

2l-2 Статистика
.pdfУЧЕБНЫЕ И ВОСПИТАТЕЛЬНЫЕ ЦЕЛИ
·приобщение студентов к жизни в информационном обществе;
·формирование психологической готовности студентов к овладению
методологией дальнейшего самостоятельного изучения современных информационных технологий и их эффективного использования будущей практической деятельности врача, провизора;
·формирование знаний выполнения основных операций работы с данными: сбора, формализации данных и преобразования их в электронную форму, сортировки, фильтрации, транспортировки и преобразования данных;
·подготовка студентов к выбору темы, планированию эксперимента, статистической обработке результатов экспериментов, выполнению, оформлению и представлению на вузовских и международных научных конференциях студенческой научно-исследовательской работы;
· формирование |
у студентов |
знаний, необходимых для |
изучения |
на |
старших |
курсах |
дисциплины«Общественное |
здоровье |
и |
здравоохранение». |
|
|
|
|
ЛИТЕРАТУРА
1.Гараничева С.Л. Основы информационных технологий: Учеб. пособ. – Витебск: ВГМУ, 2001. – 201 с.
2.Гаснаков В. К. Основы научного управления и информатизация в здравоохранении. Ижевск. «Вектор». 1997 – 169 с.
3.Гельман В. Я. Электронная таблица Excel для врачей – СПб.: СПб МАПО, 2000 – 58 с.
4.Гельман В.Я. Медицинская информатика: практикум. – СПб.: Питер, 2001
– 480 с. – (Серия «Национальная медицинская библиотека»).
5.Додж М., Стинсон К. Эффективная работа с Microsoft Excel 2000 – СПб.:
«Питер», 2001 – 1056 с.
6.Долженков В., Колесников Ю. Самоучитель. Microsoft Excel 2000 – СПб.:
БХВ. СПб. 1999 – 355 с.
7.Дюк В. Эммануэль В. Информационные технологии в медико-
биологических исследованиях – СПб.: Питер, 2003. – 528 с.
8. Кудрина В. Г. Медицинская информатика М. РМАПО, 1999 – 100 с.
9.Курс молодого бойца. Самоучитель 3-е изд. Камилл Ахметов, 2003 г., 400 стр., с ил.
10.Тюрин Ю.Н., Макаров А.А. Анализ данных на компьютере / Под ред. В.Э. Фигурнова. – М.: ИНФА-М, Финансы и статистика, 1995. – 384 с.
МАТЕРИАЛЬНОЕ ОБЕСПЕЧЕНИЕ
· Мультимедиа презентация Microsoft PowerPoint – 30 слайдов.
РАСЧЕТ УЧЕБНОГО ВРЕМЕНИ
№ п/п |
Перечень учебных вопросов |
Выделенное |
|
|
время |
1. |
Введение |
5 мин. |
2. |
Элементарные понятия медицинской статистики |
15 мин. |
|
(генеральная совокупность, выборка, виды |
|
|
распределения элементов выборки, основные |
|
|
характеристики выборки, нулевая и альтернативная |
|
|
гипотезы). |
|
3. |
Использование электронных таблиц для |
10 мин. |
|
представления данных и обработки результатов |
|
|
медико-биологического эксперимента. |
|
4. |
Применение статистических функцийMicrosoft Excel |
5 мин. |
|
для анализа экспериментальных данных. |
|
5. |
Определение среднего значения и стандартного |
10 мин. |
|
отклонения выборки с помощью функций СРЗНАЧ и |
|
|
СТАНДОТКЛОН. |
|
6. |
Статистическая обработка результатов медико- |
10 мин. |
|
биологического эксперимента с помощью функций |
|
|
Microsoft Excel с целью определения эффективности |
|
|
новых методик диагностики, лечения, реабилитации |
|
|
пациентов, использования лекарственных |
|
|
препаратов (функции ТТЕСТ, ХИ2ТЕСТ). |
|
7. |
Определение взаимосвязей между отдельными |
10 мин. |
|
параметрами (функция КОРРЕЛЛ). |
|
8. |
Заключение |
5 мин. |
ИТОГО |
: |
60 мин. |
2
СОДЕРЖАНИЕ ПЛАН-КОНСПЕКТА ЛЕКЦИИ
1.ВВЕДЕНИЕ
Внастоящее время в медицине и здравоохранении математические методы обработки данных широко применяются при:
· определении эффективности новых методик диагностики, лечения и реабилитации пациентов;
·апробации новых фармакологических препаратов, эффективность действия которых на организм человека надо подтвердить или опровергнуть;
·исследования действия на измеряемую величину одного или нескольких факторов (например, степень влияния тяжести специального
браслета |
на |
частоту |
самопроизвольного |
дрожания |
мышц) – |
ру |
||
дисперсионный анализ; |
