

Для увс с общим нагруженным дублированием и восстановлением
![]() ,
,
где
![]() ,
,![]() ;
;![]() ;
;![]() .
.
Несмотря на то что общее нагруженное дублирование с восстановлением отказавших ЭВМ ведет к росту Kг, Tср, тем не менее вероятность безотказной работы порядка 0,997 обеспечивается лишь в течение десятка часов. Действительно, поскольку наработка на отказ современных ЭВМ не превышает нескольких сотен часов, а среднее время восстановления не меньше 0,5 ч, при λ =0,01÷0,004 1/ч и λ / μ = 0,005÷0,002
![]()
При этом интервал времени Δt, в течение которого Робщ(Δt)≥ 0,997, составляет лишь 10—25 ч, что по крайней мере на два порядка ниже, чем требуется в ряде прикладных задач управления техническими объектами. Чтобы достичь Δt = 1000 ч, нужно» либо уменьшать Тв до 10 мин, либо при Тв = 0,5 ч и Тcp=100 ч применять четырехкратный общий резерв. Такая высокая кратность резервирования вряд ли реализуема на практике по экономическим соображениям. Из приведенного анализа следует важный практический вывод: обеспечить высокую надежность УВС путем общего нагруженного резерва не представляется возможным по экономическим соображениям.
Известно, что наибольший эффект дает поэлементное резервирование. В [2] показано, что для средств вычислительной техники с поэлементным нагруженным дублированием и восстановлением» отказавших элементов
![]() (19)
(19)
где п — число элементов в ЭВМ.
Как следует из (19), наработка на отказ такой системы в п раз больше по сравнению с наработкой на отказ в случае общего нагруженного дублирования. Так как число элементов п современных УВС велико, то наработка на отказ восстанавливаемых УВС с поэлементным дублированием соизмерима с долговечностью элементов. Расчеты показывают, что вероятность безотказной работы такой ЭВМ настолько велика, что УВС можно считать идеально надежной в течение тысяч часов [2]. Использование поэлементного резервирования для обеспечения надежности УВС, несмотря на высокую эффективность, крайне затруднительно. Это объясняется тем, что его техническая реализация практически невозможна при использовании современной элементной базы.
Построение УВС как вычислительных систем, состоящих из n основных и m резервных равнонадежных ЭВМ с параметром потока отказов λ, восстановление которых с параметром μ допускается в процессе работы системы, является практически осуществимым путем создания высоконадежных УВС. В [2] показано, что уже при m = 2÷3 и μ /( n λ) ≥102 наработка на отказ Тcp ≈ 104÷106ч, так как при μ / λ ≥1
![]() .
.
Вытекающими из выше приведенных рассуждений практическими рекомендациями по построению надежных УВС следует считать: введение структурной избыточности путем построения узлов, устройств, и вычислительных систем с изменяющейся архитектурой при возникновении отказов отдельных изделий; ремонт отказавших изделий без нарушения функционирования УВС в целом; создание бессбойного математического обеспечения.
§ 3 Методы повышения надежности программно-информационных технологий для корпоративных структур
К современным вычислительным системам предъявляются высокие требования по надежности хранения информации. Это объясняется переходом от процессоро-ориентированных приложений к дата-ориентированным приложениям. Внедрение информационных технологий в области, связанные с крупными финансовыми потоками, привело к тому, что хранящаяся в системе информация многократно дороже носителей. В качестве примера можно привести банковские приложения, биллинговые системы (учет трафика, времени телефонных переговоров).
Как показывает недавнее исследование консалтинговой организации Standish Group, в высококритичных средах даже минута простоя может иметь серьезные финансовые последствия. Доклад VirtualCompass Research Report по результатам опроса 250 компаний из числа Fortune 1000 в семи крупнейших отраслях показывает, что минута простоя обходится в сумму от 1000 до 27 000 долларов. Авторы отчета суммируют эти цифры: «Если простой приложения обходится в 10 000 долларов в минуту, то его неработоспособность в течение двух часов будет стоить более миллиона долларов». При таких космических последствиях простоев основной задачей администратора сети становится сведение к минимуму времени недоступности сети и нахождение экономически оправданного решения этой задачи.
Таблица 1 – Недополученные доходы в результате простоя приложений
|
Вид приложения |
Цена минуты простоя, доллар США |
|
Биллинговая система оператора мобильной связи |
27000 |
|
Планирование ресурсов крупного предприятия |
13000 |
|
Управление цепочкой поставок |
11000 |
|
Электронная коммерция |
10000 |
|
Банковские операции через Internet |
7000 |
|
Розничная точка продаж |
3500 |
Резервирование дисковых накопителей
Носителями информации в большинстве современных вычислительных систем являются жесткие магнитные диски. Несмотря на свой главный недостаток (наличие вращающихся частей) они обладают наилучшими характеристиками для соответствующего типа устройств и доступной ценой.
Особенности технологии построения магнитных дисков привели к значительному несоответствию между увеличением производительности процессоров и самих магнитных дисков. В 1990 г. лучшие 5.25" диски имели среднее временя доступа 12 мс, время задержки 5 мс (при оборотах шпинделя около 5 000 об/м). Сейчас 3.5" диски характеризуются средним временем доступа 5 мс и временем задержки 1 мс (при оборотах шпинделя 10 000 об/м). При этом быстродействие процессоров увеличилось более чем на 2000% [www.ixbt.com].
