

Шпоры по МПиПА1
.doc
Применительно к прог-ю технологию можно определить как процесс создания, сопровождение и применения ПП. Любая технология прог-я базируется на некоторой методологии разработки программ. Методология – это система принципов, способов организации и построения теоретической и практической деятельности, а также учение о самой системе. Самой важной целью методологии прог-я явл-ся изучение и внедрение таких методов проектирования программ, которые облегчают задачу сопровождения программ. Легкость сопровождения – это такое качество программы, которое нельзя улучшить после её разработки никакими другими способами кроме перепрог-я. Методология реализуется в методах. Под методом понимают совокупность приемов и операций практического и теоретического освоения деятельности. В прог-ии широкую известность приобрели методы функционального, структурного, модульного и ООП прог-я. Одним из важных понятий Технологии прог-я является понятие жизненного цикла программы(ЖЦП). ЖЦПП определяется как совокупность последовательных состояний ПП и всех действий по его преобразованию, начиная с анализа возникшей потребности в автоматизации определённых действий по обработке данных, до их программной реализации и включения в ПО конкретного применения.
Традиционно в ЖЦПП принято выделять следующие этапы:1).Анализ. 2)Проектирование. 3)Программирование 4.)Тестирование и отладка .5) Эксплуатация и сопровождение В процессе проектирования важен критерий окончания этапов при выполнении которого можно фиксировать окончание того или иного этапа и определять сроки окончания разработки. В качестве такого критерия может выступать готовность документов. Проектирование – это процесс, протекающий во времени и следовательно имеющий временную диаграмму своей реализации. Временная последовательность этапов учитывается в модели ЖЦ. Традиционная модель ЖЦПП строится по каскадному принципу, суть которого заключается в том, что переход на следующий этап происходит по окончании предыдущего. Недостатком данной модели является то, что на практике принятое на предыдущем этапе решение приходится пересматривать из-за неверной интерпретации требований заказчика. Этот недостаток является настолько существенным, что делает эту модель малопригодной. Поэтому более правдоподобным является возврат текущего этапа на предыдущий для корректировки проектного решения. Такая модель ЖЦ строится по поэтапному принципу с промежуточным контролем. Критерий перехода на следующий этап является готовность документов. Спиральная модель. Делается упор на начальные этапы ЖЦ. 1).Анализ требований 2).Проек-ние спецификации. 3).Предварительное детальное проектирование На этих этапах проверяется и обосновывается реализуемость тех. решений путем созданий прототипов. Все эти этапы выполняются на каждом витке спирали ЖЦ. Каждый виток соотв-ет некоторому уровню детализации проекта. Каждый след. Виток характеризуется более высокой степенью детализации. Преимущества: 1.Накопление и повторное использование программных средств, моделей, прототипов. 2 Ориентация на развитие и модификацию ПО. 3.Анализ риска и издержек в процессе проектирования
ЖЦПП сопровождается разработкой таких документов как потребность в автоматизации, функциональная архитектура, системная архитектура и ПП. Потребность в автоматизации. В технике подобный документ называется техническим заданием. В данном документе содержится описание целей автоматизации с точки зрения пользователя. Функ-ая архитектура. Включает формализованное описание, предъявляемых к ПП требований, как с точки зрения пользователей таки с точки зрения разработчика. Данный документ называют тех. Требованиями. В состав функ. Архитектуры входит: 1). Описание функции ПП 2).Описание требуемых режимов функционирования среды. Описание функций ПП представляют в виде дерева целей. Системная архитектура. Представляет собой документ, отражающий модульную и иерархическую структуру проектного ПП с подробным описанием функциональных спецификаций отдельных модулей, т.е. блок схема, а также другие схемы, описанные по ГОСТам. Формулу ПП можно записать след. образом ПП=коды программ + проект. Под проектом разработчики понимают окончательное и исчерпывающее обоснование и описание средств реализации поставленной цели. При документировании проекта разработчик ПО применяет следующие схемы: 1. Работы системы, в которой формализуется процесс выполнения программы, а также взаимодействие пользователей и данных. 2. Программа, формализуется алгоритм процесса обработки данных. 3. Схема данных. Уточняются потоки данных между процессами. 4. Схема взаимодействия программ, отображает суть активации программ. 5. Схема ресурсов системы, отображает конфигурацию блоков данных и обрабатывающих блоков, которые требуются для решения задачи.
CASE-технологиями называют реализованные в виде ПП технологические схемы, ориентированные на создание сложных программных систем и поддержку их полного ЖЦ. Используются не только для производства ПП, но и как мощный инструмент решения исследовательских и проектных задач. Такие задачи включают: 1)Структурный анализ предметной области. 2)Моделирование деловых предложения с целью решения стратегического и оперативного планирования и управления ресурсами CASЕ-технологии являются продолжением всей отрасли разработки ПО. Выделяют 6 периодов разработки ПО, в качестве инструментов использовались: I CASE генерация: 1) Ассемблеры, анализаторы. 2) Компиляторы, интерпретаторы, трассировщики. 3)Символические отладчики пакет программ 4)Система анализа и управления исходными текстами 5)CASE-средства анализа требования, проектирования спецификаций и структуры, редактирования инетерфейса II CASE Генерация: 1)CASE-средства генерации исходных текстов и реализации интегрированного окружения полного ЖЦ разработки ПО. CASE начали развиваться с целью преодоления ограничения методологии структурного прог-я. Эта методология характеризуется большой трудоемкостью, большой стоимостью и трудностью внесения изменений в проектные спецификации. Основывается на спиральной модели ЖЦПП. Достоинства CASE: 1) улучшает качество создаваемого ПО за счет автоматизации контроля. 2) позволяет за короткое время создавать прототип будущей системы, что позволяет оценить на ранних этапах полученный результат. 3) Ускоряет процесс проектирования и разработки. 4) Позволяют разработчику больше времени уделять творческой работе по созданию ПО. 5) Поддерживает развитие и сопровождение разработки. 6)Поддерживает технологию повторного использования компонента разработки.