|
|
|
|
|
|
||
· |
для |
выявления |
степени |
взаимосвязи |
между |
отдельны |
||
явлениями и процессами, например между частотой сердечных сокращений |
|
|||||||
(ударов в минуту) и частотой дыхания (вдохов в минуту) – корреляция; |
|
|
||||||
· |
выявление наиболее существенной периодической зависимости и |
|
||||||
их задержки в одном процессе или между несколькими процессами– |
||||||||
корреляционный анализ; |
|
|
|
|
|
|
||
· |
нахождении |
периодических (и |
|
квазипериодических) |
|
|||
зависимостей в данных – спектральный анализ (например, анализ ритмов в энцефалографии);
·преобразование временных рядов с целью удаления из них высокочастотных и низкочастотных колебаний– сглаживание и фильтрация (например, фильтрация электрокардиограмм с целью удаления артефакторов
ипомех)
·других направлениях обработки медико-биологических данных. Следует отметить, что материал данной лекции ориентирован на
первичное ознакомление студентов с практическими приемами проведения элементарной статистической обработки данных. Более глубокие знания по данной теме студенты лечебного факультета смогут получить на предмете «Общественное здоровье и здравоохранение», который преподается на одноименной кафедре, в теме «Медицинская статистика» на 4 курсе, в теме «Методы статистической обработки данных» на 6 курсе медицинского вуза.
В основе обработки и анализа данных лежат математические методы, которые в большинстве своем являются неизменными в течение десятилетий. Компьютерный анализ медико-биологических данных предполага преобразование данных с помощью определенных программных средств. Следовательно, специалисту-медику необходимо иметь представление как о самих математических методах обработки данных, так и о программных средствах, реализующих эти методы.
Статическую обработку данных позволяют осуществлять следующие современные программные средства:
3
· электронные таблицы, работа с которыми осуществляется под управлением программ табличных процессоров. К ним относятся программы
SuperCalc, QuattroPro, Lotus-1-2-3, Microsoft Excel и другие;
· специализированные |
статистические |
пакеты– |
Statgrafics, |
STATISTICA, SPSS и другие – в |
эти пакеты |
включены практически все |
|
математические методы обработки данных. |
|
|
|
В связи с тем, что в данном курсе мы на углубленном уровне изучаем приемы работы с приложениями интегрированного пакетаMicrosoft Office, напомним возможности электронных таблиц (ЭТ) Microsoft Excel.
ЭТ Microsoft Excel позволяют выполнить:
·автоматизацию вычислений с помощью подготовленных макетов;
·построение диаграмм и графиков;
·обработку данных списков – простейших баз данных;
·создание и исследование медико-биологических моделей;
·решение задач прогнозирования;
·статистическую обработку медико-биологических данных;
· аппроксимацию |
графиков |
зависимостей |
данных |
полученн |
||
эмпирическим |
путем |
математическими |
функциями(т.е. получение |
|||
математических формул, для описания функциональных зависимостей); |
|
|||||
· решение задач оптимизации и др.
Для лучшего восприятия материала вначале ознакомимся с основными сведениями по статистике, а затем рассмотрим возможности их реализации в среде электронных таблиц.
Элементарные понятия медицинской статистики |
|
|
||||
Понятия «генеральная совокупность» и «выборка». |
|
|
||||
Множество |
единиц |
наблюдения, охватываемых |
|
сплошным |
||
наблюдением, называется генеральной совокупностью. |
|
|
||||
В связи |
с ,темчто невозможно провести анализ необходимых |
|||||
признаков во всей генеральной совокупности, сследование генеральной |
||||||
совокупности |
заменяют |
исследованием |
выборки. Выборочный |
метод |
||
используется для получения |
правильных |
выводов |
относительно вс |
|||
совокупности объектов. Конечной целью изучения выборки всегда является получение информации о генеральной совокупности.
