

3.3.7. Предшествование более высокого порядка
Рассмотрим следующее дерево:
+
T
E
*
(E)
F
T
E+T
E
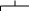
Для этого дерева существует следующие неоднозначности: +≐T и +⋖T; (≐E и (⋖E.
Для простого предшествования это не пригодно, поэтому для нашего случая необходимо ввести символ, чтобы Т не совпадали, то есть введем стратификацию.
Для решения проблемы введём новые правила:
E: = E1;
E1: = E1+T1|T1;
T1: = T.
Теперь, учитывая эти новые правила, можно нарисовать следующее дерево:
E1

E
T1
+
T
Т
*
F
(E)
E1
E1+T
В итоге для этого дерева имеем следующие отношения:
+≐T1 и +⋖T;
(≐E и (⋖E1.
Для первого дерева без замены Т и ввода новых правил получим
E+T*F;
+⋖T*;
(⋖E+.
Для того чтобы отличать предшествование 2.1 от операторного, внесём символ «∘» за знак < . Пусть у нас есть три символа R, S, T , которые принадлежат словарю алфавита.
Этот путь решения проблемы называется стратификация.
RS>∘ T – S является хвостом основы.(2.1 предшествование).
RS =>∘ T – T принадлежит основе. (2.1 предшествование).
R∘<ST – S является головой основы. (1.2 предшествование).
R∘<= ST – R принадлежит основе. (1.2 предшествование).
R, S, TÎ VN∪VT.
Выводы к определениям:
RS>∘T тогда и только тогда, когда имеется вывод Z=>+…[R]UTx…=> =>+…RSTx…
Для этого необходимы следующие выводы: U=>+…S или U=>+…RS.
RS =>∘T тогда и только тогда, когда Z=>+…[R]Ux =>...RSTx .
Чтобы получился этот вывод, нужно: U: = ST.
R∘< ST тогда и только тогда, когда Z=>+…RUТx =>+…RSTx… .
Чтобы получился этот вывод, нужно: U: = S .
R∘<= ST тогда и только тогда, когда Z=>+…UТx =>…RSTx… .
Чтобы получился этот вывод, нужно: U: = RS .
Если цепочка # S1 S2 … Si Sj … Sn # – сентенциальная форма, то основа этой сентенциальной формы будет цепочка Si … Sj , если для неё выполняется условие
Si-1∘< Si Si+1=>∘ Si+2 … Sj-1Sj >∘ Sj+1.
=>∘ этот символ означает, что мы ищем хвост основы.
∘<= этот символ означает, что ищем голову основы.
Si … Sj –основа.
# ∘<S # -условие, когда заканчивается поиск.
Может быть ситуация:
# Sj >∘ Sj+1 #;
# ∘<SiSj #;
# ∘<S #.
Если найден хвост, то можно просмотреть правила и сравнить правые части.
Алгоритм распознавания
Распознаватель использует единственную таблицу. Таблица содержит три столбца.
В первом столбце таблицы содержится содержимое стека в форме Tu, где Т - любой символ или ограничитель, а U-правая часть правила.
Второй столбец содержит соответствующие правые контексты (либо # - символ конца цепочки ).
В третьем столбце записан номер правила, которое использовано при редукции.
На каждом шаге работы распознаватель среди строк таблицы ищет ту, в которой содержимое первого столбца совпадает с верхней частью стека, а содержимое второго столбца совпадает с последним считанным символом.
Если такая строка найдена, осуществляется редукция в соответствии с правилом, номер которого указан в третьем столбце.
Если такой строки нет, то редукция невозможна.
Последний сканируемый символ помещается в стек, и сканируется следующий символ предложения.
Предшествование m: n
Грамматика m,n предшествования это такая грамматика, которая удовлетворяет условиям:
Все правые части правил единственны.
Для любой пары цепочек xy таких, что |x| = m; |y| = n, выполняется не более одного из трех рассмотренных ниже отношений.
W = xy |x| = m; |y| = n.
x ∘< y, если первый символ цепочки y является головой основы.
x >∘ y, если последний символ цепочки x является хвостом основы.
x ≗ y, , если последний символ цепочки x и первый символ цепочки y принадлежат основе.