

Кластерный анализ
Следующим этапом данного исследования является кластерный анализ. Задачей кластерного анализа является разбиение выбранных регионов (n=56) на сравнительно небольшое число групп (кластеров) на основе их естественной близости относительно значений переменных xi. При проведении кластерного анализа мы предполагаем, что геометрическая близость двух или нескольких точек в пространстве означает физическую близость соответствующих объектов, их однородность (в нашем случае - однородность регионов по показателям, влияющим на инвестиции в основные средства).
На первой стадии кластерного анализа необходимо определиться с оптимальным числом выделяемых кластеров. Для этого необходимо провести иерархическую кластеризацию – последовательное объединение объектов в кластеры до тех пор, пока не останется два больших кластера, объединяющиеся в один на максимальном расстоянии друг от друга. Результат иерархического анализа (вывод об оптимальном количестве кластеров) зависит от способа расчета расстояния между кластерами. Таким образом, протестируем различные методы и сделаем соответствующие выводы.
Метод «ближнего соседа»
Если расстояние между отдельными объектами мы рассчитываем единым способом – как простое евклидово расстояние – расстояние между кластерами вычисляется разными методами. Согласно методу «ближайшего соседа», расстояние между кластерами соответствует минимальному расстоянию между двумя объектами разных кластеров.
Анализ в пакете SPSS проходит следующим образом. Сначала рассчитывается матрица расстояний между всеми объектами, а затем, на основе матрицы расстояний, объекты последовательно объединяются в кластеры (для каждого шага матрица составляется заново). Шаги последовательного объединения представлены в таблице:
Таблица 25. Шаги агломерации. Метод «ближайшего соседа»
|
||||||
Этап |
Кластер объединен с |
Коэффициенты |
Этап первого появления кластера |
Следующий этап |
||
Кластер 1 |
Кластер 2 |
Кластер 1 |
Кластер 2 |
|||
1 |
7 |
8 |
,003 |
0 |
0 |
8 |
2 |
17 |
18 |
,004 |
0 |
0 |
18 |
3 |
3 |
4 |
,004 |
0 |
0 |
27 |
4 |
14 |
15 |
,005 |
0 |
0 |
10 |
5 |
22 |
23 |
,005 |
0 |
0 |
13 |
6 |
9 |
10 |
,005 |
0 |
0 |
14 |
7 |
11 |
12 |
,005 |
0 |
0 |
19 |
8 |
6 |
7 |
,006 |
0 |
1 |
14 |
9 |
34 |
35 |
,007 |
0 |
0 |
20 |
10 |
13 |
14 |
,007 |
0 |
4 |
11 |
11 |
13 |
16 |
,009 |
10 |
0 |
19 |
12 |
27 |
28 |
,010 |
0 |
0 |
22 |
13 |
21 |
22 |
,010 |
0 |
5 |
31 |
14 |
6 |
9 |
,010 |
8 |
6 |
24 |
15 |
45 |
46 |
,010 |
0 |
0 |
42 |
16 |
24 |
25 |
,011 |
0 |
0 |
33 |
17 |
39 |
40 |
,012 |
0 |
0 |
28 |
18 |
17 |
19 |
,012 |
2 |
0 |
26 |
19 |
11 |
13 |
,012 |
7 |
11 |
24 |
20 |
34 |
36 |
,012 |
9 |
0 |
35 |
21 |
42 |
