

Зайцев Применение методов Дата Мининг для поддержки процессов управления ИТ-услугами.Учебное пособие 2009
.pdfФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ ЯДЕРНЫЙ УНИВЕРСИТЕТ «МИФИ»
К.С. Зайцев
Применение методов Data Mining для поддержки процессов управления IT-услугами
Учебное пособие
Москва 2009
УДК 004.4(075)+ 004.65(075) + 007.51(075) ББК 32.973-018.2я7+32.973.26-018.2я7+30.17я7 З-17
Зайцев К.С. Применение методов Data Mining для поддержки процессов управления IT-услугами: учебное пособие. – М.: МИФИ, 2009. – 96 с.
Учебное пособие ориентировано на студентов, специализирующихся по направлению «Прикладная математика», в части практического применения технологий глубокого анализа (Data Mining) структурированных хронологических данных при решении задач из области управления деятельностью IT-служб крупных предприятий (IT Service Management) и социальных сетей. В пособии описаны наиболее популярные сегодня методы глубокого анализа данных (методы анализа временных рядов, граничные методы, методы деревьев решений и др.) и области их эффективного использования; исследованы программные продукты Data Mining, а также приведены примеры решения конкретных практических задач анализа из области ITSM.
Предназначено как для студентов старших курсов, так и для аспирантов и научных работников, специализирующихся в области технологий организации и систематизации контента для добычи новых знаний, а также технологий параллельной и распределенной обработки данных.
Рецензент д-р физ.-мат. наук, проф. О.В. Нагорнов
Рекомендовано редсоветом МИФИ в качестве учебного пособия
ISBN 978-5-7262-1150-3 |
© Национальный исследовательский |
|
ядерный университет «МИФИ», 2009 |
Редактор Н.Н. Антонова
Подписано в печать 22.05.2009. Формат 60х84 1/16
П.л. 6,0. Уч.-изд.л. 6,0. Тираж 100 экз.
Изд. № 050-1. Заказ № 287
Национальный исследовательский ядерный университет «МИФИ». Типография МИФИ.
115409, Москва, Каширское шоссе, 31
|
ОГЛАВЛЕНИЕ |
|
Введение......................................................................................................................... |
4 |
|
1. Методы анализа структурированных данных |
|
|
с использованием технологии Data Mining.............................................................. |
5 |
|
1.1. |
Анализ временных рядов............................................................................... |
5 |
1.2. |
Граничные методы.......................................................................................... |
7 |
1.3. |
Деревья решений. .......................................................................................... |
9 |
1.4. |
Иерархические методы кластерного анализа............................................. |
11 |
1.5. |
Неиерархические методы кластерного анализа......................................... |
11 |
1.6. |
Методы рассуждений на основе аналогичных случаев............................. |
13 |
1.7. |
Линейная регрессия...................................................................................... |
14 |
1.8. |
Логистическая регрессия.............................................................................. |
14 |
1.9. |
Наивная байесовская классификация.......................................................... |
16 |
1.10. |
Нейронные сети............................................................................................ |
17 |
1.11. |
Поиск ассоциативных правил...................................................................... |
18 |
2. Алгоритмы нахождения деревьев решений....................................................... |
18 |
|
2.1. |
Описание дерева решений ........................................................................... |
18 |
2.2. |
Анализ возможностей и ограничений метода деревьев решений............. |
23 |
2.3. |
Алгоритм С 4.5.............................................................................................. |
24 |
2.4. |
Алгоритм CART............................................................................................ |
32 |
3. Алгоритмы нахождения ассоциативных правил.............................................. |
48 |
|
3.1. Понятие ассоциативного правила................................................................... |
48 |
|
3.2.Анализ возможностей и ограничений метода поиска
|
ассоциативных правил.................................................................................. |
51 |
3.3. |
Алгоритм Apriori........................................................................................... |
52 |
3.4. Выявление обобщенных ассоциативных правил....................................... |
58 |
|
3.5. Алгоритм вычисления обобщенных ассоциативных правил.................... |
63 |
|
3.6. Улучшенный алгоритм поиска часто встречающихся множеств............. |
66 |
|
3.7. |
Прогноз развития.......................................................................................... |
68 |
4. Программные продукты, реализующие технологию Data Mining................. |
70 |
|
5. Управление ИТ-услугами ..................................................................................... |
76 |
|
5.1. |
Процессы управления ИТ-услугами............................................................ |
76 |
5.2. |
Процесс управления инцидентами.............................................................. |
77 |
5.3. |
Процесс управления проблемами................................................................ |
78 |
5.4. |
Процесс управления изменениями.............................................................. |
79 |
5.5. Процесс управления активами и конфигурациями.................................... |
80 |
|
6. Практическое применение методов Data Mining в задачах ITSM ................. |
81 |
|
6.1. Анализ причин нарушения сроков выполнения заявок............................. |
81 |
|
6.2. |
Анализ причин нарушения сроков выполнения нарядов.......................... |
85 |
6.3.Анализ инцидентов системы автоматизации
процессов управления ИТ-услугами........................................................... |
90 |
Контрольные вопросы............................................................................................... |
94 |
Список литературы.................................................................................................... |
95 |
3
Введение
Сегодня для многих специалистов по обработке информации стало очевидным, что в сверхбольших массивах (десятки и сотни миллионов записей) хронологически накопленных данных, хранимых в электронных хранилищах (data warehouse) крупных государственных организаций и промышленных компаний содержится значительный скрытый потенциал знаний, способных повысить эффективность их коммерческой и производственной деятельности [9, 14]. Поэтому задача извлечения этих знаний из ранее накопленных данных является достаточно актуальной.