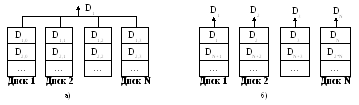
Рис. 5. Увеличение производительности дисковых накопителей: массив с параллельным доступом (а) и массив с независимым доступом (б).
Невозможность значительного увеличения технологических параметров магнитных дисков влечет за собой необходимость поиска других путей, одним из которых является параллельная обработка. Если расположить блок данных по N дискам некоторого массива и организовать это размещение так, чтобы существовала возможность одновременного считывания информации, то этот блок можно будет считать в N раз быстрее, (без учёта времени формирования блока). Поскольку все данные передаются параллельно, это архитектурное решение называется parallel-access array (массив с параллельным доступом). Массивы с параллельным доступом обычно используются для приложений, требующих передачи данных большого размера.
Некоторые задачи, наоборот, характерны большим количеством малых запросов. К таким задачам относятся, например, задачи обработки баз данных. Располагая записи базы данных по дискам массива, можно распределить загрузку, независимо позиционируя диски. Такую архитектуру принято называть independent-access array (массив с независимым доступом).
Дисковые накопители – наиболее ненадежная часть вычислительных систем. Для обмена данными в дисковых накопителях чаще всего используются интерфейсы SCSI, IDE, SATA. При увеличении количества дисков в массиве, надежность всего массива уменьшается. При независимых отказах и экспоненциальном законе распределения наработки на отказ среднее время безотказной работы всего массива вычисляется по формуле MTTFarray = MMTFhdd / Nhdd (MMTFhdd – среднее время безотказной работы одного диска; Nhdd – количество дисков).
Для повышения отказоустойчивости массивов используют избыточное кодирование. Существует два основных типа кодирования, которые применяются в избыточных дисковых массивах – это дублирование и четность.
Дублирование, или зеркализация – наиболее часто используются в дисковых массивах. Простые зеркальные системы используют две копии данных, каждая копия размещается на отдельных дисках. Это схема достаточно проста и не требует дополнительных аппаратных затрат, но имеет один существенный недостаток - она использует 50% дискового пространства для хранения копии информации.
Второй способ реализации избыточных дисковых массивов - использование избыточного кодирования с помощью вычисления четности. Четность вычисляется как операция XOR всех символов в слове данных. Использование четности в избыточных дисковых массивах уменьшает накладные расходы до величины, исчисляемой формулой: НРhdd = 1/Nhdd (НРhdd - накладные расходы; Nhdd - количество дисков в массиве).
RAID-массивы
Несмотря на то, что системы хранения данных, основанные на магнитных дисках, производятся уже 40 лет, массовое производство отказоустойчивых систем началось совсем недавно. Дисковые массивы с избыточностью данных, которые принято называть RAID (redundant arrays of inexpensive disks - избыточный массив недорогих дисков) были представлены исследователями (Петтерсон, Гибсон и Катц) из Калифорнийского университета в Беркли в 1987 году. Но широкое распространение RAID системы получили только тогда, когда диски, которые подходят для использования в избыточных массивах стали доступны и достаточно производительны.
RAID0 был представлен как определение не отказоустойчивого дискового массива. В Беркли RAID1 был определен как зеркальный дисковый массив. RAID2 зарезервирован для массивов, которые применяют код Хемминга. Уровни RAID 3, 4, 5 используют четность для защиты данных от одиночных неисправностей. Именно эти уровни, включительно по 5-й были представлены в Беркли, и эта систематика RAID была принята как стандарт де-факто.
RAID0 представляет собой дисковый массив, в котором данные разбиваются на блоки, записывающиеся (или считывающиеся) на отдельный диск. Таким образом, можно осуществлять несколько операций ввода-вывода одновременно. Емкость массива из N дисков равна N* (емкость наименьшего диска). Если поступает запрос на чтение/запись логически последовательных блоков, то происходит параллельное обращение, и скорость операций ввода-вывода увеличивается. С точки зрения производительности это означает два основных преимущества:
повышается пропускная способность последовательного ввода/вывода за счет одновременной загрузки нескольких интерфейсов.
снижается латентность случайного доступа; несколько запросов к различным небольшим сегментам информации могут выполнятся одновременно.
скорость потокового чтения/записи при некотором оптимальном размере страйп-блока увеличивается почти пропорционально числу дисков в массиве.
Уровень RAID0 предназначен исключительно для повышения производительности, и не обеспечивает избыточности данных. Поэтому любые дисковые сбои потребуют восстановления информации с резервных носителей. В общем, это неприемлемое для серверов решение может использоваться для работы с большими файлами на рабочей станции – при обработке больших изображений, видео, некоторых научных вычислениях и т. д. При использовании RAID0 обязательно наличие системы резервного копирования (backup & recovery).