43 |
,012 |
0 |
0 |
39 |
22 |
27 |
29 |
,013 |
12 |
0 |
25 |
23 |
37 |
38 |
,014 |
0 |
0 |
28 |
24 |
6 |
11 |
,014 |
14 |
19 |
32 |
25 |
26 |
27 |
,014 |
0 |
22 |
30 |
26 |
17 |
20 |
,014 |
18 |
0 |
31 |
27 |
2 |
3 |
,015 |
0 |
3 |
29 |
28 |
37 |
39 |
,015 |
23 |
17 |
43 |
29 |
2 |
5 |
,016 |
27 |
0 |
32 |
30 |
26 |
30 |
,017 |
25 |
0 |
33 |
31 |
17 |
21 |
,018 |
26 |
13 |
38 |
32 |
2 |
6 |
,018 |
29 |
24 |
36 |
33 |
24 |
26 |
,019 |
16 |
30 |
37 |
34 |
31 |
32 |
,019 |
0 |
0 |
37 |
35 |
33 |
34 |
,020 |
0 |
20 |
43 |
36 |
1 |
2 |
,021 |
0 |
32 |
38 |
37 |
24 |
31 |
,021 |
33 |
34 |
40 |
38 |
1 |
17 |
,022 |
36 |
31 |
40 |
39 |
41 |
42 |
,024 |
0 |
21 |
45 |
40 |
1 |
24 |
,025 |
38 |
37 |
44 |
41 |
49 |
50 |
,027 |
0 |
0 |
49 |
42 |
44 |
45 |
,030 |
0 |
15 |
45 |
43 |
33 |
37 |
,033 |
35 |
28 |
44 |
44 |
1 |
33 |
,034 |
40 |
43 |
46 |
45 |
41 |
44 |
,042 |
39 |
42 |
46 |
46 |
1 |
41 |
,052 |
44 |
45 |
47 |
47 |
1 |
47 |
,074 |
46 |
0 |
48 |
48 |
1 |
48 |
,101 |
47 |
0 |
49 |
49 |
1 |
49 |
,103 |
48 |
41 |
53 |
50 |
52 |
53 |
,126 |
0 |
0 |
51 |
51 |
51 |
52 |
,163 |
0 |
50 |
52 |
52 |
51 |
54 |
,198 |
51 |
0 |
53 |
53 |
1 |
51 |
,208 |
49 |
52 |
54 |
54 |
1 |
55 |
,583 |
53 |
0 |
55 |
55 |
1 |
56 |
1,072 |
54 |
0 |
0 |
Как видно из Таблицы 26, на первом этапе объединились элементы 7 и 8, т. к. расстояние между ними было минимальным – 0,003. Далее расстояние между объединенными объектами увеличивается. По таблице также можно сделать вывод об оптимальном числе кластеров. Для этого нужно посмотреть, после какого шага происходит резкий скачок в величине расстояния, и вычесть номер этой агломерации из числа исследуемых объектов. В нашем случае: (56-53)=3 – оптимальное число кластеров.

Рисунок 5. Дендрограмма. Метод "ближайшего соседа"
Аналогичный вывод об оптимальном количестве кластеров можно сделать и глядя на дендрограмму (Рис. 5): следует выделить 3 кластера, причем в первый кластер войдут объекты под номерами 1-54 (всего 54 объекта), а во второй и третий кластеры – по одному объекту (под номерами 55 и 56 соответственно). Данный результат говорит о том, что первые 54 региона относительно однородны по показателям, влияющим на инвестиции в основные средства, в то время как объекты под номерами 55 (Республика Дагестан) и 56 (Новосибирская область) значительно выделяются на общем фоне. Стоит заметить, что данные субъекты имеют самые большие объемы инвестиций в основные средства среди всех отобранных регионов. Этот факт еще раз доказывает высокую зависимость результирующей переменной (объема инвестиций) от выбранных независимых переменных.
Аналогичные рассуждения проводятся для других методов расчета расстояния между кластерами.
