

Зайцев Применение методов Дата Мининг для поддержки процессов управления ИТ-услугами.Учебное пособие 2009
.pdfРис. 2.4. Дерево Т2.
Минимум хранится в узле t1, поэтому обрезаем в t1 и получаем корень дерева (Т3 = { t1}). На этом процесс отсечения заканчивается.
Полученная последовательность значений 
 имеет вид:
имеет вид:
 1 = 0,
1 = 0,  2 = 1/20,
2 = 1/20,  3 = 2/10.
3 = 2/10.
В итоге Т1 является лучшим деревом для 
 [0, 1/20), Т2 – для
[0, 1/20), Т2 – для

 [1/20, 2/10) и Т3 = { t1} при
[1/20, 2/10) и Т3 = { t1} при 
 [2/10,
[2/10, 

 ).
).
Выбор финального дерева. Итак, имеем последовательность деревьев, из которой необходимо выбрать лучшее, то, которое будем использовать в дальнейшем. Наиболее простым способом является выбор финального дерева посредством тестирования последовательности деревьев на тестовой выборке. В этом случае дерево, дающее минимальную ошибку классификации, и будет лучшим.
Однако, это не единственно возможный путь, так как используемая нами процедура отсечения дерева использовала только данные, на которых строилось первоначальное дерево. Даже не сами данные, а количество примеров каждого класса, которое "прошло" через узел.
Естественно, качество тестирования во многом зависит от объема тестовой выборки и «равномерности» данных, которые попали и в обучающую, и в тестовую выборки.
Часто можно наблюдать, что последовательность деревьев дает ошибки близкие друг к другу. Этот случай изображен на рис. 2.5. Представленная длинная плоская последовательность очень чувствительна к данным, которые будут выбраны в качестве тестовой выборки. Чтобы уменьшить эту нестабильность CART использует
41

1-SE правило, т.е. выбирает минимальное по размеру дерево с Rts в пределах интервала [min Rts, min min Rts + SE] (где Rts – ошибка классификации дерева; SE – стандартная ошибка, являющаяся оценкой реальной ошибки
,
где ntest – число примеров в тестовой выборке). Данная ситуация проиллюстрирована на рис. 2.5.
Рис. 2.5. Зависимость ошибки от размера дерева
Перекрестная проверка. Перекрестная проверка (V-fold crossvalidation) – самая оригинальная и сложная часть алгоритма CART. Этот путь выбора финального дерева используется тогда, когда набор данных для обучения мал или каждая запись в нем по своему «уникальна» так, что мы не можем выделить выборку для обучения
ивыборку для тестирования.
Втаком случае строим дерево на всех данных и последова-
тельно вычисляем  1,
1,  2, …,
2, …,  k и Т1 > Т2 > … > Тn. Обозначим через Тk – наименьшее минимизируемое поддерево для
k и Т1 > Т2 > … > Тn. Обозначим через Тk – наименьшее минимизируемое поддерево для 
 [
[ k,
k,  k+1).
k+1).
Теперь мы хотим выбрать дерево из последовательности, уже просмотрев все имеющиеся данные. Нюанс заключается в том, что
42

мы собираемся вычислить ошибку дерева Тk из последовательности косвенным путем.
Шаг 1. Установим
β1 = 0, β2 =  α2α3, β3 =
α2α3, β3 =  α3α4,....., βN − 1 =
α3α4,....., βN − 1 =  αN − 1αN , βN = ∞.
αN − 1αN , βN = ∞.
Считается, что  k будет типичным значением для [
k будет типичным значением для [ k,
k, 
 k+1) и,
k+1) и,
следовательно, как значение соответствует Тk.
Шаг 2. Разделим весь набор данных на V групп одинакового размера G1, G2, …, Gv. Обычно [13] рекомендуется брать V = 10. Затем для каждой группы Gi вычислим:
•последовательность деревьев с помощью описанного выше
механизма отсечения на всех данных, исключая Gi., и определим значения T(i)(  1), T(i)(
1), T(i)(  2), …, T(i)(
2), …, T(i)(  N) для этой последовательности;
N) для этой последовательности;
•ошибку дерева T(i)<  k) на Gi. Здесь T(i)(
k) на Gi. Здесь T(i)(  k) означает наи-
k) означает наи-
меньшее минимизированное поддерево из последовательности, построенное на всех данных, исключая Gi для 
 =
= 
 k.
k.
Шаг 3. Для каждого  k просуммируем ошибку T(i)(
k просуммируем ошибку T(i)(  k) по всем Gi
k) по всем Gi
(i = 1, …, V). Пусть  h будет с наименьшей общей ошибкой. Так как
h будет с наименьшей общей ошибкой. Так как

