещалось несколько десятков тысяч электрических элементов.
Микропроцессор
В 1971 году американская фирма Intel объявила о создании микропроцессора. Это событие стало революционным в электронике.
Микропроцессор – это миниатюрный мозг, работающий по программе, заложенной в его память. Соединив микропроцессор с устройствами ввода-вывода и внешней памяти, получили новый тип компьютера: микро-ЭВМ.
Микро-ЭВМ относится к машинам четвертого поколения. Наибольшее распространение получили персональные компьютеры (ПК). Их появление связано с именами двух американских специалистов: Стива Джобса и Стива Возняка. В 1976 году на свет появился их первый серийный ПК Apple-1, а в 1977 году – Apple-2.
Однако с 1980 года «законодателем мод» на рынке ПК становится американская фирма IBM. Ее архитектура стала фактически международным стандартом на профессиональные ПК. Машины этой серии получили название IBM PC (Personal Computer). Появление и распространение ПК по своему значению для общественного развития сопоставимо с появлением книгопечатания.
С развитием этого типа машин появилось понятие «информационные технологии», без которых невозможно обойтись в большинстве областей деятельности человека. Появилась новая дисциплина – информатика.
ЭВМ пятого поколения будут основаны на принципиально новой элементной базе. Основным их качеством должен быть высокий интеллектуальный уровень, в частности, распознавание речи, образов. Это требует перехода от традиционной фон-неймановской архитектуры компьютера к архитектурам, учитывающим требования задач создания искусственного интеллекта. Таким образом, для компьютерной грамотности необходимо понимать, что на данный момент создано четыре поколения ЭВМ:
1-ое поколение: 1946 г. создание машины ЭНИАК на электронных лампах.
2-ое поколение: 60-е годы. ЭВМ построены на транзисторах.
3-ье поколение: 70-е годы. ЭВМ построены на интегральных микросхемах (ИС).
4-ое поколение: Начало создаваться с 1971 г. с изобретением микропроцессора (МП). Построены на основе больших интегральных схем (БИС) и сверх БИС (СБИС).
Пятое поколение ЭВМ строится по принципу человеческого мозга, управляется голосом. Соответственно, предполагается применение принципиально новых технологий. Огромные усилия были предприняты Японией в разработке компьютера 5-го поколения с искусственным интеллектом, но успеха они пока не добились.
МЭСМ (Малая электронная счётная машина) — советская ЭВМ, первая в СССР и континентальной Европе[1][2]. Разрабатывалась лабораторией С. А. Лебедева (на базе киевского Института электротехники АН УССР) с конца 1948 года.
Первоначально МЭСМ задумывалась как макет или модель Большой электронной счётной машины (БЭСМ), первое время буква «М» в названии означала «модель»[3]. Работа над машиной носила исследовательский характер, в целях экспериментальной проверки принципов построения универсальных цифровых ЭВМ. После первых успехов и с целью удовлетворения обширных потребностей в вычислительной технике, было принято решение доделать макет до полноценной машины, способной решать реальные задачи.
БЭСМ-6 (Большая Электронно-Счётная Машина) — советская электронная вычислительная машина, первая суперЭВМ на элементной базе второго поколения — полупроводниковых транзисторах.
PDP-8 — первый успешный коммерческий миникомпьютер, производившийся корпорацией Digital Equipment Corporation (DEC) в 1960-х. DEC представила его 22 марта 1965 и продала более 50 тысяч штук, самое большое количество компьютеров для того времени. Это был первый широко продаваемый компьютер серии DEC PDP (PDP-5 являлся компьютером для решения специфических задач).
Ранняя модель PDP-8 (неофициально называвшаяся «Straight-8») была построена на диодно-транзисторной логике, упакованной на картах Flip Chip, и достигала размеров холодильника.
Мини-ЭВМ
ЭВМ, относящаяся к классу вычислительных машин, разрабатываемых из требования минимизации стоимости и предназначенных для решения достаточно простых задач
Первые фирменные домашние ПК
В 1976—1977 годах несколькими фирмами были выпущены первые персональные компьютеры, в том числе с 1977 года тысячами продавались компьютеры компаний Commodore и Tandy Radio Shack.