Выборкой называется группа элементов, выбранная для исследования
из всей (генеральной) совокупности элементов. |
|
|
||||
При формировании выборки должны выполняться ряд условий: |
|
|||||
1. |
Каждый член генеральной совокупности должен иметь равную |
|||||
вероятность попасть в выборку; |
|
|
|
|
||
2. |
Отбор |
единиц |
из |
генеральной |
совокупности |
необходи |
производить независимо от изучаемого признака; |
|
|
||||
3. |
Отбор должен проводиться из однородных групп(например, |
|||||
одинаковое соотношение полов). |
|
|
|
|
||
Случайная выборка формируется случайным образом – наудачу. |
|
|||||
4
Чтобы по выборке можно было судить о генеральной совокупности,
выборка |
должна |
быть |
представительной(репрезентативной). |
Репрезентативность означает, |
что объекты выборки достаточно хорошо |
||
представляют |
генеральную |
совокупность. |
Различают количественную и |
качественную репрезентативность.
Количественная репрезентативность определяется числом наблюдений, гарантирующих получение статистически достоверных данных. Чем больше
наблюдений, тем результаты достоверней. |
|
|
|
структурное |
|||||||||||
Качественная |
репрезентативность |
обозначает |
|||||||||||||
соответствие выборочной и генеральной совокупностей. |
|
|
|
||||||||||||
Основные характеристики выборки. |
|
|
|
|
|
||||||||||
Выборка |
описывается |
|
рядом |
|
параметров, среди |
которых |
закон |
||||||||
распределения элементов в выборке, среднее арифметическое, дисперсия, |
|||||||||||||||
стандартное отклонение и ряд других величин. |
|
|
|
|
|
||||||||||
Элементы |
|
выборки |
|
обычно |
|
распределяются |
в |
совокупности |
|||||||
соответствии |
|
с |
каким-то |
законом(биноминальное, |
пуассоновское, |
||||||||||
нормальное распределение, распределение Фишера и др.). |
|
|
|
||||||||||||
Нормальное распределение (распределение Гаусса) – используется для |
|||||||||||||||
приближённого |
описания явлений, |
в |
которых |
на |
результат |
воздействует |
|||||||||
большое |
количество |
независимых |
случайных |
,факторовимеющих |
|||||||||||
вероятностный |
(случайный) характер, |
среди |
которых |
нет |
сильно |
||||||||||
выделяющихся. В связи с тем, что в подавляющее большинство медико- |
|||||||||||||||
биологических |
|
явлений |
|
носит |
вероятностный |
характер, нормальное |
|||||||||
распределение в этих явлениях встречается весьма часто, и имеет вид, |
|||||||||||||||
представленный на рис.14. |
|
|
|
|
|
|
|
|
|
|
|
|
|||
Важной характеристикой выборки является среднее арифметическое. |
|
||||||||||||||
Среднее арифметическое ( |
|
) |
возвращает функция Excel СРЗНАЧ(M), |
||||||||||||
x |
|||||||||||||||
где M массив выборки. Это центр выборки вокруг, которого группируются элементы выборки (см. рис 14). Оно выражает характерную, типичную для данного ряда величину признака и даёт возможность:
1) точечно оценить генеральный параметр математического ожидания случайной величины, т.е. охарактеризовать исследуемую совокупность одним числом;
2)сравнить отдельные величины со средним арифметическим;
3)определить тенденцию развития какого-либо явления;
4)сравнить разные совокупности;
5)вычислить другие статистические показатели, так как многие статистические вычисления опираются на средние арифметические.
Дисперсия (D), характеризует разброс параметров выборки вокруг
среднего значения. Значение дисперсии вычисляется по формуле: D=Sdi2/n. Для увеличения точности формулу изменяют следующим образомD=Sdi2/(n- 1)), где n – число наблюдений, di – отклонение варианты от среднего.
