

Кодирование сообщений источника и текстов. Равномерное кодирование. Дерево кода
Чаще всего информация представляется в виде языковых сообщений (цепочек знаков или слов), причем в процессе ее обработки форма представления может меняться. Например, сообщение, предназначенное для передачи по телеграфу, первоначально может быть представлено в виде рукописного текста. Телеграфист переводит это сообщение в последовательность длинных, коротких импульсов и пауз, передающихся по телеграфному каналу. А на приемном конце такая последовательность может быть преобразована в печатный текст. Рассмотренные преобразования представляют собой пример кодирования сообщений. Еще одним примером кодирования является тайнопись, когда исходное сообщение преобразуется в другую форму, скрывающую содержание исходного сообщения.
Различные
задачи кодирования можно формализовать
следующим образом. Пусть ![]() и
и ![]() алфавиты,
алфавиты, ![]() некоторое
множество слов в алфавите
некоторое
множество слов в алфавите ![]() .
Тогда функция
.
Тогда функция
![]()
называется кодированием или кодом.
Кодом называется также образ отображения ![]() ,
обозначаемый
,
обозначаемый ![]() .
Если существуетобратная
функция
.
Если существуетобратная
функция ![]() ,
то она называется декодированием.
Одно и то же множество сообщений можно
закодировать многими различными
способами. Поэтому среди многих вариантов
кодирования ищут такой, который был бы
оптимальным в некотором смысле или
обладал определенными полезными
свойствами. Наиболее естественным
требованием является возможность
декодирования.
,
то она называется декодированием.
Одно и то же множество сообщений можно
закодировать многими различными
способами. Поэтому среди многих вариантов
кодирования ищут такой, который был бы
оптимальным в некотором смысле или
обладал определенными полезными
свойствами. Наиболее естественным
требованием является возможность
декодирования.
Побуквенное
(алфавитное) кодирование.
Обычно, кодирование множества
слов ![]() производится
с помощью функции кодирующей отдельные
буквы алфавита
производится
с помощью функции кодирующей отдельные
буквы алфавита ![]() .
Для этого случая определение кода будет
следующим.
.
Для этого случая определение кода будет
следующим.
Кодом называется отображение
|
|
( 6.2) |
сопоставляющее
каждому знаку из алфавита ![]() некоторое
слово, которое составлено из знаков,
входящих в
некоторое
слово, которое составлено из знаков,
входящих в ![]() .
Слова, входящие в
.
Слова, входящие в ![]() ,
называются кодовыми словами. Отображение
(6.2) может задаваться любым из известных
в математике способов. Для конечного
множества
,
называются кодовыми словами. Отображение
(6.2) может задаваться любым из известных
в математике способов. Для конечного
множества ![]() чаще
всего используется табличный способ,
задающий код (6.2) таблицей.
чаще
всего используется табличный способ,
задающий код (6.2) таблицей.
|
Кодируемая буква алфавита А |
Кодовое слово |
|
|
|
|
|
|
|
|
|
|
|
|
Такая
таблица называется кодовой таблицей.
В качестве примера можно привести
таблицу кодирования алфавита ![]() из
цифр восьмеричной
системы счисления словами
из упоминавшегося ранее бинарного
алфавита
из
цифр восьмеричной
системы счисления словами
из упоминавшегося ранее бинарного
алфавита ![]() .
В данном случае отображение (6.2) имеет
вид
.
В данном случае отображение (6.2) имеет
вид ![]() .
.
|
Кодируемый знак |
Кодовое слово |
|
0 |
000 |
|
1 |
001 |
|
2 |
010 |
|
3 |
011 |
|
4 |
100 |
|
5 |
101 |
|
6 |
110 |
|
7 |
111 |
Еще одним примером является так называемый код ASCII, фрагмент которого показан в следующей таблице.
|
Знак |
Кодовое слово (в десятичной системе счисления) |
Кодовое слово (в шестнадцатеричной системе счисления) |
|
… |
… |
|
|
a |
97 |
61 |
|
b |
98 |
62 |
|
c |
99 |
63 |
|
d |
100 |
64 |
|
e |
101 |
65 |
|
f |
102 |
66 |
|
g |
103 |
67 |
|
h |
104 |
68 |
|
i |
105 |
69 |
|
j |
106 |
6A |
|
… |
… |
|
Кодирование
слов.
