

Алгоритмы классификации |
201 |
Дисперсия
Дисперсия (variance) количественно определяет точность, с которой модель оценивает целевую переменную, если для обучения модели использовался другой набор данных. Она показывает, насколько хорошо математическая фор мулировка модели обобщает лежащие в ее основе закономерности.
Слишком точные правила, основанные на конкретных ситуациях, дают высо кую дисперсию, а общие правила, применимые к различным ситуациям‚ — низкую.
Наша цель — обучить модели, которые демонстрируют низкое смеще ние и низкую дисперсию. Это непростая задача, которая лишает сна многих дата-сайентистов.
Дилемма смещения — дисперсии
При обучении модели МО довольно сложно определить уровень обобще ния правил, лежащих в ее основе. Это отражено в дилемме смещения — дис персии.
Обратите внимание, что упрощенные допущения = большее обобщение = низкая дисперсия = высокое смещение.
Соотношение между смещением и дисперсией определяется выбором алгорит ма, характеристиками данных и различными гиперпараметрами. Важно достичь оптимального компромисса, опираясь на требования конкретной задачи.
Этапы классификации
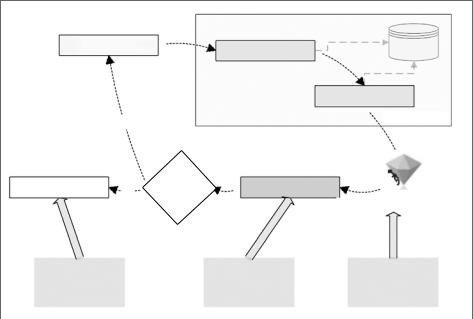
Как только размеченные данные подготовлены, мы приступаем к разработке классификаторов. Она включает в себя обучение, оценку и внедрение. Три эта па реализации классификатора представлены в жизненном цикле CRISP-DM на следующей диаграмме (рис. 7.5). CRISP-DM подробно описан в главе 6.
На первых двух этапах реализации классификатора — контроля и обучения — используются размеченные данные. Они разделены на две части: большую часть — обучающие данные и меньшую часть — контрольные данные. Для раз деления данных используется метод случайной выборки. Это позволяет гаран тировать, что обе части содержат единые закономерности. Сначала выполняет
202 |
Глава 7. Традиционные алгоритмы обучения с учителем |
ся обучение модели с помощью обучающих данных, затем — ее проверка посредством контрольных данных. Для оценки работы обученной модели ис пользуются различные матрицы производительности. После этого происходит развертывание модели. Обученная модель используется для извлечения инфор мации и решения реальной задачи путем присваивания меток неразмеченным данным (см. рис. 7.5).
|
- |
|
• |
|
|||
|
|
|
|
|
|||
|
|
|
|
|
|
• • • |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
< |
• • |
|
|||
|
|
||||||
|
|
|
|
||||
3. |
2. |
1. |
|
|
|
||
|
|||
|
|
||
|
|||
|
|
|
|
|
Рис. 7.5 |
|
Рассмотрим следующие алгоритмы классификации:
zz алгоритм дерева решений (decision tree algorithm); zz алгоритм XGBoost (XGBoost algorithm);
zz алгоритм случайного леса (random forest algorithm);
zz алгоритм логистической регрессии (logistic regression algorithm); zz метод опорных векторов (SVM, support vector machine); zzнаивный байесовский алгоритм (naive Bayes algorithm).
Начнем с алгоритма дерева решений.
Алгоритмы классификации |
203 |
Алгоритм дерева решений
Дерево решений основано на рекурсивном методе разделения («разделяй и вла ствуй»). Алгоритм генерирует набор правил, которые можно использовать для предсказания метки. Он начинается с корневого узла и расходится на несколь ко ветвей. Внутренние узлы представляют собой проверку по определенному атрибуту, а результат проверки является ответвлением на следующий уровень. Дерево решений заканчивается концевыми узлами, в которых содержатся ре шения. Процесс останавливается, если разделение больше не улучшает резуль тат.
Этапы алгоритма дерева решений
Отличительной особенностью дерева решений является создание понятной для человека иерархии правил, используемых для предсказания метки. По своей природе это рекурсивный алгоритм. Создание иерархии правил состоит из следующих шагов.
1.Поиск наиболее важного признака. Алгоритм определяет признак, который наилучшим образом дифференцирует элементы в обучающем наборе данных относительно метки. Расчет основан на таких критериях, как прирост информации (information gain) или критерий (примесь) Джини (Gini impurity).
2.Разделение. С помощью этого признака алгоритм создает критерий, который используется для разделения обучающего набора данных на две ветви:
yy элементы данных, которые соответствуют критерию; yy элементы данных, которые не соответствуют критерию.
3.Проверка на наличие концевых узлов. Если полученная ветвь в основном со держит метки одного класса, она становится окончательной и завершается концевым узлом.