Традиционная математическая статистика, долгое время претендовавшая на роль главного инструмента анализа данных, сегодня пасует перед возникшими проблемами добычи новых знаний из больших объемов структурированных оперативных данных [5, 6]. Методы математической статистики оказались полезными главным образом для проверки заранее сформулированных гипотез и для «грубого» разведочного анализа новых закономерностей, составляющего основу оперативной аналитической обработки дан-
ных OLAP (online analytical processing) [9]. На передний план вы-
двинулись иные методы и технологии анализа данных, получившие название Data Mining (добыча новых данных) направленные на выявление скрытых закономерностей различного типа.
Понятие Data Mining можно определить как один из процессов поддержки принятия решений, основанный на поиске в накопленных в хранилищах хронологических данных скрытых закономерностей (шаблонов информации) [9]. С другой стороны, Data Mining – технология, которая предназначена для поиска в больших объемах данных неочевидных, объективных и полезных на практике закономерностей [29].
Исходя из приведенных определений, появляется реальная возможность, используя методы Data Mining при обработке информации баз данных, получать новые закономерности, связывающие накопленные оперативные данные, и затем применять их при при-
4
нятии управленческих и иных решений в государственных организациях федерального уровня, крупных компаниях и корпорациях.
Однако среди множества существующих на данный момент методов Data Mining, лишь некоторые представляют найденную информацию о скрытых знаниях в виде, пригодном для восприятия и усвоения человеком. Поэтому главное внимание в системах поддержки принятия решений человеком должно быть обращено на нахождение и исследование именно таких методов. Часто в качестве удобной формы представления найденных зависимостей используется представление информацииввиделогическихправил«если-то».
В настоящем учебном пособии производится исследование методов Data Mining, ориентированных на получение информации о скрытых знаниях в пригодном для восприятия и усвоения человеком виде. Кроме этого, исследуются области эффективного использования и ограничения этих методов при решении конкретных задач глубокого анализа данных с целью выявления скрытых закономерностей. В качестве примера анализируются данные, хранимые системой HP Service Desk – одной из крупных коммерческих компаний.
1.Методы анализа структурированных данных
сиспользованием технологии Data Mining
Данный раздел посвящен анализу популярных методов Data Mining и их соответствия критерию получения информации о скрытых знаниях в пригодном для усвоения человеком виде, т.е. в виде правил «если-то».
1.1.Анализ временных рядов
Вотличие от анализа случайных выборок, анализ временных рядов [9] основывается на предположении, что последовательные значения в файле данных наблюдаются через равные промежутки времени (тогда как в других методах нам не важна и часто не интересна привязка наблюдений ко времени).
Большинство регулярных составляющих временных рядов принадлежит к двум классам: они являются либо трендом, либо сезонной составляющей. Тренд представляет собой общую систематиче-
5
скую линейную или нелинейную компоненту, которая может изменяться во времени. Сезонная составляющая – периодически повторяющаяся компонента. Оба эти вида регулярных компонент часто присутствуют в ряде одновременно.