5.Технологии объектно-ориентированного программирования. ООПроект. - методы проектир., соед. в себе процесс объект. декомпозиции и приемы представления логической и физической стат. и дин. моделей проектиров. систем. ООП - процесс реализации прог., основанный на представлении проги в виде совокупности объектов. ООП предполагает, что любая функц. или процедура. в проге представляет собой метод объекта некоторого класса, причем класс в проге должен формироваться естествен. образ., как только в проге возникает необходимость описания нов. физич предметов или их абсолютных понятии. каждый новый шаг в разработке алгоритма должен представлять собой разработку нового класса на основе уже имеющегося класса.
6. Основные понятия используемые в ОО языках. 3 принципа объектно-ориентированного программирования: 1) инкапсуляция. Объединение переменных и функций для их обработки в одном типе данных. В классах переменные называются свойствами, а функции – методами. 2) Наследование. Определение класса и использование его для построения иерархии порожденных классов с возможностью доступа объектов порожденных классов к свойствам и методам базовых классов. 3) Полиморфизм. Присвоение действию одного имени, которое будет использоваться по иерархии классов, причем каждый класс будет использовать его удобным для него способом (тем способом, который в нем определен. Создание нового класса: class имя {члены_класса}; К членам класса относятся свойства и методы. Свойства – переменные, методы – функции. Доступ к ним осуществляется так: <объект_класса>.<свойство>, <объект_класса>.<метод([параметры])>. Конструктор – имя_класса() – обычно инициализируется значение переменной. Деструктор - ~имя_класса() – производит уничтожение объекта класса и освобождение памяти, занимаемой переменными (свойствами) объекта. Если в классе не описаны конструктор и/или деструктор, то среда предоставляет свои (по умолчанию) конструктор и деструктор.
7. Стратегии и методы тестирования . Тестирование программного обеспечения охватывает целый ряд видов деятельности, аналогичных последовательности процессов разработки программного обеспечения. В него входят/1: а) постановка задачи для теста, б) проектирование теста, в) написание тестов, г) тестирование тестов, д) выполнение тестов, е) изучение результатов тестирования. Решающую роль играет проектирование тестов. Возможен целый ряд подходов к стратегии проектирования тестов. Чтобы ориентироваться в них, рассмотрим два крайних подхода /1/. Первый состоит в том, что тесты проектируются на основе внешних спецификаций программ и модулей, либо спецификаций сопряжения программы или модуля. Программа при этом рассмат-тся как черный ящик (стратегия ‘черного ящика’). Существо такого подхода - проверить соответствует ли программа внешним спецификациям. При этом логика модуля совершенно не принимается во внимание. Второй подход основан на анализе логики программы (стратегия ‘белого ящика’). Существо подхода - в проверке каждого пути, каждой ветви алгоритма. При этом внешняя специф-ия во внимание не принимается. 23. Методы хэширования в основной памяти. Хэширование – есть разбиение множества ключей, однородных по характеру их элементов и представленных либо в виде строк, либо в виде чисел на непересекающихся подмножествах, обладающих определенным свойством. Это св-во описывается с помощью функции хэширования и называется хэш-адресом. Решение обратной задачи возможно на хэш-таблице: по хэш-адресу она обеспечивает быстрый доступ к элементу. В идеале для задач поиска хэш-адрес – уникален для того, чтобы за 1 обращение можно было получить доступ к элементу, характеризуемому данным ключом.(соверешенная хэш функция) Совершенное хэширование [A 000001000001]---[A(1)] [B 000001000010]---[B(2)] [Z 000001011010]---[Z(1A)] Здесь ключами являются коды, заменяющие буквы латинского алфавита, а хэш-функция отрезает от кода буквы младше 5 бит. В более сложных случаях на построение хэш-функции используются проги, которые по заданному набору ключей генерируют функции отображения ключей в индексах массива хранимых записей. Совершенная хэш функция не гарантирует, что все эл-ты массива будут заполнены записями с соответствующими значениями ключей. Кроме того, при добавлении хотя бы одного ключа к ранее заданному набору, потребуется генерация новой хэш-функции и соответствующей ей перестановки эл-ов массива записей. Коллизии при хэшировнии и способы их разрешения. Хэш-е может обеспечивать хорошие результаты и в том случае, когда набор ключей заранее неизвестен, но в этом случае нельзя говорить о генерации совершенной хэш-функции. Даже если будет заранее известен диапазон ключей, то для применения совершенного хэшир-я потребуется наличие в памяти массива с размером=мощности множества кючей. Подбор ф-и хэширования эмпирическим методом. (1) по значению ключа производит значения с индексов в границах массива.(2) равномерно распределяет ключи по эл-там массива. Если ORD(k) – обозначает порядковый номер ключа k в упорядоченном множестве допустимых ключей, а N – число эл-тов массива, то наиболее известной хэш-функцией в этом случае является H(k)=ORD(k)MODN такая функция выполняется очень быстро и обеспечивает достаточную равномерность распределения ключей в массивах. Однако если ключом является последовательность символов, то при исп-и данной функции возникает большая вероятность выработки одного и того же значения для ключей, отличающихся небольшим числом символов. Для облегчения данной ситуации в кач-ве N использую простое число. Вычисление функции становится более сложным, но вероятность выработки одного значеия для разных ключей снижается. Используются и более сложные способы вычисления хэш-функции основанные, например, на вырезке поднабора бит из битового представления ключа или вычислении квадратичного выражения от ORD(k). Но в любом случае с ненулевой вероятностью хэш-функция может выдать одно значение для разных значений ключа. Такая ситуация называется коллизией ключей. Одним из выходов является увеличение размера массива, образование новой хэш-функции и расстановка заново всех занятых элементов массива.. Принято различать методы прямой адресации (ключ, появление которого вызвало коллизию, помещается в один из свободных элементов хэш-таблицы) и методы цепочек (записи, для ключей которых выработано одинаковое значение хэш-функции связываются в линейный список). Линейное зондирование Идея состоит в том, что сталкиваясь с коллизией при включении записи, мы последовательно просматриваем массив в поиске первого незанятого элемента. Если такой элемент обнаруживается, в него и заносится включаемая запись. Если все элементы массива заняты, то это означает, что хэш-таблица переполнена и требуется расширение массива и новая расстановка его элементов. Если коллизия обнаруживается при поиске (т.е. следуя применяемой хэш-функции мы обращаемся по свертке ключа к элементу массива и обнаруживаем, что он занят записью с другим ключом), последовательно просматриваются следующие элементы массива, пока не будет найдена запись с указанным ключом, либо мы не наткнемся на свободный элемент массива. Недостаток метода состоит в том, что при разрешении коллизии вторичные элементы массива (те, на которые прямо не указывает хэш-функция) имеют обыкновение сосредотачиваться вблизи первичных элементов. Заполнение массива происходит неравномерно, и увеличивается вероятность следующих коллизий. Двойное хэширование. Метод состоит в том, что если при включении или поиске ключа в хэш-таблице возникает коллизия, то к ключу применяется вторичная хэш-функция, значение которой указывает циклическое смещение в массиве от текущего индекса к элементу, в который следует включать или в котором следует искать требуемую запись. Сущ-ет способ, состоящий в использовании квадратичной функции при вычислении индекса следующей пробы. В этом случае последовательность вычисления индексов проб при включении или поиске записи является следующей: h0 = H(K), hi = (h0 + i^2) MOD N (i>0) Основным недостатком метода квадратичных проб является то, что для включаемой записи может не найтись свободного элемента массива даже в том случае, когда около половины элементов являются свободными.