Рисунок 3.2 – Дисковый массив без отказоустойчивости RAID0
RAID1 – отказоустойчивый массив из пары дисков. При записи данные с первого диска дублируются на втором (так называемое зеркалирование). Зеркалирование – традиционный способ для повышения надежности дискового массива небольшого объема. В простейшем варианте используется два диска, на которые записывается одинаковая информация, и в случае отказа одного из них остается его дубль, который продолжает работать в прежнем режиме.
Это эффективное и сравнительно простое в реализации решение обладает существенным недостатком – объем дискового пространства массива равен емкости наименьшего диска (например, если объединить в RAID1 диски на 30 и 40 Гбайт, то доступно будет только 30 Гбайт). Время записи может оказаться несколько больше, чем для одного диска, в зависимости от стратегии записи: запись на два диска может производится либо параллельно (для скорости), либо строго последовательно (для надежности).
В RAID1 можно уменьшить время доступа к массиву по сравнению с одиночным диском благодаря оптимизации запросов на чтение. Скорость чтения тоже может значительно повыситься из-за параллельного считывания с двух дисков. В серверных приложениях RAID1 может показывать гораздо большую производительность, чем одиночный диск или даже RAID0.

Рисунок 3.3 – Дисковый массив с дублированием RAID1
RAID2 представляет собой отказоустойчивый дисковый массив с использованием кода Хемминга (Hamming Code ECC). Избыточное кодирование, которое используется в RAID2, носит название кода Хемминга, позволяющего исправлять одиночные и обнаруживать двойные неисправности. Если происходит сбой одного диска с данными, то система может восстановить его содержимое по содержимому остальных дисков с данными и диска с информацией четности. Код Хемминга активно используется в технологии кодирования данных в оперативной памяти типа ECC. Преимуществами RAID2 являются быстрая коррекция ошибок («на лету»), очень высокая скорость передачи данных больших объемов, простая реализация. К тому же при увеличении количества дисков накладные расходы уменьшаются.
Производительность в RAID2 велика для больших объемов информации, но может быть весьма скромной для малых объемов, поскольку невозможно перекрывающееся чтение нескольких небольших сегментов информации. Из-за низкой скорости обработки запросов уровень 2 не подходит для систем ориентированных на обработку транзакций.

Рисунок 3.4 – Отказоустойчивый дисковый массив с использованием кода Хемминга
RAID3 – отказоустойчивый массив с параллельной передачей данных и четностью. Отличие RAID3 от RAID2 состоит в том, что RAID2 использует для хранения битов четности несколько дисков, тогда как RAID3 использует только один. Здесь данные разбиваются на подблоки на уровне байт и записываются одновременно на все диски массива кроме одного, который используется для четности. Использование RAID3 решает проблему большой избыточности в RAID2. Большинство контрольных дисков, используемых в RAID уровня 2, нужны для определения положения неисправного разряда. Но в этом нет нужды, так как большинство контроллеров в состоянии определить, когда диск отказал при помощи специальных сигналов, или дополнительного кодирования информации, записанной на диск и используемой для исправления случайных сбоев.
К положительным характеристикам этого уровня RAID относятся очень высокая скорость передачи данных и малые накладные расходы для реализации избыточности. Кроме того, здесь отказ диска мало влияет на скорость работы массива. Но при большой интенсивности запросов данных небольшого объема производительность RAID3 низкая.

