

6. Пример вычислительного кластера
Вычислительный кластер разработан специалистами УГАТУ совместно с компаниями АйТи и IBM в рамках приоритетного национальногопроекта "Образование".
Технические характеристики:
|
Тип вычислительных узлов: |
IBM BladeCenter HS21 |
|
Число вычислительных узлов/процессоров/ядер: |
266/532/2128 |
|
Тип процессора: |
Intel Quad Xeon 5300 |
|
Оперативная память: |
RAM 2128 Gb |
|
Дисковая память: |
RAID50 2 Tb |
|
Тип вычислительной сети: |
Infiniband |
|
Тип управляющей сети: |
Gigabit Ethernet |
|
Операционная система: |
Red Hat Enterprise Linux 4 |
|
Пиковая производительность: |
19.8 TFlop |
|
Производительность на тесте LINPACK: |
15.3 TFlop |

Проводимые исследования
УГАТУ совместно с различными организациями проводит исследования с применением суперкомпьютерных технологий:
ООО «РН-УфаНИПИнефть» - моделирование фильтрационных течений в пластах нефтегазовых месторождений - моделирование многофазных течений в задачах совместной транспортировки нефти и газа;
ОАО «Уфимское моторостроительное производственное объединение» - моделирование технологических процессов изготовления узлов и деталей авиационных двигателей 5-го поколения;
Институт механики УНЦ РАН - моделирование течений в пористых средах.
Области применения суперкомпьютера:
Моделирование газодинамических течений в камерах сгорания и других элементах проточной части ГТД.
Моделирование многофазных течений в аппаратах химических технологий.
Моделирование гидродинамических процессов в нефтяных пластах.