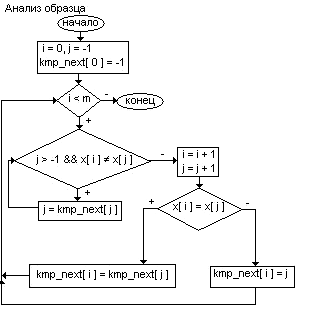
17. Алгоритмы поиска подстройки в строке. 1. Алгоритм Грубой силы. Данный алг-м заключается в проверке всех позиций текста на предмет совпадения с нач. обазца. Если произошло совпадение то просматривается следующая буква и т.д. Данный алг-м не нуждается в предварительной обработке и в дополнительном пространстве. 2. Алгоритм Морриса – Тратта. Данный алг-м появился в результате тщательного анализа алгоритма грубой силы. Исследователи хотели найти способ более полного исследования инф-и, полуненной во время скашерования. Алгоритм грубой силы её просто выбрасывает. Р-р сдвига образца можно увеличить одновременно запомнив части текста совпадающие с образцом. Это поможет избежать ненужных сравнений, это будет способствовать увеличению скорости поиска. 3. Алгоритм КНУТТА-МОРРИСА-ПРАТТА.
время поиска
сокращается за счёт: 1. возможности
перемещения образца по тексту более
чем на один символ. 2. за счёт
невозможности перемещения по тексту
в обратном направлении. Возможно
большее сокращение времени за счёт
доп. сравнения на этапе анализа образца.
Эффективен, когда наблюдается совпадение
нескольких символов образца с текстом.
4. АЛГОРИТМ
БОУЕРА-МУРА.
|
9. Методы стратегии «черного ящика». - Метод эквивалентного разбиения. Поскольку приходится ограничиваться использованием небольшого числа подмножества входных данных, то 1) каждый тест должен включать столько различных входных условий, сколько возможно, с тем, чтобы минимизировать число тестов. 2) необходимо попытаться разбить входную область программы на конечное число классов эквивалентности так, чтобы можно было предположить, что каждый тест, являющийся представителем какого-то класса, эквивалентен любому другому тесту этого класса. Разработка тестов этим методом осуществляется в 2 этапа: 1) выделение классов эквивалентности. 2) построение тестов. Построение тестов: данный процесс включает в себя: 1) назначение каждому классу эквивалентности уникального номера 2) проектирование новых тестов, каждый из которых покрывает как можно большее число непокрытых правильных классов эквивалентности,пока все правильные классы эквивалентности не будут покрыты тестами.3)Запись тестов, каждый из которых покрывает один из непокрытых неправильных классов эквивалентности. Каждый неправильный класс эквивалентности должен быть покрыт индивидуальным тестом. Причина состоит в том, что определённые проверки с ошибочными входами скрывают или заменяют другие ошибки. Метод анализа граничных значений: граничные условия – это ситуация, возникающая непосредственно на выше или ниже входных или выходных классов эффективности. Анализ граничных значений отличается от эквивалентного разбиения следующим: выбор любого элемента в классе эквивалентности при анализе граничных значений осуществляется следующим образом, чтобы проверить тестом каждую границу этого класса. При разработке тестов рассматриваются не только входные условия, но и пространство результатов, т.е. выходные классы эквивалентности.