Существенным недостатком дисперсии, которая является именованной величиной, является несоответствие её размерности и размернос
5
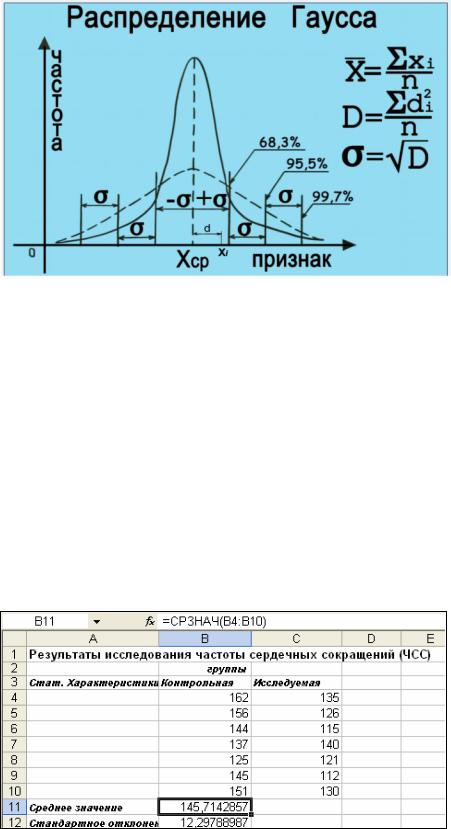
отдельных единиц числового ряда(Х). Размерность дисперсии равна квадрату размерности исследуемого параметра.
Рис. Вид распределения Гаусса |
|
|
|
|
|
||
Указанного |
недостатка |
лишеностандартное |
отклонение (s). |
||||
s = КОРЕНЬ(D). |
Его |
значение |
|
вычисляет |
функцияMicrosoft |
Excel |
|
СТАНДОТКЛОН(М). Геометрическая |
интерпретация |
этого |
параметра |
||||
представлена на рис.14. |
|
|
|
|
|
|
|
В области, |
где |
располагается |
часть |
вариант, отклоняющихся от |
|||
среднего не более, чем на s, при нормальном распределении всегда оказывается 68,3 % всех вариант. Таким образом, 68,3% всех вариант отклоняется от среднего значения не более, чем на величину s. В пределах от -2s до +2s лежат 95,5% всех вариант. В пределах от -3s до +3s находится 99, 7% - всех вариант выборки (правило трёх сигм).
На рис. представлен пример вычисления средствами приложенияExcel среднего значения и стандартного отклонения.
Рис. Вид Рабочего листа ЭТ Excel с примерами вычисления среднего значения и стандартного отклонения
6
При вычислении среднего значения выборки, стандартного отклонения, приведенных на рис. 15, в качестве массива в соответствующих функциях Excel используются интервалы размещения значений элементов выборок В4:В10 – для контрольной группы и С4:С10 – для исследуемой группы.
Контрольная и экспериментальные группы выборок.
При проведении научных исследований обычно используют несколько
выборок (групп). |
|
|
|
|
|
Контрольная |
группа – |
это |
выборка |
элементов |
генеральной |
совокупности, которая отражает исходные свойства этой совокупности. |
|||||
Исследуемая |
группа – это |
совокупность |
объектов, над |
которыми |
|
проводится исследование. Она отражает свойства генеральной совокупности после воздействия на нее каким-либо конкретным фактором.
Понятие статистической гипотезы.
Под статистической гипотезой понимают всякое высказывание о
генеральной совокупности (случайной |
величине), |
проверяемое |
по |
выборке |
||
(результатам наблюдений). |
|
|
|
|
|
|
Процедуру |
сопоставления |
высказанной |
гипотезы |
с |
выборочными |
|
данными называют проверкой статистической гипотезы. |
|
|
||||
Проверяемую |
статистическую |
гипотезу принято называть основной |
||||
(нулевой - 0 отличий) гипотезой (обозначается H0), а противоречащую ей |
||||||
гипотезу – альтернативной (или |
конкурирующей) |
гипотезой (обозначается |
||||
H1). |
|
|
|
|
|
|
По прикладному содержанию различают следующие основные виды высказываемых в ходе статистической обработки данных гипотез:
·Параметрические: о числовых значениях исследуемой генеральной совокупности (среднее, медиана, и др.);
·Непараметрические: о типе закона распределения исследуемой величины;
·другие:
Ø |
об однородности двух или нескольких обрабатываемых выборок |
|||||
или некоторых характеристик анализируемых совокупностей; |
|
|||||
Ø |
о |
типе |
зависимости |
между |
компонентами |
исследуемог |
многомерного признака; |
|
|
|
|
||
Ø |
о независимости и стационарности обрабатываемого ряда |
|||||
наблюдений. |
|
|
|
|
|
|
Если известна вероятность справедливости нулевой гипотезы (PH0), то выводы о ее принятии делают при сравнении этой вероятности с некоторой величиной, называемой уровнем значимости.
