


3. Модели и структуры данных информационных систем
Рассматриваемые в контексте понятия «информационная система» элементы реального мира, информацию о которых мы сохраняем и обрабатываем, будем называть объектами. Объект может быть материальным (например, служащий, изделие или населенный пункт) и нематериальным (например, имя, понятие, абстрактная идея).
Набором объектов будем называть совокупность объектов, однородных с некоторой точки зрения (например, объектов нашего внимания, пусть даже и разнородных по своей внутренней природе).
Объект имеет различные свойства (например, цвет, вес, имя), которые важны для нас в то время, когда мы обращаемся к объекту (например, выбираем среди множества других) с какой-либо целью его использования. Причем свойства могут быть заданы как отдельными однозначно интерпретируемыми количественными показателями, так и словесными нечеткими описаниями, допускающими разную трактовку, зависящую, например, от точки зрения и наличных знаний воспринимающего субъекта.
Общим же фактором является то, что человек, работая с информацией, имеет дело с абстракцией, представляющей интересующий его фрагмент реального мира - той совокупностью
характеристических свойств (атрибутов), которые важны для решения его прикладной задачи. Абстрагирование – это способ упрощения совокупности фактов, относящихся к реальному объекту (по своей сути бесконечно сложному и разнообразному). При этом некоторые свойства объекта игнорируются, поскольку считается, что для решения данной прикладной задачи (или совокупности задач) они не являются определяющими и не влияют на конечный результат действий при решении.
Цель такого абстрагирования - построение конструктивного операбельного описания (рабочей модели), удобного в обработке, как для человека, так и для машины, позволяющего организовать эффективную обработку больших объемов информации, причем высокопроизводительной должна быть работа не только вычислительной системы, но и взаимодействующего с ней человека.
3.1. Семантика ИС, основанных на концепции баз данных
Как уже отмечалось, задачи информационных систем – это не только поддержка процессов планирования и управления, но и интеграция разработки и сопровождения основных и технологических объектов и процессов, диагностика, мониторинг, моделирование. Соответственно, задачи и назначение БД, как системы хранящей информацию обо всех составляющих – обеспечить информационную поддержку процессов жизненного цикла автоматизируемой системы.
68
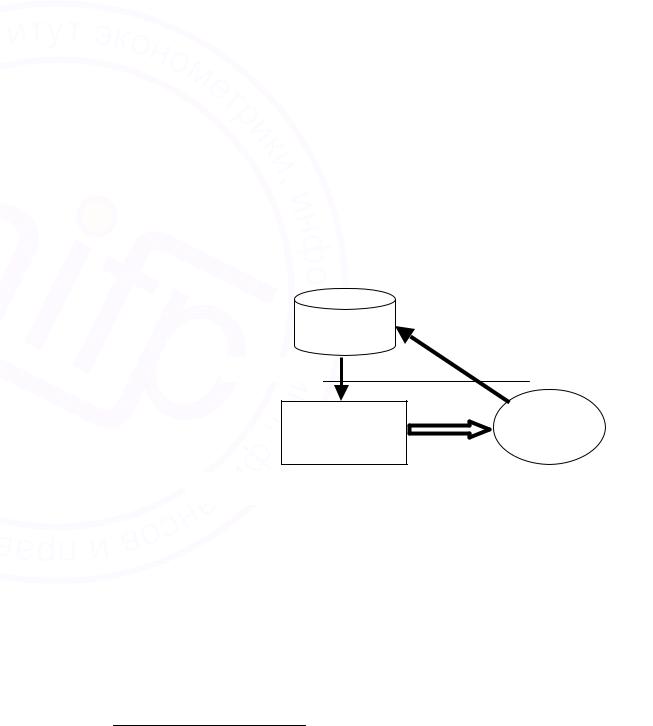
Здесь база данных, как основная информационная компонента системы управления, – это отражение реальной предметной области, «действующая» информационная модель21, которая, обеспечивая субъект информацией для принятия решения, позволяет в итоге управлять физическими объектами и процессами. Такая функциональная направленность (и, естественно, предполагающая достижение эффективности в первую очередь за счет использования именно БД) обуславливает и обратную зависимость: объекты, процессы и события ПрО выделяются таким образом, чтобы было возможно их представление в виде системы взаимосвязанных данных и процедур, удобных для их последующей (человеко-машинной!) обработки.