Отображение (6.2) позволяет перейти от
кодирования отдельных знаков (букв
конечного алфавита) к кодированию слов.
Если ![]() -
слово, состоящее из знаков (полученное
конкатенацией знаков)
-
слово, состоящее из знаков (полученное
конкатенацией знаков) ![]() ,
то кодом
,
то кодом ![]() слова
слова ![]() (по
определению) является конкатенация
кодов
(по
определению) является конкатенация
кодов ![]() знаков
знаков ![]() ,
образующих слово, т. е.
,
образующих слово, т. е. ![]() .
Например, с применением таблицы ASCII кода
(см. последнюю таблицу) слово head будет
закодировано последовательностью
10410197100 при использовании десятичной
системы счисления или последовательностью
68656164 - в шестнадцатеричной.
.
Например, с применением таблицы ASCII кода
(см. последнюю таблицу) слово head будет
закодировано последовательностью
10410197100 при использовании десятичной
системы счисления или последовательностью
68656164 - в шестнадцатеричной.
Условие
(необходимое) однозначной
декодируемости заключается
в инъективности отображения (6.2).
Инъективность обеспечивает однозначную
декодируемость отдельных знаков из
алфавита ![]() .
Однако однозначной декодируемости слов
из
.
Однако однозначной декодируемости слов
из ![]() это
условие не обеспечивает, если коды
отдельных знаков, входящих в слово,
следуют один за другим и не разделяются
специальным символом. Подробнее проблема
однозначной декодируемости будет
рассмотрена позже.
это
условие не обеспечивает, если коды
отдельных знаков, входящих в слово,
следуют один за другим и не разделяются
специальным символом. Подробнее проблема
однозначной декодируемости будет
рассмотрена позже.
В
частном случае, когда знаки из ![]() кодируются
однобуквенными словами, отображение
(6.2) имеет вид
кодируются
однобуквенными словами, отображение
(6.2) имеет вид ![]() и
представляет собой простую замену
(подстановку) знаков. Однако чаще всего,
в основном из-за использования в
большинстве технических устройств
обработки информации двоичного
алфавита
и
представляет собой простую замену
(подстановку) знаков. Однако чаще всего,
в основном из-за использования в
большинстве технических устройств
обработки информации двоичного
алфавита ![]() ,
каждый знак из
,
каждый знак из ![]() кодируется
последовательностью знаков (словом) из
B.
кодируется
последовательностью знаков (словом) из
B.
Недостаточность
количества знаков в алфавите ![]() является
препятствием применения простой замены
для кодирования (не обеспечивается
инъективность и, следовательно,
однозначность декодируемости при
является
препятствием применения простой замены
для кодирования (не обеспечивается
инъективность и, следовательно,
однозначность декодируемости при ![]() ).
Для устранения этой проблемы используются
множества новых, "составных"
объектов из степеней
).
Для устранения этой проблемы используются
множества новых, "составных"
объектов из степеней ![]() алфавита
алфавита ![]() .
Множество
.
Множество ![]() состоит
из упорядоченных последовательностей
элементов из
состоит
из упорядоченных последовательностей
элементов из ![]() (векторов)
длины
(векторов)
длины ![]() .
Число элементов
.
Число элементов ![]() множества
множества ![]() равно
равно ![]() .
Например, для двоичного алфавита
.
Например, для двоичного алфавита ![]() имеем
имеем ![]() .
Таким образом, взяв достаточно большую
степень
.
Таким образом, взяв достаточно большую
степень ![]() ,
можно получить нужное количество
элементов вторичного алфавита.
,
можно получить нужное количество
элементов вторичного алфавита.
Если
каждый знак алфавита ![]() отображается
при кодировании
отображается
при кодировании ![]() в
слово одинаковой длины
в
слово одинаковой длины ![]() ,
то говорят, что код является кодом
постоянной длины.
Такие коды широко распространены,
поскольку для обработки сообщений
используются вычислительные машины,
коммуникацион-ные устройства и другое
оборудование, имеющее регистры
фиксированного размера.
,
то говорят, что код является кодом
постоянной длины.
Такие коды широко распространены,
поскольку для обработки сообщений
используются вычислительные машины,
коммуникацион-ные устройства и другое
оборудование, имеющее регистры
фиксированного размера.