10. Модульное тестирование В тестирование многомодульных программ можно выделить четыре этапа: 1)тест-е отд-ных модулей;2) совместное тест-е модулей; 3) тест-е спецификации проги;4) тест-е всего комплекса в целом. На первых двух этапах используются прежде всего методы структурного тест-я, т.к. на посл-ющих этапах тест-я эти методы исп-вать сложнее из-за больших размеров проверяемого ПО; последующие этапы тест-ния ориентированы на обнаружение ошибок разл-го типа, кот-ые не обяз-но связаны с логикой проги. Известны два подхода к тест-нию модулей: монолитное и пошаговое тест-е. При монолитном тест-ии сначала по отдельности тест-ся все модули программного комплекса, а затем все они объединяются в рабочую прогу для комплексного тест-я. Для автономного тест-я кажд модуля требуется модуль - драйвер и неск-ко модулей - заглушек (имитирующих работу модулей, вызываемых из тестируемого). При пошаговом тест-нии кажд модуль для своего тест-я подкл-ся к набору уже проверенных модулей. При ПТ модули проверяются не изолированно друг от друга, поэтому требуются либо только драйверы, либо только заглушки.При ПТ возможны две стратегии подкл-ния модулей: нисходящая и восходящая. Нисходящее тест-ние нач-ся с главного (или верхнего) модуля проги, а выбор следующего подключаемого модуля происходит из числа модулей, вызываемых из уже протест-ных. Одна из осн-х проблем, возникающих при НТ, - созд-е заглушек. (+)-сы НТ: уже на ранней стадии тест-я есть возм-сть получить работающий вариант разр-ваемой проги; быстро могут быть выявлены ошибки, связанные с организацией взаимод-я с пользователем. При восходящем тест-ии проверка проги нач-ся с терминальных модулей.Эта стратегия во многом противоположна НТ-нию (в частности, (+)-сы становятся (-) и наоборот). (+)-сы ВТ :поскольку нет промежуточных модулей, нет проблем, связанных с трудностью задания тестов;нет трудностей, вызывающих желание перейти к тест-ю след-го модуля, не завершив проверки пред-го. (-)-м ВТ является то , что проверка всей структуры разрабатываемого программного комплекса возможна только на завершающей стадии тест-я. В большинстве случаев более предпочтительным является ВТ.
11. Отладка Отладкой называется процесс выявления природы ошибки программы и исправления ошибок. В нем выделяют две задачи: 1. определение природы ошибки; 2. исправление ошибки. Метод грубой силы: 1) отладка с исп-ем операторов печати в проге 2)с исп-ем автоматич ср-в. Метод индукции включает: определение данных тестирования, имеющих отношение к ошибке; анализ от частного к общему позволит выявить закономерности в данных пункта 1); в результате анализа (п.2) выдвигается гипотеза о причине ошибки; для подтверждения гипотезы 3 разрабатывается один или больше тестов, которые должны либо подтвердить, либо опровергнуть гипотезу; если дополнительные тесты подтверждают гипотезу, можно приступать к исправлению ошибки, а вот если не подтверждают, то требуется в лучшем случае возврат к п.3, а в худшем - к п.2. метод дедукции заключается в: перечисление возможных причин или гипотез: использование данных тестирования для исключения некоторых возможных причин; уточнение выбранной наиболее вероятной гипотезы, возможно с использованием дополнительных тестов; доказательство выбранной гипотезы совпадает с п.4 и п.5 метода индукции.
12. Качество программного продукта Качество ПП – это совокупность его черт и характеристик, которые влияют на способность ПП удовлетворять заданные потребности пользователя. Улучшение одних показателей качества может быть достигнуто за счет ухудшения других.Критериями качества ПП являются: Функциональность - способность ПП выполнять набор функций, определенных его внешними спецификациями; Надежность - это способность безотказно выполнять заданные функции при заданных условиях в течение заданного периода времени с высокой степенью вероятности. Для надежного ПП важно, чтобы ошибки появлялись достаточно редко и не приводили к катастрофическим последствиям. легкость применения - это способность минимизировать затраты пользователя на подготовку и ввод исходных данных и оценку полученных результатов. Эффективность - это отношение уровня услуг, предоставляемых ПП к объему используемых вычислительных ресурсов. Сопровождаемость - это такие характеристики ПП, которые позволяют минимизировать усилия по внесению изменений при обнаружении ошибок в ПП и при его модификации.
13.Алгоритмы и их эффективность. Алгоритм – это не просто набор бесконечного числа правил задающих последовательность выполнения определений для задач определённого типа. Особенности: А) Конечность – алгоритм должен всегда заканчиваться после выполнения конечного числа шагов. Б) Определённость – каждый шаг алгоритма должен быть точно определён. Алгоритм обычно описывается обычным языком, поэтому существует возможность их неточного понимания. В) Ввод – алгоритм имеет некоторое число входных данных. Г) Вывод – у алгоритма есть ондо или несколько выходных данных, т.е. величин имеющих вполне определённую связь с входными данными. Д) Эффективность – осн вопрос прогр-я - выбор алг-ма для реш-я конкр. задачи. Пользователь всегда предпочитает более эффективные решения, даже в тех случаях, когда эффективность не является решающей. Эффективность состоит: 1)Память (или пространство). 2)Время. Пространственная эффективность измеряется количеством памяти для выполнения проги. Временная эффективность определяется временем для выполнения проги. Лучший способ сопоставления эффективностей состоит в сопоставлении их порядков сложности. Данный метод применим, как временной, так и пространственной эффективности, порядок сложности алгоритмов выражает его эффективность обычно ч/з количество обрабатываемых данных.
14. Порядок сложности алгоритма. Это функция доминирующая над точным выражением временной сложности. Напр. f(n) имеет порядок O(g(n)), если имеется нек. конст k и счетчик n0, такие, что f(n)(k*g(n)) при n>n0, известно, что действительное время обработки массива будет след: Действ время(длина массива)=Длина массива2+5*Дл.масс.+100 Вспом. функция будет: Оценка времени(длина массива)=1.1* Длина массива2 О - функция выражает относительную скорость алгоритма в зависимости от некоторой переменной или переменных. Правила: 1) О(k*f)=O(f) 2) O(f*g)=O(f)*O(g) O(f/g)=O(f)/O(g) 3) O(f+g)=доминанте O(f) или O(g) Где: k – const, f и g – функции. 1ое правило означает, что постоянные множители не имеют значения для определения порядка сложности. 2ое правило: порядок сложности произведения функция = произведению их сложностей. 3ье правило: порядок сложности суммы функций = доминанте одной из сложностей.
15. Виды сложностей алгоритмов. 1)Const – сложность. В том случае, если алгоритм требует всегда одного и того же времени для выполнения, вне зависимости от размера данных. 2)Полиноминальная сложность O(N^2) и O(N^3) 3) Логарифмическая сложность O(log(N)) – В этом случае прога работает медленней, когда N – увеличивается. Такую сложность имеют все алгоритмы, которые разбивают задачи на части, решают их, а потом соединяют решение. 4)Экспоненциальная сложность. О(2N) Временная сложность алгоритма может быть подсчитана исходя из анализа его управляющих структур.