В каком-то смысле базу данных можно сравнить с сообщением о состоянии предметной области, воспринимаемым некоторым субъектом, задачей которого и является преобразование объектов этой ПрО, причем в своей деятельности субъект руководствуется информацией извлекаемой именно из этого «сообщения». Схема этого соотношения, приведенная на рис. 3.1, иллюстрирует еще и то, что система, преобразующая объект, принципиально является комплексной (состоящей, по крайней мере, из двух компонент, работающих с объектами разной природы: субъект преобразования взаимодействует преимущественно с материальными объектами, а БД – с информационными).
БД |
|
Управление |
|
Субъект |
Объект |
преобразования |
ПрО |
Рис. 3.1. Информационная модель преобразования
В общем случае, поскольку для сложных систем с многоуровневым представлением семантики, эффективность обработки достигается через специализированность представления объектов или процессов путем сведения представления множества обрабатываемых объектов к однородности природы и формы их представления, то для реализации эффективного межуровнего (межкомпонентного) взаимодействия (на каждом из которых объекты представлены в виде, наиболее адекватном функциональным средствам этого уровня или процесса) любая величина должна быть преобразована в соответствии с
21 Модель – лишь в том смысле, что она – представление, описание на уровне данных только некоторых аспектов, и только некоторой части реального мира, и поэтому не может быть тождественна реальным объектам. Но в тоже время БД и сама является частью реального мира.
69

«контекстом» этого уровня для получения такого ее представления, которое будет «значимо» для воспринимающего уровня, т.е. может быть обработано средствами этого уровня. Здесь «контекст» - это декларативное или, иногда, процедурное определение способа использования элементарных составляющих величины для получения значения. Например, контекст - это порядок использования байтов при преобразовании вещественного числа, представленного в двоичной форме, в символьный формат.
Соотношение понятий величина, контекст и значение приведено на рис. 3.2. Здесь значение, получаемое на первом уровне (в первой подсистеме, процессе), на следующем рассматривается в свою очередь как величина, которая будет интерпретироваться в соответствии с контекстом своего уровня22 (процесса).
Уровень 2 |
Значение |
|
Контекст Величина
Уровень 1
Значение
Контекст Величина
Рис. 3.2. Соотношение понятий «величина», «контекст» и «значение»
Таким образом, можно сказать, что значение в общем случае определяется парой <контекст, величина>. Причем, поскольку контекст и величина имеют разную природу, они должны быть представлены в вычислительной среде самостоятельными, скорее всего, разнотипными объектами.
Такое, хотя и упрощенное, представление БД как средства информационных коммуникаций, позволяет тем не менее увидеть взаимосвязь вида информации с формой ее представления и особенностью ее использования.
В этом смысле (с точки зрения способа представления и, соответственно, восприятия) в отдельный класс можно выделить
фактографическую информацию: такое представление реально существующих событий и явлений, когда они могут быть описаны как факты, задаваемые парой <имя, значение>, где имя – знак, уникально определяющий (идентифицирующий) факт в заданной предметной
22 Соотношение понятий «величина» и «значение» аналогично соотношению понятий «данные» и «информация».
70

области, и обычно не нуждающийся в явном определении или доопределении его существа; а значение – характеристика, задающая одно из множества возможных состояний.
Т.е., здесь факт (его значение) задается величиной, например, числовой для физически измеримых параметров, в том числе и логическими величинами «истина» / «ложь» для указания свершилось событие или нет23.
Можно сказать, что особенностью фактографической информации является практическая очевидность (минимальная неопределенность, не требующая использования сложных или нечетких процедур) идентификации и интерпретации «факта», как его имени, так и состояния. То есть, в этом случае контекст в достаточной степени определяется однозначно понимаемым объявлением о назначении базы данных и таким именованием полей данных, когда в качестве имени используется общепринятое, не зависящее от прикладных задач, имя свойства (и таким образом определяются характеристические признаки). Именно такое состояние предопределяет для пользователя возможность адекватного восприятия содержания: способ интерпретации данных в этом случае практически не может быть неоднозначным, причем для пользователя определение способа происходит неявно (не требует от него явных действий для определения и использования контекста). Это, с одной стороны, позволяет свести представление предметной области к точной теоретико-множественной модели, а с другой – обуславливает возможность непосредственного использования данных в задачах обработки (на уровне прикладных программ) для генерации новой информации без участия субъекта (человека), внешнего по отношению к машинной среде, обеспечивающего определение и использование контекста.