 h соответствует дереву Тh, мы выбираем Тh из последовательности,
h соответствует дереву Тh, мы выбираем Тh из последовательности,
построенной на всех данных в качестве финального дерева. Показатель ошибки, вычисленный с помощью перекрестной проверки можно использовать как оценку ошибки дерева.
Альтернативным путем выбора финального дерева из последовательности является использование правила 1-SE на последнем шаге.
Алгоритм обработки пропущенных значений. Большинство алгоритмов Data Mining предполагает отсутствие пропущенных значений. В практическом анализе это предположение часто является неверным. Вот только некоторые из причин, которые могут привести к пропущенным данным:
•респондент не желает отвечать на некоторые из поставленных вопросов;
•ошибки при вводе данных;
•объединение не совсем эквивалентных наборов данных. Наиболее общее решение – отбросить данные, которые содер-
жат один или несколько пустых атрибутов. Однако это решение имеет свои недостатки.
43
Смещение данных. Если отброшенные данные лежат несколько «в стороне» от оставленных, тогда анализ может дать предубеждённые результаты.
Потеря мощности. Может возникнуть ситуация, когда придется отбросить много данных. В таком случае точность прогноза сильно уменьшится.
Если мы хотим строить и использовать дерево на неполных данных, то необходимо получить ответы на следующие вопросы:
•как определить качество разбиения;
•в какую ветвь необходимо послать наблюдение, если пропущена переменная, на которую приходится наилучшее разбиение (построение дерева и тренировка)?
Заметим, что наблюдение с пропущенной меткой класса бесполезно для построения дерева и будет отброшено.
Чтобы определить качество разбиения, алгоритм CART просто игнорирует пропущенные значения. Это «дает ответ» на первый вопрос, но необходимо ещё определить, по какому пути посылать наблюдение с пропущенной переменной, содержащей наилучшее разбиение. С этой целью CART вычисляет так называемое "суррогатное" разбиение. Оно создает наиболее близкие к лучшему подмножества примеров в текущем узле. Чтобы определить значение альтернативного разбиения как суррогатного, создадим кросстаблицу (табл. 2.1).
Таблица 2.1
|
Кросс-таблица |
|
|
|
|
p(l*, l") |
|
p(l*, r") |
p(r*, l") |
|
p(r*, r") |
В этой таблице p(l*, l") обозначает пропорцию случаев, которые будут посланы в левую ветвь при лучшем s* и альтернативном разбиении s" и аналогично для p(r*, r"), так p(l*, l") + p(r*, r") – пропорция случаев, которые посланы в одну и ту же ветвь для обоих разбиений. Это мера сходства разбиений, или иначе, это говорит, насколько хорошо мы предсказываем путь, по которому послан случай наилучшим разбиением, смотря на альтернативное разбиение. Если p(l*, l") + p(r*, r") < 0.5, тогда можем получить лучший
44

суррогат, поменяв левую и правую ветви для альтернативного разбиения. Кроме того, необходимо заметить, что пропорции в табл. 2.1 вычислены, когда обе переменные (суррогатная и альтернативная) наблюдаемы.
Рис. 2.6. Лучшее и суррогатное разбиения
Альтернативные разбиения с p(l*, l") + p(r*, r") > max(p(l*), p(r*)) отсортированы в нисходящем порядке сходства. Теперь, если пропущена переменная лучшего разбиения, тогда используем первую из суррогатных в списке, если пропущена и она, тогда следующую и т.д. Если пропущены все суррогатные переменные,
используем max(p(l*), p(r*)).
На рис. 2.6 изображен пример лучшего и альтернативного разбиения. Каково значение альтернативного разбиения по супружескому статусу как суррогатного? Видно, что примеры 6 и 10 оба разбиения послали влево. Следовательно, p(l*, l") = 2/7. Оба разбиения послали примеры 1 и 4 направо – p(r*, r") = 2/7. Его значе-
ние как суррогатного есть p(l*, l") + p(r*, r") = 2/7 + 2/7 = 4/7. Так как max(p(l*), p(r*)) = 4/7, то разбиение по супружескому статусу не является хорошим суррогатным разбиением.
Регрессия. Построение дерева регрессии во многом схоже с деревом классификации. Сначала мы строим дерево максимального размера, затем обрезаем дерево до оптимального размера.
Основное достоинство деревьев по сравнению с другими методами регрессии – возможность работать с многомерными задачами (рис. 2.7) изадачами, вкоторыхприсутствуетзависимостьвыходнойпеременной отпеременнойилипеременныхкатегориальноготипа[20].
45

Основная идея – разбиение всего пространства на прямоугольники [25], необязательного одинакового размера, в которых выходная переменная считается постоянной. Заметим, что существует сильная зависимость между объемом обучающей выборки и ошибкой ответа дерева.
Рис. 2.7. Пример двумерной задачи
Процесс построения дерева происходит последовательно. На первом шаге мы получаем регрессионную оценку просто как константу по всему пространству примеров. Константу считаем просто как среднее арифметическое выходной переменной в обучающей выборке. Итак, если мы обозначим все значения выходной переменной как Y1, Y2, …, Yn , тогда регрессионная оценка получается в виде:

 ,
,
где R – пространство обучающих примеров, n – число примеров, IR(x) – индикаторная функция пространства – фактически, набор правил, описывающих попадание переменной x в пространство. Мы рассматриваем пространство R как прямоугольник. На втором
46
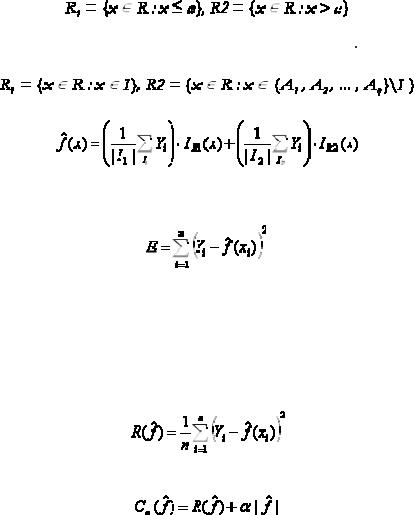
шаге делим пространство на две части. Выбирается некоторая переменная xi и, если переменная числового типа, тогда определяем

 .
.
Если xi – категориального типа с возможными значениями A1, A2, …, Aq, тогда выбирается некоторое подмножество I 
 { A1, …, An} и далее определяем
{ A1, …, An} и далее определяем
.
Регрессионная оценка принимает вид:

 ,
,
где I1 = {i, xi  R1} и | I1| – число элементов в I1.
R1} и | I1| – число элементов в I1.
Как выбрать лучшее разбиение? В качестве оценки здесь служит сумма квадратов разностей:
 .
.
Выбирается разбиение с минимальной суммой квадратов разностей.
Продолжаем разбиение до тех пор, пока в каждом подпространстве не останется малое число примеров или сумма квадратов разностей не станет меньше некоторого порога.
Отсечение, выбор финального дерева. Эти операции происхо-
дят аналогично операции построения дерева классификации. Единственное отличие – определение ошибки ответа дерева:
или, иначе говоря, среднеквадратичной ошибки ответа. Стоимость дерева при этом равна:
.
Другие операции происходят аналогично ранее описанным при построении дерева классификации.
47

3. Алгоритмы нахождения ассоциативных правил
3.1. Понятие ассоциативного правила
Определение. Пусть I = {i1, i2, i3, …, in} – множество (набор) элементов. Пусть D – множество транзакций, где каждая транзакция T – набор элементов из I, T 
 I. Каждая транзакция представляет собой бинарный вектор, где t[k] = 1, если ik элемент присутствует в транзакции, иначе t[k] = 0. Мы говорим, что транзакция T содержит
I. Каждая транзакция представляет собой бинарный вектор, где t[k] = 1, если ik элемент присутствует в транзакции, иначе t[k] = 0. Мы говорим, что транзакция T содержит
X – некоторый набор элементов из I, если X |
|
|
T. Ассоциативным |
|||||
|
||||||||
|
||||||||
правилом называется импликация X |
|
Y, где X |
|
I, Y |
|
I и X Y = |
||
|
|
|
||||||
|
||||||||
|
|
|
||||||
= 
 . Правило X
. Правило X  Y имеет поддержку s (support), если s% транзакций из D содержат X
Y имеет поддержку s (support), если s% транзакций из D содержат X 
 Y, supp(X
Y, supp(X  Y) = supp (X Y). Достоверность правила показывает какова вероятность того, что из X следует Y. Правило X
Y) = supp (X Y). Достоверность правила показывает какова вероятность того, что из X следует Y. Правило X  Y справедливо с достоверностью c (confidence), если c% транзакций из D, содержащих X, также содержат Y, conf(X
Y справедливо с достоверностью c (confidence), если c% транзакций из D, содержащих X, также содержат Y, conf(X  Y) = supp(X Y)/supp(X).
Y) = supp(X Y)/supp(X).
Проанализируем это на конкретном примере: «75% транзакций, содержащих хромосому типа 1, также содержат хромосому типа 2. 3% от общего числа всех транзакций содержат оба типа хромосом». 75% – это достоверность (confidence) правила, 3% это поддержка (support), иными словами «Хромосома типа 1»  «Хромосома типа 2» с вероятностью 75%.
«Хромосома типа 2» с вероятностью 75%.
Другими словами, целью анализа является установление следующих зависимостей: если в транзакции встретился некоторый набор элементов X, то на основании этого можно сделать вывод о том, что другой набор элементов Y также же должен появиться в этой транзакции. Установление таких зависимостей дает нам возможность находить очень простые и интуитивно понятные правила.
Алгоритмы поиска ассоциативных правил предназначены для нахождения всех правил X  Y, причем поддержка и достоверность этих правил должны быть выше некоторых наперед определенных порогов [21, 31], называемых соответственно минимальной поддержкой (minsupport) и минимальной достоверностью
Y, причем поддержка и достоверность этих правил должны быть выше некоторых наперед определенных порогов [21, 31], называемых соответственно минимальной поддержкой (minsupport) и минимальной достоверностью
(minconfidence).
Задача нахождения ассоциативных правил разбивается на две подзадачи:
48

