

Березкин Основы теории информации и кодирования Лабораторный практикум 2009
.pdf
|
|
|
|
|
1 |
|
− |
( X − A ) 2 |
|
|||
|
|
|
|
|
|
2 σξ |
2 |
|
||||
L(a2 ) = |
f ( X |
/ a2 ) = |
|
|
|
e |
|
, |
||||
|
σξ |
2π |
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
(4.3) |
|||
|
|
|
|
|
1 |
|
e − |
|
X 2 |
|
||
L(a1 ) = f ( X / a1 ) = |
|
|
|
2 σξ2 |
. |
|
||||||
σξ |
2π |
|
||||||||||
|
|
|
|
|
|
|
|
|
||||
Отношение правдоподобия при этом
λ= e
= e
− |
( |
X − A ) 2 + X 2 |
|||||
|
|
|
2 |
σ ξ2 |
|
||
|
|
|
|
|
|||
A 2 |
|
X |
− |
1 |
|
||
|
|
|
|
|
|
|
|
σ ξ |
2 |
A |
2 |
||||
|
|
|
|
||||
=
(4.4)
.
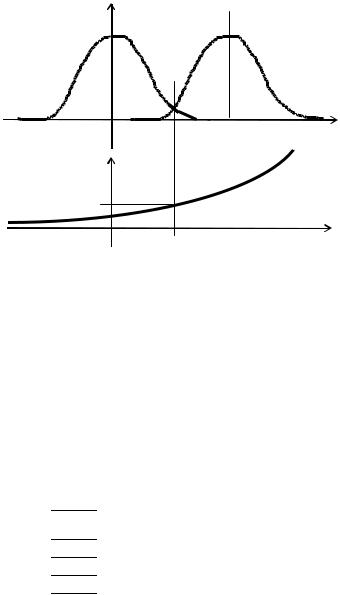
Графики функций L ( a 2 ), L ( a1 ) и λ приведены на рис. 4.3. При использовании критерия максимума правдоподобия пороговое значение λ0 =1. Тогда условие для порогового значения входного
|
A2 |
|
X 1 |
1 |
|
||
|
|
|
|
П |
− |
|
|
|
σ |
2 |
|
2 |
|||
сигнала будет иметь вид e |
|
A |
|
||||
|
ξ |
|
|
|
|
=1. Полученное уравне- |
|
ние имеет единственное решение |
Xп1 |
− |
1 |
= 0 . |
|
A |
2 |
||||
|
|
|
Таким образом, приемное устройство – это устройство сравне-
ния, |
сопоставляющее |
входной сигнал |
с пороговым уровнем |
|||
Xп1 = |
A |
. Если амплитуда входного сигнала больше уровня |
X п1 , в |
|||
2 |
||||||
|
|
|
|
|
||
принятом сигнале содержится полезный сигнал. |
|
|||||
В |
данном примере |
рассматривался |
частный случай, |
когда |
||
mξ = 0 . В процессе домашней подготовки предстоит решить ряд аналогичных задач, в которых mξ ≠ 0 , а это потребует переосмысления выражений (4.3) и (4.4).
41
L(ai )
L(a1 ) |
|
L(a2 ) |
|
|
|
X
A
λ
λ0 = 1
X
X п1
Рис. 4.3. Графики функций правдоподобия L(ai ) и отношения функций правдоподобия λ
ПОДГОТОВКА К ВЫПОЛНЕНИЮ РАБОТЫ
1.Изучить теоретический материал. Вывести выражения порогового уровня измерения сигнала для трех решающих правил.
2.Произвольным образом задать значения отличных от нуля
параметров в едином формате (табл. 4.1). Параметры P(ai ) и rij
должны отражать существо решаемой задачи и используемого решающего правила.
|
|
|
|
|
|
Таблица 4.1 |
|
|
Решающее |
A |
mξ |
σξ |
P(a1) |
P(a2 ) |
r12 |
|
r21 |
правило |
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
42

3. Вычислить пороговый уровень X п1 для обнаружения постоянного сигнала величиной A на фоне аддитивной помехи с нормальным распределением и параметрами mξ , σξ . Метод приема –
однократный отсчет. Решающее правило 1 – критерий максимума правдоподобия.
