

Генетические алгоритмы оптимизации
Появившись на свет в качестве упрощенного описания эволюционных перестроек в природных популяциях организмов, генетические алгоритмы (ГА) стараниями многочисленных исследователей на сегодняшний день превратились в мощную поисковую процедуру, ориентированной на решение задач глобальной оптимизации в самом широком диапазоне возможных применений – от создания алгоритмов поиска в распределенных базах данных в условиях высокой степени неопределенности исходных критериев (Data Mining) до решения прикладных задач при проектировании современных технических устройств (в том числе и средств измерений).
ГА базируются на теоретических достижениях теории эволюции, учитывающей микробиологические механизмы наследования признаков в природных и искусственных популяциях организмов, а также на накопленном человечеством опыте в селекции животных и растений.
В основе ГА основана на гипотезе селекции, которая в самом общем виде может быть сформулирована так: чем выше приспособленность особи, тем выше вероятность того, что в потомстве, полученном с ее участием, признаки, определяющие приспособленность, будут выражены еще сильнее.
Применительно к техническим системам под особью будет подразумеваться тот или иной вариант ее реализации (или вариант принимаемого решения), а под приспособленностью – способность наиболее полно удовлетворять набору исходных требований- критериев (другими словами - оптимальность). Таким образом, ГА представляют собой семейство методов оптимизации.
Представим себе, что нам необходимо спроектировать самолет, который должен с максимальной скоростью (критерий 1) перевозить максимальное количество груза (критерий 2) на максимальное расстояние (критерий 3). После формирования набора критериев и допустимых диапазонов их изменения мы формируем набор параметров, наиболее полным образом характеризующих наш технический объект (размер и форма фюзеляжа и крыльев, количество и тип двигателей, материал обшивки, объем топливных баков и т. д.). Затем мы строим математическую модель и начинаем эксперименты с ней.
В классических эмпирических методах оптимизации мы, основываясь на предыдущем опыте, генерируем первоначальный вариант конструкции, вычисляем величину ее выходных величин (скорость, грузоподъемность, дальность) для данного варианта. Затем, в соответствии с выбранным алгоритмом изменяем параметры объекта, вычисляем выходные величины и т. д. Процедура повторяется пока не будет достигнут максимум поверхности функции цели.
Проблема состоит в том, что в общем случае приходится иметь дело с существенно нелинейной функцией многих переменных, нахождение глобального экстремума которой традиционными методами вовсе не гарантируется и может занять неопределенно долгое время. С описанием подобной задачи мы уже сталкивались, знакомясь с алгоритмами обучения искусственных нейронных сетей.
Традиционно практикуемый способ описания технических объектов при помощи векторов переменных проектирования подразумевает символьное кодирование информации об объекте. Вектор переменных— даже не чертеж, то есть глядя на него и не зная правил кодирования, невозможно составить представление об объекте. В определенном смысле можно утверждать, что категория вектор переменных проектирования играет в технике ту же роль, что и категория генотип в биологии. Группируя ключевые параметры объекта в вектор переменных, мы, но существу, придаем им статус генетической информации. Именно генетической, потому что, с одной стороны, ее достаточно, для того, чтобы построить сам объект, а во-вторых, она служит исходным материалом при генерации генотипов объектов следующего поколения.
Таким образом, в рассматриваемом примере используемый набор параметров по существу представляет собой геном самолета, а качество удовлетворения критериев тем или иным вариантом конструкции (особью) характеризует степень приспособленности этой особи к внешним условиям, заданным разработчиком.
Как и в биологическом прототипе, здесь присутствует гипотеза селекции — в качестве родительских всегда выступают лучшие, а не произвольные комбинации параметров объекта (особи) из популяции потенциальных решений, неудачные же решения отбрасывают на текущем шаге (можно считать, что они вымирают).
Здесь мы подходим к тому, что именно отличает ГА на фоне других численных методов оптимизации.
ГА заимствуют из биологии:
• понятийный аппарат;
• идею коллективного поиска экстремума при помощи популяции особей;
• способы представления генетической информации;
• способы передачи генетической информации в череде поколений (генетические операторы);
• идею о преимущественном размножении наиболее приспособленных особей (речь идет не о том, даст ли данная особь потомков, а о том, сколько будет у нее потомков).