Процедуру
кодирования слова ![]() в
алфавите
в
алфавите ![]() можно
представить следующим образом. Имеется
кодовая таблица, в левом столбце которой
находятся кодируемые буквы алфавита
можно
представить следующим образом. Имеется
кодовая таблица, в левом столбце которой
находятся кодируемые буквы алфавита ![]() ,
а в правом столбце - соответствующие
кодовые слова (кодовые слова могут иметь
различную длину).
,
а в правом столбце - соответствующие
кодовые слова (кодовые слова могут иметь
различную длину).
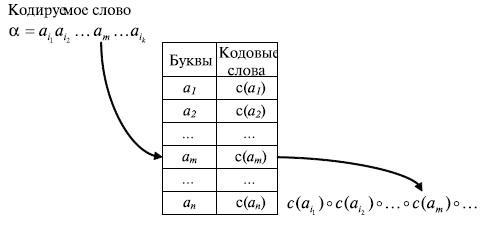
Рис. 6.4. Процедура кодировании слов с использованием кодовой таблицы
Для
каждого знака слова ![]() ,
начиная с первого знака, в кодовой
таблице находится строка, в которой в
левом поле располагается кодируемый
знак (буква), и из правого поля этой
строки берется соответствующее кодовое
слово в алфавите
,
начиная с первого знака, в кодовой
таблице находится строка, в которой в
левом поле располагается кодируемый
знак (буква), и из правого поля этой
строки берется соответствующее кодовое
слово в алфавите ![]() .
Найденное кодовое слово приписывается
слева (конкатенируется) к уже сформированной
части кода слова
.
Найденное кодовое слово приписывается
слева (конкатенируется) к уже сформированной
части кода слова ![]() .
Кодовое слово первой буквы
слова
.
Кодовое слово первой буквы
слова ![]() приписывается
к пустому слову е. Эта процедура
схематически показана на рис.6.4.
приписывается
к пустому слову е. Эта процедура
схематически показана на рис.6.4.
Неравномерное кодирование. Средняя длина кодирования
В приведенных выше примерах кодирования все кодовые слова имели одинаковую длину. Однако это не является обязательным требованием. Более того, если вероятности появления сообщений заметно отличаются друг от друга, то сообщения с большой вероятностью появления лучше кодировать короткими словами, а более длинными словами кодировать редкие сообщений. В результате кодовый текст при определенных условиях станет в среднем короче.
Показателем экономичности или эффективности неравномерного кода является не длина отдельных кодовых слов, а "средняя" ихдлина, определяемая равенством:
![]()
где ![]() - кодовое
слово,
которым закодировано сообщение
- кодовое
слово,
которым закодировано сообщение ![]() ,
а
,
а ![]() -
его длина,
-
его длина, ![]() - вероятность сообщения
- вероятность сообщения ![]() ,
,![]() -
общее число сообщений источника
-
общее число сообщений источника ![]() .
Для краткости записи формул далее могут
использоваться обозначения
.
Для краткости записи формул далее могут
использоваться обозначения ![]() и
и ![]() .
Заметим, что обозначение средней длины
кодирования через
.
Заметим, что обозначение средней длины
кодирования через ![]() подчеркивает
тот факт, что эта величина зависит как
отисточника
сообщений
подчеркивает
тот факт, что эта величина зависит как
отисточника
сообщений ![]() ,
так и от способа кодирования
,
так и от способа кодирования ![]() .
.
Наиболее
экономным является код с наименьшей
средней длиной ![]() .
Сравним на примерах экономичность
различных способов кодирования одного
и того же источника.
.
Сравним на примерах экономичность
различных способов кодирования одного
и того же источника.
Пусть
источник содержит 4 сообщения ![]() с
вероятностями
с
вероятностями ![]() .
Эти сообщения можно закодировать
кодовыми словами постоянной длины,
состоящими из двух знаков, в алфавите
.
Эти сообщения можно закодировать
кодовыми словами постоянной длины,
состоящими из двух знаков, в алфавите ![]() в
соответствии с кодовой таблицей.
в
соответствии с кодовой таблицей.
|
|
00 |
|
|
01 |
|
A_3 |
10 |
|
A_4 |
11 |
Очевидно, что для представления (передачи) любой последовательности в среднем потребуется 2 знака на одно сообщение. Сравним эффективность такого кодирования с описанным выше кодированием словами переменной длины. Кодовая таблица для данного случая может иметь следующий вид.
|
|
0 |
|
|
1 |
|
|
10 |
|
|
11 |
В
этой таблице, в отличие от предыдущей,
наиболее частые сообщения ![]() и
и ![]() кодируются
одним двоичным знаком. Для последнего
варианта кодирования имеем
кодируются
одним двоичным знаком. Для последнего
варианта кодирования имеем
![]()
в
то время как для равномерного кода
средняя длина ![]() (она
совпадает с общей длиной кодовых слов).