Уровень значимости (α) – максимальное значение вероятности наступления события, при котором событие ещё считается практически невозможным (в медицине равен0,05). Если вероятность меньше0,05, то
событие принято считать маловероятным. Величина уровня значимости |
|
|||||
выражает |
вероятность |
нулевой |
гипотезы, .е. вероятность |
того, что |
|
|
выборочная |
(экспериментальной |
группы) и |
генеральные |
средние |
не |
|
отличаются друг от друга.
7
Иначе говоря, чем выше уровень значимости, тем меньше можно доверять утверждению, что различие существуют. Уровень значимости представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на всю генеральную совокупность, которую совершают отвергая нулевую гипотезу, принимая альтернативную.
Верхняя |
граница |
α<0,05 |
статистической |
значимости содержит |
довольно большую вероятность ошибки(5%). Поэтому в тех случаях, когда |
||||
требуется особая уверенность в достоверности полученных результатов, |
||||
принимается |
значимость |
α<0,01 |
или даже |
α<0,001 (токсикология, |
фармакология). |
|
|
|
|
В статистике используют понятиядоверительная вероятность P = 1 – |
||||
α, это вероятность достаточная для того, чтобы с уверенностью судить о принятом статистическом решении.
При: α = 0,05 |
Р = 95%; |
α = 0,01 |
Р = 99%; |
α = 0,001 |
Р = 99,9%. |
Интервал, в котором с заданной доверительной вероятностьюP=1 – α, находится оцениваемый параметр, называется доверительным интервалом.
Следует помнить, что, если выборки небольшие по объёму, то распределение вероятности не следует точно нормальному закону.
ВЫЯВЛЕНИЕ ДОСТОВЕРНОСТИ РАЗЛИЧИЙ
Для выявления достоверности различий между выборками пользуются различными математическими критериями. Рассмотрим некоторые из них.
Критерий Стьюдента позволяет найти вероятность того, что средние значения выборок принадлежат одной и той же генеральной совокупности, т.е. выборки взяты из одной и той же генеральной совокупности. Для оценки
достоверности события по критерию Стьюдента |
принимается нулева |
гипотеза, что средние выборок равны между собой. |
|
В среде электронных таблиц Microsoft Excel этот критерий реализуется |
|
функцией ТТЕСТ(M1,M2,Хв, Тип), где М1 – массив |
первой выборки |
(например, контрольная группа), М2 – массив второй выборки(например, исследуемая группа), Хв – хвосты распределения (может принимать значения 1 или 2), Тип – тип теста (значения от 1 до 3).
Параметр Хвосты предусматривает возможность ввода значений:
1 – одностороннее распределение, 2 – двустороннее.
Параметр Тип определяет вид выполняемого теста: |
|
|
||||
· |
1 – |
парный (используются пары данных), |
|
|
||
· |
2 – |
|
двухвыборочный (сравнение |
двух разных |
выборокс |
|
равными дисперсиями), |
|
|
|
|||
· |
3 |
– |
двухвыборочный (разные |
выборки |
с |
неравными |
дисперсиями). |
|
|
|
|||
Втех случаях, когда используются две группы, состоящие из одних
итех же пациентов, используется значение параметра Тип равное 1, разных – Тип равен 3.
8

При |
использовании |
критерия |
Стьюдента |
следует |
иметь |
вв |
|
следующие ограничения на его применение: |
|
работы смалыми |
|
||||
1) |
Этот критерий |
может применятьсядля |
|
||||
выборками от 4 до 100 единиц; |
|
|
|
|
|
|
|
2) |
Распределение |
элементов |
выборок |
должно |
подчинят |
||
нормальному закону распределения (Гаусса). |
|
|
|
|
|
||
Пример использования функции ТТЕСТ( ), приведен на рис. |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. Вид фрагмента листа Excel с функцией ТТЕСТ( )
В качестве параметров функции ТТЕСТ(), представленной на рис. 16. взяты интервалы размещения массивов группы 1 – С4:С8, группы 2 – D4:D8, значение параметра Хвосты равно 2 (двустороннее распределение), параметр
Тип равен 3 (разные пациенты). |
|
|
|
|
|||
Для |
оценки |
меры |
соответствия(расхождения) |
полученных |
|||
эмпирических |
данных |
и |
каких-либо |
теоретическихраспределений |
|||
применяются критерии согласия. |
|
|
|
|
|||
Критериями |
согласия называют |
статистические |
критерии, |
||||
предназначенные для проверки согласияопытных данных и теоретической |
|||||||
модели. |
|
|
|
|
|
|
|
Формально |
задача |
нахождения различий между контрольными и |
|||||
опытными группами (или несколькими группами) методически близка задаче |
|||||||
нахождения |
|
различий |
|
между |
эмпирическим |
и |
теоре |
распределениями. В такой ситуации исключается только этап формирования теоретического распределения, которое заменяется данными о контрольной группе.