Не существует «автоматического» способа обнаружения тренда во временном ряду. Однако если тренд является монотонным (устойчиво возрастает или устойчиво убывает), то анализировать такой ряд обычно нетрудно. Если временные ряды содержат значительную ошибку, то первым шагом выделения тренда является сглаживание. Сглаживание всегда включает некоторый способ локального усреднения данных, при котором несистематические компоненты взаимно погашают друг друга. Многие монотонные временные ряды можно хорошо приблизить линейной функцией. Если же имеется явная монотонная нелинейная компонента, то данные вначале следует преобразовать, чтобы устранить нелинейность. Обычно для этого используют логарифмическое, экспоненциальное или (реже) полиномиальное преобразование данных.
Периодическая и сезонная зависимость (сезонность) представляет собой другой общий тип компонент временного ряда. В общем, периодическая зависимость может быть формально определена как корреляционная зависимость порядка k между каждым i-м элементом ряда и (i-k)-м элементом. Ее можно измерить с помощью автокорреляции (т.е. корреляции между самими членами ряда); k обычно называют лагом (иногда используют эквивалентные термины: сдвиг, запаздывание).
Сезонные составляющие временного ряда могут быть найдены с помощью коррелограммы. Коррелограмма (автокоррелограмма) показывает численно и графически автокорреляционную функцию (AКФ), иными словами коэффициенты автокорреляции (и их стандартные ошибки) для последовательности лагов из определенного диапазона (например, от 1 до 30). На коррелограмме обычно отмечается диапазон в размере двух стандартных ошибок на каждом лаге, однако обычно величина автокорреляции более интересна, чем ее надежность, потому, что интерес в основном представляют очень сильные (следовательно, высоко значимые) автокорреляции.
Другой полезный метод исследования периодичности состоит в исследовании частной автокорреляционной функции (ЧАКФ), представляющей собой углубление понятия обычной автокорреля-
6
ционной функции. В ЧАКФ устраняется зависимость между промежуточными наблюдениями (наблюдениями внутри лага). Другими словами, частная автокорреляция на данном лаге аналогична обычной автокорреляции, за исключением того, что при вычислении из нее удаляется влияние автокорреляций с меньшими лагами. На лаге 1 (когда нет промежуточных элементов внутри лага), частная автокорреляция равна, очевидно, обычной автокорреляции. На самом деле, частная автокорреляция дает более «чистую» картину периодических зависимостей.
Как отмечалось выше, периодическая составляющая для данного лага k может быть удалена взятием разности соответствующего порядка. Это означает, что из каждого i-го элемента ряда вычитается (i-k)-й элемент. Имеются два довода в пользу таких преобразований.
Во-первых, таким образом можно определить скрытые периодические составляющие ряда. Напомним, что автокорреляции на последовательных лагах зависимы. Поэтому удаление некоторых автокорреляций изменит другие автокорреляции, которые, возможно, подавляли их, и сделает некоторые другие сезонные составляющие более заметными.
Во-вторых, удаление сезонных составляющих делает ряд стационарным, что необходимо для применения АРПСС и других методов, например, спектрального анализа.
Существуют две основные цели анализа временных рядов: определение природы ряда и прогнозирование (предсказание будущих значений временного ряда по настоящим и прошлым значениям). Все методы анализа временных рядов не выдают на выходе правил «если-то», следовательно, эти методы не удовлетворяют критерию получения информации о скрытых знаниях в пригодном для усвоения человеком виде.
1.2. Граничные методы
Граничные методы определяют классы, используя границы областей [14]. В некоторых простейших случаях классы можно разделить прямой линией. Каждый объект в данном случае характеризуется двумя измерениями. Набирающий популярность метод опорных векторов (Support Vector Machine – SVM) ищет образцы, расположенные на границах между двумя классами.
7

Метод опорных векторов. Метод опорных векторов (МОВ или SVM – Support Vector Machine) относится к группе граничных методов. Она определяет классы при помощи границ областей.
В общем виде задача классификации при использовании МОВ формулируется следующим образом. Имеется: пространство векторов X , m-мерное евклидово пространство Rm векторов-признаков изображения.
Пространство ответов Y = {1, -1} , где yi =1 означает, что вектор xi соответствует объекту одного класса, а y j = −1, что x j со-
ответствует объекту другого класса.