4.Вычислить X п2 при условии, что используется решающее правило 2 – критерий идеального наблюдателя.
5.Вычислить X п3 при условии, что используется решающее
правило 3 – критерий минимального риска.
6. Отразить подготовку в лабораторном отчете.
ПОРЯДОК ВЫПОЛНЕНИЯ РАБОТЫ
1.Используя обучающие и графические средства диалоговой программы, изучить особенности спектральных характеристик случайных сигналов.
2.Внимательно ознакомиться с элементами теории оптимального приема, используя предоставленные программные средства.
3. Проверить правильность вычислений пороговых уровней X пi ,i =1,3 по формулам, выведенным при решении задач в процес-
се домашней подготовки. Исходные параметры вводятся по мере запроса. В случае неудачи изучить предлагаемые диалоговой программой подсказки и скорректировать входные данные либо значения пороговых уровней. Выход из каждой задачи возможен только при правильном ее решении.
4.Провести исследование влияния априорных данных на процесс принятия решения, используя вычислительные средства задачи № 3.
5.Результаты отразить в лабораторном отчете.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Какие трудности возникают при использовании n -мерных плотностей распределения вероятностей случайного процесса для анализа систем передачи информации?
43
2.Какими усредненными характеристиками описываются обычно случайные процессы?
3.Что понимается под математическим ожиданием и дисперсией случайного процесса?
4.Что понимается под корреляционной функцией случайного процесса?
5.Какие случайные процессы называются стационарными?
6.Как обеспечивается улучшение отношения сигнал/помеха ?
7.В чем сущность основной задачи приема сигналов при наличии помех?
8.Что такое функция правдоподобия?
9.Что такое ошибки первого и второго рода?
10.Чему равна вероятность принятия правильного решения?
11.Как оценивается средняя ошибка распознавания?
12.Как оценивается средний риск распознавания?
13.В чем сущность основных критериев распознавания и их достоинства?
Лабораторная работа 5
РАЦИОНАЛЬНОЕ КОДИРОВАНИЕ ДВОИЧНОГО ИСТОЧНИКА
Цель: изучить практические методы сжатия двоичной информации в условиях частично известной статистики источника и исследовать области их применимости.
ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
Энтропия сообщений q-ных источников при одинаковом количестве n элементов может быть различной в зависимости от статистических характеристик сообщений. Энтропия максимальна, если элементы сообщений равновероятны и взаимно независимы
H = nH ( X ) = n log2 q .
Если поступление элементов сообщений не равновероятно, то энтропия снижается
44
|
q |
|
|
H = n |
−∑ p i log 2 |
p i . |
|
|
i = |
1 |
|
Еще меньшей будет энтропия при наличии коррелятивных связей между элементами
H = H ( X1 X 2 ...X n ) = H ( X n ) =
n
= ∑H ( X j / X j −1 ) .
j =1
Сообщения, энтропия которых максимальна, являются оптимальными с точки зрения наибольшего количества передаваемой информации.
Мерой количественной оценки того, насколько данные реальные сообщения по своей энтропии отличаются от соответствующих
оптимальных сообщений, является коэффициент сжатия – Kсж .
Если неоптимальные и оптимальные сообщения характеризуются одинаковой общей энтропией, то справедливы следующие соотношения:
nH ( X ) = n" H ( X ) max ,
K сж = |
H ( X ) max |
= |
n |
, |
|
H ( X ) |
n" |
||||
|
|
|
где n – число элементов неоптимальных сообщений, а n " – среднее число элементов оптимальных сообщений.
Таким образом, реальные сообщения обладают определенной избыточностью. Избыточность приводит к увеличению времени передачи сообщений, излишней загрузке аппаратуры обработки информации (канала связи).
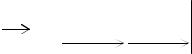
Пусть имеется двоичный источник, который порождает последовательность статистически независимых символов 1 и 0 с вероятностями p и 1− p (рис. 5.1).
Разобьем всю последовательность двоичных символов, порожденных источником, на блоки длиной n (n-блоки). Каждому блоку поставим в соответствие кодовое слово, содержащее некоторое
число ni двоичных символов (D=2), это отображение называется
кодированием.