Рассмотрим критерий согласия(Пирсона c2 ) Хи-квадрат, который в среде ЭТ Microsoft Excel реализует функция ХИ2ТЕСТ (М1;М2), где М1 – фактический интервал, М2 – ожидаемый.
Критерий согласия c2 – используется, когда необходимо подтвердить или отвергнуть гипотезу совпадении законов распределенияслучайной величины в двух выборках.
При использовании этого критерия принимается нулевая гипотеза(H0) о том, законы распределения равны между собой в двух группах выборок и
9
альтернативная гипотеза (H1) о том, что эти законы различны. Определяется вероятность применимости нулевой гипотезы(функция ХИ2ТЕСТ()). Если эта вероятность превосходит некоторую величину, называемую уровнем
значимости (0,05), |
то считают, что нулевая гипотеза не противоречит |
опытным данным, |
и она может быть принята. |
Применение этого критерия имеет ряд следующих особенностей: |
|
1) Непараметрический критерий согласия Пирсона c2 получил большое распространение, так как даёт возможность его использования сразличными
формами |
распределений |
совокупностей. Основное |
преимущество c2- |
критерия |
в его гибкости. |
Этот критерий можно применять для проверки |
|
допущения о любом распределении, даже не зная параметров распределения. 2) Основной недостаток этого критерия– нечувствительность к
обнаружению адекватной модели, когда число наблюдений невелико. Рассмотрим пример применения критерия согласия Пирсона.
Постановка задачи.
Дано: Две группы пациентов. В одной группе 100 человек, в другой 60.
Во время эпидемии контрольнойв |
группе |
заболело60 |
человек, а в |
||||
вакцинированной - 40 человек. |
|
|
|
|
|
||
Требуется определить: эффективность действия вакцины. |
|
|
|||||
Нам |
известно фактическое |
распределение |
пациентов, требуется |
||||
определить теоретическое распределение (т.е. ожидаемое) предполагая, что |
|||||||
вид распределений в этих совокупностях одинаков. |
|
|
|
||||
При |
определении ожидаемого |
значения результата |
полагают, что |
||||
средние значения в выборках(фактическое распределение и ожидаемое) |
|||||||
равны. В связи с тем, что в двух группах разное количество пациентов, |
|||||||
определим среднее арифметическое между относительнымизначениями |
|||||||
больных пациентов в этих группах, как: (60/100+40/60)/2=(0,6+0,67)/2=0,63. |
|||||||
Таким |
образом, при |
полученном |
среднем |
значении |
относительного |
||
количества больных |
в контрольной |
группе |
должно заболеть63 пациента |
||||
(0,63*100), а в вакцинированной: 0,63*60=37,8 человек.
Зная количество больных и общее количество пациент, можнов определить количество здоровых в каждой группе. В контрольной группе количество здоровых равно 100 - 63 = 37 человек, в вакцинированной – 60 – 37,8 =22,2 человека. Округлим полученные значения до целых.
Вид фрагмента листа ЭТ с решением этой задачи представлен на рис. В качестве параметров функции ХИ2ТЕСТ(), как показано на рис.,
используются интервалы ячеекВ5:С6, В9:С10 – соответственно для фактического и ожидаемого распределений.
Рис. Вид фрагмента листа Excel с функцией ХИ2ТЕСТ( )
Рассмотрим алгоритм анализа полученных значений в результате применения рассмотренных выше критериев.
Как отмечалось выше, оба критерия возвращаютвероятность справедливости нулевой гипотезы.
Алгоритм анализа полученного результата.
10