Метод «дальнего соседа»
Таблица 26. Шаги агломерации. Метод "дальнего соседа"
|
||||||
Этап |
Кластер объединен с |
Коэффициенты |
Этап первого появления кластера |
Следующий этап |
||
Кластер 1 |
Кластер 2 |
Кластер 1 |
Кластер 2 |
|||
1 |
7 |
8 |
,003 |
0 |
0 |
9 |
2 |
17 |
18 |
,004 |
0 |
0 |
26 |
3 |
3 |
4 |
,004 |
0 |
0 |
19 |
4 |
14 |
15 |
,005 |
0 |
0 |
12 |
5 |
22 |
23 |
,005 |
0 |
0 |
18 |
6 |
9 |
10 |
,005 |
0 |
0 |
24 |
7 |
11 |
12 |
,005 |
0 |
0 |
24 |
8 |
34 |
35 |
,007 |
0 |
0 |
22 |
9 |
6 |
7 |
,009 |
0 |
1 |
27 |
10 |
27 |
28 |
,010 |
0 |
0 |
25 |
11 |
45 |
46 |
,010 |
0 |
0 |
31 |
12 |
13 |
14 |
,011 |
0 |
4 |
21 |
13 |
24 |
25 |
,011 |
0 |
0 |
34 |
14 |
39 |
40 |
,012 |
0 |
0 |
30 |
15 |
42 |
43 |
,012 |
0 |
0 |
29 |
16 |
37 |
38 |
,014 |
0 |
0 |
30 |
17 |
19 |
20 |
,014 |
0 |
0 |
26 |
18 |
21 |
22 |
,014 |
0 |
5 |
34 |
19 |
2 |
3 |
,017 |
0 |
3 |
33 |
20 |
29 |
30 |
,017 |
0 |
0 |
35 |
21 |
13 |
16 |
,018 |
12 |
0 |
36 |
22 |
34 |
36 |
,018 |
8 |
0 |
32 |
23 |
31 |
32 |
,019 |
0 |
0 |
38 |
24 |
9 |
11 |
,021 |
6 |
7 |
36 |
25 |
26 |
27 |
,022 |
0 |
10 |
35 |
26 |
17 |
19 |
,026 |
2 |
17 |
39 |
27 |
5 |
6 |
,026 |
0 |
9 |
37 |
28 |
49 |
50 |
,027 |
0 |
0 |
46 |
29 |
41 |
42 |
,034 |
0 |
15 |
41 |
30 |
37 |
39 |
,035 |
16 |
14 |
44 |
31 |
44 |
45 |
,035 |
0 |
11 |
41 |
32 |
33 |
34 |
,037 |
0 |
22 |
38 |
33 |
1 |
2 |
,037 |
0 |
19 |
37 |
34 |
21 |
24 |
,042 |
18 |
13 |
39 |
35 |
26 |
29 |
,044 |
25 |
20 |
45 |
36 |
9 |
13 |
,046 |
24 |
21 |
42 |
37 |
1 |
5 |
,063 |
33 |
27 |
42 |
38 |
31 |
33 |
,077 |
23 |
32 |
44 |
39 |
17 |
21 |
,082 |
26 |
34 |
45 |
40 |
47 |
48 |
,101 |
0 |
0 |
46 |
41 |
41 |
44 |
,105 |
29 |
31 |
48 |
42 |
1 |
9 |
,117 |
37 |
36 |
49 |
43 |
52 |
53 |
,126 |
0 |
0 |
47 |
44 |
31 |
37 |
,134 |
38 |
30 |
48 |
45 |
17 |
26 |
,142 |
39 |
35 |
49 |
46 |
47 |
49 |
,187 |
40 |
28 |
51 |
47 |
51 |
52 |
,265 |
0 |
43 |
50 |
48 |
31 |
41 |
,269 |
44 |
41 |
51 |
49 |
1 |
17 |
,275 |
42 |
45 |
52 |
50 |
51 |
54 |
,439 |
47 |
0 |
53 |
51 |
31 |
47 |
,504 |
48 |
46 |
52 |
52 |
1 |
31 |
,794 |
49 |
51 |
55 |
53 |
51 |
55 |
,902 |
50 |
0 |
54 |
54 |
51 |
56 |
1,673 |
53 |
0 |
55 |
55 |
1 |
51 |
2,449 |
52 |
54 |
0 |
При методе «дальнего соседа» расстояние между кластерами рассчитывается как максимальное расстояние между двумя объектами в двух разных кластерах. Согласно Таблице 27, оптимальное число кластеров равно (56-53)=3.

Рисунок 6. Дендрограмма. Метод "дальнего соседа"
Согласно дендрограмме, оптимальным решением также будет выделение 3 кластеров: в первый кластер войдут регионы под номерами 1-50 (50 регионов), во второй – под номерами 51-55 (5 регионов), в третий – последний регион под номером 56.
Метод «центра тяжести»
При методе «центра тяжести» за расстояние между кластерами принимается евклидово расстояние между «центрами тяжести» кластеров – средними арифметическими их показателей xi.
При анализе таблицы шагов объединения (далее не будем приводить саму таблицу из-за ее громоздкости) выяснилось, что оптимальное количество кластеров равно (56-52)=4.
