

3 Помехоустойчивое кодирование. Шифрование
3.1 Корректирующие коды
Наличие
помех в линии передачи сигналов приводит
к тому, что при демодуляции принимаемого
сигнала с помехой демодулятор не всегда
верно угадывает значение очередного
m-ичного
символа, т.е. вместо истинного значения
 выдает другое значение
выдает другое значение
 ,
взятое из алфавита
,
взятое из алфавита
 .
В таком случае говорят, что в данном
символе произошла ошибка. Ошибки
возникают случайным образом, поэтому
нет гарантии того, что в принятом сигнале
они отсутствуют.
.
В таком случае говорят, что в данном
символе произошла ошибка. Ошибки
возникают случайным образом, поэтому
нет гарантии того, что в принятом сигнале
они отсутствуют.
В таких условиях дальнейшая обработка (декодирование) цифрового сигнала с выхода демодулятора основана на анализе взаимосвязи между символами в последовательности. Если декодер приходит к выводу, что такая последовательность символов в принципе не могла быть передана, то такое решение называется обнаружением ошибок. На данном этапе декодер не пытается выяснить, какие именно символы приняты ошибочно и каковы их истинные значения, важно лишь установить факт, что в принятой последовательности хотя бы один символ содержит ошибку. Таким образом, этап обнаружения ошибок завершается выдачей решения в двоичной форме: “нет ошибок”, “есть хотя бы одна ошибка”. Если принято первое решение, декодирование очередной принятой последовательности на этом фактически завершается.
Если в системе передачи информации отсутствует обратный канал, то есть, нет возможности сообщить в пункт передачи о принятом решении, декодер после обнаружения ошибок предпринимает попытку восстановить переданное сообщение. Если ему удалось угадать положение ошибочных символов и их истинные значения, считают, что произошло исправление ошибок.
Очевидно, что угадывание далеко не всегда завершается успехом, поэтому не все возможные сочетания ошибок могут быть исправлены и даже обнаружены. В итоге иногда на выходе декодера всё-таки будут появляться последовательности символов, содержащие ошибки. Поэтому основной задачей теории помехоустойчивого кодирования является поиск таких последовательностей символов, при использовании которых процент ошибочных комбинаций на выходе декодера был бы как можно ниже.
Итак, корректирующим называется такой код, использование которого даёт возможность в процессе приёма цифрового сигнала обнаруживать в нём наличие ошибок и, возможно, даже исправлять некоторые из ошибочных символов.
Среди корректирующих кодов наибольшее распространение получили блочные двоичные коды, то есть передача двоичного сообщения производится блоками, причём каждый блок содержит n двоичных символов. Кодирование и декодирование каждого блока производится независимо от других блоков.
Напомним,
что расстояние
Хэмминга
(1.43)
 между двумя кодовыми комбинациями a
и b
численно равно количеству символов, в
которых эти комбинации отличаются одна
от другой. Например, пусть n=5,
a=01101,
b=00001,
тогда
между двумя кодовыми комбинациями a
и b
численно равно количеству символов, в
которых эти комбинации отличаются одна
от другой. Например, пусть n=5,
a=01101,
b=00001,
тогда
 .
.
Вес комбинаций равен количеству единиц, содержащихся в ней. Например, W(a)=3, W(b)=1. Очевидно, что 0≤W≤n.
Расстояние Хэмминга удобно вычислять, пользуясь операцией суммирования по модулю 2
|
(3.1) |
В дальнейшем суммирование двоичных кодовых комбинаций или их элементов предполагается проводить лишь по mod 2, даже если используется обычный знак суммирования.
Вектор ошибки e – это n-разрядная двоичная комбинация, в которой положение единиц указывает на положение ошибочных символов в принятой комбинации y. Пусть при этом передана комбинация x , тогда
y=x+e. |
(3.2) |
Например, если n=6, x=0110110, e=010100, то y=001110.
Кратность ошибки q – это количество ошибочных символов в принятой комбинации
q=W(e)=W(x+y)= |
(3.3) |
причём 0≤q≤n.