45
Под избыточностью, приходящейся на символ исходной последовательности, будем понимать величину
|
|
|
R n ( p ) = |
|
n n |
|
− H , |
|
|
|
|
|
|
n |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
где |
nn |
– |
средняя |
длина |
кодового |
слова; |
|||
H = −p log 2 p − (1− p) log 2 (1− p) – энтропия источника.
|
|
010…1100 |
|
011…01… |
|||
ИИ |
|
n |
|
n |
|||
|
|
000…00 → |
|
n1 |
|
||
|
|
|
|||||
|
|
|
|||||
|
|
000…01 → |
|
n |
|
|
|
|
|
|
|
||||
|
|
… |
2 |
||||
|
|
|
|
nn |
|||
|
|
|
|
|
|
||
|
|
111…11 → |
|
n n |
|
||
|
|
|
2 |
|
|||
Рис. 5.1. Процесс кодирования для двоичного источника информации
Качество кодирования определяется эффективностью кодирования
Э = |
|
|
H |
= |
|
H |
= HK сж |
||
|
|
|
|
|
|
||||
n log 2 D |
n n / n |
||||||||
|
|
|
|||||||
или, более строго, избыточностью кодирования
Rn = sup Rn ( p) .
0< p <1
Сокращение избыточности Rn позволяет выделять наиболее
существенные данные, т.е. только ту часть информации, которая необходима адресату. Такое техническое решение получило назва-
ние сжатие данных.
Существует большое количество различных методов сокращения объемов передаваемых и хранимых данных. Эти методы различаются по ряду признаков: они могут быть необратимыми, обратимыми и квазиобратимыми; ориентированными на аналоговый или дискретный источник; адаптивными или неадаптивными; ра-
46
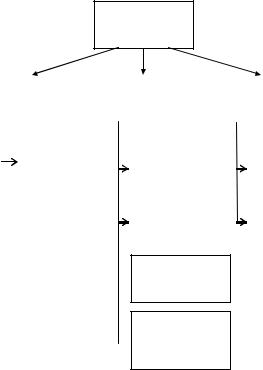
ботать в условиях известных или неизвестных статистических характеристик источника сообщений.
Классификация обратимых методов сжатия по статистике источника (к обратимому сжатию данных относятся методы, позволяющие восстановить на приемном конце исходную последовательность с абсолютной точностью) приведена на рис. 5.2.
Методы сжатия дискретной информации
Статистика |
|
Статистика |
|
Статистика |
|
||||||
не известна |
|
известна |
|
известна |
|
||||||
|
|
|
|
частично |
|
полностью |
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
Универсальное |
|
Кодирование |
|
|
Кодирование |
||||
|
|
кодирование |
|
|
длин серий |
|
|
по методу |
|||
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
Шеннона-Фано |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Адресно- |
|
|
Оптимальное |
||
|
|
|
|
|
|
позиционное |
|
|
кодирование |
||
|
|
|
|
|
|
кодирование |
|
|
(код Хаффмана) |
||
Итерации  простых
простых
подстановок
Адаптивное кодирование в  разрядной плоскости
разрядной плоскости
Рис. 5.2. Классификация обратимых методов сжатия дискретной информации
Если источник двоичных сообщений имеет низкую энтропию (H<<1), это означает, что сообщение состоит из последовательности частых символов (например, нулей), вероятность появления которых близка к единице, и редких символов (например, единиц) с небольшой вероятностью появления. В таких случаях обычно используется способ кодирования исходной последовательности,
47
заключающийся в представлении кодом длины серии входящих в нее последовательностей высоковероятных однотипных символов (рис. 5.3). Такой способ получил название метод кодирования длин серий (КДС).
