

455716
.pdf91
корреляции сигнала (простирании сигнала). Величина смещения сигнала от профиля к профилю определяется по положительному экстремуму ВКФ для данных соседних пар профилей.
В соответствии с изложенным, обработка данных по способу межпрофильной корреляции включает следующие процедуры:
-расчет нормированных ВКФ для данных соседних пар профилей; -оценка простирания сигнала по величине абсциссы положительного экстремума
ВКФ;
-задание направления суммирования и выбор базы суммирования из N-
профилей. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Вычисление нормированных |
ВКФ |
дает |
|
возможность оценить |
отношение |
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
B (l ) |
|
сигнал/помеха по значению положительного экстремума ВКФ |
|
s |
= |
|
|||||||||||||||||||
BН (lэ ) : σ 2 |
1 − B |
(l ) . |
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
э |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Н |
э |
что позволяет |
определить |
базу |
суммирования |
N исходя из |
заданной |
надежности |
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
N ρ |
|
|
|
|
2 / σ 2 = 1 . |
(BН (lэ ) = 0,5) |
|
|
|||||||||
обнаружения |
сигнала |
γ = Φ |
|
|
|
|
. |
Так, |
при |
|
|
обычно |
|||||||||||
|
|
|
|
|
|
s |
|||||||||||||||||
|
2 |
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
m ³ 5 (ρ = 5) |
и при |
базе |
N=3 |
обеспечивается |
надежность |
обнаружения |
|
γ ³ 97% . |
|||||||||||||||
( N ρ = 15) . При |
|
2 / σ 2 < 1 , |
когда (BН (lэ ) = 0,3 ÷ 0, 4) . N ³ 5 ¸ 7 : |
|
|
|
|
|
|
|
|||||||||||||
s |
|
|
|
|
|
|
|
||||||||||||||||
-скользящее суммирование исходных данных по каждому заданному направлению суммирования в пределах N-профилей съемки. Результаты суммирования относятся к среднему из суммируемых профилей;
-выделение сигналов и аномальных зон по коррелируемым особенностям суммарного поля.
При этом надежно выделяемыми сигналами следует считать лишь те. которые коррелируются по числу профилей. превышающему базу суммирования. Заметим, что изложенный алгоритм аналогичен методам общей глубинной точки и регулируемого направленного приема (РНП) в сейсморазведке. В первом из них направление суммирования задается с учетом известной скоростной характеристики разреза конечным, во втором осуществляется перебор по различным значениям кажущейся скорости.
Результаты обработки данных магнитного поля способом межпрофильной корреляции приведены на рис.8.3, на котором иллюстрируется разделение аномалий по двум направлениям их простираний.
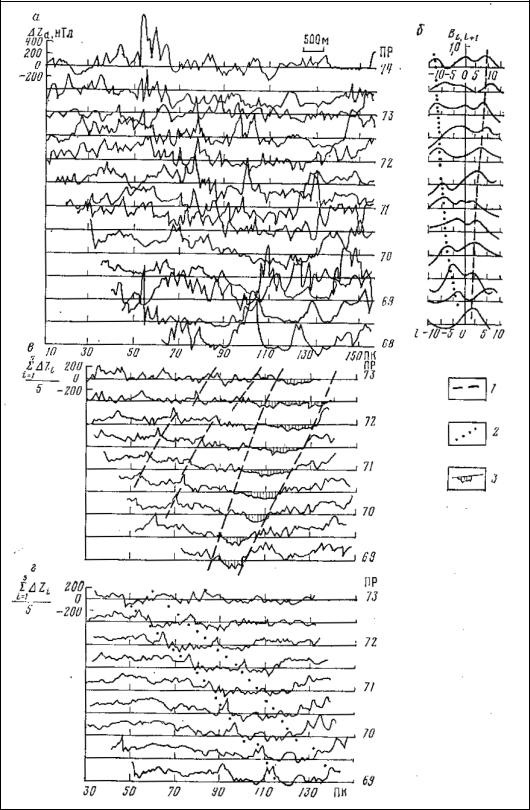
92
Рис.8.3. Разделение аномалий по двум направлениям их простираний с использованием метода межпрофильной корреляции.
а - исходные данные, б - функция взаимной корреляции между соседними профилями, в- результат суммирования по пяти профилям (северо-восточное простирание), г- результат суммирования по пяти профилям (северо-западное простирание).
