

РГР_ИТ_ДМ_01
.pdf3.3 Определение избыточности сообщений. Оптимальное кодирование.
Если энтропия источника сообщений не равна максимальной энтропии для алфавита с данным количеством качественных признаков (имеются в виду качественные признаки алфавита, при помощи которых составляются сообщения), то это прежде всего означает, что сообщения данного источника могли бы нести большее количество информации. Абсолютная недогруженность в расчёте на единичный символ сообщений такого источника составит:
Для определения количества «лишней» информации, которая заложена в структуре алфавита, либо в природе кода, вводится понятие
избыточности.
Избыточность, с которой мы имеем дело в теории информации, не зависит от содержания сообщения и обычно заранее известна из статистических данных.
Информационная избыточность показывает относительную недогруженность на символ алфавита и является безразмерной величиной:
Где (H / Hmax) равно — коэффициент сжатия (относительная энтропия). H и Hmax берутся относительного одного и того же алфавита.
Избыточность, обусловленная неравновероятностным распределением символов в сообщении, может быть выражена следующим образом:
Избыточность, вызванная статистической связью между символами сообщения, может быть представлена в следующем виде:
Таким образом, представление полной информационной избыточности может быть осуществлено в следующем виде:
Избыточность, которая заложена в природе данного кода, получается в результате неравномерного распределения в сообщениях качественных признаков этого кода и не может быть задана одной цифрой на основании

статистических испытаний. Так, при передаче десятичных цифр двоичным кодом максимально загруженными бывают только те символы вторичного алфавита, которые передают значения, являющиеся целочисленными степенями двойки. В остальных случаях тем же количеством символов может быть передано большее количество цифр (сообщений).
Например, тремя двоичными разрядами мы можем передать и цифру 5, и цифру 8.
Фактически, для передачи сообщения достаточно иметь длину кодовой комбинации:
Где N — общее количество передаваемых сообщений, m — количество качественных признаков.
Длина кодовой комбинации (L) может быть представлена и другим образом:
Где m1 и m2 — качественные признаки первичного и вторичного алфавитов соответственно.
Поэтому, например для цифры 5 в двоичном коде можно записать:
Однако эту цифру необходимо округлить до ближайшего целого числа (в большую сторону), так как длина кода не может быть выражена дробным числом.
В общем случае, избыточность от округления может быть выражена следующим образом:
k — округлённое до ближайшего целого значение ;
Для нашего примера:
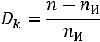
Избыточность необходима для повышения помехоустойчивости кодов и её вводят искусственно в виде добавочных nk символов. Если в коде всего n разрядов и nИ из них несут информационную нагрузку, то nk = n - nИ
характеризуют абсолютную корректирующую избыточность, а величина:
характеризует относительную корректирующую избыточность.
Для уменьшения избыточности используют оптимальные коды. При построении оптимальных кодов наибольшее распространение получили методики Шеннона – Фано и Хаффмана.
Согласно методике Шеннона – Фано построение оптимального кода ансамбля из сообщений сводится к следующему:
На первом шаге множество из сообщений располагается в порядке убывания вероятностей.
На втором шаге первоначальный ансамбль кодируемых сигналов разбивается на две группы таким образом, чтобы суммарные вероятности сообщений обеих групп были по возможности равны. Если равной вероятности в подгруппах нельзя достичь, то их делят так, чтобы в верхней части (верхней подгруппе) оставались символы, суммарная вероятность которых меньше суммарной вероятности символов в нижней части (нижней подгруппе).
На третьем шаге первой группе присваивается символ 0, а второй группе — символ 1.
На четвёртом шаге каждую из образованных подгрупп делят на две части таким образом, чтобы суммарные вероятности вновь образованных подгрупп были по возможности равны.
На пятом шаге первым группам каждой из подгрупп вновь присваивается символ 0, а вторым — 1. Таким образом, мы получаем вторые цифры кода. Затем, каждая из четырёх групп вновь делится на две равные (с точки зрения суммарной вероятности) части до тех пор, пока в каждой из подгрупп не останется по одной букве.
Полученный таким образом код называют оптимальным неравномерным кодом (ОНК).

4 Практическая часть
4.1 Содержание задания
Исходные данные: = 13 (Пример расчёта для варианта = 13)
4.2 Расчёт на основе исходных данных
Определение количества символов алфавита
Расчёт вероятности появления символов:
1 |
0,05 |
11 |
0,00909 |
2 |
0,00263 |
12 |
0,01111 |
3 |
0,00292 |
13 |
0,01389 |
4 |
0,00327 |
14 |
0,01786 |
5 |
0,00368 |
15 |
0,02381 |
6 |
0,00417 |
16 |
0,03333 |
7 |
0,00476 |
17 |
0,05 |
8 |
0,00549 |
18 |
0,08333 |
9 |
0,00641 |
19 |
0,16667 |
10 |
0,00758 |
20 |
0,5 |
Таблица 4.2.1.1 Вероятности появления символов.
4.2.1 Определение количества информации, соответствующего одному символу сообщения, составленного из данного
алфавита
Для случая, когда символы алфавита встречаются с равными вероятностями:
Для случая, когда символы алфавита встречаются в сообщении с заданными вероятностями:
Вычисление неопределённости (энтропии), приходящейся на символ алфавита для неравновероятностных алфавитов:

Вычисление неопределённости (энтропии), приходящейся на символ первичного (кодируемого) алфавита, составленного из равновероятностных и взаимонезависимых символов:
Вычисление количества информации для случая, когда символы алфавита встречаются в сообщении с заданными вероятностями:
Вычисление абсолютной недогруженности символов:
4.2.2Вычисление теоретической скорости передачи сообщений
4.2.3Вычисление избыточности сообщений, составленных из
данного алфавита
4.2.4 Построение оптимального кода сообщения
Сортировка множества из сообщений в порядке убывания вероятностей появления:
1 |
0,05 |
11 |
0,00909 |
2 |
0,16667 |
12 |
0,00758 |
3 |
0,8333 |
13 |
0,00641 |
4 |
0,05 |
14 |
0,00549 |
5 |
0,05 |
15 |
0,00476 |
6 |
0,03333 |
16 |
0,00417 |
7 |
0,02381 |
17 |
0,00368 |
8 |
0,01786 |
18 |
0,00327 |
9 |
0,01389 |
19 |
0,00292 |
10 |
0,01111 |
20 |
0,00263 |
Таблица 4.2.4.1 Сортировка множества из сообщений в порядке убывания вероятностей.
Результат построения оптимального неравномерного кода на основе разработанного вычислительного алгоритма:
№ |
Вероятность |
Код |
№ |
Вероятность |
Код |
|
символа |
символа |
|||||
|
|
|
|
|||
1 |
0,5 |
0 |
11 |
0,00909 |
1111011 |
|
2 |
0,16667 |
100 |
12 |
0,00758 |
1111100 |
|
3 |
0,8333 |
101 |
13 |
0,00641 |
11111010 |
|
4 |
0,05 |
1100 |
14 |
0,00549 |
11111011 |
|
5 |
0,05 |
1101 |
15 |
0,00476 |
11111100 |
|
6 |
0,03333 |
11100 |
16 |
0,00417 |
11111101 |
|
7 |
0,02381 |
111010 |
17 |
0,00368 |
11111110 |
|
8 |
0,01786 |
111011 |
18 |
0,00327 |
111111110 |
|
9 |
0,01389 |
111100 |
19 |
0,00292 |
1111111110 |
|
10 |
0,01111 |
1111010 |
20 |
0,00263 |
1111111111 |
Таблица 4.2.4.2 Оптимальный неравномерный код.
5Заключение
Впроцессе выполнения данной расчётно-графической работы был синтезирован оптимальный неравномерный код. Данный код имеет следующие свойства:
1.Код состоит из комбинаций различной длины;
2.Комбинации одинаковой длины не совпадают;
3.Никакие комбинации не являются началом более длинной комбинации.
Данные условия являются условиями префиксности эффективного кода, характеризующими его оптимальность.
В рамках данной расчётно-графической работы были произведены расчёты количества информации, приходящегося на символ сообщения в случае равновероятных и неравновероятных символов, определена абсолютная недогруженность символов, теоретическая скорость передачи данных и избыточность сообщений. Оптимальный код сообщения был синтезирован на основе методики Шеннона – Фано.
Кодировка символов по методике Шеннона – Фано является сравнительно оптимальной, так как символы, имеющие наибольшую вероятность появления, будут иметь наименьшую длину кодового слова.
Необходимо отметить сходство метода Шеннона – Фано и более актуального в настоящее время метода Хаффмана. Вместе с тем, метод Шеннона – Фано является менее оптимальным, по отношению к методу Хаффмана.
Алгоритм Шеннона – Фано, который был предложен Шенноном и Фанов в 1948—49 гг. независимо друг от друга, так же как и метод Хаффмана основывается на статистических исследования, т. е. на числе вхождений символов в исходный текст. Таким образом, более вероятные символы кодируются малым числом бит, а менее вероятные — большим числом бит.
Несмотря на то, что данный имеет определённую избыточность, её наличие практически не оказывает влияние на полученный результат.
6Библиографический список
1.Бауэр Ф. Л., Гооз Г. Информатика. Вводный курс: Пер. с нем. —
М.: Мир, 1990.
2.Колесник В. Д., Полтырев Г. Ш. Курс теории информации — М.:
Наука, 1982, 416 с.
3.Макаров Е. Инженерные расчёты в Mathcad 15 — Питер, 2011.
4.Использвание программных циклов в среде Mathcad — Электронный ресурс, режим доступа: http://plasma.colorado.edu/ /mathcad/0_Essentials_Program_Loops.pdf