Однако большинство задач, решаемых человеком, не могут быть сведены к «фактографическому» представлению и описываются (и, соответственно, представляются в машинной среде) средствами естественного или специализированного языков, оперирующих лингвистическими переменными, значение которых может зависеть не только от контекста предметной области, но также и от контекста ближайшего окружения – значения соседних переменных. Причем, появление нового смысла (факта) не обязательно приводит к появлению новой переменной: новый факт представляется с помощью уже существующих переменных. Например, словесные определения философских или географических понятий.
В отличие от ранее рассмотренного фактографического представления, для вербальной формы представления факта (выражениями языка с использованием лингвистических переменных) характерно то, что для задания имени, значения и контекста может
23 И, следует отметить, что такая форма в наибольшей степени соответствует машинным формам представления информации.
71
использоваться единый способ и средства – лингвистические переменные одного и того же языка. Например, описание весовых свойств может быть представлено несколькими, но имеющих один смысл, вариантами предложений: «Чугунная заготовка весом 29 килограмм» или «Чугунная заготовка имеет свойство m = 29, где m – вес в килограммах».
Автоматическое приведение такого рода представлений к очевидной наилучшей для этого случая табличной форме, потребовало бы применения трудно реализуемых процедур морфологического и семантического анализа. Но, с другой стороны, выделение смысла (и генерация новой информации) обычно производится человеком, сознание которого (как среда преобразования) ориентировано именно на обработку лингвистических переменных.
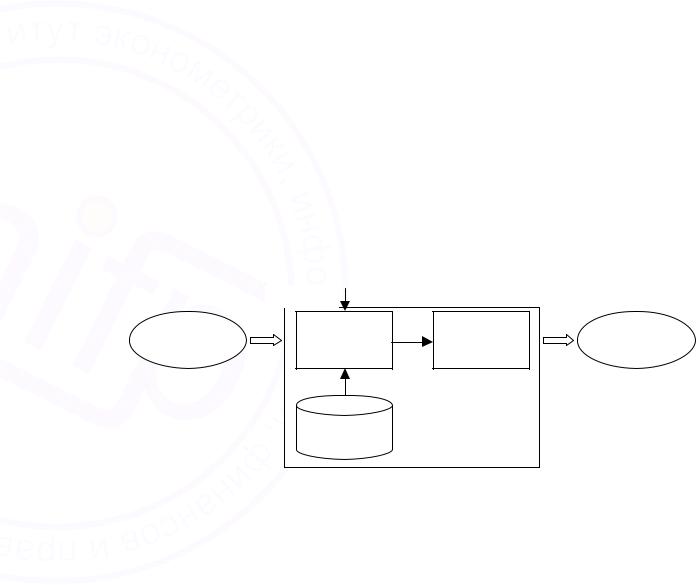
Рассматривая процесс генерации новой информации (рис. 3.3), где в качестве источника исходных данных используются БД, нужно сказать, что отбор и обработка должны быть выделены в отдельные процессы, т.к. с точки зрения общей (суммарной) эффективности один из них (обычно поиск) должен быть опосредованным - оценка полезности найденной информации производится человеком в сознание человека - внешней по отношению к машине среде, работающей со слабоструктурированной информацией эффективнее машин.
|
Контекст |
|
|
|
Постановка |
Отбор |
Обработка |
Решение |
|
исходных |
данных |
|||
задачи |
задачи |
|||
данных |
|
|||
|
|
|
||
|
База |
|
|
|
|
данных |
|
|
Рис. 3.3. Схема процесса автоматизированного решения задач
Случаи, когда информация представляется в форме не адекватной архитектуре Фон-Неймановских машин, могут быть обусловлены разными факторами. Рассмотрим следующие случаи.
1. Хорошо структурированная информация представляется в графическом или специальном формате. Например, структурные химические формулы, конструкторская документация и т.д. В этом случае для автоматической обработки требуются узко специализированные средства, что приводит к общей не унифицированности представления семантических элементов (например, графических примитивов) на уровне данных.
72