Нахождение всех наборов элементов, которые удовлетворяют порогу minsupport. Такие наборы элементов называются часто встречающимися.
Генерация правил из полученных в п. 1 наборов элементов с достоверностью, удовлетворяющей порогу minconfidence.
Одним из первых алгоритмов, эффективно решающих подобный класс задач, является алгоритм APriori. Кроме этого алгоритма в последнее время был разработан ряд других алгоритмов: DHP,
Partition, DIC и др.
Значения параметров «минимальная поддержка» и «минимальная достоверность» выбираются таким образом, чтобы ограничить количество найденных правил. Если поддержка имеет большое значение, то алгоритмы будут находить правила, хорошо известные аналитикам или настолько очевидные, что нет никакого смысла проводить такой анализ. С другой стороны, низкое значение поддержки ведет к генерации огромного количества правил, что, конечно, требует существенных вычислительных ресурсов. Тем не менее, большинство интересных правил находится именно при низком значении порога поддержки. Хотя слишком низкое значение поддержки ведет к генерации статистически необоснованных правил.
Поиск ассоциативных правил совсем не тривиальная задача, как может показаться на первый взгляд. Одна из проблем – алгоритмическая сложность при нахождении часто встречающих наборов элементов, т.к. с ростом числа элементов в I (| I |) экспоненциально растет число потенциальных наборов элементов.
Обобщенное ассоциативное правило. При поиске ассоциатив-
ных правил, мы предполагали, что все анализируемые элементы однородны. Однако не составит большого труда дополнить транзакцию информацией о том, в какую группу входит элемент и построить иерархию элементов. Приведем пример такой группировки (таксономии) в виде иерархической модели.
Пусть нам дана база транзакций D и известно, в какие группы (таксоны) входят элементы. Тогда можно извлекать из данных правила, связывающие одни группы с другими группами, отдельные элементы групп с целыми группами и т.д.
Определение. Обобщенным ассоциативным правилом [16] называется импликация X  Y, где X
Y, где X 
 I, Y
I, Y 
 I и X Y =
I и X Y = 
 и где ни один из элементов, входящих в набор Y, не является предком ни
и где ни один из элементов, входящих в набор Y, не является предком ни
49

одного элемента, входящего в X. Поддержка и достоверность подсчитываются так же, как и в случае ассоциативных правил (см. определение выше).
Введение дополнительной информации о группировке элементов в виде иерархии даст следующие преимущества:
•поможет установить ассоциативные правила не только между отдельными элементами, но и между различными уровнями иерархии (группами);
•отдельные элементы могут иметь недостаточную поддержку, но в целом группа может удовлетворять порогу minsupport.
Для нахождения таких правил можно использовать любой из вышеназванных алгоритмов. При этом каждую транзакцию нужно дополнить всеми предками каждого элемента, входящего в транзакцию. Однако, применение «в лоб» этих алгоритмов неизбежно приведет к определенным проблемам:
•элементы на верхних уровнях иерархии стремятся к значительно большим значениям поддержки по сравнению с элементами на нижних уровнях;
•с добавлением в транзакции групп увеличилось количество атрибутов и, соответственно, размерность входного пространства. Это усложняет задачу, а также ведет к генерации большего количества правил;
•появляются избыточные правила, противоречащие определению обобщенного ассоциативного правила, например, «Хромосома типа 1»  «Хромосомы». Очевидно, что практическая ценность такого «открытия» нулевая при 100% достоверности. Следовательно, нужны специальные операторы, удаляющие подобные избыточные правила.
«Хромосомы». Очевидно, что практическая ценность такого «открытия» нулевая при 100% достоверности. Следовательно, нужны специальные операторы, удаляющие подобные избыточные правила.
Для нахождения обобщенных ассоциативных правил желательно использование специализированного алгоритма (один из которых представлен ниже), который устраняет вышеописанные проблемы и к тому же работает быстрее, чем стандартный алгоритм
APriori.
Группировать элементы можно не только по вхождению в определенную группу, но и по другим характеристикам, например по цене (дешево, дорого), бренду и т.д.
Численные ассоциативные правила. При поиске ассоциатив-
ных правил, задача была существенно упрощена. По сути все сво-
50