93
8.6. Способ самонастраивающейся фильтрации.
Рассмотренный выше способ межпрофильной корреляции эффективен в тех случаях, когда по площади фиксируется несколько слабых сигналов одного и того же простирания, что обеспечивает надежную оценку положительного экстремума ВКФ. Однако, при этом слабые сигналы, отмечающиеся по простиранию от серии сигналов одного и того же направления или от сильных, визуально выделяемых сигналов, не будут выявлены. Одним из эффективных приемов обнаружения слабых сигналов при минимуме априорной информации об их форме в общем случае является способ самонастраивающейся фильтрации. Под самонастройкой (адаптацией) понимается приспособляемость алгоритма обработки к изменению свойств сигнала (его формы и параметров) и помех, в частности, к изменению дисперсии помех.
Оценка этих свойств производится непосредственно в процессе обработки данных. При использовании самонастраивающихся процедур обработки основное значение при принятии решения о наличии сигнала приобретают критерии многомерного дисперсионного анализа. Рассмотрим применение одного из таких критериев (критерий или статистика Хоттелинта), содержащего алгоритм решения задачи как обнаружения сигнала на фоне некоррелированных помех, так и разделения сигналов по различным направлениям.
Принципиальным в данном алгоритме является задание размеров скользящего окна, содержащего N профилей по m точек в каждом из профилей. Размеры такого окна можно оценить по контуру значимой изолинии. равной обычно 0,1 ÷ 0, 2 .
двумерной автокорреляционной функции. Направление простирания сигналов определяется наклоном окна, который задается величиной смещения окна θ к простиранию профилей на один, два и т.д. пикета последующего профиля относительно предыдущего. Обычно достаточно принять значение θ , равным
0; ±2 ; ±5 , поскольку направление профилей перпендикулярно к простиранию искомых объектов. В ином случае сеть профилей следует повернуть на 900.
В пределах скользящего окна, содержащего mN точек, оценивается форма сигнала непосредственно по наблюденным значениям поля путем их суммирования по
|
|
|
1 |
|
N |
|
|
|
|
|
|
|
|
|
||
N-профилям. т.е. |
|
= |
∑ fki . где |
fki |
- значение поля в i-той точке k-го профиля. |
|||||||||||
S |
||||||||||||||||
N |
||||||||||||||||
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|||
По полученной оценке формы сигнала |
|
|
рассчитывается дисперсия сигнала |
|||||||||||||
Si |
||||||||||||||||
|
|
|
|
|
|
|
1 |
m |
1 |
N |
2 |
|
||||
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
S 2 = |
|
∑ |
|
∑ fki |
(8.18) |
|||||||
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
m i=1 |
N |
1 |
|
|
|||||

94
Для оценки дисперсии некоррелированной помехи следует из наблюденных значений поля fki вычесть полученную оценку формы сигнала по каждому профилю и затем рассчитать дисперсию найденного результата, т.е.
|
1 |
N m |
|
|
1 |
N |
|
2 |
σ 2 = |
|
∑∑ fki |
− |
|
∑ fki |
(8.19) |
||
|
N |
|||||||
|
mN k =1 i=1 |
|
|
1 |
|
|
||
Отношение дисперсии сигнала (8.18) к дисперсии помех (8.19) определяет непосредственно алгоритм самонастраивающейся фильтрации в виде
|
|
|
|
|
|
1 |
m 1 |
N |
|
2 |
|
|
||
|
|
|
2 |
|
|
|
|
∑ |
|
∑ fki |
|
|
||
|
|
|
|
|
|
m |
|
|
|
|||||
|
|
s |
|
|
|
|
|
|||||||
μ = |
|
|
= |
|
|
1 N |
1 |
|
|
|
(8.20) |
|||
σ 2 |
1 |
|
N |
m |
|
1 |
N |
2 |
||||||
|
|
|
|
|
|
∑∑ fki |
− |
|
∑ fki |
|
||||
|
|
|
|
|
mN |
N |
|
|||||||
|
|
|
|
|
1 |
1 |
|
1 |
|
|
||||
В этом алгоритме величина отношения сигнал/помеха получена лишь по наблюденным значениям поля без привлечения априорных сведений о форме сигнала и дисперсии помех.
