

2.5 Хранение индексированных документов
Организация хранения массива поисковых образов документов – одна из критических частей технологии поиска информации.
Индексирование документов является разовым процессом в локальных системах или постоянным в глобальных, но в любом случае оно не производится одновременно с поиском (для поиска и индексирования не используются одновременно одни и те же аппаратные ресурсы). Вследствие этого скорость поиска информациив ИПС определяетсяскоростью доступа к хранилищу поисковых образов(второй влияющий фактор – поисковый алгоритм), которая зависит от структуры и объема базы данных документов [, , ].
Прямой просмотр файлов поисковых образов документов занимает много времени, что является неприемлемым для пользователя, особенно в сети Интернет. Поэтому база данных документов организуется в виде ряда связанных таблиц. Помимо информации о соответствии терминов и документов (идентификаторы терминов и документов, веса терминов и т. д.), в базах данных ИПС хранятся также различные дополнительные сведения. Некоторые из них непосредственно используются при поиске, например, даты последних изменений документов или информация о содержащихся в документах ссылках на другие документы (это особенно актуально для ИПС сети Интернет).
Часть данных необходима для облегчения работы пользователя с результатами поиска (заголовки и аннотации документов и др.). Обычно информация о терминах и документах, которая находится в базах данных ИПС, может быть использована одновременно для нескольких алгоритмов поиска.
Рассмотрим общую структуру базы данных поисковых образов интернет-документов (гипертекстовых страниц) [, , , ].
База данных (рис. Рис. 10) состоит из таблицы адресов страниц, таблицы ключевых слов, таблицы заголовков страниц, таблицы с датами изменения страниц, таблицы гиперссылок, а также двух таблиц-списков – прямого и инвертированного.
Таблица адресов страницсодержит уникальные идентификаторы (pageID) и адреса страниц (URL).
Таблица ключевых словсодержит термины и их уникальные идентификаторы (kwdID).
Таблица с заголовками страницставит в соответствие каждому идентификатору страниц pageID название этой страницы.
Таблица с датами изменения страницфиксирует для каждой страницы pageID дату последнего посещения этой страницы индексационным роботом (т. е. дату индексации этой страницы). Она используется при обновлении базы данных: если содержание страницы изменилось со времени последней индексации, ее следует проиндексировать заново. В этой таблице также хранятся даты модификации стра ниц. Эта информация используется при ранжировании результатов поиска не по релевантности, а по дате.
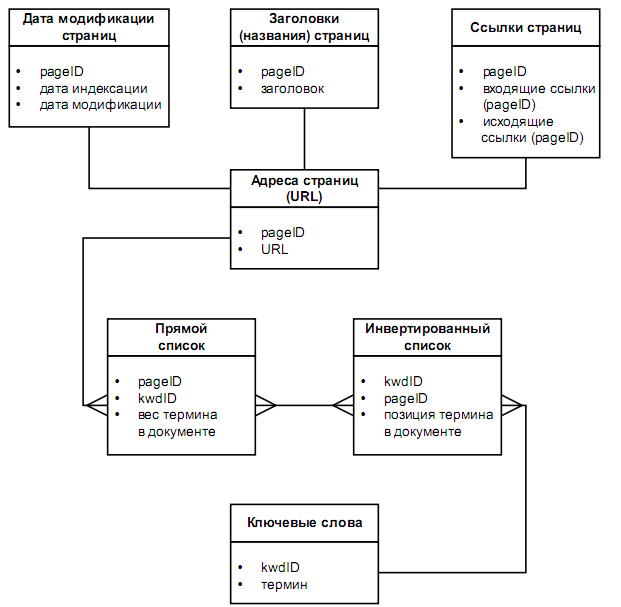
Рис.10. Структура базы данных поисковых образов
Таблица гиперссылокопределяет для каждой страницы список входящих и исходящих гиперссылок. Входящими называются такие ссылки, которые находятся на других страницах, а ссылаются на данную, а исходящими – ссылки, которые находятся на данной странице, а ссылаются на другие.
Таблицы, содержащие информацию о ссылках, необходимы по двум причинам:
они используются индексационными роботами при сканировании сети
Интернет;
документы, объединенные гиперссылками, содержат также и много одинаковых индексационных терминов.
Результаты поиска можно улучшить, добавляя к документам, описываемым идентификаторами терминов, информацию об их гиперссылках .
Таблица, называемая прямым списком, содержит список ключевых слов (kwdID) для каждой страницы (pageID). Эта таблица используется для вычисления частоты встречаемости термина в документе (TF)iи определения весов терминов, а также в алгоритмах обратной связи по релевантности и в функциях поддержки и актуализации массива индексированных документов.
Таблица – инвертированный списоксодержит для каждого ключевого слова (kwdID) список страниц (pageID), в которых это слово встречается. Кроме того, здесь указывается позиция (порядковый номер) данного термина в странице. Эта информация используется в тех запросах, где важным является взаимное расположение слов (контекстный поиск). Например, когда идет поиск по запросу «операционная система», важно получить не просто все документы, в тексте которых присутствуют термины «операционная» и «система», а только те, в которых эти два слова расположены друг за другом, т. е. объединены во фразу.
Отметим, что схема, приведенная на рис. 10, не является наиболее эффективной с точки зрения производительности ИПС. Она описывает лишь общий принцип хранения информации, который призван обеспечить максимальную полноту и точность поиска.
В ходе выполнения поискового алгоритма термины из запроса тем или иным способом сравниваются с терминами из инвертированного списка. Далее формируется результирующий список страниц (заголовок, адрес, краткая аннотация, дата индексации и т. д.), который поисковая система возвращает пользователю.
Для ускорения доступа к базе данных поисковых образов веб-документов применяются механизмы индексации и хеширования.
Индексация– средство, ускоряющее поиск и сортировку в таблице за счет использования ключевых значений, что позволяет обеспечить уникальность строк таблицы.
Хеширование– алгоритм, в ходе выполнения которого для сохраняемых объектов генерируется специальный указатель (хеш-код), используемый впоследствии для индексации массива указателей.
Часто для хранения и обработки писаний документов используются системы управления базами данных (СУБД). В таких случаях поиск по базе данных осуществляется с использованием встроенных средств СУБД.