Если нет рекурсии и циклов, то все управляющие структуры могут быть сведены к структурам const – сложности, следовательно весь алгоритм может характеризоваться константной сложностью
8. Методы стратегии ‘белого ящика’ Метод покрытия операторов Если отк-ся полн-ю от тест-я всех путей, можно показать, что критерием покрытия явл-я вып-е кажд. оператора проги хотя бы 1 раз. Это необх-мое, но недост-ное усл-е для приемлемого тест-ния по принц-пу бел. ящика. 1) 2)
В этой проге можно вып-ть кажд. опер-тор, заполнив один ед. тест, кот-ый реализовал бы путь ace. Т.е., если бы на входе было: А=2, В=0, Х=3, кажд. оператор вып-лся бы 1 раз. Заменим “and”“or” и во 2-м вместо “x>1”“x<1” (правильная прога 1), а неправильная – 2)). Рез-ты тест-ния приведены в таблице. Ожидаемый рез-т опр-яется по алг-му на рис. 1), а фактический - по алгоритму рисунка 2), поскольку опр-яется чувств-сть метода тест-ния к ошибкам прогр-вания. Как видно из этой табл, ни одна из этих ошибок не будет обнаружена .
Метод покрытия решений (покрытия переходов) Согласно данному методу должно быть написано дост-ное число тестов, такое, что кажд направление перехода должно быть реализовано по крайней мере один раз. ПРеш обычно удовлетворяет критерию ПОп. Т.к. кажд опер-р лежит на некотором пути, исходящем либо из опер-ра перехода, либо из точки входа проги, при вып-нии каждого направления перехода каждый опе-р должен быть вып-нен. Для проги приведенной на рис 2) ПРеш может быть вып-но двумя тестами, покрывающими пути {ace, abd}, либо {aсd,abe}. Пути {aсd,abe}покроим, выбрав следующие исходные данные: {A=3, B=0, X=3} и {A=2, B=1, X=1} -
Метод покрытия условий Лучшие рез-ты по сравнению с пред-ми может дать метод П.У. В этом случае записывается число тестов, дост-ное для того, чтобы все возможные рез-ты кажд усл-я в решении вып-лись по крайней мере 1 раз. Для дан-го примера имеем 4 условия: {A>1, B=0}, {A=2, X>1}. Cлед-но, требуется дост-е число тестов, такое, чтобы реализ-ть ситуации, где A>1, A1, B=0 и B0 в точке а и A=2, A2, X>1 и X1 в точке b. Тесты, удовл-щие критерию П. У. и соотв-щие им пути: а) A=2, B=0, X=4 ace б) A=1, B=1, X=0 abd
|
16. Оценка программ. При работе алгоритма пользователя обычно интересует средний случай, т.е. ожидаемое время работы проги для типичных входных данных и худший случай – ожидаемое время работы на самых плохих входных данных. Некоторые алгоритмы хорошо изучены в том смысле, что известны точные математические формулы для среднего и худшего случая. Такие формулы разрабатываются по средствам тщательного изучения проги с целью нахождения времени работы в терминах матем. характеристик, а затем производит их мат. анализ, он необходим из-за: А) Прога на языке высокого уровня транслируется в машинные коды и понять сколько времени для выполнения того или иного оператора может быть трудно. Б) Многие проги чувствительны к входным данным и эффективность может от них сильно зависеть. Может оказаться, что средний случай яв-ся матем. функцией не связанной с теми данными на которых используется программа, а худший случай может оказаться маловероятным. Лучший, худший и средний случай большое влияние играет при сортировке. Недостатки: 1)Для сложных алгоритмов получение О-оценок очень трудоёмко, либо невозможно. 2)О – оценки очень грубые для отображения более тонких отличий алгоритма. (0,001*N и 1000*N) 3)О – анализ даёт слишком мало информации для анализа поведения алгоритма при обработке небольших объёмов данных. 4)Существует ещё одна сложность – это определение среднего случая. Обычно, сделать это сложно из-за невозможности предсказания условия работы алгоритма. Иногда алгоритм используется, как фрагмент большой сложной проги. Иногда эффективность работы аппаратуры или ОС или некоторых компонентов компилятора существенно влияют на ложность алгоритма. Из-за трудностей связанных с проведением анализа возможной сложности алгоритма в среднем случае, приходится дов-ся оценками для лучш и худш. случаев.
