

42. Индекс на основе битовых карт. Основные свойства.
Индексы на основе битовых карт (bitmapped indexes) разработаны для ответов на запросы, которые затрагивают столбцы с небольшим числом возможных значений, каждое из которых потенциально соответствует большому числу строк. Число возможных значений для столбца называется кардинальностью (cardinality). В отличие от иерархических индексов, хранящих указатели на строки, используя идентификаторы строк (rowids), индекс на основе битовых карт хранит для каждого возможного значения столбца битовую карту. Основные свойства:
Низкая кардинальность значений колонок. В зависимости от объема данных, процент уникальных значений равный 1%, является хорошим показателем для использования BITMAP индекса
Возможность хранения NULL-значений в рамках одно колоночного индекса. В отличии от B+дерева
Максимум 30 колонок в индексеBITMAP-индекс
№ строки
№ сотрудника
Фамилия
Пол
Пол/М
Пол/Ж
1
107
Петрова
Ж
0
1
2
108
Иванова
Ж
0
1
3
109
Петров
М
1
0
4
110
Иванов
М
1
0
5
111
Кузнецов
М
1
0
Может быть функциональным
|
|
|
|
Составной BITMAP-индекс | |||||
|
№ строки |
№ сотрудника |
Фамилия |
Пол/М |
Пол/Ж |
Город/ Москва |
Город/ Уфа |
Город/ Рязань |
Город/ Иркутск |
|
1 |
107 |
Петрова |
0 |
1 |
1 |
0 |
0 |
0 |
|
2 |
108 |
Иванова |
0 |
1 |
0 |
1 |
0 |
0 |
|
3 |
109 |
Петров |
1 |
0 |
1 |
0 |
0 |
0 |
|
4 |
110 |
Иванов |
1 |
0 |
0 |
0 |
1 |
0 |
|
5 |
111 |
Кузнецов |
1 |
0 |
0 |
1 |
0 |
0 |
Индексы на основе битовых карт по двум столбцам таблицы можно эффективно комбинировать, используя булевы операторы AND и OR. Это позволяет использовать их в запросах с множественными условиями, затрагивающими индексированные данным индексом столбцы таблицы. Это дает то преимущество, что вы можете отвечать на очень разнообразные запросы с помощью всего нескольких одностолбцовых индексов на основе битовых карт. Например, предположим, что у нас есть таблица сотрудников, которая содержит имя сотрудника, пол и город (Москва, Уфа, Рязань, Иркутск, и т. п.). Мы хотим получить информацию о женщинах сотрудниках в городе Москва ( SELECT * FROM employee WHERE sex = ‘Ж’ AND city = ‘Москва’)
Структура листового блока. В индексе на основе битовых карт каждая запись состоит из набора флагов, байта блокировки и (в данном случае) четырех строк данных. Эти четыре строки, на самом деле:
row#0[8013] flag: -----, lock: 0
col 0; len 2; (2): c1 03
col 1; len 6; (6): 01 00 01 82 00 00
col 2; len 6; (6): 01 00 01 83 00 07
col 3; len 3; (3): 00 с2 44
проиндексированное значение,
2 строки идентификаторов строк задают непрерывную часть таблицы
поток битов говорит, какие строки в этом диапазоне идентификаторов строк содержат соответствующие значение

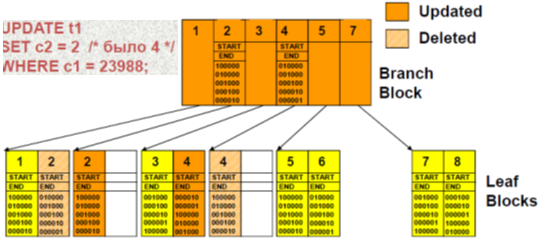
Операция обновления выполняется через удаление и последующую вставку:
Удаляется старое значение из части битовой карты
Добавляется новое значение части битовой карты
Как минимум 2 части битовой карты вовлечены в процесс каждого обновления
Когда bitmap индексы обновляются:
Должно быть достаточно места в блоке для старых и новых значений
В противном случае блок делится
Что приводит к длинным рядам промежуточных блоков
Когда
bitmap индекс обновляется, устанавливается
блокировка на запись листового блока
Обновляемая запись в листовом блоке
может содержать битовую карту, которая
охватывает несколько строк в других
блоках. Ни одна другая транзакция не
может обновлять строку, вовлеченную в
процесс обновления другой строкой до
завершения транзакции
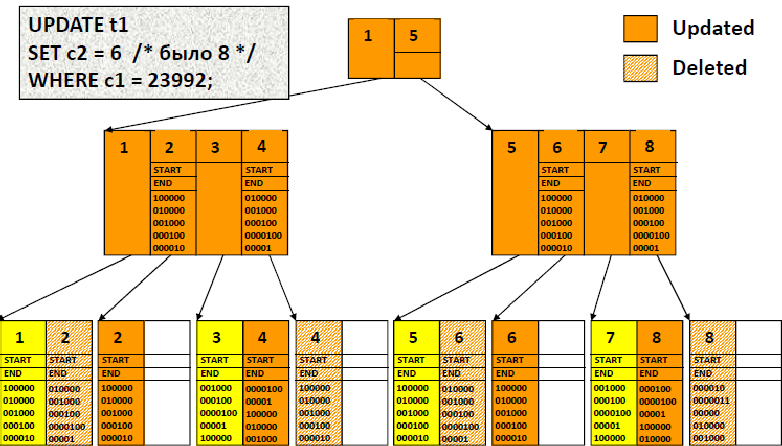
Когда bitmap индекс обновляется:
Удаляемая строка остается до завершения транзакции
Новая строка записывается в свободное пространство листового блока
Если нет свободного места в текущем блоке, используется новый блок
Элементы в листовых блоках упорядочены
Если обновляется последняя битовая карта в блоке, блок делится
Промежуточные блоки указывают на начало дочерних или листовых блоков
Если изменения касаются конца битовой карты, битовая карта может быть скопирована в промежуточный блок
Пример деления листовых блоков: 8 уникальных значений – разделены на 3000 строк

Выводы
Индекс на основе битовых карт создается достаточно быстро и занимает мало места
Размер и BITMAP индекса существенно зависит от распределения данных
Стоимостной оптимизатор обычно выбирает Bitmap индекс, если можно использовать несколько таких индексов
Операции вставки и удаления столбцов, входящих в состав Bitmap индексов, могут вызывать существенные конфликты и блокировки