Величина q случайна, в каналах с независимыми ошибками её математическое ожидание mq=pn, где p – вероятность появления ошибки в одном символе на выходе демодулятора (битовая вероятность ошибки). В реальных каналах связи отношение сигнал/помеха обычно настолько велико, что pn<<1. Это значит, что большинство комбинаций будут приняты без ошибок (q=0), изредка будут встречаться комбинации, содержащие где-то один ошибочный символ (q=1), ещё реже – комбинации с двукратными ошибками и т.д. То есть, принятая комбинация лежит недалеко от переданной.
Очевидно, что никакой код не способен обнаружить и исправить все возможные ошибки вплоть до q=n. Возможности любого кода ограничены, поэтому в первую очередь нужно направить усилия на борьбу с теми видами ошибок, которые встречаются наиболее часто, то есть с ошибками малых кратностей.
С пособ
кодирования полностью определён, если
задана кодовая
таблица,
в которой перечислены все возможные
сообщения и соответствующие им n-разрядные
кодовые комбинации. Например, если
каждая комбинация соответствует одной
букве алфавита, а в используемом алфавите
всего 4 буквы, кодовая таблица может
иметь следующий вид (табл.3.1).
пособ
кодирования полностью определён, если
задана кодовая
таблица,
в которой перечислены все возможные
сообщения и соответствующие им n-разрядные
кодовые комбинации. Например, если
каждая комбинация соответствует одной
букве алфавита, а в используемом алфавите
всего 4 буквы, кодовая таблица может
иметь следующий вид (табл.3.1).
|
(3.4) |
Можно вычислить расстояние djk между двумя любыми комбинациями в кодовой таблице. Минимальное его значение
называется
кодовым расстоянием и служит одной из
важнейших характеристик выбранного
способа кодирования. Это показатель
отличия двух наиболее близких комбинаций
в таблице. В приведённом примере
 ,
, ,…,
,…, ,
в итоге
,
в итоге
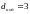 .
.
Довольно трудоёмкий, зато универсальный способ декодирования – это декодирование по минимуму расстояния. Принятая комбинация сравнивается поочерёдно со всеми комбинациями в таблице. Если такая комбинация есть в таблице, то декодирование заканчивается. Конечно, при этом нет полной уверенности в том, что в принятой комбинации отсутствуют ошибки, хотя это весьма вероятно. Просто здесь нет лучшего варианта, поскольку обычно равновозможна передача любой из комбинаций, входящих в таблицу.
В противном случае (принятая комбинация не совпадает ни с одной комбинацией в кодовой таблице) следует несомненный вывод: в принятой комбинации есть ошибка и, может быть, не одна (произошло обнаружение ошибок).
Логически рассуждая и рассматривая примеры, легко убедиться в том, что можно гарантированно обнаруживать любые ошибки кратности
|
(3.5) |
В приведённом примере (табл. 3.1) код обнаруживает все однократные и двукратные ошибки. Этот же код способен обнаруживать также некоторые ошибки более высоких кратностей, но не все. В частности, ошибки в первых трёх символах кодовой комбинации не будут замечены.
После обнаружения ошибок в СПИ с обратным каналом посылают запрос на повторную передачу данной комбинации. При отсутствии канала переспроса следует попытаться исправить ошибки, то есть найти в кодовой таблице комбинацию, наиболее близкую к той, которая была принята (наиболее правдоподобную). Даже если в таблице нашлась лишь одна такая комбинация, это ещё не служит гарантией того, что ошибки исправлены верно. Можно гарантированно исправить любые ошибки кратности
|
(3.6) |
Например,
код (табл. 3.1) способен исправить любую
однократную ошибку. Убедитесь на примерах
в том, что ресурсы кода используются
полнее, если
 является нечётным числом. Кроме того,
видно, что исправлять ошибки труднее,
нежели их обнаруживать. Разумеется,
возможны случаи, когда исправляются
некоторые ошибки более высоких кратностей,
чем следует из (3.6), но не все.
является нечётным числом. Кроме того,
видно, что исправлять ошибки труднее,
нежели их обнаруживать. Разумеется,
возможны случаи, когда исправляются
некоторые ошибки более высоких кратностей,
чем следует из (3.6), но не все.