Представление генетической информации
Подобно тому, как природный хромосомный материал представляет собой линейную последовательность различных комбинаций четырех нуклеотидов (А— аденин, Ц— цитозин, Т— тимин и Г— гуанин), векторы переменных в ГА также записывают в виде цепочек символов, используя двух-, трех- или четырехбуквенный алфавит. Для простоты изложения рассмотрим случай бинарного кодирования.
Итак, будем считать, что каждая переменная (параметр объекта) xn кодируется определенным фрагментом хромосомы, состоящим из фиксированного количества генов-бит (рис. …). В любой позиции фрагмента может стоять как ноль, так и единица. Рядом стоящие фрагменты не отделяют друг от друга какими-либо маркерами, тем не менее, при декодировании хромосомы в вектор переменных на протяжении всего моделируемого периода эволюции используется одна и та же маска, разделяющая хромосому на отдельные участки.
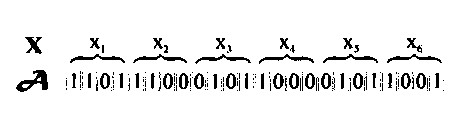
Рис. …. Простейшая маска картирования хромосомы, определяющая план распределения наследственной информации по длине хромосомы
На первоначальном этапе хромосомы популяции генерируются случайным образом, путем последовательного заполнения разрядов (генов), сразу в бинарном виде, и всякие последующие изменения в популяции затрагивают сначала генетический уровень, а только потом анализируются фенотипические последствия этих изменений, но никогда не наоборот.
В принципе, для декодирования генетической информации из бинарной формы к десятичному виду подходит любой двоично-десятичный код, но обычно исходят из того, что она представлена в коде Грея. Таблица … воспроизводит процедуру декодирования фрагмента 4-битового хромосомы в значение переменной xn.
Таблица … Декодирование фрагментов хромосом
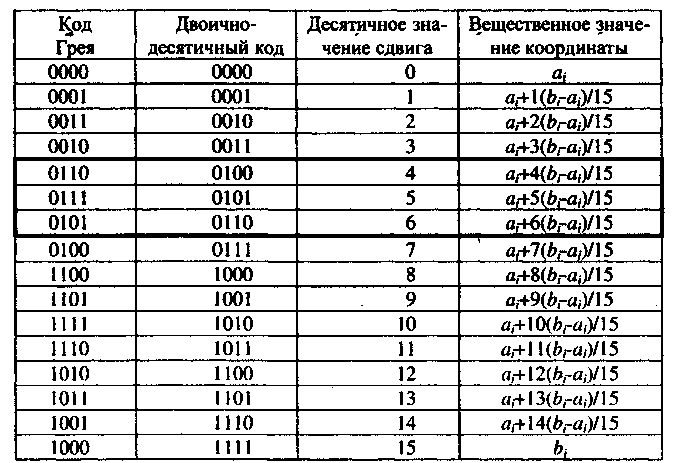
В качестве примера в таблице каждому значению переменной в коде Грея поставлено в соответствие то же значение, выраженное при помощи обычного двоично-десятичного кода. При этом хорошо видно, почему код Грея имеет явные преимущества по сравнению с двоично-десятичным кодом, который при некотором стечении обстоятельств порождает своеобразные тупики для поискового процесса. В коде Грея фенотипически близкие варианты решения всегда имеют и генотипически близкие кодовые комбинации генов. Собственно говоря, любые два соседних числа в этом коде всегда отличаются значением одного единственного бита, в отличие от двоично-десятичного кода, где это правило постоянно нарушается (см., например, разницу между представлением десятичных чисел 3 и 4, 7 и 8, 11 и 12 в обоих кодах).
Иначе говоря, код Грея гарантирует, что два соседних значения переменных всегда кодируются хромосомами, отличающимися состоянием всего одного гена. Двоично-десятичный код подобным свойством не обладает.
Генетические операторы
Те же механизмы передачи наследственности, которые действуют в природе, в упрощенной форме положены в основу того, что мы называем генетическими операторами в теории генетических алгоритмов. Таких операторов три (рис. …):
1. Кроссовер приводит к тому, что хромосома потомка включает два фрагмента, один из которых принадлежал ранее, условно говоря, отцовской хромосоме, а другой — материнской.