Далее путем перемещения окна вдоль и вкрест простирания профилей реализуется оценка отношения сигнал/помеха по всей площади съемки.
Решение о наличии сигнала принимается при значении s 2 / σ 2 , большем пороговой величины μпор. . Величина μпор определяется при заданной вероятности ошибки I рода для центрального F (0, q1, q2 ) распределения с q1 = m и q2 = m( N − 1) -
степенями свободы. Центральное F-распределение соответствует критерию Фишера в многомерном дисперсионном анализе. Этому распределению подчинена статистика Хоттелинта. отличающаяся от выражения (8.20) лишь на множитель N. В таблице 2 для
α= 5% приведены пороговые значения d для статистики Хоттелинга при некоторых m
иN.
Таблица 2.
|
|
m |
5 |
10 |
|
15 |
20 |
|
|
(N-1)m |
|
|
|
|
|
|
|
|
10 |
|
3.33 |
3.00 |
|
2.84 |
2.77 |
|
|
15 |
|
2.90 |
2.56 |
|
2.40 |
2.33 |
|
|
20 |
|
2.71 |
2.36 |
|
2.20 |
2.12 |
|
|
30 |
|
2.53 |
2.20 |
|
2.01 |
1.93 |
|
|
60 |
|
2.37 |
2.02 |
|
1.84 |
1.75 |
|
Величина |
μпор. |
связана с пороговыми значениями статистики Хоттелинга как |
||||||
μ = d / N . Так, |
для |
окна, содержащего m=5 |
и N=3 точек, |
пороговое значение |
||||
μпор. =d/N=3.33/3=1.11.
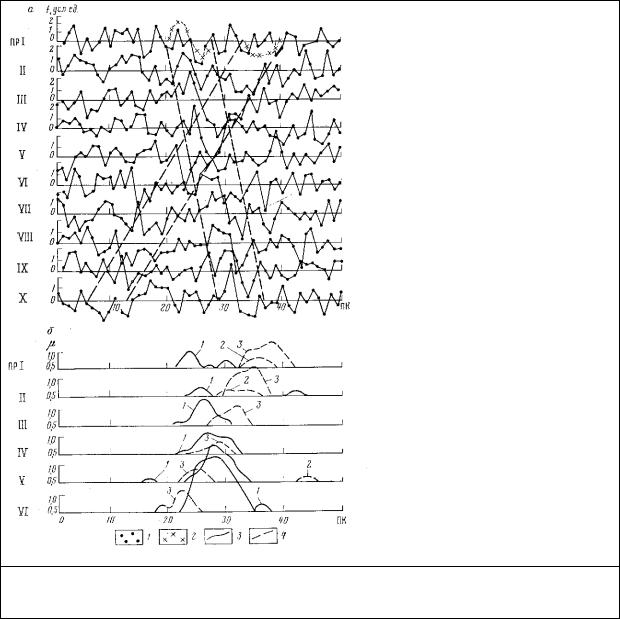
95
Вычисление отношения (8.20) осуществляется при разных наклонах скользящего окна, что обеспечивает обнаружение сигналов различного простирания при значениях μ > μпор. . При этом форма сигнала может существенно изменяться на разных участках исследуемой площади, однако при обнаружении сигнала такое изменение не имеет значения. поскольку лишь необходимо. чтобы величина μ была бы больше μпор.
Аналогично не имеет значения изменение интенсивности помех σ 2 . так как снова необходимо лишь выполнение условия μ > μпор. .
Используя распределение значений μki > μпор. по площади, можно найти оценку формы сигнала на любых интервалах исследуемой площади. если перемножить исходные значения поля fki на значения μki > μпор. .
Рис.8.4.Результаты обработки б) модельных данных а) методом самонастраивающейся фильтрации. 1- сумма сигнала и помех, 2-форма и местоположение аномалий, значение μ
для положительного 3) и отрицательного 4) наклона окна
96
8.7. Многомерные аналоги метода обратных вероятностей и самонастраивающейся фильтрации.