В 1977 году появился первый массовый персональный компьютер Apple II молодой компании Apple Computer, что явилось предвестником бума всеобщей компьютеризации населения.
Домашние компьютеры стали более удобными и требовали от своих пользователей уже гораздо меньшего количества технических навыков. В августе 1981 года IBM выпустила компьютерную систему IBM PC (фирменный номер модели IBM 5150), положившую начало эпохе современных персональных компьютеров. В 1980-х годах также появился ZX Spectrum, выпущенный английской компанией Sinclair Research.
Amiga и Macintosh
В январе 1983 года был представлен публике первый персональный компьютер с GUI, Apple Lisa, однако из-за высокой цены и некоторых других особенностей успех машины был ограничен. Год спустя, в январе 1984 года начались продажи Apple Macintosh, ставшего первым по-настоящему массовым ПК с GUI. 23 июля 1985 года появился первый в мире мультимедийный персональный компьютер Amiga (Amiga 1000). Персональные компьютеры Amiga, наряду с макинтошами, оставались самыми популярными и продаваемыми машинами для домашнего использования (IBM PC доминировали в сфере конторских компьютеров, здесь их продажи были несравнимо выше) вплоть до 1995 года.
В 1995 году произошло два ключевых события в истории ПК: банкротство корпорации Commodore и появление Microsoft Windows 95, приблизившей IBM PC-совместимые компьютеры к тем возможностям, которые существовали на Commodore Amiga и Apple Macintosh. Сегодня возможности мультимедиа доступны в каждом доме и на любой аппаратной платформе.
26. Архитектура ЭВМ: архитектура фон Неймана, процессор, АЛУ, УУ, память, внешние устройства, принципы фон Неймана, структура запоминающих устройств, контролеры внешних устройств, шина, принцип открытой архитектуры, тенденции развития архитектуры.
Архитектура фон Неймана (англ. von Neumann architecture) — широко известный принцип совместного хранения программ и данных в памяти компьютера. Вычислительные системы такого рода часто обозначают термином «машина фон Неймана», однако, соответствие этих понятий не всегда однозначно. В общем случае, когда говорят об архитектуре фон Неймана, подразумевают физическое отделение процессорного модуля от устройств хранения программ и данных.
Принцип хранимой программы Нейман первым догадался, что программа может также храниться в виде нулей и единиц, причем в той же самой памяти, что и обрабатываемые ею числа. Отсутствие принципиальной разницы между программой и данными дало возможность ЭВМ самой формировать для себя программу в соответствии с результатами вычислений. Устройство управления (УУ) и арифметико-логическое устройство (АЛУ) в современных компьютерах объединены в один блок - процессор, являющийся преобразователем информации, поступающей из памяти и внешних устройств.
Память (ЗУ) хранит информацию (данные) и программы. Запоминающее устройство у современных компьютеров "многоярусно" и включает оперативное запоминающее устройство (ОЗУ) и внешние запоминающие устройства(ВЗУ).
ОЗУ- это устройство, хранящее ту информацию, с которой компьютер работает непосредственно в данное время (исполняемая программа, часть необходимых для нее данных, некоторые управляющие программы)ВЗУ- устройства гораздо большей емкости, чем ОЗУ, но существенно более медленны.
Принцип последовательного выполнения операций
Структурно основная память состоит из пронумерованных ячеек. Процессору в произвольный момент времени доступна любая ячейка. Отсюда следует возможность давать имена областям памяти, так, чтобы к запомненным в них значениям можно было бы впоследствии обращаться или менять их в процессе выполнения программы с использованием присвоенных имен.
Принцип произвольного доступа к ячейкам оперативной памяти
Программы и данные хранятся в одной и той же памяти. Поэтому ЭВМ не различает, что хранится в данной ячейке памяти - число, текст или команда. Над командами можно выполнять такие же действия, как и над данными.