2. Мутация вызывает замену существующего состояния отдельного гена в хромосоме на противоположное (единицы — на ноль и наоборот).
3. Инверсия приводит к нарушению порядка следования фрагментов хромосом у потомка по сравнению с родительской хромосомой (фрагменты меняются местами).
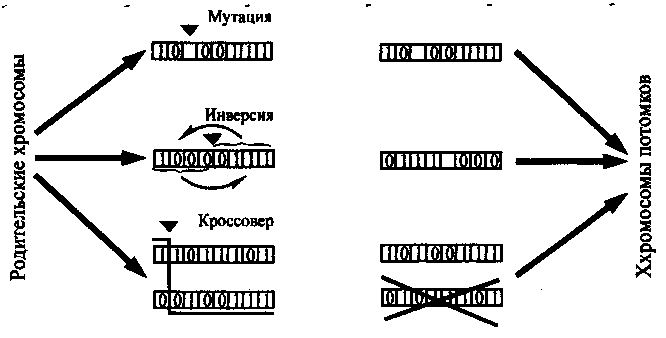
Рис. …. Триада генетических операторов
У всех трех операторов место приложения (помеченное на рис… закрашенным треугольником) выбирается случайно.
Процедурно работу одной из его быстро сходящихся версий ГА (репродуктивный план Холланда) можно проиллюстрировать блок-схемой, представленной на рис. …
На первом этапе случайным образом генерируем исходную популяцию бинарных хромосом. Декодируем значения переменных из кода Грея к десятичному виду.
При помощи математической модели определяем индекс приспособленности каждого решения (насколько оно удовлетворяет условиям задачи) и в зависимости от его величины упорядочиваем популяцию. Вычисляем среднюю по популяции приспособленность. Опираясь на нее, назначаем вероятность, с какой каждая особь, обладающая приспособленностью выше среднего уровня, может стать родителем. При этом для каждого родителя есть две возможности - либо просто быть скопированным в следующее поколение, либо подвергнуться воздействию генетических операторов в процессе генерирования хромосомы потомка.
Далее оцениваем приспособленность потомка, и, действуя аналогичным образом, постепенно заполняем популяцию следующего поколения. Через Μ шагов новое поколение оказывается сформированным. Ясно, что поскольку оно получено от лучших родителей, то его приспособленность должна быть также высокой. Блокируя слабо приспособленным особям возможность стать родителем и дать потомство, мы увеличиваем или, по крайней мере, не уменьшаем среднюю по популяции приспособленность.
Работу алгоритма прекращаем при достижении популяцией состояния адаптации, идентифицируемому по существенному сокращению генетического разнообразия в популяции - вырождению популяции. В идеальном случае в популяции остается 1 наиболее приспособленный генотип-родитель, все остальные – его полные близнецы.
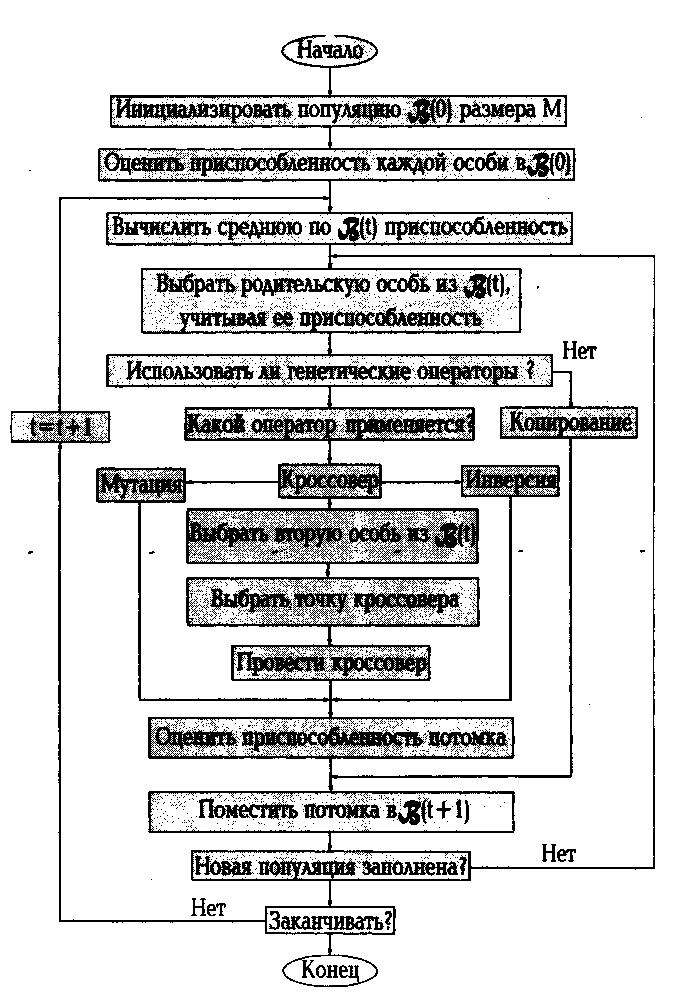
Рис. … Репродуктивный план Холланда
К сожалению, невозможно с полной уверенностью утверждать, что найденное решение представляет собой глобальный экстремум. Вырождение популяции является необходимым, но не достаточным признаком успешности поиска. Можно лишь повторно запустить алгоритм (возможно, изменив те или иные начальные условия) в надежде получить более удачное решение.
Хотя модель эволюционного развития, применяемая в ГА, сильно упрощена по сравнению со своим природным аналогом, тем не менее, ГА является достаточно мощным средством и может с успехом применяться для широкого класса прикладных задач, включая те, которые трудно, а иногда и вовсе невозможно, решить другими методам. Но даже там, где хорошо работаю существующие методики, можно достигнуть улучшения сочетанием их с ГА. Яркий пример такого сочетания – применение ГА для обучения искусственных нейронных сетей, демонстрирующее неплохие результаты по сравнению с применением традиционных градиентных методов.
