

2.2 Пример кластерного анализа
В качестве примера рассмотрим интересующую многих, пока в основном в западных странах, задачу о рынке ценных бумаг, в частности проблему оценки различных фондов, оперирующих этими бумагами.
Несмотря на неспокойность мирового рынка ценных бумаг, инвесторы сегодня вкладывают в него свои средства и имеют к нему повышенный интерес. Например, даже несмотря на то, что большинство фондов ценных бумаг в 1993 и 1994 годах функционировали без особого блеска, американцы в этот период вложили в них рекордное количество денег.
В рассматриваемом примере будут исследованы 16 известных инвестиционных фондов для оценки их состояния. В качестве переменных используются следующие характеристики (большинство из них описывается в условных единицах):
доходность за пятилетний период — переменная Five_Yr, риск — переменная Risk, ежегодный процент дохода (performance) (для каждого года) — Perf90, Perf91, Perf92, Perf93, Perf94, расходная часть — переменная Ехрепсе и налоговые рейтинги — переменная Tax. Ниже приводится таблица (табл. 2.12) с исходными данными по исследуемым фондам. В первом столбце указано наименование фонда, а в последнем — рекомендации экспертов по операциям с ценными бумагами этих
фондов. Данные заимствованы из руководства по применению STATGRAPHICS Plus for Windows.
Исследование приведенных данных состоит их трех частей. На первом этапе, излагаемом в настоящем разделе, будут изучаться многомерные группировки общественных фондов, полученные методами кластерного анализа STATGRAPHICS. Второй и третий этапы представлены в разделе «Практикумы» руководства по применению STATGRAPHICS Plus for Windows. При изложении второго этапа приводятся результаты построения линейных дискриминантных функций для разделения фондов на группы в соответствии с рекомендациями экспертов по операциям с ценными бумагами. Третья часть отведена задаче формирования базы знаний методами локальной геометрии для решения той же проблемы.
В ведем
приведенные данные в электронную таблицу
STATGRAPHICS и сохраним их в файле с именем
growth. Выберем Special > Multivariate
Methods > Cluster Analysis. Система отобразит
окно диалога для ввода данных в кластерный
анализ (рис. 2.53).
ведем
приведенные данные в электронную таблицу
STATGRAPHICS и сохраним их в файле с именем
growth. Выберем Special > Multivariate
Methods > Cluster Analysis. Система отобразит
окно диалога для ввода данных в кластерный
анализ (рис. 2.53).
Дважды щелкнем левой кнопкой мыши на переменных Expence, Five_Yr, Perf90, Perf91, Perf92, Perf93, Perf94, Risk и Tax для задействования их в анализе.
Введем характеристику Fund в поле Point Labels и оставим поле данных Select пустым. На рис. 2.53 показан пример заполнения окна диалога для ввода информации в кластерный анализ.
Н ажмем
ОК. Система выдаст окно с первичной
сводкой кластерного анализа.
ажмем
ОК. Система выдаст окно с первичной
сводкой кластерного анализа.
Так как в нашем случае желательно, чтобы кластерный алгоритм хорошо работал с небольшим количеством наблюдений (у нас их всего 16) и был нацелен на выделение кластеров с приблизительно равным числом членов, остановим свой выбор на методе Варда (Wards method).
Щелкнем правой кнопкой мыши — на экране появляется окно диалога для выбора параметров кластерного анализа.
Установим флажок Wards, а все остальные оставим в прежнем положении (рис. 2.54).
Нажмем 0 К; на экране отобразится сводка кластерного анализа для выбранного метода.
Нажмем кнопку для задания графических опций (третья слева в верхнем ряду окна анализа). Система предоставит специальное окно диалога.
Выберем отображение в виде дендрограммы (Dendrogram) и нажмем кнопку ОК. Система
добавит к

табличному окну графическое окно.