Память (ЗУ) хранит информацию (данные) и программы. Запоминающее устройство у современных компьютеров "многоярусно” и включает оперативное запоминающее устройство (ОЗУ), хранящее ту информацию, с которой компьютер работает непосредственно в данное время (исполняемая программа, часть необходимых для нее данных, некоторые управляющие программы), и внешние запоминающие устройства (ВЗУ) гораздо большей емкости, чем ОЗУ. но с существенно более медленным доступом (и значительно меньшей стоимостью в расчете на 1 байт хранимой информации). На ОЗУ и ВЗУ классификация устройств памяти не заканчивается – определенные функции выполняют и СОЗУ (сверхоперативное запоминающее устройство), и ПЗУ (постоянное запоминающее устройство), и другие подвиды компьютерной памяти.
Процессор – функциональная часть ЭВМ, выполняющая основные операции по обработке данных и управлению работой других блоков. Процессор является преобразователем информации, поступающей из памяти и внешних устройств.
Запоминающие устройства обеспечивают хранение исходных и промежуточных данных, результатов вычислений, а также программ. Они включают: оперативные (ОЗУ), сверхоперативные СОЗУ), постоянные (ПЗУ) и внешние (ВЗУ) запоминающие устройства.
Оперативные ЗУ хранят информацию, с которой компьютер работает непосредственно в данное время (резидентная часть операционной системы, прикладная программа, обрабатываемые данные). В СОЗУ хранится наиболее часто используемые процессором данные. Только та информация, которая хранится в СОЗУ и ОЗУ, непосредственно доступна процессору Внешние запоминающие устройства (накопители на магнитных дисках, например, жесткий диск или винчестер) с емкостью намного больше, чем ОЗУ, но с существенно более медленным доступом, используются для длительного хранения больших объемов информации. Например, операционная система (ОС) хранится на жестком диске, но при запуске компьютера резидентная часть ОС загружается в ОЗУ и находится там до завершения сеанса работы ПК.
ПЗУ (постоянные запоминающие устройства) и ППЗУ (перепрограммируемые постоянные запоминающие устройства) предназначены для постоянного хранения информации, которая записывается туда при ее изготовлении, например, ППЗУ для BIOS.
Шина - это кабель, состоящий из множества проводников. По одной группе проводников - шине данных передаётся обрабатываемая информация, по другой - шине адреса - адреса памяти или внешних устройств, к которым обращается процессор. Третья часть магистрали - шина управления, по ней передаются управляющие сигналы (например, сигнал готовности устройства к работе, сигнал к началу работы устройства и др). Системная шина характеризуется тактовой частотой и разрядностью. Количество одновременно передаваемых по шине бит называется разрядностью шины. Тактовая частота характеризует число элементарных операций по передаче данных в 1 секунду. Разрядность шины измеряется в битах, тактовая частота – в мегагерцах.
В современных ЭВМ реализован принцип открытой архитектуры, позволяющий пользователю самому комплектовать нужную ему конфигурацию компьютера и производить при необходимости её модернизацию. Конфигурацией компьютера называют фактический набор компонентов ЭВМ, которые составляют компьютер. Принцип открытой архитектуры позволяет менять состав устройств ЭВМ. К информационной магистрали могут подключаться дополнительные периферийные устройства, одни модели устройств могут заменяться на другие.
27. Принципы работы ЭВМ: счетчик адреса команд, процесс загрузки и функционирования ЭВМ, порядок исполнения команды, формат команд (операционная и адресная часть), одноадресные, двухадресные и трехадресные команды, основные группы машинных команд, CISC и RISC архитектуры.
1. Принцип двоичного кодирования.
Для представления данных и команд используется двоичная система счисления.
2. Принцип однородности памяти.
Как программы (команды), так и данные хранятся в одной и той же памяти
(и кодируются в одной и той же системе счисления — чаще всего двоичной). Над командами можно выполнять такие же действия, как и над данными. Это открывает целый ряд возможностей. Например, программа в процессе своего выполнения также может подвергаться переработке, что позволяет задавать в самой программе правила получения некоторых ее частей (так в программе организуется выполнение циклов и подпрограмм). Более того, команды одной программы могут быть получены как результаты исполнения другой программы. На этом принципе основаны методы трансляции — перевода текста программы с языка программирования высокого уровня на язык конкретной машины.