В данном разделе рассматриваются методы обнаружения слабых многопризнаковых геофизических аномалий, которые являются многомерными аналогами способов обратных вероятностей и самонастраивающейся фильтрации. Слабыми многопризнаковыми аномалиями будем называть такие аномалии, энергетическое отношение которых
N
ρ = ∑R -1 R (8.21) a j S a j′
j=1
меньше единицы. Здесь N - число аномальных точек, a j - значения многопризнаковой
аномалии и S - оценка ковариационной матрицы по значениям многопризнаковой аномалии. Отдельные компоненты таких аномалий по отдельным признакам практически не выделяются визуально, и их амплитуда соизмерима или меньше уровня осложняющих аномальные эффекты помех.
8.7.1.Многомерный способ обратных вероятностей.
Математическая модель многомерного аналога способа обратных вероятностей состоит в следующем. Пусть имеется сеть наблюдений размером в M профилей и N пикетов. В каждой точке наблюдения значения представлены вектором f = { f 1 , f 2 ,..., f p } , отдельные компоненты которого являются значения по различным
геофизическим полям или их трансформантам (признакам). Считается, что наблюдения
в отдельной i - ой |
точке представлены либо суммой многопризнаковой аномалии |
|||
R |
|
R |
f |
R R |
ai = { a1i ,a2i ,...,a pi } и помехи ni = { n1i ,n2,i ,...,n pi } . т.е. |
= ai + ni . либо только помехой, |
|||
|
|
|
|
i |
т.е. f |
R |
|
|
|
= ni . На векторную помеху накладывается условие о ее p -мерном нормальном |
||||
|
i |
|
|
|
распределении с нулевым вектором среднего и ковариационной матрицей S . |
||||
|
Кроме того, |
предполагается некоррелированный характер помехи каждого из |
||
признаков по площади наблюдений. Как и в одномерном случае, для построения алгоритма обработки необходима априорная информация о параметрах многопризнаковой аномалии и о величине дисперсии помехи по каждому признаку.
На основе описанной модели наблюдений, задача обнаружения p -мерной
многопризнаковой аномалии формулируется следующим образом: для имеющейся
последовательности многопризнаковых наблюдений F = { f |
, f |
,..., f |
} , требуется |
|
1 |
2 |
m |

97
определить, являются ли наблюдения суммой известной по форме многопризнаковой аномалии (заданной в m точках) и p -мерной помехи (гипотеза H 1 ), или же эти наблюдения представлены лишь помехой по каждому из признаков (гипотеза H 0 ).
По аналогии с одномерным вариантом способа обратных вероятностей формула 8.14. для расчета коэффициента правдоподобия L и проверки гипотезы H 1 будет иметь вид:
m |
1 |
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
′ |
|
|||
P(F/ H 1 )= ∑ |
|
|
|
|
exp[- |
|
|
R |
R |
|
-1 |
R |
R |
(8.22) |
||||||
|
|
|
|
|
|
|
|
|
( f |
- ai )S |
( f |
- ai ) ] |
||||||||
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
||||||||||||
(2π ) |
p |
|
|
|||||||||||||||||
i=1 |
| S | |
2 |
|
|
|
i |
|
|
|
i |
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
соответственно для нулевой гипотезы H 0 : |
|
|
|
|
|
|
|
|
|
|
|
|||||||||
m |
1 |
|
|
|
|
|
1 |
R |
|
R |
|
|
|
|
|
|||||
P(F/ H 0 )= _ |
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
exp[- |
f i S -1 |
fi ' |
] |
|
|
(8.23) |
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||||
i=1 |
|
(2π )p | S | |
|
2 |
|
|
|
|
|
|
|
|
||||||||
Коэффициент правдоподобия в этом случае равен:
|
P(F/ H 1 ) |
1 |
m |
R |
R |
-1 |
R |
R ′ |
R |
-1 |
R |
' |
|
||
L = |
|
|
= exp[- |
|
∑( f i |
- ai ) S |
|
( f i |
- ai ) + f i S |
|
fi |
|
] |
||
P(F/ H 0 ) |
|
|
|
|
|||||||||||
|
|
2 i=1 |
|
|
|
|
|
|
|
|
|
|
|||
Поскольку ковариационная матрица помехи симметрична, то справедливы следующие преобразования:
1 |
m |
R |
R |
|
-1 |
R |
|
R ′ |
R |
||
L = exp[- |
|
∑( f i - ai )S |
( f i |
- ai ) + f |
|||||||
|
|||||||||||
|
2 i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
m |
R |
R |
|
1 |
|
|
m R |
R |
= exp{ ∑ f i S |
-1ai′ - |
|
|
∑ai S |
-1ai′ |
||||||
|
|
||||||||||
|
|
|
I=1 |
|
|
|
2 i=1 |
|
|||
R
i S -1 f i′ ] =
}
Согласно критерию максимального правдоподобия при выполнении неравенства L > 1 будет справедлива гипотеза H 1 . в противном случае справедлива гипотеза H 0 .
