

32. Внутренние структуры данных. Двухуровневая система доступа к данным. Отношения каталогов.
Под данными обычно понимают любой набор знаков, рассматриваемый безотносительно к его содержательному смыслу. С точки зрения программирования данные можно рассматривать как совокупность некоторых информационных единиц (элементов), между которыми существуют определенные отношения. Эти отношения представляют собой структуру данных. Внутренние структуры данных используются для отображения абстрактных структур данных на физическую (линейную) память машины. Обычно внутренние структуры данных надстраиваются над базовой структурой памяти машины путем использования соответствующих программных средств. Каждая внутренняя структура данных строится из неделимых (с точки зрения структуры) частей, называемых элементами. Элемент может иметь несколько полей, часть из которых может использоваться для определения структуры. В качестве внутренних структур данных используются векторы, списки и сети. В каждом конкретном случае внутренняя структура выбирается с таким расчетом, чтобы быть эквивалентной используемой абстрактном структуре данных или, по крайней мере, допускать простое отображение этой абстрактной структуры.
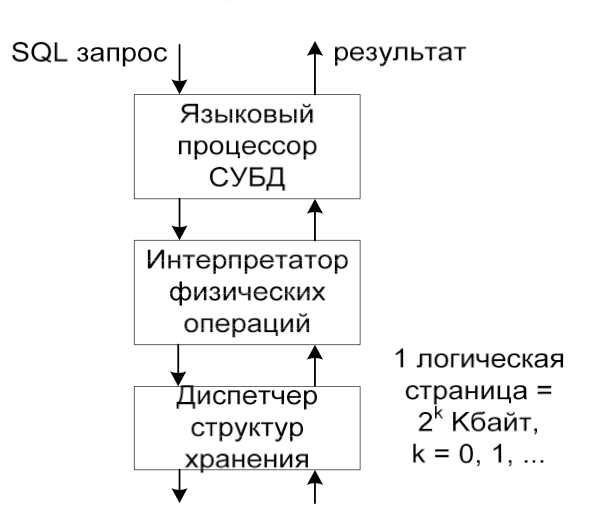
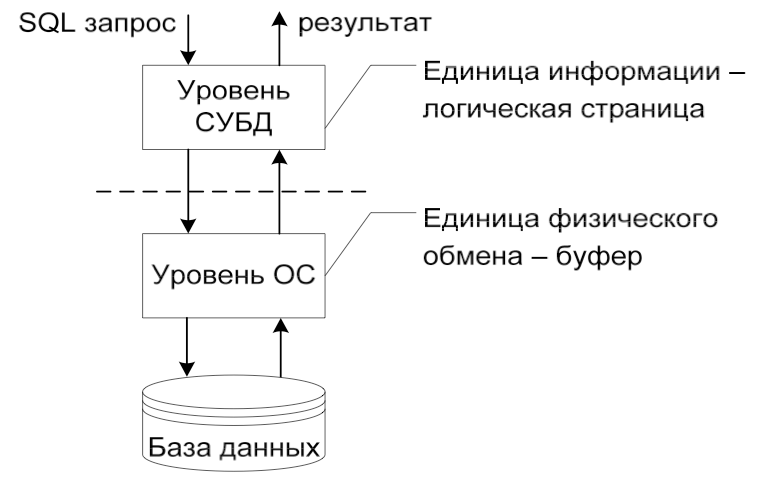
Внутренние
структуры хранения: Наличие
двух уровней системы для организации
доступа к данным; Поддержка отношений
- каталогов; Регулярность структуры
данных. Каталог
базы данных или словарь данных
содержит информацию, связанную с
объектами базы данных (имена, свойства
и т.п.). Основным
принципом организации баз данных
является совместное хранение данных и
их описания.
Описание данных называют метаданными.
Метаданные
хранятся в части базы данных, которая
называется каталогом или словарём-справочником
данных (ССД). Зная формат метаданных,
можно запрашивать и изменять данные
без написания дополнительных программ.
Строка
отношения (строка таблицы)
- основная часть базы данных, большей
частью непосредственно видимая
пользователем; Индексы–объекты,
создаваемые по инициативе пользователя
или верхнего уровня системы из соображений
повышения эффективности выполнения
запросов; Управляющая
(служебная) информация,
поддерживаемая для удовлетворения
внутренних потребностей нижнего уровня
системы (например, информация о свободной
памяти).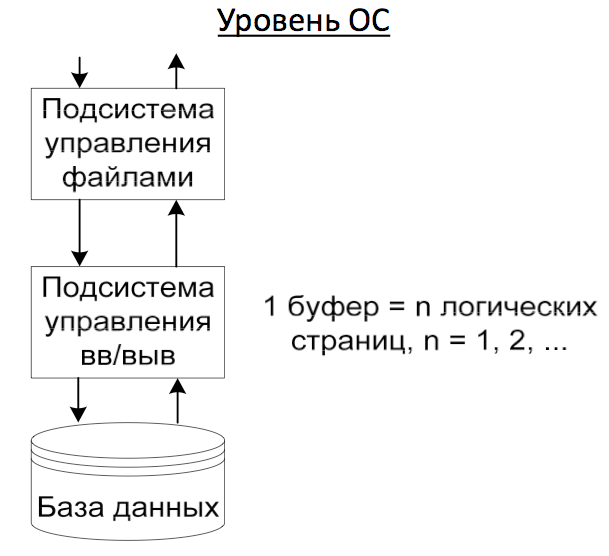
33. Методы доступа к данным. Бинарные деревья.
• Последовательный метод доступа: для получения целевой записи – обращение ко всем предшествующим цели записям
• Произвольный метод доступа: для получения целевой записи – непосредственное обращение к ней
Бинарное дерево поиска на множестве NR ключей есть бинарное дерево TNR, в котором каждая вершина помечена отдельным ключом и расположена в соответствии с определенным порядком ключей. Для любой вершины i ключи вершин в его левом поддереве «меньше» ключа вершины i, который, в свою очередь, «меньше» ключей вершин в его правом поддереве
Упорядоченная тройка (TL, R, TR)
R – корень дерева
TL, TR – левое и правое поддеревья корня R;
NL, NR – количество узлов в поддеревьях,
NL≥ 0, NR≥ 0
Общее количество узлов в дереве
NQ = NL + NR + 1
• Значение узла – ключ и некоторая запись RowId
• Левый и правый указатели на поддеревья
Длина поиска – длина пути от корня до целевой записи
•
1.
Уровень вершины или листа i, обозначаемый
Li, определяется длиной пути от корневой
вершины TNR до вершины i. Корневая вершина,
по определению, имеет уровень 0.
• 2. Высота дерева определяется как максимальный уровень среди всех вершин дерева.
• 3. Бинарное дерево называется сбалансированным, если разница уровней любых двух листьев не превышает 1.