

1. Причинность, регрессия, корреляция
Для количественного описания взаимосвязей между экономическими переменными в статистике используют методы регрессии и корреляции.
Регрессия - величина, выражающая зависимость среднего значения случайной величины у от значений случайной величины х.
Уравнение регрессии выражает среднюю величину одного признака как функцию другого.
Функция регрессии - это модель вида у = л», где у - зависимая переменная (результативный признак); х - независимая, или объясняющая, переменная (признак-фактор).
Линия регрессии - график функции у = f (x).
2 Типа взаимосвязей между х и у:
1) может быть неизвестно, какая из двух переменных является независимой, а какая - зависимой, переменные равноправны, это взаимосвязь корреляционного типа;
2) если х и у неравноправны и одна из них рассматривается как объясняющая (независимая) переменная, а другая - как зависимая, то это взаимосвязь регрессионного типа.
Виды регрессий:
1) гиперболическая - регрессия равносторонней гиперболы: у = а + b / х + Е;
2) линейная - регрессия, применяемая в статистике в виде четкой экономической интерпретации ее параметров: у = а+b*х+Е;
3) логарифмически линейная - регрессия вида: In у = In а + b * In x + In E
4) множественная - регрессия между переменными у и х1 , х2 ...xm, т. е. модель вида: у = f(х1 , х2 ...xm)+E, где у - зависимая переменная (результативный признак), х1 , х2 ...xm - независимые, объясняющие переменные (признаки-факторы), Е- возмущение или стохастическая переменная, включающая влияние неучтенных факторов в модели;
5) нелинейная - регрессия, нелинейная относительно включенных в анализ объясняющих переменных, но линейная по оцениваемым параметрам; или регрессия, нелинейная по оцениваемым параметрам.
6) обратная - регрессия, приводимая к линейному виду, реализованная в стандартных пакетах прикладных программ вида: у = 1/a + b*х+Е;
7) парная - регрессия между двумя переменными у и x, т. е, модель вида: у = f (x) + Е, где у -зависимая переменная (результативный признак), x – независимая, объясняющая переменная (признак - фактор), Е - возмущение, или стохастическая переменная, включающая влияние неучтенных факторов в модели.
Корреляция - величина, отражающая наличие связи между явлениями, процессами и характеризующими их показателями.
Корреляционная зависимость - определение зависимости средней величины одного признака от изменения значения другого признака.
Коэффициент корреляции величин х и у (rxy) свидетельствует о наличии или отсутствии линейной связи между переменными:
где