7. Заключение. Стоит ли использовать кластер
Прежде чем перейти к практической реализации кластерной технологии необходимо решить для себя несколько принципиальных вопросов.
Первый из них звучит так: "Необходим ли для решения моих задач кластер и параллельные вычисления?" Чтобы ответить на этот вопрос надо внимательно присмотреться к решаемым вами задачам. Параллельные вычисления - достаточно специфичная область математики и далеко не всегда параллельные вычисления могут быть вами применимы. Кластер вам скорее всего не нужен, если:
Вы используете специализированные пакеты программ, которые не адаптированы для параллельных вычесление в средах MPI и PVM или не предназначенные для работы в UNIX. В этом случае вы просто не сможете задействовать долее одного процессора для выполнения задачи или вообще запустить вашу программу в чужой операционной среде.
Программы, написанные вами для решения ваших задач, требуют не более нескольких часов процессорного времени на имеющемся оборудовании. Может случиться так, что время, потраченное вами на распараллеливание и отладку вашей задачи съест все преимущество в быстродействии, которое даст многопроцессорная обработка.
Время жизни вашей программы сравнимо со временем ее разработки в параллельном варианте. Основными особенностями модели параллельного программирования являются высокая эффективность программ, применение специальных приемов программирования и, как следствие, более высокая трудоемкость программирования. Не имеет смысла тратить время на распараллеливание программы, которая будет считаться несколько часов один раз в жизни, после чего, получив результаты, вы про нее забудете.
Приложение в параллельной архитектуре должно создаваться с расчетом на эффективное использование ресурсов этой архитектуры. Под этим понимается то, что приложение должно быть разделено на части, способные исполняться параллельно на нескольких процессорах, и разделено эффективно, чтобы отдельно исполняемые куски программы минимально влияли на исполнение остальных частей.
Предположим, что в вашей программе доля операций, которые нужно выполнять последовательно, равна f, где 0<=f<=1 (при этом доля понимается не по статическому числу строк кода, а по числу операций в процессе выполнения). Крайние случаи в значениях f соответствуют полностью параллельным (f=0) и полностью последовательным (f=1) программам. Так вот, для того, чтобы оценить, какое ускорение S может быть получено на компьютере из p процессоров при данном значении f, можно воспользоваться законом Амдала:
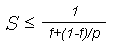
Выводы:
Можно собрать кластерную систему хоть из 10 тысяч узлов, но если не обеспечить достаточной скорости обмена данными, то производительность оставит желать лучшего
Программирование для кластеров - весьма трудоемкая задача, и если есть возможность обойтись сервером с многопроцессорной архитектурой с эквивалентной производительностью, то так и предпочитают делать
Адаптирование решаемой задачи (распараллеливание)
Лекция 6. Язык разметки XML
XML1 вовсе не предназначался для использования в разработке приложений — во всяком случае, изначально. Ни один из ранних стандартов —XML 1.0, XPath, Extensible Stylesheet Language Transformation (XSLT), Namespaces in XML, Extensible Hypertext Markup Language (XHTML), DOM— не был ориентирован на нужды разработчиков. Если бы XML создавался для разработки ПО, он бы поддерживал списки, карты и типы данных — к чему, в конце концов, пришел JSON. Нет, XML предназначался для публикации; говоря конкретно, для публикации Web-страниц.
XML явился порождением на 20 лет более давней технологии, носившей название SGML. Приблизительно в то же время Кодд работал в IBM® над вопросом о том, как структурировать данные, разбив их на неупорядоченные фрагменты малого размера; Чарлз Голдфарб, Эдвард Мошер и Раймонд Лори, также в IBM, пытались решить задачу о структурировании больших упорядоченных документов, которые не могут иметь смысла в виде таблиц. Кодд работал над бизнес-данными наподобие инвентарных списков и документов финансового учета. Голдфарб, Мошер и Лори имели дело с такими документами, как ежегодные отчеты и авиационные технические руководства.
SGML предназначался для решения издательских задач: как составлять, хранить, обновлять, распечатывать, читать и находить нужную информацию в документах, которые могут занимать десятки тысяч страниц и предполагают использование самых разных платформ, процессоров, таблиц символов, естественных языков, операционных систем и компаний. С помощью SGML удалось достичь некоторого успеха в отношении правительственных и военных организаций, испытывавших такого рода потребности, а также небольшого количества технических издательств, в частности, O'Reilly, которым волею случая удалось воспользоваться плодами этой работы. Говоря же в общем, с точки зрения потребностей большинства людей — даже тех, кто занят в издательской сфере — SGML был чересчур сложен и громоздок.
Самая большая удача SGML стала и наибольшим его провалом. Речь идет об HTML. HTML задумывался как SGML-приложение, но почти никто из тех, кто занимался написанием браузеров, редакторов и Web-страниц, не знал о SGML ничего, кроме того, как расшифровывается эта аббревиатура (а многие не знали даже и этого). Само собой, возникали расширения языка, которые быстро свели на нет все возможные притязания на согласованность HTML с SGML. Даже существовавшие в то время немногочисленные и дорогостоящие SGML-средства не могли справиться с изысками живого языка HTML, характерного для Web образца примерно 1996 года.
Именно для исправления этого положения вещей и был придуман XML. С одной стороны, он должен был упростить SGML2, приведя его к единой разумной, стандартной разновидности, которую все приняли бы и добросовестно держались бы в ее рамках. Расчет был на то, что такая упрощенная спецификация может получить более широкое распространение, чем это удалось почившему SGML. В этом отношении XML по большей части преуспел.
С другой стороны, ожидалось, что XML станет фундаментом для стройного и логичного Web, с гораздо меньшим количеством межбраузерных несовместимостей и противоречий. В этом отношении XML по большей части потерпел неудачу. XML и XHTML только лишь явились источником еще одного диалекта HTML, который необходимо было поддерживать браузерам, и нисколько не приблизились к тому, чтобы предложить альтернативу теговой каше.
Плохой ли, хороший ли, XML так или иначе предназначался для решения задач публикации: книг, руководств пользователя, и прежде всего — Web-страниц. Он не был оптимизирован и не планировался для использования в задачах разработки ПО, помимо издательских. Никто не предвидел и не рассчитывал, что XML будет применяться для конфигурационных файлов, процедурных вызовов, сериализации объектов, дампов баз данных и тому подобных задач, связанных с разработкой, поэтому не стоит удивляться, что он не всегда идеально для них подходит. И все же XML смог предложить разработчикам то, чего у них не было прежде — платформенно-независимый, не привязанный к языку, международно признанный формат данных с целым рядом высококачественных, бесплатных и легкодоступных парсеров. Благодаря такому неотразимому сочетанию программисты смогли легко пережить отсутствие таких типов данных, как int и float, а также таких фундаментальных структур, как списки и таблицы.
Но поскольку XML предназначался вовсе не для этого, его и нельзя судить по таким критериям; точно так же вовсе не здесь нужно искать его наиболее сильные стороны и будущие перспективы. Чтобы отыскать их, нам нужно вернуться в ту область, для которой XML создавался — в издательскую сферу; в частности, в сферу Web-публикаций. В опубликовании на Web участвуют три действующих лица:
Автор
Публикатор
Читатель
Инструмент читателя на сегодня полностью готов. Это браузер. Все основные браузеры поддерживают теперь XML. А вот что касается средств написания и опубликования, а также обеспечения связи между ними, то здесь все только начинается.