17. Методы сортировки данных. Под сортировкой понимается перестановка объектов множества в определенном порядке. Целью алгоритма сортировки является переорганизации записей в файле таким образом, чтобы они располагались в нем в строго определенном порядке. Различают внутреннюю и внешняя сортировку. Внутр – данные помещаются в Озу, внешн – данные делятся на части, одна часть помещаются в Озу, сортир, затем помещается след часть и т. д. Метод сортировки наз-ся стабильным, если он сохраняет относительный порядок следования записи с одинаковыми ключами. 1)Сортировка выбором: Идея метода состоит в том, чтобы создавать отсортированную последовательность путем присоединения к ней одного элемента за другим в правильном порядке. Будем строить готовую последовательность, начиная с левого конца массива. Алгоритм состоит из n последовательных шагов, начиная от нулевого и заканчивая (n-1)-м. На i-м шаге выбираем наименьший из элементов a[i] ... a[n] и меняем его местами с a[i]. Вне зависимости от номера текущего шага i, последовательность a[0]...a[i] (выделена курсивом) является упорядоченной. Таким образом, на (n-1)-м шаге вся последовательность, кроме a[n] оказывается отсортированной, а a[n] стоит на последнем месте по праву: все меньшие элементы уже ушли влево.Расположим массив сверху вниз, от нулевого элемента - к последнему. Идея метода: шаг сортировки состоит в проходе снизу вверх по массиву. По пути просматриваются пары соседних элементов. Если элементы некоторой пары находятся в неправильном порядке, то меняем их местами. 2)Пузырек. Расположим массив сверху вниз, от нулевого элемента - к последнему.Идея метода: шаг сортировки состоит в проходе снизу вверх по массиву. По пути просматриваются пары соседних элементов. Если элементы некоторой пары находятся в неправильном порядке, то меняем их местами.После нулевого прохода по массиву "вверху" оказывается самый "легкий" элемент - отсюда аналогия с пузырьком. Следующий проход делается до второго сверху элемента, таким образом второй по величине элемент. 3) Сортировка вставками. Будем разбирать алгоритм, рассматривая его действия на i-м шаге. Как говорилось выше, последовательность к этому моменту разделена на две части: готовую a[0]...a[i] и неупорядоченную a[i+1]...a[n]. На следующем, (i+1)-м каждом шаге алгоритма берем a[i+1] и вставляем на нужное место в готовую часть массива. Поиск подходящего места для очередного элемента входной последовательности осуществляется путем последовательных сравнений с элементом, стоящим перед ним. В зависимости от результата сравнения элемент либо остается на текущем месте(вставка завершена), либо они меняются местами и процесс повторяется. 4) Сортировка Шелла. Рассмотрим следующий алгоритм сортировки массива a[0].. a[15]. --1. Вначале сортируем простыми вставками каждые 8 групп из 2-х элементов (a[0], a[8[), (a[1], a[9]), ... , (a[7], a[15]).-- 2. Потом сортируем каждую из четырех групп по 4 элемента (a[0], a[4], a[8], a[12]), ..., (a[3], a[7], a[11], a[15]). --3. Далее сортируем 2 группы по 8 элементов, начиная с (a[0], a[2], a[4], a[6], a[8], a[10], a[12], a[14]). 4. В конце сортируем вставками все 16 элементов. Единственной характеристикой сортировки Шелла является приращение - расстояние между сортируемыми элементами, в зависимости от прохода. 5) Быстрая сортировка. На входе массив a[0]...a[N] и опорный элемент p, по которому будет производиться разделение. 1- Введем два указателя: i и j. В начале алгоритма они указывают, соответственно, на левый и правый конец последовательности. 2-Будем двигать указатель i с шагом в 1 элемент по направлению к концу массива, пока не будет найден элемент a[i] >= p. Затем аналогичным образом начнем двигать указатель j от конца массива к началу, пока не будет найден a[j] <= p. 3- Далее, если i <= j, меняем a[i] и a[j] местами и продолжаем двигать i,j по тем же правилам... 4 -Повторяем шаг 3, пока i <= j.
18. Общая классификация алгоритмов поиска. Поиск - нахождение какой-нибудь конкретной инфы в большом объеме ранее созданных данных. Данные делятся на записи, каждая из котор имеет хотябы 1 ключ. Ключи используются для отличия одних записей от других. Цель поиска – нахождение всех записей подходящих к ключу. кроме поиска по совпадению аргумента и ключа, существует поиск по близости аргум и ключа. Логически сложные условия поиска могут быть конъюнктивными (обязат вып всех услов), дизэюнктивн (выполнение хотя бы одного условия). Все методы – статические (массив значений не меняется) или динамические (массив может изменять размер или перестраиваться). Последовательный поиск. Пусть заданы линейные списки элементов B и ключей V. Для каждого Vi найти множество всех совпадающих элементов. Часто имеет место ситуация когда V имеет 1 элемент, а в B есть не более 1 такого элемента. Послед поиск - просмотр элем списка B в порядке расположения, пока не найден элемент равный V, если неизвестно есть ли такой элемент в списке, необходимо следить чтобы поиск не вышел за пределы списка. Бинарный поиск. Для упорядоченных списков существует более эффективный алгоритм поиска. Он состоит в том, что ключ V сравнивается со средним элементом, если значения равны, то элемент найден, если нет поиск продолжается в одной из половин массива. Поиск по дереву Фибоначчи. Числа в дочерних узлах отличаются от родительских узлов на одну и ту же величину называемую числом Фибоначчи. Суть состоит в том, что сравнивая искомое число с очередным значением в массиве мы не делим по полам, а отступаем от предыдущего значения в нужную сторону на число Фибоначчи. Интерполяционный поиск. Пусть необходимое слово начинается с буквы «а», то поиск будет начат где-то в начале словаря, далее если вы заметите, что искомое слово должно находиться гораздо дальше открытой страницы, то вы пропустите порядочное число страниц, прежде чем сделаете новую попытку. Пусть известно что K лежит между Ke и Kг, в этом случае следующая проба делается на расстоянии (u-e)(K-Ke)/(Ku-Ke).
20. Методы доступа к данным В основе операций с данными (такими как выборка, изменение…) лежит процедура доступа. Пусть необходимо организовать доступ к файлу, содержащему набор одинаковых записей, каждая из которых имеет уникальное значение ключевого слова. Для этого клячи вместе с указателями на соответствующие записи копируют другую структуру, которая позволяет быстро осуществить операции сортировки и поиска. Существует 2 класса методов, реализующих доступ к данным по ключу: 1. Метод поиска по дереву; 2. Метод хэширования.