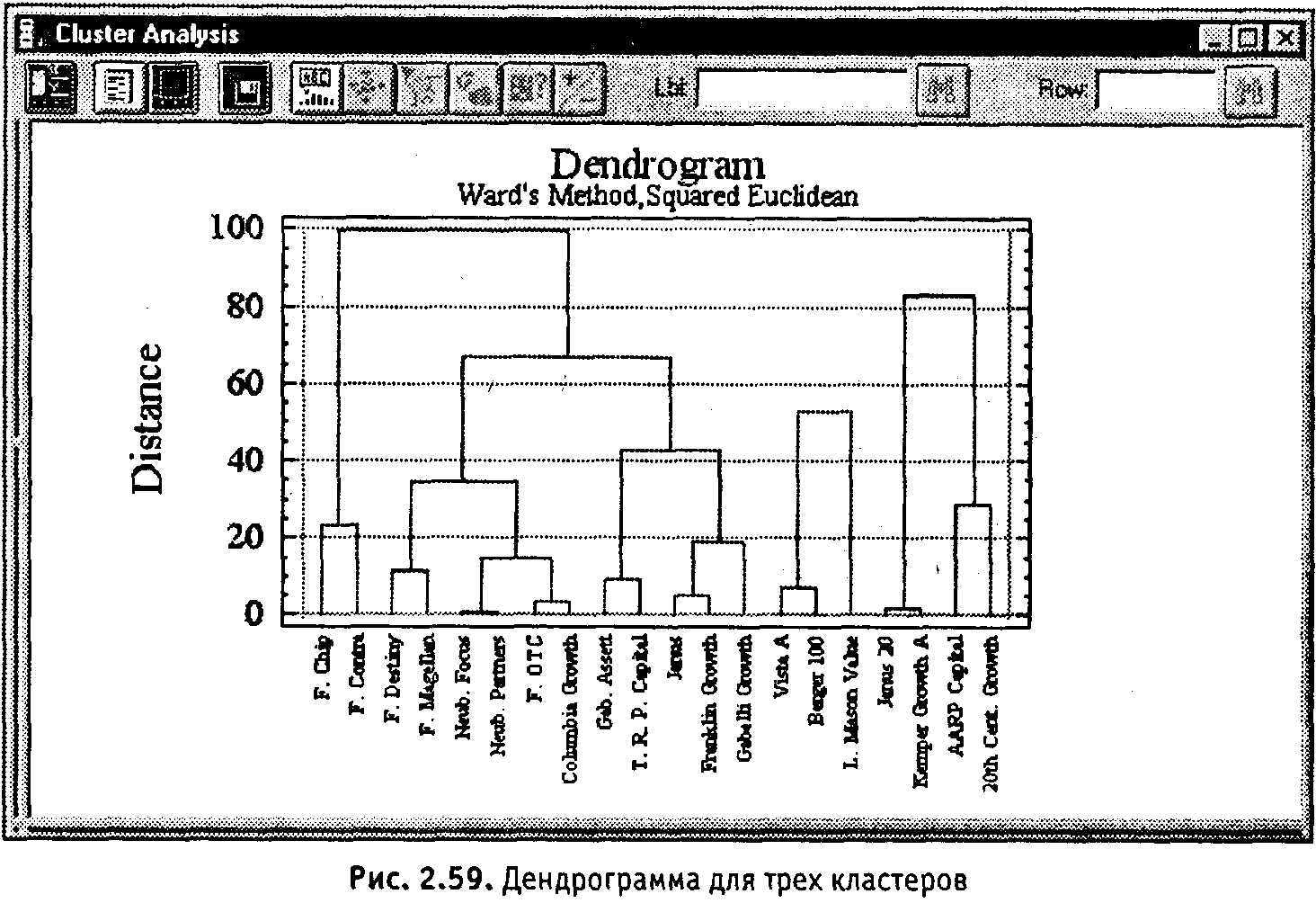
Дважды щелкнем на дендрограмме для максимального раскрытия окна (рис. 2.55).