Основы нечеткой логики
Нечеткая логика (fuzzy logic) возникла как наиболее удобный способ построения сложными технологическими процессами, а также нашла применение в бытовой электронике, диагностических и других экспертных системах. Математический аппарат нечеткой логики впервые был разработан в США в середине 60-х годов прошлого века, активное развитие данного метода началось и в Европе.
Классическая логика развивается с древнейших времен. Ее основоположником считается Аристотель. Логика известна нам как строгая наука, имеющая множество прикладных применений: например, именно на положениях классической (булевой) логики основан принцип действия всех современных компьютеров. Вместе с тем классическая логика имеет один существенный недостаток - с ее помощью невозможно адекватно описать ассоциативное мышление человека. Классическая логика оперирует только двумя понятиями: ИСТИНА и ЛОЖЬ (логические 1 или 0), и исключая любые промежуточные значения. Все это хорошо для вычислительных машин, но попробуйте представить весь окружающий вас мир только в черном и белом цвете, вдобавок исключив из языка любые ответы на вопросы, кроме ДА и НЕТ. В такой ситуации вам можно только посочувствовать.
Традиционная математика с ее точными и однозначными формулировками закономерностей также имеет в своей основе классическую логику. А поскольку именно математика, в свою очередь, представляет собой универсальный инструмент для описания явлений окружающего мира во всех естественных науках (физика, химия, биология и т. д.) и их прикладных приложениях (например, теория измерений, теория управления и т. д.), неудивительно все эти науки оперируют математически точными данными, такими как: «средняя скорость автомобиля на участке пути длиной 62 км равнялась 93 км/ч». Но мыслит ли в действительности человек такими категориями? Представим, что в вашей машине вышел из строя спидометр. Означает ли это, что отныне вы лишены возможности оценивать скорость вашего перемещения и не в состоянии ответить на вопросы типа «быстро ли ты доехал вчера домой?». Разумеется нет. Скорее всего вы скажете в ответ что-то вводе: «Да, довольно быстро». Собственно говоря, вы скорее всего ответите примерно в том же духе, даже и в том случае, если спидометр вашей машины был в полном порядке, поскольку, совершая поездки, не имеете привычки непрерывно отслеживать его показания в режиме реального времени. То есть, в своем естественном мышлении применительно к скорости мы склонны оперировать не точными значениями в км/ч или м/с, а приблизительными оценками типа: «медленно», «средне», «быстро» и бесчисленным множеством полутонов и промежуточных оценок: «тащился как черепаха», «катился, не торопясь», «не выбивался из потока», «ехал довольно быстро», «несся как ненормальный» и т. п.