Далее рассмотрим дендрограмму:

Рисунок 7. Дендрограмма. Метод "центра тяжести"
На Рисунке 7 видно, что оптимальное число кластеров следующее: 1 кластер – 1-47 объекты; 2 кластер – 48-54 объекты (всего 6); 3 кластер – 55 объект; 4 кластер – 56 объект.
Принцип «средней связи»
В данном случае расстояние между кластерами равно среднему значению расстояний между всеми возможными парами наблюдений, причем одно наблюдение берется из одного кластера, а второе – соответственно, из другого.
Анализ таблицы шагов агломерации показал, что оптимальное количество кластеров равно (56-52)=4. Сравним этот вывод с выводом, полученным при анализе дендрограммы. На Рисунке 8 видно, что в 1 кластер войдут объекты под номерами 1-50, во 2 кластер – объекты 51-54 (4 объекта), в 3 кластер – 55 регион, в 4 кластер – 56 регион.

Рисунок 8. Дендрограмма. Метод "средней связи"
Метод «средней связи элементов разных кластеров и внутри групп»
В данном методе расстояние между кластерами рассчитывается на основании всех возможных пар наблюдений, принадлежащих обоим кластерам, причем учитываются также пары наблюдений, образующиеся внутри кластеров. В этом случае получаются интересные результаты. Оптимальное число кластеров равно 4: в первый кластер войдут 34 региона, во второй – 18 регионов, в третий – 3 региона (под номерами 52-54), а в 4 – один регион под номером 56.

Рисунок 9. Дендрограмма №5
На основании иерархического кластерного анализа, проведенного различными методами, можно сделать вывод, что оптимальное число кластеров равно 4.
Метод k-средних
Несмотря достоинства иерархического метода (можно отследить поэтапное объединение объектов в кластеры), при большом количестве объектов проводить данный анализ весьма сложно. Поэтому в случае, когда число объектов n велико, применяют метод k-средних. Идея этого метода состоит в том, чтобы разбить анализируемое множество объектов n на заранее известное число кластеров k, причем данное разбиение должно минимизировать функционал качества – сумму внутриклассовых дисперсий:
![]()
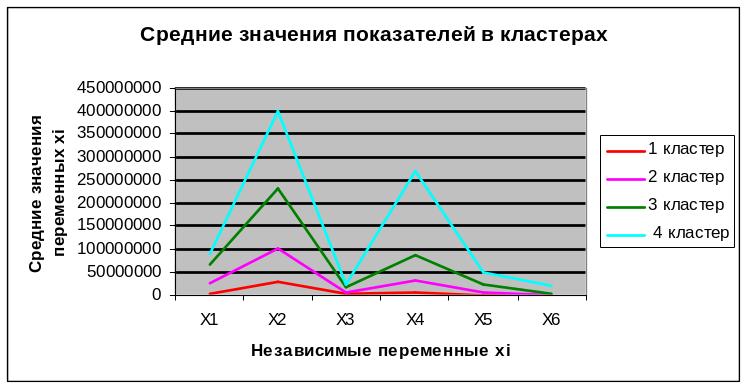
При помощи пакета SPSS рассчитаем значения средних показателей в кластерах:
Таблица 27. Конечные центры кластеров
|
Кластер |
|||
|
1 |
2 |
3 |
4 |
X1 |
4195240 |
25034440 |
68079262 |
89474435 |
X2 |
29617943 |
103000000 |
233000000 |
400000000 |
X3 |
2070030 |
7251361 |
17833344 |
24428385 |
X4 |
5397553 |
31181165 |
86732878 |
271000000 |
X5 |
737058 |
5586734 |
23933823 |
49465146 |
X6 |
148188 |
983240 |
2935974 |
21539977 |
На основании Рисунка 10 можно сделать вывод, что 1 кластер характеризуется самыми низкими средними значениями показателей xi, в то время как 4 кластер – самыми высокими средними значениями соответствующих показателей. Таким образом, чем выше номер кластера, тем выше средние значения показателей xi.
