

3.3.5. Предшествование более высокого порядка
E
E + T
T * F
(E)
E + T
Для этого дерева: +≐T и +⋖T; (≐E и (⋖E.
Чтобы решить проблему, введём новые правила:
E: = E1;
E1: = E1+T1|T1;
T1: = T.
Учитывая эти правила, можно нарисовать дерево:
E
|
E1
E1 + T1
|
T
T * F
|
(E)
|
E1
E1 + T1
Для этого дерева имеем следующие отношения: +≐T1 и +⋖T; (≐E и (⋖E1. Этот путь решения проблемы называется стратификация.
R, S, TÎ VN∪VT.
RS>∘ T – S является хвостом основы.(2.1 предшествование).
RS =>∘ T – T принадлежит основе. (2.1 предшествование).
R∘< ST – S является головой основы. (1.2 предшествование).
R∘<= ST – R принадлежит основе. (1.2 предшествование).
RS>∘ T тогда и только тогда, когда Z=>+…[R]UTx… =>+…RSTx… .
Чтобы получился этот вывод, нужно: U=>+…S или U=>+…RS.
RS =>∘ T тогда и только тогда, когда Z=>+…yUx => yRSTx .
Чтобы получился этот вывод, нужно: U: = RST.
R∘< ST тогда и только тогда, когда Z=>+…RUx =>+…RSTx… .
Чтобы получился этот вывод, нужно: U: = ST .
R∘<= ST тогда и только тогда, когда Z=>+…yUx =>…yRSTx… .
Чтобы получился этот вывод, нужно: U: = RST .
Если # S1 S2 … Si Sj … Sn # – сентенциальная форма, то основа этой сентенциальной формы будет цепочка Si … Sj , если для неё выполняется условие: Si-1∘< Si Si+1= >∘ Si+2 … Sj-1Sj >∘ Sj+1.
Предшествование m,n
W = xy |x| = m; |y| = n .
x ∘< y, если первый символ цепочки y является головой основы.
x >∘ y, если последний символ цепочки x является хвостом основы.
x ≗ y, , если последний символ цепочки x и первый символ цепочки y принадлежат основе.
Грамматика m,n предшествования это такая грамматика, которая удовлетворяет условиям:
Все правые части правил единственны.
Для любой пары цепочек xy таких, что |x| = m; |y| = n, выполняется не более одного из трех рассмотренных выше отношений.
3.3.6. Способ представления грамматики в оп
Одномерный массив
EE+T|T$TT*F|F$F(E)|а#, где
$ – символ, не принадлежащий грамматике, - разделитель между правилами;
# – конец массива;
| – промежуточный мета-символ.
Построение легкое, но работать с ним неудобно.
Имеет более удобную структуру двумерный массив.
Каждая вершина – это символ из правой части и содержит 4 компоненты:
Имя в некоторой внутренней форме.
Определение: 0, если терминал; в противном случае указывает на первый символ правой части первого правила. Предположение, что рассматриваемый находится в левой.
Альтернатива: указывает на первый символ правой части правила, который может быть использован вместо правила, где стоит рассматриваемый символ; 0 в противном случае.
Приемник: указывает на символ, который следует непосредственно за рассматриваемым, а если такового нет, то 0. Рассматриваются все символы для правой части.
Е |
||
Определение |
Альтернатива |
Приёмник |
E:=E<АОП>T|T;
T:=T<МОП>F|F;
F:=(E)|а;
АОП - аддитивный оператор: <АОП>:=+|-;
МОП - мультипликативный оператор: <МОП>:=*|/.
<АОП> |
||
|
0 |
|
Т |
||
|
0 |
0 |
+ |
||
0 |
|
0 |
- |
||
0 |
0 |
0 |
Т |
||
|
0 |
0 |
Т |
||
|
|
|
<МОП> |
||
|
0 |
|
F |
||
|
0 |
0 |
* |
||
0 |
|
0 |
/ |
||
0 |
0 |
0 |
F |
||
|
0 |
0 |
( |
||
0 |
|
|
E |
||
|
0 |
|
) |
||
0 |
0 |
0 |
а |
||
0 |
0 |
0 |













E |
||
|
|
|
Этим графом пользуется машина.
В итеративной форме: E:=T{+T}.
В НФБ: E:=E+T|E-T, в итеративной форме: E:=T{+T}.
Каждый нетерминальный выглядит как Е:
имя в некоторой внутренней форме;
о

Для правой части
пределение;альтернатива Т;
приёмник F;
каждому нетерминальному символу ставится в соответствие вершина графа, указывая на (первый символ), правую часть правила.
E:={<АОП>T}.
Для повторения АОП введём символ *- начало, **- конец цепочки.
G(z).
E:=E+T|T.
T:=T*F|F.
F:=(E)|а.
2)
E
1)
*
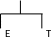

E |
|
|
|
T |
|
|
|
F |
|
|
|
(E) |
|
|
|
E+T |
|