Выполнение неравенства L > 1 эквивалентно выполнению неравенства:
m R |
R |
m |
R |
R |
∑ f i S -1 ai′ > ∑ ai S |
-1 ai′ |
|||
i=1 |
|
i=1 |
|
|
Переход от коэффициента правдоподобия к апостериорной вероятности наличия аномалии осуществляется по формуле Байеса.
|
|
P( H 1 /F) = L/(L +1) |
|
||
При |
P( H 1 /F) > 0.5 |
принимается решение |
о |
наличии многопризнаковой |
|
аномалии |
aRi ,i = 1,2,...,m , |
при P( H 1 /F) < 0.5 |
- |
об |
ее отсутствии. Надежность |
обнаружения аномалии γ |
определяется через |
интеграл вероятности по аналогии с |
|||
одномерным случаем с использованием величины R из (8.21):
γ = φ( 
 ρ /2)
ρ /2)

98
8.7.2.Многомерный способ самонастраивающейся фильтрации.
Математическая модель многомерного аналога способа самонастраивающейся фильтрации состоит в том, что, как и в одномерном случае, рассматривается окно размером в n -пикетов и m -профилей на прямоугольной сети наблюдений размером в M профилей и N пикетов. Остальные предпосылки относительно свойств помехи и наблюденных данных полностью согласуются с общей моделью, рассмотренной в предыдущем разделе.
При различных расположениях окна (различных наклонах окна по отношению к простиранию профилей) проверяется нулевая гипотеза о средних значениях во всех столбцах окна. Отличием от одномерного случая является то, что значения в окне образуют векторы размерности p , где p число признаков. Модель поля при отсутствии аномалий определяется многомерной нормально распределенной помехой с нулевым вектором среднего m = { m1 ,m2 ,...,mp } и ковариационной матрицей S
(гипотеза H0). При наличии аномалии - суммой многопризнаковой аномалии a и той же помехи (гипотеза H1). Считается, что значение ковариационной матрицы неизвестно. Окончательное выражение для статистики критерия F для проверки гипотез H0 и H1 имеет вид [6]:
|
|
|
nm - n - p +1 |
|
|
|
|
n |
R |
|
R |
|
|
F = |
|
|
Sp( ∑n f *j |
f *′j S |
-1 ) = |
||||||
|
(n - 1)pn(m - 1) |
|||||||||||
|
|
|
|
|
j=1 |
|
|
|
|
|||
|
|
|
nm - n - p +1 |
|
|
n |
R |
|
-1 |
R |
|
|
|
|
|
|
|
|
|
|
|||||
|
= |
|
|
∑n f *j S |
f *′j |
|
||||||
|
(n - 1)p(nm - n) |
|
|
|||||||||
|
|
|
j=1 |
|
|
|
|
|
||||
где fR |
-оценка вектора среднего в j -ом столбце окна; |
|||||||||||
|
* j |
|
|
|
|
|
|
|
|
|||
m-количество строк в окне;
n-количество столбцов в окне;
S -оценка ковариационной матрицы в окне; Sp – знак следа матрицы.
Гипотеза H 0 о равенстве векторов средних в столбцах окна нулевому вектору отклоняется (то есть принимается решение о наличии аномалии), если: F ³ F g1,g2 ,α . где
- критическое значение F -распределения со степенями свободы:
(n - 1)p(nm - n - p) g1 = nm - (n - 1)p - 2
g2 = nm - n - p +1
на уровне значимости α .
99
ГЛАВА IX. Обработка комплексных геофизических наблюдений.
9.1.Методы классификации многомерных наблюдений.