|
|
|
|
n |
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
ИИ |
|
|
1010...01 |
|
|
|
0101...11 |
0100... |
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
№ |
|
Код |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
1 |
|
|
1 |
|
1 |
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
k |
k |
|
|
|||||||||
|
Серии |
01 |
|
|
2 |
|
2 |
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
001 |
|
|
3 |
|
3 |
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
k = ]log2 (n +1)[ |
||||||||||||
|
|
|
... |
|
|
|
... |
n |
|
||||||||||
|
|
|
000...001 |
|
|
|
n |
|
|
|
|
|
|
|
|||||
|
|
|
000...000 |
|
|
|
n+1 |
0 |
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 5.3. Процесс кодирования по методу КДС
Метод адресно-позиционного кодирования (АПК) заключается в переходе от передачи высоковероятных символов сообщения к передаче маловероятных символов и их местоположения в фиксированном интервале. Исходное сообщение, представляющее собой последовательность двоичных символов, разбивается на фиксированные интервалы-отрезки по n символов в каждом. Внутри отрезка символы можно пронумеровать, обозначив тем самым позицию (или адрес) каждого из них. При монотонно возрастающем порядке нумерации адрес маловероятного символа сообщения указывает на "расстояние" его от начала отрезка, т.е. является координатой. Поэтому рассматриваемый способ рационального кодирования сообщений иногда называется координатным (рис. 5.4).
Отличие передачи позиций маловероятных символов от передачи кодов длин серий высоковероятных символов сообщения в том, что если в КДС положение очередного маловероятного символа определяется по отношению к предыдущему, то в АПК – относительно некоторых фиксированных элементов последовательности (например, начала отрезка).
48
|
|
|
n |
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
0101... 0... 1 |
|
0100...11 |
|
|
0010... |
|
|||||
ИИ |
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
k |
|
k |
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
k = |
]log2 (n +1)[ |
|
|||
Рис. 5.4. Процесс кодирования по методу АПК
Метод итерации простых подстановок (ИПП – метод Блоха)
заключается в многократном повторении простейшего алгоритма кодирования (1-p >> p)
00 → 0
01 → 11
1 → 10 .
Эта операция рекуррентно повторяется до тех пор, пока она приносит желаемый эффект – уменьшается общее число символов в данной последовательности (рис. 5.5).
0 0 0 0 0 1 0 0 0 0 - 10
0 |
0 1 |
1 0 |
0 |
- 6 |
|
0 |
10 |
10 |
0 |
- 6 |
Результат |
1 |
1 1 |
1 |
0 • |
- 5 |
сжатия |
|
|||||
10 |
10 10 10 |
0 |
- 9 |
|
|
Рис. 5.5. Процесс кодирования по методу ИПП
Если последовательность двоичных разрядов передаваемого сообщения разбить на группы, а затем к одноименным разрядам
49
всех групп в зависимости от статистики входящих в нее символов применить какой-либо из описанных выше методов статистического кодирования, то можно получить более компактное описание некоторых из этих совокупностей разрядов. Такая адаптивная операция сокращения первоначального объема сообщения называется
кодированием в плоскости разряда.
Для случая статистической неизвестности было предложено кодирование, названное впоследствии универсальным, такое, что Rn →0 при n → ∞ .
Рассмотрим один из методов универсального кодирования (УК – метод Бабкина). Пусть в n-блоке имеется k единиц и (n-k) нулей.
Пронумеруем последовательно нули и единицы, встречающиеся
вn-блоке. Пусть i1 , i 2 , . . . , i k — номера позиций единиц. Положим
b |
|
= |
i1 |
−1 |
+ |
i2 |
−1 |
+ + |
ik |
−1 |
, |
k |
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
1 |
|
|
2 |
|
|
k |
|
где ν |
|
– биномиальный коэффициент, причем полагаем ν |
|
= 0 |
||
|
|
|
|
|
|
|
|
μ |
|
μ |
|
||
при ν < μ. В этом случае справедливы следующие утверждения:
1.0 ≤ b k ≤ n − 1 .
k
2.Соответствие между n-блоками и парами чисел (k , bk ) вза-
имно однозначно.
Тогда кодовое слово, соответствующее n-блоку, определяется как упорядоченная пара двоичных наборов (k , bk ). При этом длина кодового слова
ln ,k |
= ]log 2 |
|
n |
, |
(n + 1)[+ log 2 |
|
|||
|
|
|
k |
|
где ]x[ – наименьшее большое целое.
Пример. Пусть n = 8 и последовательность, порожденная источником, имеет вид:
50