4.Проверка условий остановки и повтор. Если предусмотренные условия оста новки не выполнены, алгоритм возвращается к шагу 1 для следующей ите рации. В противном случае модель считается обученной, и каждый узел результирующего дерева решений на самом низком уровне помечается как концевой узел. В качестве условия остановки можно просто задать количество итераций. Также можно установить условие, при котором алгоритм завер шается, как только достигает определенного уровня однородности для каж дого концевого узла.
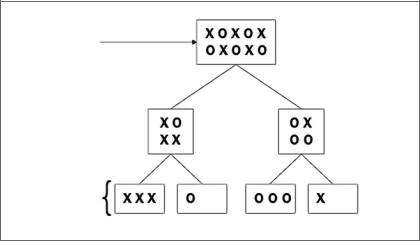
Алгоритм дерева решений проиллюстрирован на следующей диаграмме (рис. 7.6).
204 |
Глава 7. Традиционные алгоритмы обучения с учителем |
Рис. 7.6
На диаграмме корневой узел содержит множество крестиков и ноликов. Алго ритм создает критерий, по которому пытается отделить нолики от крестиков. На каждом уровне дерево решений создает разделы данных, которые становят ся все более и более однородными с уровня 1 и выше. Идеальный классифика тор имеет концевые узлы, которые содержат только нолики или крестики. Обучение идеальных классификаторов обычно затруднено из-за присущей набору обучающих данных неупорядоченности.
Использование алгоритма дерева решений для задачи классификации
Теперь используем алгоритм дерева решений на практике, чтобы решить по ставленную задачу: нам необходимо предсказать, купит ли клиент некий продукт.
1.Прежде всего создадим экземпляр алгоритма дерева решений и обучим мо дель, используя обучающую часть данных, подготовленную для классифи каторов:
classifier = sklearn.tree.DecisionTreeClassifier(criterion = 'entropy', random_state = 100, max_depth=2) classifier.fit(X_train, y_train)
2.С помощью обученной модели предскажем метки для контрольной части размеченных данных. Создадим матрицу ошибок, чтобы обобщить произво дительность модели:

Алгоритмы классификации |
205 |
import sklearn.metrics as metrics y_pred = classifier.predict(X_test)
cm = metrics.confusion_matrix(y_test, y_pred) cm
Получим следующий результат (рис. 7.7).
Рис. 7.7
3.Теперь рассчитаем значения accuracy, recall и precision для созданного классификатора с помощью алгоритма дерева решений:
accuracy= metrics.accuracy_score(y_test,y_pred) recall = metrics.recall_score(y_test,y_pred) precision = metrics.precision_score(y_test,y_pred) print(accuracy,recall,precision)
4. Выполнение этого кода приведет к следующему результату (рис. 7.8).
Рис. 7.8
Метрики производительности позволяют сравнить различные методы обу чения моделей между собой.
Сильные и слабые стороны классификаторов дерева решений
В этом разделе мы рассмотрим достоинства и недостатки использования алго ритма дерева решений для классификации.
Сильные стороны
zz Правила моделей, созданных с помощью алгоритма дерева решений, могут быть интерпретированы людьми. Такие модели называются «белыми ящиками» (whitebox models). «Белый ящик» требуется, если нужна прозрачность для отслеживания подробностей и причин решения, принимаемого моделью. Прозрачность имеет огромное значение в тех случаях, где необходимо из бежать предвзятости и защитить уязвимые группы населения. Как правило, модель «белый ящик» используется для вынесения важнейших решений в государственных и страховых отраслях.
206 |
Глава 7. Традиционные алгоритмы обучения с учителем |
zz Классификаторы на основе дерева решений предназначены для извлечения информации из дискретного пространства задачи. Это означает, что по большей части признаки являются категориальными переменными, поэтому использование дерева решений для обучения модели — хороший выбор.
Слабые стороны
zz Если дерево, сгенерированное классификатором, слишком разрастается, то правила становятся слишком детализированными и это приводит к пере обучению модели. Этот алгоритм склонен к переобучению, поэтому мы должны «подстригать» дерево по мере необходимости.
zz Классификаторы на основе дерева решений не способны фиксировать не линейные взаимосвязи в создаваемых ими правилах.
Примеры использования
Рассмотрим примеры практического применения алгоритма дерева решений.
Классификация записей
Классификаторы деревьев решений могут использоваться для классификации точек данных, например, в следующих случаях.
zz Заявки на ипотеку. Бинарный классификатор определяет вероятность не кредитоспособности заявителя.
zz Сегментация клиентов. Классификатор распределяет клиентов по принципу их платежеспособности (высокой, средней и низкой), чтобы можно было настроить маркетинговые стратегии для каждой категории.
zz Медицинский диагноз. Классификатор различает доброкачественные и зло качественные новообразования.
zz Анализ эффективности лечения. Классификатор отбирает пациентов, по ложительно отреагировавших на конкретное лечение.
Отбор признаков
Алгоритм классификации на основе дерева решений выбирает небольшое под множество признаков, чтобы создать для них правила. Его можно использовать для отбора признаков (если их много) в работе с другим алгоритмом машинно го обучения.