Существующие в настоящее время классификационные алгоритмы, основанные на принципах самообучения, можно разделить на три основных группы – эвристические, корреляционные и статистические. Эвристические методы классификации основаны на разбиении диапазона значений каждого признака на заданное число градаций и в большинстве своем сводятся к расчету комплексного параметра, который является линейной комбинацией соответствующего номера интервала градации по совокупности анализируемых признаков в каждой точке наблюдений. Существенным недостатком эвристических методов является то обстоятельство, что они строятся в предположении независимости отдельных признаков между собой. Однако, наличие отдельных недостатков алгоритмов классификации не уменьшает их значимости в обработке геолого-геофизических наблюдений.
Рассматриваемые способы классификации многопризнаковых геофизических наблюдений относятся к числу эвристических и направлены на решение задачи выделения в многомерном пространстве компактных групп точек. В прикладных задачах автоматической классификации (при отсутствии эталонных объектов) эвристические алгоритмы стали применяться одними из первых и до сих пор сохраняют большое значение благодаря наглядности полученных результатов и, как
правило, |
простоте реализации. |
|
|
|
Разделение рассматриваемой совокупности признаков на однородные (в |
смысле |
|||
вектора |
среднего) группы |
называется классификацией. |
При этом |
термин |
“ классификация” используют, |
в зависимости от контекста, |
для обозначения, как |
||
самого процесса разделения, так и его результата. Это понятие тесно связано с такими терминами, как группировка, типологизация, систематизация, дискриминация, кластеризация, и является одним из основополагающих в практической и научной деятельности человека.
В общей постановке задачи проблема классификации объектов заключается в том, чтобы всю анализируемую совокупность признаков, представленную в виде матрицы, разбить на сравнительно небольшое число однородных, в определенном смысле, групп или классов. Понятие однородности основано на предположении, что геометрическая
100
близость двух или нескольких объектов означает близость их “ физических” состояний, их сходство.
В общем случае понятие однородности объектов определяется заданием правила вычисления величины ρij . характеризующей расстояние d ( X i , X j ) между объектами Хi
и Хj из исследуемой совокупности. Если задана функция d ( X i , X j ) . то близкие в
смысле этой метрики объекты считаются однородными, принадлежащими к одному классу. Естественно, при этом необходимо сопоставление d ( X i , X j ) с некоторым
пороговым значением, определяемым в каждом конкретном случае по-своему.
9.1.1.Метод динамических сгущений (k-средних).
Достаточно известный и эффективный метод классификации многомерных наблюдений на заранее известное число классов k в условиях минимума информации о начальных центрах классов, известный под названием k-средних или k-ближайших
соседей. Блок схема алгоритма заключается в следующем: |
|
|
|
|
||||||||
-для |
всех |
p |
обрабатываемых |
признаков |
оценивается |
значение |
||||||
среднеквадратического |
|
отклонения |
σ i |
, |
минимального |
Yimin |
и максимального |
|||||
Y imax ,i = 1,..p значений; |
|
|
|
|
|
|
|
|
|
|
||
-каждый f i , i = 1,..., p признак |
нормируется на |
соответствующее |
значение |
|||||||||
|
|
|
/ σ i ; |
|
|
|
|
|
||||
среднеквадратического отклонения f i |
= f i |
|
|
|
|
|
||||||
-случайным образом выбирается k |
|
векторов размерности |
p |
начальных центров |
||||||||
классов |
C j = { c1j ,c2j ,...,cpj } , j = 1,..,k . |
|
причем отдельные |
случайно |
выбранные |
|||||||
компоненты каждого вектора удовлетворяют неравенству |
Yimin |
< cij < |
Yimax |
; |
σ i |
σ i |
|||
-осуществляется классификация нормированных многопризнаковых наблюдений |
||||
исходной сети на классы, при этом значение в каждой точке сети x = { x1 ,.., x p } относится к классу m . если расстояние от центра этого класса до точки является минимальным
rm = MIN{r1 ,..,rk } ;
-по результатам |
классификации определяются новые |
вектора центров классов. |
||
R |
|
при этом каждая компонента отдельного вектора m является |
||
Cn = { c1jn ,...,cnpj } , j = 1,..k . |
||||
|
1 |
nm |
|
|
оценкой среднего cimn = |
∑ xim ,i = 1,..p . рассчитанной по nm |
точкам, попавшим в класс |
||
nm |
||||
|
j=1 |
|
||
m после классификации. проведенной на предыдущем шаге алгоритма;