Рисунок 10. Средние значения показателей в кластерах
В следующей таблице представлены регионы, входящие в каждый кластер:
Таблица 28. Распределение регионов по кластерам
1 кластер (32 региона) |
2 кластер (19 регионов) |
3 кластер (4 региона) |
4 кластер (1 регион) |
Чукотский авт. округ |
Смоленская область |
Оренбургская область |
Республика Дагестан |
Республика Тыва |
Владимирская область |
Иркутская область |
|
Республика Калмыкия |
Тамбовская область |
Республика Коми |
|
Республика Алтай |
Калининградская область |
Новосибирская область |
|
Республика Адыгея |
Алтайский край |
|
|
Костромская область |
Астраханская область |
|
|
Магаданская область |
Вологодская область |
|
|
Респ. Северная Осетия |
Ярославская область |
|
|
Кабардино-Балкарская респ. |
Тульская область |
|
|
Псковская область |
Омская область |
|
|
Еврейская авт. область |
Калужская область |
|
|
Республика Хакасия |
Волгоградская область |
|
|
Орловская область |
Томская область |
|
|
Республика Марий Эл |
Саратовская область |
|
|
Республика Карелия |
Архангельская область |
|
|
Курганская область |
Амурская область |
|
|
Ивановская область |
Тверская область |
|
|
Камчатский край |
Белгородская область |
|
|
Республика Бурятия |
Липецкая область |
|
|
Кировская область |
|
|
|
Мурманская область |
|
|
|
Рязанская область |
|
|
|
Республика Мордовия |
|
|
|
Ненецкий авт. Округ |
|
|
|
Новгородская область |
|
|
|
Брянская область |
|
|
|
Забайкальский край |
|
|
|
Удмуртская республика |
|
|
|
Чувашская республика |
|
|
|
Курская область |
|
|
|
Ульяновская область |
|
|
|
Пензенская область |
|
|
|
Регионы, входящие в состав 1 кластера, характеризуются самыми низкими средними значениями всех показателей xi, и далее чем выше номер кластера – тем выше средние значения соответствующие значения показателей. Интересно, что аналогичная картина вырисовывается и при распределении данных регионов по среднему уровню инвестиций в основные средства: чем выше номер кластера, тем выше средний уровень инвестиций в основные средства (результирующий показатель Y):
Таблица 29. Среднее значение объема инвестиций в основные средства (переменная Y)
1 кластер (32 региона) |
2 кластер (19 регионов) |
3 кластер (4 региона) |
4 кластер (1 регион) |
26432 |
67628 |
102335 |
115106 |
Таким образом, деление регионов на кластеры, однородные по средним значениям независимых переменных, соответствует группировке этих регионов по среднему значению результирующей переменной. Следовательно, объем инвестиций в основные средства действительно тесно зависит от переменных xi.
Важной целью кластерного анализа является минимизация расстояния между объектами, находящимися в пределах одного кластера, и максимизация расстояния между кластерами. В этой связи рассмотрим следующую таблицу:
Таблица 30. Межгрупповая дисперсия
|
|||||
Кластер |
1 |
2 |
3 |
4 |
|
|
1 |
0 |
229485075 |
80722999 |
467540086 |
2 |
229485075 |
0 |
149003554 |
252258277 |
|
3 |
80722999 |
149003554 |
0 |
390909592 |
|
4 |
467540086 |
252258277 |
390909592 |
0 |
|
Из Таблицы 31 видно, что расстояние между кластерами очень велико, причем расстояние между 1 и 2 кластером намного меньше, чем расстояние, скажем, между 1 и 3 и тем более 1 и 4 кластерами. Учитывая предыдущие размышления о характере объектов, попавших в каждый кластер (об средних значениях показателей xi), этот результат представляется весьма логичным.
Поскольку анализ проводился на основании 6 независимых переменных, наглядно представить его результаты при помощи графиков – достаточно сложная задача. Скорее всего, на многомерном графике сложилась бы следующая картина: объекты, находящиеся в одном кластере, образовали бы «облако» точек, элементы которого находятся на достаточно близком расстоянии друг от друга. Вместе с тем, отдельные «облака» находились бы на большом друг от друга расстоянии. По крайней мере, такая «картинка» представляется автору работы крайне желательной.
Итак, в результате кластерного анализа были выделены 4 кластера и охарактеризованы особенности такой классификации. Далее перейдем к дискриминантному.