 (-1;
1). Если:
(-1;
1). Если: =
-1, то наблюдается строгая отрицательная
связь;
=
-1, то наблюдается строгая отрицательная
связь; =
1, то наблюдается строгая положительная
связь;
=
1, то наблюдается строгая положительная
связь; =
0, то линейная связь отсутствует.
=
0, то линейная связь отсутствует. -
ковариация, т. е. среднее произведение
отклонений признаков от их средних
квадратических отклонений.
-
ковариация, т. е. среднее произведение
отклонений признаков от их средних
квадратических отклонений.Коэффициент корреляции может служить мерой зависимости случайных величин.
Корреляция для нелинейной регрессии:
 при R
при R [0;1].
[0;1].Чем ближе R к 1, тем теснее связь рассматриваемых признаков.
2. Основные задачи и предпосылки применения корреляционно-регрессионного анализа
Формы проявления корреляционной связи между признаками:
1) причинная зависимость результативного признака от вариации факторного признака;
2) корреляционная связь между двумя следствиями общей причины. Здесь корреляцию нельзя интерпретировать как связь причины и следствия. Оба признака - следствие одной общей причины;
3) взаимосвязь признаков, каждый из которых и причина, и следствие. Каждый признак может выступать как в роли независимой переменной, так и в качестве зависимой переменной.
Задачи корреляционно-регрессионного анализа:
1) выбор спецификации модели, т. е. формулировки вида модели, исходя из соответствующей теории связи между переменными;
2) из всех факторов, влияющих на результативный признак, необходимо выделить наиболее существенно влияющие факторы;
3) парная регрессия достаточна, если имеется доминирующий фактор, который и используется в качестве объясняющей переменной. Поэтому необходимо знать, какие остальные факторы предполагаются неизменными, так как в дальнейшем анализе их придется учесть в модели и от простой регрессии перейти к множественной;
4) исследовать, как изменение одного признака меняет вариацию другого.
Предпосылки корреляционно-регрессионного анализа:
1) уравнение парной регрессии характеризует связь между двумя переменными, которая проявляется как некоторая закономерность лишь в среднем в целом по совокупности наблюдений;
2) в уравнении регрессии корреляционная связь признаков представляется в виде функциональной связи, выраженной соответствующей математической функцией;
3) случайная величина Е включает влияние неучтенных в модели факторов, случайных ошибок и особенностей измерения;
4) определенному значению признака-аргумента отвечает некоторое распределение признака функции.
Недостатки анализа:
1) невключение ряда объясняющих переменных:
a. целенаправленный отказ от других факторов;
b. невозможность определения, измерения определенных величин (психологические факторы);
c. недостаточный профессионализм исследователя моделируемого;
2) агрегирование переменных (в результате агрегирования теряется часть информации);
3) неправильное определение структуры модели;
4) использование временной информации (изменив временной интервал, можно получить другие результаты регрессии);
5) ошибки спецификации:
a. неправильный выбор той или иной математической функции;
b. недоучет в уравнении регрессии какого-либо существенного фактора, т. е. использование парной регрессии, вместо множественной);
6) ошибки выборки, так как исследователь чаще имеет дело с выборочными данными при установлении закономерной связи между признаками. Ошибки выборки возникают и в силу неоднородности данных в исходной статистической совокупности, что бывает при изучении экономических процессов;
7) ошибки измерения представляют наибольшую опасность. Если ошибки спецификации можно уменьшить, изменяя форму модели (вид математической формулы), а ошибки выборки - увеличивая объем исходных данных, то ошибки измерения сводят на нет все усилия по количественной оценке связи между признаками.
3. Корреляционные параметрические методы изучения связи
Корреляционные параметрические методы - методы оценки тесноты свози, основанные на использовании, как правило, оценок нормального распределения, применяются в тех случаях, когда изучаемая совокупность состоит из величин, которые подчиняются закону нормального распределения.
Параметризация уравнения регрессии: установление формы зависимости; определение функции регрессии; оценка значений параметров выбранной формулы статистической связи Методы изучения связи - форму зависимости можно установить с помощью поля корреляции. Если исходные данные (значения переменных х и у) нанести на график в виде точек в прямоугольной системе координат, то получим поле корреляцииПри этом значения независимой переменной x (признак-фактор) откладываются по оси абсцисс, а значения результирующего фактора у откладываются по оси ординат. Если зависимость у от x функциональная, то все точки расположены на какой-то линии. При корреляционной связи вследствие влияния прочих факторов точки не лежат на одной линии.
Расчет показателей силы и тесноты связей Линейный коэффициент корреляции - количественная оценка и мера тесноты связи двух переменных. Коэффициент корреляции принимает значения в интервале от -1 до +1. Считают, что если этот коэффициент не больше 0,30, то связь слабая: от 0,3 до 0,7 - средняя; больше 0,7 - сильная, или тесная. Когда коэффициент равен 1, то связь функциональная, если он равен 0, то говорят об отсутствии линейной связи между признаками.

Коэффициент детерминации - квадрат линейного коэффициента корреляции, рассчитываемый для оценки качества подбора линейной функции.
Формула нелинейного коэффициента корреляции:

Корреляция для нелинейной регрессии Уравнение нелинейной регрессии, так же как и в линейной зависимости, дополняется показателем корреляции, а именно - индексом корреляции (R):

