

Представление простых типов данных языков программирования
Разные языки программирования позволяют использовать разные типы данных. Одни и те же машинные форматы в разных языках называются по разному. Однако, если не принимать во внимание сильно специфические языки, вроде Lisp, то окажется, что все не так безнадежно.
Символы (char, unsigned char, character). Казалось бы, что может быть проще? Но давайте заглянем внутрь. Начнем с того, что один алфавитно-цифровой символ совсем не обязательно занимает один байт. Причина кроется в необходимости поддерживать несколько национальных алфавитов, причем некоторые, например китайский, сожержат куда больше 255 символов, которые можно представить одним байтом. Кроме однобайтовых кодовых таблиц, таких как CP866, Windows-1251, koi8-r, существуют кодовые таблицы с символами переменной длины. Вы наверно встречали абревиатуры DBCS, набор двухбайтных символов, или MBCS, набор многобайтных символов. Это кодовые таблицы символов переменной длины. Работа с такими символами не удобна и медленна. Поэтому была сдела попытка ввести международный стандарт. На роль такого стандарта была выдвинута кодировка UNICODE. Каждый символ в Unicode занимает два байта. Причем сюда входит и информация о стране, т.е. наборе национальных или специальных символов, и сам символ. К сожалению, кодировка Unicode не сняла всех проблем. Да и вспоминают о ней чаще всего тогда, когда пишут программы поддерживающие несколько национальных языков. Итак. Алфавитно-цифровые символы, или просто символы, как бы они не назывались в различных языках, чаще всего храняться в байте. При чем в некоторых языках, например в С, даже различают знаковые и беззнаковые символы. Кодировка Unicode требует для хранения символа двух байт, или, по другому, слова (короткого).
Целые числа (int, integer, long, short, unsigned int, unsigned long, unsigned short). Могут быть представлены байтом, словом, двойным словом. Это зависит от транслятора. В версиях языка С, работавших еще на машинах PDP (16 разрядные машины), тип int занимал два байта, short один байт, long четыре байта. Это было логично и диктовалось архитектурой PDP. Однако с тех пор прошло много времени, язык стремительно набирал популярность и переносился на другие аппаратные платформы, в том числе на 8 и 32 разрядные. Естественное соответствие длины и названия было утеряно. В настоящее время, можно с уверенностью сказать лишь то, что short занимает не больше разрядов, чем int, а int не больше чем long. Для IBM PC, 16 разрядные версии трансляторов С размещает int и short в двух байтах (в слове), а long в четырех (в длинном слове). 32 разрядные версии тех же трансляторов размещают short в двух байтах (слово), а int и long в четырех (длинное слово). Unsigned, как и следовало ожидать, означает беззнаковое представление. Трансляторы языков Fortran, Pascal и им подобных, не обеспечивающих такого разнообразия целых типов, как язык С, всегда хранят целые числа с естественным, для конкретного процессора, числом разрядов. Для 16 разрядных версий, это слово, для 32 разрядных - двойное слово. Кроме того, в этих языках целые числа всегда имеют знак.
Числа с плавающей запятой, вещественные числа (real, float, double, double precision).Обеспечивают работу с числами, имеющими целую и дробную части. Для процессоров, не имеющих аппаратуры для работы с такими числами, обычно предусматривается программная эмуляция соответствующего аппаратного обеспечения. Это позволяет работать с вещественными числами на любом компьютере. Однако время выполнения программ, в случае эмуляции, довольно значительно возрастает. Числа с плавающей запятой всегда имеют знак. Типы real и float хранятся как числа одинарной точности, занимая 32 разряда (двойное слово). Типы double и double precision хранятся как числа двойной точности, занимая 64 разряда (квадро слово). Формат расширенной точности не доступен из языков программирования высокого уровня. Трансляторы для компьютеров моделей отличных от IBM PC, например Mac, или использующих процессоры отличные от Intel совместимых, могут использовать другие форматы хранения чисел с плавающей запятой.
Упакованные десятичные числа, числа в формате BCD.Некоторые реализации языков программирования предлагают нестандартные типы данных: упакованные числа, числа в формате BCD. Ничего мистического в этих форматах нет. Чаще всего они используются для представления целых чисел большой длины или для арифметики сверхвысокой точности. При этом каждый байт содержит по две цифры числа, а само число может занимать любое количество байт.
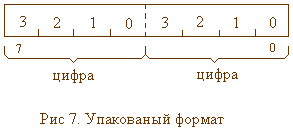
Вычисления высокой точности, причем гарантированой, можно выполнять и над числами, представлеными в символьной форме. Но такое представление требует в два раза больше памяти, чем упакованый формат, так как каждый байт будет содержать только одну цифру.
Половина байта, состоящая из 4 бит, называется тетрада. Четырех бит достаточно для представления чисел от 0 до 15 (0F). Так как в десятичной арифметике используются только цифры от 0 до 9, то тетрада как раз подходит для размещения одной десятичной цифры. Значения от 10 (0A) до 15 (0F) являются запрещенными и требуют выполнения процедур коррекции результата. С упакованными числами связано понятие еще одного признака результата (флажка) - дополнительный перенос (AF). Это перенос между тетрадами в байте, когда значение младшей тетрады превышает 9. Рассмотрим пример сложения десятичных чисел 15+28=43. А теперь, как это выглядит для BCD формата: 15+28=3D. Видно, что результат требует коррекции, младшая тетрада должна быть 10-D=3. И возникает перенос между тетрадами, так как младшая тетрада больше 9. В результате значение старшей тетрады увеличивается на 1. Результат коррекции будет правильным - 43. По аналогичным правилам выполняются и другие арифметические операции. В процессорах Intel 80х86 предусмотрены специальные команды для выполнения операций над числами в формате BCD. Предусмотрен и флажек AF.