25. Методы хэширования для поиска во внешней памяти Исходная: если при управлении данными на основе хэширования в основной памяти хэш-функция вырабатывает адрес требуемого элемента, то при обращении к внешней памяти необходимо генерировать номер блока дискового пространства, в котором находится запрашиваемый элемент данных. Расширяемое хэширование. В основе подхода расширяемого хэширования лежит принцип использования деревьев цифрового поиска в основной памяти. В основной памяти поддерживается справочник, организованный на основе бинарного дерева цифрового поиска, ключами которого являются значения хэш-функции, а в листовых вершинах хранятся номера блоков записей во внешней памяти. В этом случае любой поиск в дереве цифрового поиска ведет к некоторому блоку внешней памяти. Входит ли в этот блок искомая запись, обнаруживается уже после прочтения блока в основную память. Как таковых, коллизий не существует. Может возникнуть лишь ситуация переполнения блока внешней памяти. Значение хэш-функции указывает на этот блок, но места для включения записи в нем уже нет. Тогда блок расщепляется на два, и дерево цифрового поиска переформируется соответствующим образом. Конечно, при этом может потребоваться расширение самого справочника. Расширяемое хэширование хорошо работает в условиях динамически изменяемого набора записей в хранимом файле, но требует наличия в основной памяти справочного дерева. Линейное хэширование Идея состоит в том, чтобы можно было обойтись без поддержания справочника в основной памяти. Основой метода является то, что для адресации блока внешней памяти всегда используются младшие биты значения хэш-функции. Если возникает потребность в расщеплении, то записи перераспределяются по блокам так, чтобы адресация осталась правильной.
|
19. Поиск подстроки в строке. Алгоритм грубой силы. Этот алгоритм заключается в проверке всех позиций текста с 0 по n - m на предмет совпадения с началом образца. Если совпадает - смотрим следующую букву и т.д.Алгоритм грубой силы не нуждается в предварительной обработке и дополнительном пространстве. Алгоритм Морриса-Пратта. Этот алгоритм появился в результате тщательного анализа алгоритма грубой силы. Размер сдвига образца можно увеличить, одновременно запомнив части текста, совпадающие с образцом. Это позволит избежать ненужных сравнений и, тем самым, резко увеличить скорость поиска. Рассмотрим сравнение на позиции i, где образец x[ 0, m - 1 ] сопоставляется с частью текста y[ i, i + m - 1 ]. Предположим, что первое несовпадение произошло между y[ i + j ] и x[ j ] , где 1 < j < m. Тогда y[ i, i + j - 1 ] = x[ 0, j - 1 ] = u и a = y[ i + j ] =/= x[ j ] = b. При сдвиге вполне можно ожидать, что префикс образца u сойдется с каким-нибудь суффиксом подслова текста u. Наиболее длинный такой префикс - граница u ( Он встречается на обоих концах u ). Это приводит нас к следующему алгоритму: пусть mp_next[ j ] - длина границы x[ 0, j - 1 ]. Тогда после сдвига мы можем возобновить сравнения с места y[ i + j ] и x[ j - mp_next[ j ] ] без потери возможного местонахождения образца. Таблица mp_next может быть вычислена за O( m ) перед самим поиском. Максимальное число сравнений на 1 символ – m. Алгоритм Кнута-Морриса-Пратта Аналогично при сдвиге вполне можно ожидать, что префикс образца u сойдется с каким-нибудь суффиксом подслова текста u. Если мы хотим избежать выявления другого несовпадения, буква, находящаяся за префиксом в образце должна отличаться от b. Наиболее длинный такой префикс v называется границей u ( он встречается по обоим сторонам u ). Это приводит к следующему алгоритму: пусть kmp_next[ j ] - длина длиннейшей границы x[ 0, j - 1 ], за которой следует символ c, отличающийся от x[ j ]. Тогда после сдвига мы можем возобновить сравнения между символами y[ i + j ] и x[ j - kmp_next[ j ] ] без возможной потери местонахождения образца. Алгоритм Боуера-Мура Состоит из след. шагов: Сначала строится таблица смещений для искомого образца. Далее совмещается начало строки и образца и начинается проверка последнего символа образца. Если он и соотв-й ему при наложении символ строки не совп-ет, то образец сдвигается относит-но строки на величину, полученную из таблица смещений. После чего снова проводится сравнение, если символы совпадают – проводится проверка предпосл. символа и .т.д. Если все мив строки совп. с симв образца, до поиск закончен, если нет – то образец сдвиг на 1 символ вправо и снова начинается проверка с посл-го символа. Величина сдвига в случае несовпадения последнего символа выч-ся так: сдвиг обр-ца должен быть минимальным, но таким, чтобы не пропустить вхождение образца в строку. Если данный символ строки встретился в образце, то образец смещается так, чтобы символ строки совпал с самым правым вхождением этого символа в образце. Если же образец вообще не содержит этого символа, то образец сдвигается на свою длину. Величина смещ-я для каждого символа образца зависит только от порядка символа в образце. Поэтому табл. смещений вычисляется заранее и хранится в одномерном массиве, где кажд сиволу алфавита соотв-ет смещ-е относит-но посл. символа образца.