Из рассмотренного примера видно,
что кодирование сообщений
словами различной длины может дать
суще-ственное (почти в два раза) увеличение
экономичности кодирования.
(она
совпадает с общей длиной кодовых слов).
Из рассмотренного примера видно,
что кодирование сообщений
словами различной длины может дать
суще-ственное (почти в два раза) увеличение
экономичности кодирования.
При
использовании неравномерных кодов
появляется проблема, которую поясним
на примере последней кодовой таблицы.
Пусть при помощи этой таблицы кодируется
последовательность сообщений ![]() ,
в результате чего она преобразуется в
следующий двоичный текст: 010110. Первый
знак исходного сообщения декодируется
однозначно - это
,
в результате чего она преобразуется в
следующий двоичный текст: 010110. Первый
знак исходного сообщения декодируется
однозначно - это ![]() .
Однако дальше начинается
неопределенность:
.
Однако дальше начинается
неопределенность: ![]() или
или ![]() .
Это лишь некоторые из возможных вариантов
декодирования исходной последовательности
знаков.
.
Это лишь некоторые из возможных вариантов
декодирования исходной последовательности
знаков.
Необходимо отметить, что неоднозначность декодирования слова появилась несмотря на то, что условие однозначности декодирования знаков (инъективность кодового отображения) выполняется.
Существо
проблемы - в невозможности однозначного
выделения кодовых слов. Для ее решения
следовало бы отделить однокодовое
слово от
другого. Разумеется, это можно сделать,
но лишь используя либо паузу между
словами, либо специальный разделительный
знак, для которого необходимо особое
кодовое обозначение. И тот, и другой путь,
во-первых, противоречат описанному выше
способу кодирования слов путем
конкатенации кодов ![]() знаков
знаков ![]() ,
образующих слово,
и, во-вторых, приведет к значительному
удлинению кодового текста, сводя на нет
преимущества использования кодов
переменной длины.
,
образующих слово,
и, во-вторых, приведет к значительному
удлинению кодового текста, сводя на нет
преимущества использования кодов
переменной длины.
Решение данной проблемы заключается в том, чтобы иметь возможность в любом кодовом тексте выделять отдельные кодовые слова без использования специальных разделительных знаков. Иначе говоря, необходимо, чтобы код удовлетворял следующему требованию: всякая последовательность кодовых знаков может быть единственным образом разбита на кодовые слова. Коды, для которых последнее требование выполнено, называются однозначно декодируемыми (иногда их называют кодами без запятой).
Рассмотрим
код (схему алфавитного кодирования) ![]() ,
заданный кодовой таблицей
,
заданный кодовой таблицей
и различные слова, составленные из элементарных кодов.
Определение.
Код ![]() называется
однозначно декодируемым, если
называется
однозначно декодируемым, если
![]()
и
![]()
то есть любое слово, составленное из элементарных кодов, единственным образом разлагается на элементарные коды.
Если таблица кодов содержит одинаковые кодовые слова, то есть если
![]()
то код заведомо не является однозначно декодируемым (схема не является разделимой). Такие коды далее не рассматриваются.
Префиксные коды
Наиболее простыми и часто используемыми кодами без специального разделителя кодовых слов являются так называемые префиксные коды [29].
Определение. Код, обладающий тем свойством, что никакое кодовое слово не является началом (префиксом) другого кодового слова, называется префиксным.
Теорема 1. Префиксный код является однозначно декодируемым.
Доказательство.
Предположим противное. Тогда
существует слово ![]() которое
можно представить двумя разными
способами
которое
можно представить двумя разными
способами ![]() ,
причем до номера
,
причем до номера ![]() все
подслова в обоих представлениях
(разложениях) совпадают, а слова
все
подслова в обоих представлениях
(разложениях) совпадают, а слова ![]() и
и ![]() различны.
Отбросив одинаковые префиксы двух
равных слов (представлений), получим
совпадающие окончания
различны.