где
 -общая
дисперсия результативного признака у,
-общая
дисперсия результативного признака у,  -
остаточная дисперсия, определяемая
исходя из уравнения регрессии : ух
= f (х).Корреляция
для множественной регрессии. Значимость
уравнения множественной регрессии
оценивается с помощью показателя
множественной корреляции и его квадрата
- коэффициента детерминации. Показатель
множественной корреляции характеризует
тесноту связи рассматриваемого набора
факторов с исследуемым признаком, или
оценивает тесноту совместного влияния
факторов на результат. Независимо от
формы связи показатель множественной
корреляции может быть найден как индекс
множественной корреляции:
-
остаточная дисперсия, определяемая
исходя из уравнения регрессии : ух
= f (х).Корреляция
для множественной регрессии. Значимость
уравнения множественной регрессии
оценивается с помощью показателя
множественной корреляции и его квадрата
- коэффициента детерминации. Показатель
множественной корреляции характеризует
тесноту связи рассматриваемого набора
факторов с исследуемым признаком, или
оценивает тесноту совместного влияния
факторов на результат. Независимо от
формы связи показатель множественной
корреляции может быть найден как индекс
множественной корреляции: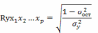
где
 - общая
дисперсия результативного признака;
- общая
дисперсия результативного признака; - остаточная
дисперсия для уравнения
- остаточная
дисперсия для уравненияу = f (x1,x2,…,xp)
4. Парная регрессия на основе метода наименьших квадратов и группировки
Парная регрессия - регрессия между двумя переменными у и х, т.е. модель вида: у = f (x)+E, где у- зависимая переменная (результативный признак); x - независимая, обьясняющая переменная (признак-фактор); E- возмущение, или стохастическая переменная, включающая влияние неучтенных факторов в модели. В случае парной линейной зависимости строится регрессионная модель по уравнению линейной регрессии. Параметры этого уравнения оцениваются с помощью процедур, наибольшее распространение получил метод наименьших квадратов.
Метод наименьших квадратов (МНК) - метод оценивания параметров линейной регрессии, минимизирующий сумму квадратов отклонений наблюдений зависимой переменной от искомой линейной функции.

где уi- статические значения зависимой переменной; f (х) - теоретические значения зависимой переменной, рассчитанные с помощью уравнения регрессии.
Экономический смысл параметров уравнения линейной парной регрессии. Параметр b показывает среднее изменение результата у с изменением фактора х на единицу. Параметр а = у, когда х = 0. Если х не может быть равен 0, то а не имеет экономического смысла. Интерпретировать можно только знак при а: если а > 0. то относительное изменение результата происходит медленнее, чем изменение фактора, т. е. вариация результата меньше вариации фактора: V < V. и наоборот.
То есть МНК заключается в том, чтобы определить а и а, так, чтобы сумма квадратов разностей фактических у и у. вычисленных по этим значениямa0 и а1 была минимальной:

Рассматривая эту сумму как функцию a0 и a1 дифференцируем ее по этим параметрам и приравниваем производные к нулю, получаем следующие равенства:


n - число единиц совокупности (заданны параметров значений x и у). Это система «нормальных» уравнений МНК для линейной функции (yx)
Расчет параметров уравнения линейной регрессии:
 ,
a = y – bx
,
a = y – bxНахождение уравнения регрессии по сгруппированным данным. Если совокупность сгруппирована по признаку x, для каждой группы найдены средние значения другого признака у, то эти средние дают представление о том, как меняется в среднем у в зависимости от х. Поэтому группировкаслужит средством анализа связи в статистике. Но ряд групповых средних уx имеет тот недостаток, что он подвержен случайным колебаниям. Они создают колебания уx отражающие не закономерность данной зависимости, а затушевывающий ее «шум».
Групповые средние хуже отражают закономерность связи, чем уравнение регрессии, но могут быть использованы в качестве основы для нахождения этого уравнения. Умножая численность каждой группы nч на групповую среднюю уч мы получим сумму у в пределах группы Суммируя эти суммы, найдем общую сумму у. Несколько сложнее с суммой ху. Если при сумме ху интервалы группировки малы, то можно считать значение x для всех единиц в рамках группы одинаковым Умножив на него сумму у, получим сумму произведений x на у в рамках группы и, суммируя эти суммы, общую сумму xу. Численность nx, здесь играет такую же роль, как взвешивание в вычислении средних.
5. Множественная (многофакторная) регрессия. Оценка существенности связи
Множественная регрессия - регрессия между переменными у и x1,x2,…,xm. Т. е. модель вида: у = f (x1,x2,…,xm)+E
где у - зависимая переменная (результативный признак);
x1,x2,…,xm - независимые, объясняющие переменные (признак-фактор); Е- возмущение, или стохастическая переменная, включающая влияние неучтенных факторов в модели.
Множественная регрессия применяется в решении проблем спроса, доходности акций, при изучении функции издержек производства, в макроэкономических расчетах. Цель множественной регрессии - построить модель с большим числом факторов, определив при этом влияние каждого из них в отдельности, а также их совокупное воздействие на моделируемый показатель.
Основные типы функций, используемые при количественной оценке связей: линейная функция: у = а0 + a1х1 + а2х2,+ ... + amxm.Параметры a1, а2, am, называются коэффициентами «чистой» регрессии и характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизменном значении других факторов, закрепленных на среднем уровне; нелинейные функции:у=ах1b1 х2b2....xmbm- - степенная функция; b1, b2..... bm - коэффициенты эластичности; показывают, насколько % изменится в среднем результат при изменении соответствующего фактора на 1 % и при неизменности действия других факторов.
 -
гипербола;
-
гипербола; -
экспонента.
-
экспонента.Отбор факторов при построении множественной регрессии. Включение в уравнение множественной регрессии того или иного набора факторов связано с представлением исследователя о природе взаимосвязи моделируемого показателя с другими экономическими явлениями. Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям.
1. Они должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, не имеющий количественного измерения, то ему нужно придать количественную определенность.
2. Факторы не должны быть интеркоррелированы и тем более находиться в точной функциональной связи. Включение в модель факторов с высокой интеркорреляцией может привести к нежелательным последствиям - система нормальных уравнений может оказаться плохо обусловленной и повлечь за собой неустойчивость и ненадежность оценок коэффициентов регрессии.
3. Если между факторами существует высокая корреляция, то нельзя определить их изолированное влияние на результативный показатель и параметры уравнения регрессии оказываются неинтерпретируемыми.
Методы построения уравнения множественной регрессии. Подходы к отбору факторов на основе показателей корреляции могут быть разные. Они приводят построение уравнения множественной регрессии к разным методам:
1) метод исключения (отсев факторов из полного его набора);
2) метод включения (дополнительное введение фактора);
3) шаговый регрессионный анализ (исключение ранее введенного фактора).
Каждый из этих методов по-своему решает проблему отбора факторов, давая в целом близкие результаты.
6. Методы изучения связи социальных явлений. Непараметрические показатели связи
Непараметрические методы не накладывают ограничений на закон распределения изучаемых величин. Их преимуществом является простота вычислений.
Непараметрические показатели связи
Коэффициент ассоциации:

Коэффициент контингенции:

Коэффициент взаимной сопряженности Пирсона:


Коэффициент Фехнера:

Коэффициент корреляции рангов:

Непараметрические показатели связи позволяет судить о степени и тесноте связи не только, для количественных, но и для атрибутивных признаков.
Методы многомерного анализа, основанные на рассмотрении сочетания непараметрических взаимосвязанных признаков:
1) дискриминантный анализ состоит в установлении правила, на основании которого та или иная новая единица не может быть отнесена к данной совокупности объектов, имея в виду значения рассматриваемых у нее признаков;
2) распознавание образов состоит в отнесении объекта на основании сочетания признаков в ту или другую из заранее определенных и охарактеризованных групп совокупности;
3) кластерный анализ (таксономия) состоит в разбиении совокупности на классы (группы, типы, «кластеры», «таксоны»), границы которых наперед не заданы. Число кластеров может быть при этом задано или нет;
4) метод главных компонент - если признаки отобраны правильной в них действительно отражается качественная природа объектов в рассматриваемом отношении, то эти признаки оказываются друг с другом связанными;
факторный анализ является дальнейшим развитием метода главных компонент. В нем охватываемая выделенными -главными компонентами» У вариация всех признаков X может затем между ними перераспределяться, причем между ними может быть допущена и корреляция.