Пространство F функций f: X -> Y, или пространство функцийклассификаторов. Требуется по некоторому обучающему набору (xi , yi ), i =1,2,.., N найти функцию f, так чтобы достигался минимум
среднеквадратической ошибки
N |
( yi − f (xi ))2 →min . |
∑ |
|
i=1 |
f F |
|
Метод опорных векторов основан на том, что ищется линейное
разделение |
|
классов. |
В этом случае функция |
реше- |
|||
ния f (x) =sgn( |
w |
x +b) , и производится поиск параметров |
w |
и b. |
|||
Видно, что |
w |
x +b =0 – |
уравнение разделяющей классы гиперп- |
||||
лоскости. Проводя параллельные гиперплоскости w x +b = ±1, получим, что для проведения оптимальной разделяющей гиперплоскости, надо максимизировать расстояние между этими двумя
плоскостями |
|
|
2 |
|
|
с условиями, что между ними нет точек данных, |
|
|
|
|
w |
|
|
||
|
|
|
|
|
|
|
|
т.е. yi (w xi +b) ≥1. Методом множителей Лагранжа эта задача сводится к поиску коэффициентов
N |
1 |
N |
αi ≥0 : L(α) = ∑αi − |
|
∑αiαj yi y j (xi x j ) →max |
i=1 |
2 i, j |
|
N
с ограничениями ∑αi yi =0 . Эта задача решается с помощью алго-
i=1
ритма последовательной оптимизации SMO (Sequential Minimal Optimization). Этот метод сводит решаемую задачу максимизации
8
функции N переменных к задаче с минимально возможным количеством α – с двумя – и является одним из наиболее эффективных методов обучения.
Цель метода опорных векторов – найти плоскость, разделяющую два множества объектов. Метод отыскивает образцы, находящиеся на границах между двумя классами, т.е. опорные векторы. Опорными векторами называются объекты множества, лежащие на границах областей.
В результате решения задачи, т.е. построения SVM-модели, находится функция, принимающая значения меньше нуля для векторов одного класса и больше нуля – для векторов другого класса. Для каждого нового объекта отрицательное или положительное значение определяет принадлежность объекта к одному из классов.
Все граничные методы на выходе не дают знаний в виде правил вида «если-то». Они дают только собственно функций разделяющих поверхностей. Следовательно, этот метод не удовлетворяет выбранному критерию вида представляемой зависимости.
1.3. Деревья решений
Метод деревьев решений является одним из наиболее популярных методов решения задач классификации [13, 22]. Иногда этот метод Data Mining также называют деревьями решающих правил, деревьями классификации.
Рассмотрим следующий пример. База данных, на основе которой должно осуществляться прогнозирование, содержит следующие структурированные данные о клиентах банка, являющиеся ее атрибутами: возраст, наличие недвижимости, образование, среднемесячный доход, вернул ли клиент вовремя кредит. Задача состоит в том, чтобы на основании перечисленных выше данных (кроме последнего атрибута) определить, стоит ли выдавать кредит новому клиенту.
Такая задача решается в два этапа: построение классификационной модели и ее использование.
На этапе построения модели, собственно, и строится дерево классификации или создается набор неких правил вида «если-то». На этапе использования модели построенное дерево, или путь от его корня к одной из вершин, являющийся набором правил для конкретного клиента, используется для ответа на поставленный вопрос «Выдавать ли кредит?»
9
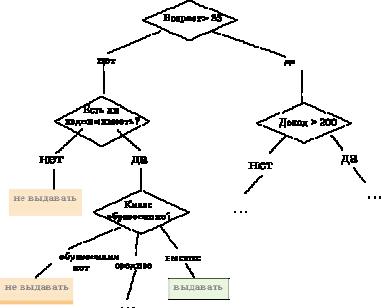
Правилом является логическая конструкция, представленная в виде «если-то».
На следующем рисунке приведен пример дерева классификации, с помощью которого решается задача «Выдавать ли кредит клиенту?». Она является типичной задачей классификации структурированных данных, и при помощи деревьев решений получают достаточно хорошие варианты ее решения.
Как видим, внутренние узлы дерева (возраст, наличие недвижимости, доход и образование) являются атрибутами описанной выше базы данных. Эти атрибуты называют прогнозирующими, или атрибутами расщепления. Конечные узлы дерева, или листы, именуются метками класса, являющимися значениями зависимой категориальной переменной «выдавать» или «не выдавать» кредит.
Рис. 1.1. Дерево решений «Выдавать ли кредит?»
На рис. 1.1 изображено одно из возможных деревьев решений для рассматриваемой базы данных. Например, критерий расщепления «Какое образование?» мог бы иметь два предиката расщепления и выглядеть иначе: образование «высшее» и «не высшее». Тогда дерево решений имело бы другой вид.
10