Отбросив одинаковые префиксы двух
равных слов (представлений), получим
совпадающие окончания ![]() ,
начинающиеся с различных слов. Из-за
равенства окончаний первые буквы
слов
,
начинающиеся с различных слов. Из-за
равенства окончаний первые буквы
слов ![]() и
и ![]() должны
совпадать. По аналогичной
причине должны совпадать и вторые буквы
этих слов и т.д. Это означает,
что неравенство слов
должны
совпадать. По аналогичной
причине должны совпадать и вторые буквы
этих слов и т.д. Это означает,
что неравенство слов ![]() и
и ![]() может
заключаться только в том, что они имеют
разную длину и, следовательно, одно из
них является префиксом другого. Это
противоречит префиксности кода.
может
заключаться только в том, что они имеют
разную длину и, следовательно, одно из
них является префиксом другого. Это
противоречит префиксности кода.
Множество кодовых слов можно графически изобразить как поддерево словарного дерева (рис.6.5). Для этого из всего словарного дерева следует показать только вершины, соответствующие кодовым словам, и пути, ведущие от этих вершин к корню дерева. Такое поддерево называют деревом кода или кодовым деревом.
На рис.6.5 а) - дерево, соответствующие коду, у которого все слова имеют одинаковую длину. Кружками помечены те вершины, которые соответствуют кодовым словам. В данном случае это 4 двухбуквенных слова, составляющих второй уровень словарного дерева (универсума). Нетрудно понять, как отражается свойство префиксности или его отсутствие на кодовом дереве. Рассмотрим код, состоящий из слов (0, 10, 111). Это не полный префиксный код, так как к коду можно добавить слово 110, которое получается из слова 11 приписыванием справа 0. Эта операция показана на рис.6.5 б) пунктирным ребром. На рис.6.5 в) показано дерево полного префиксного кода. В данном случае вершины, соответствующие словам префиксного кода, как бы "разрезают" словарный универсум на две части - "верхнюю" и "нижнюю". Если попытаться добавить слово "выше" кодовых слов, то одно из кодовых слов станет префиксом добавляемого слова. Если добавлять слово "ниже" слов префиксного кода, то добавляемое слово окажется префиксом одного из кодовых слов. В обоих случаях нарушается свойство префиксности. На рис.6.5г) представлено дерево для рассмотренного ранее кода, не обладающего свойством префиксности. Таким образом, если свойство префикса не выполняется, то некоторые промежуточные вершины дерева могут соответствовать кодовым словам.
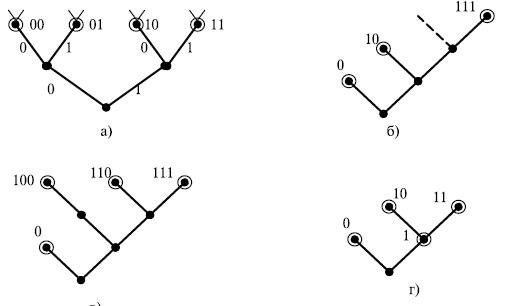
Рис. 6.5. Деревья различных кодов
Замечание. Свойство префиксности является достаточным, но не является необходимым для однозначной декодируемости.
Пример. Код, состоящий из двоичных кодовых слов 1, 10, - не префиксный, но может быть однозначно декодирован. Появление символа 1 означает начало нового кодового слова. Последнее остается справедливым для кода, каждое слово которого естьединица с последующими нулями. Разумеется, подобные коды далеко не самые экономные.
Если код префиксный, то, читая кодовую запись подряд от начала, мы всегда сможем разобраться, где кончается одно кодовое слово и начинается следующее. Если, например, в кодовой записи встретилось кодовое обозначение 110, то разночтений быть не может, так как в силу префиксности наш код не содержит кодовых обозначений 1, 11 или, скажем, 1101. Именно так обстояло дело для рассмотренного выше кода, который очевидно является префиксным.
Необходимые и достаточные условия существования префиксного кода с заданными длинами кодовых слов. Неравенство Крафта
Для применения кода на практике желательно, чтобы кодовые слова были как можно короче. Однако чем слова короче, тем их запас меньше. В этом легко убедиться, посмотрев на изображение словарного универсума на рис.6.3. Если попытаться построитьпрефиксный код с очень короткими длинами кодовых слов, то можно потерпеть неудачу - кода с такими длинами слов может не быть. Например, нетрудно убедиться, что не существует префиксного кода с длинами слов 1, 1, 2. При необходимости построить префиксный код с большим числом кодовых слов заданной длины проверка существования такого кода может быть достаточно сложной. К счастью, найдены необходимые и достаточные условия на длины кодовых слов для существования префиксного и любого однозначно декодируемого кода. Эти условия известны как теорема Крафта - Мак-Милана. Необходимые и достаточные условия сформулируем в виде двух теорем.