Рисунок 3.5 – Отказоустойчивый массив с параллельной передачей данных и четностью
RAID4 – отказоустойчивый массив независимых дисков с разделяемым диском четности. Данные разбиваются на блочном уровне. Каждый блок данных записывается на отдельный диск и может быть прочитан отдельно. Четность для группы блоков генерируется при записи и проверяется при чтении. RAID уровня 4 повышает производительность передачи небольших объемов данных за счет параллелизма, давая возможность выполнять более одного обращения по вводу/выводу одновременно. Главное отличие между RAID3 и 4 состоит в том, что в последнем, расслоение данных выполняется на уровне секторов, а не на уровне битов или байтов.
Преимущества RAID4 – очень высокая скорость чтения данных больших объемов, высокая производительность при большой интенсивности запросов чтения данных, малые накладные расходы для реализации избыточности. Недостатки – достаточно сложная реализация, очень низкая производительность при записи данных, сложное восстановление данных, низкая скорость чтения данных малого объема при единичных запросах, асимметричность быстродействия относительно чтения и записи.

Рисунок 3.6 – Отказоустойчивый массив независимых дисков с разделяемым диском четности
RAID5 представляет собой отказоустойчивый массив независимых дисков с распределенной четностью. Этот уровень похож на RAID4, но в отличие от предыдущего четность распределяется циклически по всем дискам массива. Это изменение позволяет увеличить производительность записи небольших объемов данных в многозадачных системах. Если операции записи спланировать должным образом, то, возможно, параллельно обрабатывать до N/2 блоков, где N– число дисков в группе.
К преимуществам RAID5 относятся высокая скорость записи данных; достаточно высокая скорость чтения данных; высокая производительность при большой интенсивности запросов чтения/записи данных; малые накладные расходы для реализации избыточности. Среди недостатков RAID5 низкая скорость чтения/записи данных малого объема при единичных запросах, достаточно сложная реализация, сложное восстановление данных.

Рисунок 3.7 – Отказоустойчивый массив независимых дисков с распределенной четностью
Современные RAID контроллеры позволяют комбинировать различные уровни RAID. Таким образом, можно реализовать системы, которые объединяют в себе достоинства различных уровней, а также системы с большим количеством дисков. Обычно это комбинация нулевого уровня (stripping) и какого либо отказоустойчивого уровня.
Так, RAID10 – отказоустойчивый массив с дублированием и параллельной обработкой – являет собой массив типа RAID0, сегментами которого являются массивы RAID1. Он объединяет в себе очень высокую отказоустойчивость и производительность.
RAID30 – отказоустойчивый массив с параллельной передачей данных и повышенной производительностью – представляет собой массив типа RAID0, сегментами которого являются массивы RAID3. Он объединяет в себе отказоустойчивость и высокую производительность. Обычно используется для приложений требующих последовательной передачи данных больших объемов.
RAID50 – отказоустойчивый массив с распределенной четностью и повышенной производительностью – это массив типа RAID0, сегментами которого являются массивы RAID5. Он объединяет в себе отказоустойчивость и высокую производительность для приложений с большой интенсивностью запросов и высокую скорость передачи данных.
Рассмотрим теперь стандартные уровни вместе для сравнения их характеристик. Сравнение производится в рамках архитектур, упомянутых в таблице 2.
Таблица 2 – характеристики различных уровней RAID
|
RAID |
Минимум дисков |
Потребность в дисках |
Отказо- устойчивость |
Скорость передачи данных |
Скорость обработки запросов |
Практическое использование |
|
0 |
2 |
N |
> 1 диск |
< RAID3 |
Очень высокая до N х 1 диск |
Графика, видео |
|
1 |
2 |
Обычно 2N |
> RAID0 |
R > 1 диск W = 1 диск |
до 2 х 1 диск W = 1 диск |
Малые файл-серверы |
|
2 |
7 |
N+1 … N |
> RAID0 |
~ RAID3 |
Низкая |
Мейнфреймы |
|
3 |
3 |
N+1 |
> RAID0 |
~ RAID2 |
Низкая |
Графика, видео |
|
4 |
3 |
N+1 |
> RAID0 |
R < RAID3 W < RAID5 |
R = RAID0 W < 1 диск |
Файл-серверы |
|
5 |
3 |
N+1 |
> RAID0 |
R < RAID4 W < RAID3 |
R = RAID0 W < 1 диск |
Серверы баз данных |
Примечание: R – чтение; W – запись.