Дендрограмма отображает иерархическую структуру группирования инвестиционных фондов. На ней отчетливо видны как минимум три группировки- одна заканчивается на фонде Gabelli Growth, вторая заканчивается на фонде Legg Mason Value и третья, достаточно плотная группировка, - на фонде 20th Century Growth. Отсюда следует, что для более подробного рассмотрения группировок следует задать их количество равным 3.
Дважды щелкнем на рисунке для минимизации размеров окна.
Щелкнем правой кнопкой мыши на окне сводки кластерного анализа — появит ся окно диалога для задания параметров проводимого исследования.
Изменим
количество кластеров (Number of Clusters) с 1 до
3.

Нажмем кнопку ОК. В соответствии с введенными изменениями будут произведены табличные преобразования (рис. 2.56 и 2.57).
В сводке кластерного анализа прежде всего указываются: имена переменных участвующих в анализе, количество полных образцов (наблюдений без пропусков), использованный метод кластерного анализа и принятая метрика. Затем в сводке описываются: число кластеров,, количество объектов в каждом кластере (населенность) и соответствующий процент населенности. Кроме того, в нижней части сводки приводится важная дополнительная информация.
Например, по координатам центроидов (рис. 2.57) можно судить о том, какие переменные играют наиболее важную роль в каждом кластере. В частности, в первом кластере видно, что расходы были разумными: несмотря на низкие доходы в 1990 году, заметно, что в другие годы состояние фондов 1-го кластера постоянно улучшалось. Также в первом кластере индицируется самый низкий рейтинг риска среди всех кластеров, а налоговые сборы были тоже достаточно невысокими.
Переменные, представляющие кластер 2, говорят о том, что здесь имелись наибольшие расходы, хотя за пятилетний период доходы оставались самыми высокими. Оценка риска и налоговые сборы являются максимальными среди всех кластеров,
Нажмем кнопку табличных опций (вторая слева в верхнем ряду). Система предоставит соответствующее окно диалога.
Установим Membership Table (таблица принадлежности наблюдений), затем нажмем кнопку ОК.
Дважды щелкнем левой кнопкой мыши на таблице населенности для максимального раскрытия окна.
В данной таблице описаны выбранные параметры кластерного анализа и затем дается полный список всех наблюдений, их имена и номера кластеров, в которые входят указанные наблюдения (рис. 2.58).
Создание двухмерной диаграммы рассеивания
Нажмем кнопку графических опций (третью слева в верхней части окна анализа). Появится окно диалога для задания соответствующих параметров.
Установим флажок 2D Scatterplot (двухмерная диаграмма рассеивания). Нажмем кнопку 0 К — система отобразит еще одно графическое окно.
Дважды щелкнем левой кнопкой мыши на окне дендрограммы, чтобы развернуть его.
На дендрограмме видны три дерева (рис. 2.59). По вертикальной оси отложено расстояние для каждого шага работы агломеративного иерархического алгоритма кластеризации. На горизонтальной оси показаны наблюдения, скомбинированные в соответствии с проведенным анализом. Дендрограмма позволяет увидеть отчетливую картину трех группировок и имена наблюдений (инвестиционных фондов), вошедших в выделенные кластеры.
Дважды щелкнем
на дендрограмме и тем самым вновь
минимизируем ее.
Дважды щелкнем левой кнопкой мыши на двухмерной диаграмме рассеивания (рис. 2.60).

Диаграмма показывает, как группируются исследуемые наблюдения на плоскости двух переменных Ехрепсе и Five_Yr (рис. 2.60). Каждый кластер представлен на диаграмме собственным символом, а если бы это было в цветном исполнении, то и цветом. Из графика следует, что первый кластер имеет низкие относительные расходы; видно, как распределены доходы фондов за пятилетний период. В кластере 2 наблюдаются самые высокие расходы, но и максимальные пятилетние доходы. В кластере 3 низкие расходы сопровождаются и невысокими пятилетними доходами.
Для того чтобы отобразить другие диаграммы рассеивания, достаточно щелкнуть правой кнопкой мыши и, получив в распоряжение соответствующее окно диалога, выбрать интересующие пары переменных.