Если попытаться выразить наши интуитивные понятия о скорости графически, то получится нечто вроде рисунка ниже.
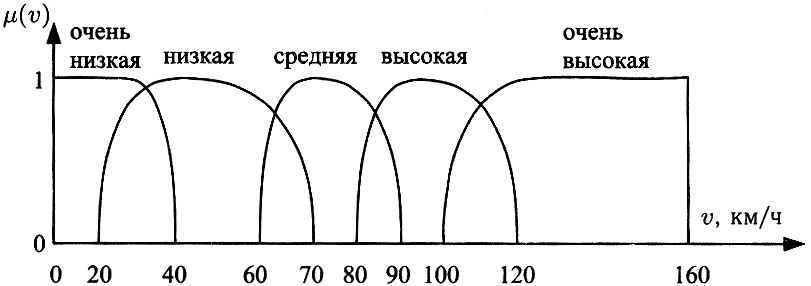
Здесь по оси X отложены значения скорости в традиционной строгой математической записи, а по оси Y – т. н. функцию принадлежности (изменяется от 0 до 1) точного значения скорости к нечеткому множеству, обозначенному тем или иным значением лингвистической переменной «скорость»: очень низкая, низкая, средняя, высокая и очень высокая. Этих градаций (гранул) может быть меньше или больше. Чем больше гранулированность нечеткой информации, тем больше она приближается к математически точной оценке (не забудем, что и выраженная в традиционной форме измерительная информация всегда обладает некоторой погрешностью, а значит в определенном смысле также является нечеткой). Таким образом, например значение скорости 105 км/ч принадлежит к нечеткому множеству «высокая» со значением функции принадлежности 0.8, а к множеству «очень высокая» со значением 0.5.
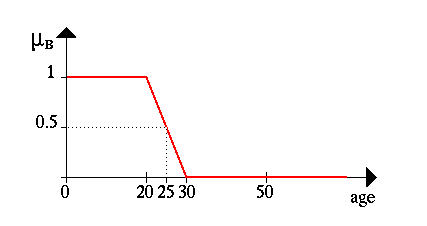
Другой пример – оценка возраста человека. Часто мы не имеем абсолютно точной информации о возрасте того или иного знакомого нам человека и поэтому, отвечая на соответствующий вопрос, вынуждены давать нечеткую оценку типа: «ему лет 30» или «ему далеко за 60» и т. п. Особенно часто используются такие значения лингвистической переменной «возраст» как: «молодой», «средних лет», «старый» и т. п. На рисунке ниже приведен графически возможный вид нечеткого множества «возраст = молодой» (очевидно, с точки зрения человека, которому самому ну никак не больше 20 лет ;)
Нечеткие числа, получаемые в результате “не вполне точных измерений”, во многом похожи (но не тождественны! см. пример с двумя бутылками) распределениям теории вероятностей, но свободны от присущих последним недостатков: малое количество пригодных к анализу функций распределения, необходимость их принудительной нормализации, соблюдение требований аддитивности, трудность обоснования адекватности математической абстракции для описания поведения фактических величин. По сравнению с точными и, тем более, вероятностными методами, нечеткие методы измерения и управления позволяют резко сократить объем производимых вычислений, что, в свою очередь, приводит к увеличению быстродействия нечетких систем.
Как уже говорилось, принадлежность каждого точного значения к одному из значений лингвистической переменной определяется посредством функции принадлежности. Ее вид может быть абсолютно произвольным. Сейчас сформировалось понятие о так называемых стандартных функциях принадлежности (см. рисунок ниже).

Стандартные функции принадлежности легко применимы к решению большинства задач. Однако если предстоит решать специфическую задачу, можно выбрать и более подходящую форму функции принадлежности, при этом можно добиться лучших результатов работы системы, чем при использовании функций стандартного вида.
Процесс построения (графического или аналитического) функции принадлежности точных значений к нечеткому множеству называется фаззификацией данных.