

лекции по СУБД / лекции по СУБД / СУБД_лекции (6)
.docПараллельные СУБД
Кроме того, следует четко понимать различия, существующие между распределенными и параллельными СУБД.
Параллельная СУБД: Система управления базой данных, функционирующей с использованием нескольких процессоров и жестких дисков, что позволяет ей (если это возможно) распараллеливать выполнение некоторых операций с целью повышения общей производительности обработки.
Появление параллельных СУБД было вызвано тем фактом, что системы с одним процессором оказались не способны удовлетворять растущие требования к масштабируемости, надежности и производительности обработки данных. Применение параллельных СУБД позволяет объединить несколько маломощных машин для получения такого же уровня производительности, как и в случае одной, но более мощной машины, с дополнительным выигрышем в масштабируемости и надежности системы по сравнению с однопроцессорными СУБД.
Существуют три основных типа архитектуры параллельных СУБД представлены на рисунке ниже. К ним относятся:
-
системы с разделением памяти;
-
системы с разделением дисков;
-
системы без разделения вычислительных ресурсов.
Хотя параллельная система без разделения вычислительных ресурсов иногда рассматривается как распределенная СУБД, в такой системе распределение данных обусловлено лишь стремлением к повышению производительности. Узлы распределенной СУБД обычно разделены географически, находятся под управлением разных администраторов и соединены между собой относительно медленными сетевыми соединениями. Напротив, узлы параллельной СУБД чаще всего располагаются на одном и том же компьютере или в пределах одной и той же производственной площадки.
Системы с разделением памяти состоят из тесно связанных между собой компонентов, в число которых входит несколько процессоров, разделяющих общую системную память. Эта архитектура, называемая также архитектурой с симметричной многопроцессорной обработкой (SMP), в настоящее время получила широкое распространение. Эта архитектура обеспечивает быстрый доступ к данным для ограниченного набора процессоров (обычно не более 64). В противном случае взаимодействие по сети становится узким местом всей системы.
Системы с разделением дисков создаются из менее тесно связанных между собой компонентов. Они являются оптимальным вариантом для приложений с высокой централизацией обработки и должны обеспечивать самые высокие показатели доступности и производительности. Каждый из процессоров имеет прямой доступ ко всем совместно используемым дисковым устройствам, но обладает собственной оперативной памятью. Архитектура с разделением дисков, точно также как и архитектура без разделения вычислительных ресурсов, исключает узкие места, связанные с совместно используемой памятью. Однако, в отличие от архитектуры без разделения вычислительных ресурсов, данная архитектура не требует дополнительных издержек, связанных с физическим распределением данных по отдельным устройствам. Разделяемые дисковые системы иногда называют кластерами.
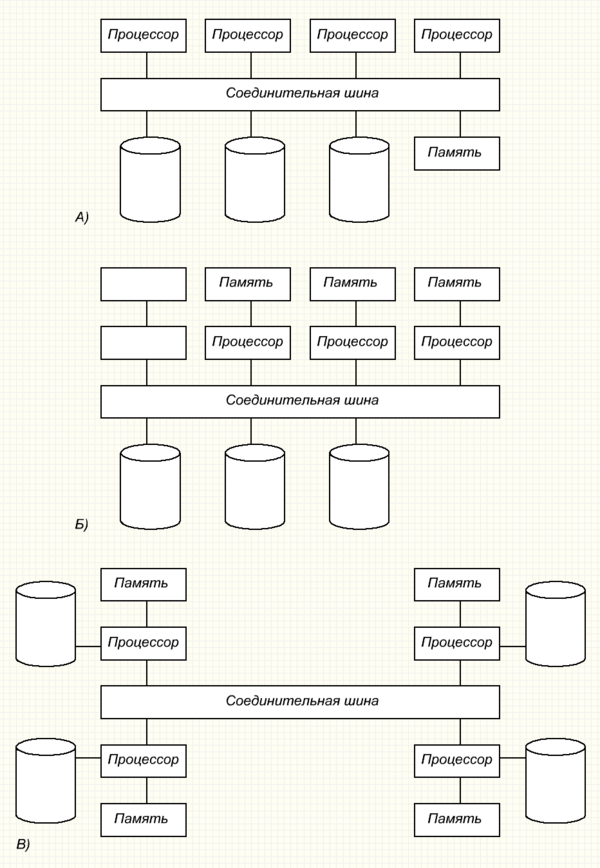
Архитектура систем баз данных с параллельной обработкой: а) с разделением памяти; б) с разделением дисков; в) без разделения
Системы без разделения вычислительных ресурсов (эту архитектуру иначе называют архитектурой с массовой параллельной обработкой) используют схему, в которой каждый процессор, являющийся частью системы, имеет свою собственную оперативную и дисковую память. База данных распределена между всеми дисковыми устройствами, подключенным к отдельным, связанным с этой базой данных вычислительным подсистемам, в результате чего все данные прозрачно доступны пользователям каждой из этих подсистем. Такая архитектура обеспечивает более высокий уровень масштабируемости, чем системы с разделяемой памятью, и позволяет легко поддерживать большое количество процессоров. Однако оптимальной производительности удается достичь только в том случае, если требуемые данные хранятся локально.
Параллельные
технологии обычно используются в случае
исключительно больших баз данных,
размеры которых могут достигать
нескольких терабайтов (![]() байт), или в системах, обеспечивающих
выполнение тысяч транзакций в секунду.
Параллельные СУБД могут использовать
различные вспомогательные технологии,
позволяющие повысить производительность
обработки сложных запросов за счет
применения методов распараллеливания
операций просмотра, соединения и
сортировки, что позволяет нескольким
процессорным узлам автоматически
распределять между собой текущую
нагрузку.
байт), или в системах, обеспечивающих
выполнение тысяч транзакций в секунду.
Параллельные СУБД могут использовать
различные вспомогательные технологии,
позволяющие повысить производительность
обработки сложных запросов за счет
применения методов распараллеливания
операций просмотра, соединения и
сортировки, что позволяет нескольким
процессорным узлам автоматически
распределять между собой текущую
нагрузку.