21. Бинарные деревья, типовые функции при работе с бинарными деревьями Бинарные деревья: изображают растущими сверху вниз с корнями наверху. Отдельные ячейки наз-ют узлами (потомками). Узел имеющий дочерний узел наз-ся родителем, не имеющий– листом. У листа может быть только 1 родитель, и 1,2 или ни одного потомка. Узел слева называется левым потомком, справа – правым. Для каждой вершины дерева необходимо хранить значение ключа Key, а также указатели left, right, parent. Если потомка нет, то null. Типовые функции при работе с бинарным деревом: 1) Процедура поиска – на входе: искомый ключ k и указатель x на корень поддерева. Данная процедура возвращает указатель на вершину с ключом k, либо null если её нет. 1.) Пока х не равен NULL и k не равно Key[x] .2.) Начало .3.) Если k<Key[x] 4.) тогда x=left[x]. 5.).иначе x=right[x]. 6.) Конец . 7.) Вернуть х. 2) Минимум и максимум. Минимальный ключ в дереве поиска можно найти, пройдя по указателю left от корня. Процедура возвращает указатель на min Эл-т поддерева с корнем х. Минимум(х) 1.) Пока left[x] не равен Null. 2.) Начало. 3.) x=left[x ]. 4.) Конец. 5.) Вернуть x. Максимум – то же самое только right. 3) Следующий и предыдущий элементы. Процедура возвращает указатель на следующий за х элемент, или NULL, если этот эл-т последний в дереве. Получить след эл-т 1.) Если right[x]!=NULL 2.) тогда вернуть минимум(right[x]) 3.) y=p[x] 4.) пока y!=NULL и x= =right[x] 5.)Начало 6.) x=y 7.) y=p[y] 8.) вернуть y Если у вершины х есть правый сын, то возвращается минимальная вершина правого поддерева. Если это условие не выполняется, то х – есть правый сын своего отца и у него нет правого сына. В этом случае в цикле идём вверх по дереву пока текущий узел является правым сыном своего отца. Далее возвращаем ссылку на отца. После цикла текущий узел является левым сыном своего отца. Пред эл-т – то же самое, только вместо right left и вместо минимум – максимум. 4) Добавление. Процедура добавляет заданный эл-т в подходящее место дерева, сохраняя при этом упорядоченность. Параметром процедуры является указатель z на новую вершину, в которую помещается значение Key[z], left[z] = Null, right[z]=Null. В ходе работы процедура меняет дерево Т. начало 1.) y=NULL 2.) x=root[T] – корень бинарного дерева. 3.) Пока x!=Null. 4.) Начало 5.) y=x 6.) Если Key[z]<Key[x] 7.) Тогда x=left[x] 8.) Иначе x=right[x] 9.) Конец 10.) p[z]=y 11.) если y= =Null 12.) тогда root [T]=z 13.) Иначе если Key[z]<key[y] 14.) Тогда left[y]=z 15.) Иначеt right[y]=z 5) Удаление. Параметром этой процедуры является указатель на удаляемую вершину. При удалении возможны след. случаи: (1) Если у z нет детей, то для удаления z достаточно поместить Null в соответствующее поле его родителя. (2) Если есть один сын, то можно вырезать z ю соединив его ребёнка напрямую с родителем (3) Если детей двое, в этом случае требуется приготовление. Сначала находим следующий (в смысле порядка на ключах) за z элементy. И у него нет левого ребёнка. Теперь необходимо скопировать ключ и дополнить данные из вершины y в вершину z. Затем вершину y удалить. 1.) Если left[z]=Null или right[z]=Null 2.) Тогда y=z 3.) иначе y=ПолучитьСледующийЭлемент(z) 4.)если left[y]!=Null . 5.) тогда x=left[y] 6.) иначе x=right[y] 7.) если x!=Null 8.) тогда p[x]=p[y] 9.) если p[y]=Null 10.) тогда root[T]=x 11.) Иначе если y=left[p[y]] 12.) тогда left[p[y]]=x 13.) иначе right[p[y]]=x 14.) если y!=z 15.) тогда Key[z]=Key[y] 16.) Параллельно копируем дополнительные данные связанные с у 17.) Удалить
22. Сбалансированные деревья. Бинарное дерево называется идеально сбалансированным, если для каждой его вершины количество вершин в левом и правом поддереве различаются не более чем на 1. Алгоритм постр-я сбаланс. дер-ев формируется с помощью рекурсии. При этом необходимо учитывать, что для достижения мин высоты при заданном числе вершин необходимо расположить макс. возможное число вершин на всех уровнях кроме, самого нижнего. Это можно сделать, если располагать поступающие вершины поровну слева и справа от каждой вершины. Идеально сбалансированные деревья были изобретены для снижения времени работы алгоритмов, связанных с необходимостью частого прохда по ветвям деревьев, при формировании идеально сбал дереваключи необходимо вводить в отсортированном виде.Все операции для AVL деревьев идентичны операциям для бинарных деревьев, кроме методов вставки и удаления, которые должны отслеживать соотношение высот левого и правого поддеревьев узла. Для сохранения этой инфы вводится спец поле балансфактор (balance factor=height(right subtree)-height(left subtree)). BF<0, то узел перевешивает влево, т.к. высота левого поддерева больше высоты правого. При BF>0 узел перевешивает вправо .Показатель сбалансированности должен лежать в пределах ( -1, 1). Алгоритм АВЛ вставки. Осуществляется рекурсивный спуск по левому и правому сынам, пока не встретится пустое поддерево. Затем происходит пробная вставка нового узла в это поддерево. Обработка узлов ведётся в обратном порядке, т.к. процесс рекурсивный, при этом показатель сбалансированности родительского узла можно корректировать после изучения эффекта от добавления нового узла. Сущ-ет 3 возм-х ситуации. Случай 1: узел на поисковом маршруте изначально сбалансирован, т.е. БФ=0. После вставки в поддерево нового эл-та узел стал перевешивать вправо или влево, если эл-т вставлен в левое поддерево, то показатель сбалансированности = -1, если вправо, то 1. Случай 2: одно из поддеревьев узла перевешивает, и новый узел вставляется в более легкое поддерево, тогда узел становится сбалансированным. Случай 3: одно из поддеревьев узла перевешивает, а новый узел помещается в более тяжелое поддерево. Условие сбалансированности нарушается, т.к. БФ выходит за допустимые пределы. Для решения проблемы выполняется поворот. Высота сбалансированного дерева с n вершинами ограничивается значениями: log(n+1)<h<1. Ситуации, приводящие к разбалансировке дерева (два варианта):
|

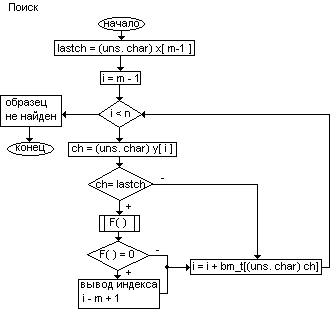 Используется
во всех текстовых редакторах. сравнение
образца с текстом начин. с последнего
символа образца. Перед началом поиска
строится таблица bm_t[j]
jый
элемент будет иметь значение= расстоянию
от конца образца до самого правого
вхождения в образец с символом j.
F()
осуществляет линейное сравнение
символа образца с инд.
Используется
во всех текстовых редакторах. сравнение
образца с текстом начин. с последнего
символа образца. Перед началом поиска
строится таблица bm_t[j]
jый
элемент будет иметь значение= расстоянию
от конца образца до самого правого
вхождения в образец с символом j.
F()
осуществляет линейное сравнение
символа образца с инд.