Теорема
(необходимые условия). Пусть ![]() -
префиксный двоичный код с длинами
кодовых слов
-
префиксный двоичный код с длинами
кодовых слов ![]() .
Тогда выполняется неравенство
Крафта
.
Тогда выполняется неравенство
Крафта
|
|
( 6.3) |
Доказательство.
Рассмотрим, сколько слов длины ![]() может
быть в префиксном коде. Максимальное
число таких слов равно
может
быть в префиксном коде. Максимальное
число таких слов равно ![]() .
В этом случае все
.
В этом случае все ![]() кодовых
слова имеют длину
кодовых
слова имеют длину ![]() .
.
Для
каждого кодового слова длины ![]() имеется
имеется ![]() слов
длины
слов
длины ![]() ,
для которых данное слово является
префиксом и по этой
причине не является кодовым. Это следует
из структуры словарного дерева (см. рис.
6.3). Множества
,
для которых данное слово является
префиксом и по этой
причине не является кодовым. Это следует
из структуры словарного дерева (см. рис.
6.3). Множества ![]() и
и ![]() слов
длины
слов
длины ![]() ,
для которых кодовые слова
,
для которых кодовые слова ![]() и
и ![]() являются
префиксами, не пересекаются, так как в
противном случае более короткое из этих
слов было бы префиксом более длинного.
Значит, если в префиксном коде
имеется
являются
префиксами, не пересекаются, так как в
противном случае более короткое из этих
слов было бы префиксом более длинного.
Значит, если в префиксном коде
имеется ![]() слов
длины
слов
длины ![]() слов
длины
слов
длины ![]() слов
длины 1, то число
слов
длины 1, то число ![]() слов
длины
слов
длины ![]() удовлетворяет
неравенству
удовлетворяет
неравенству
|
|
( 6.4) |
Это неравенство верно
для любого ![]() ,
в том числе и для
,
в том числе и для ![]() ,
равного максимальной длине кодовых
слов. После деления на
,
равного максимальной длине кодовых
слов. После деления на ![]() обеих
частей неравенства (6.4) его можно
преобразовать к виду
обеих
частей неравенства (6.4) его можно
преобразовать к виду
|
|
( 6.5) |
Слагаемое
вида ![]() ,
представляющее в неравенстве
(6.5)
,
представляющее в неравенстве
(6.5) ![]() кодовых
слов длины
кодовых
слов длины ![]() ,
можно записать в виде суммы
,
можно записать в виде суммы
![]()
С учетом такого представления неравенство (6.5) можно переписать следующим образом:
![]()
где ![]() -
общее число слов префиксного
кода.
Теорема доказана.
-
общее число слов префиксного
кода.
Теорема доказана.
Выполнение неравенства Крафта доказано для префиксного кода. Однако в 1956 году Мак-Милан доказал более общую теорему, согласно которой неравенство Крафта выполняется и для любого однозначно декодируемого кода. Доказательство теоремы изложено в [29], [31].
Можно также доказать, что если префиксный код полный, то в нестрогом неравенстве (6.3) будет выполняться равенство.
Теорема
(достаточные условия). Если положительные
целые числа ![]() удовлетворяют неравенству
Крафта
удовлетворяют неравенству
Крафта
![]()
то
существует префиксный
код ![]() с
длинами кодовых слов
с
длинами кодовых слов ![]()
Доказательство.
Если среди чисел ![]() имеется
ровно
имеется
ровно ![]() чисел,
равных
чисел,
равных ![]() ,
то неравенство
Крафта можно
записать в виде
,
то неравенство
Крафта можно
записать в виде
![]()
где ![]() -
максимальное из данных чисел. Из
справедливости этого неравенства
следует, что верны неравенства (6.5) для
всех
-
максимальное из данных чисел. Из
справедливости этого неравенства
следует, что верны неравенства (6.5) для
всех ![]() ,
а следовательно, и неравенство (6.4).
,
а следовательно, и неравенство (6.4).
Для
построения нужного префиксного
кода должна
быть возможность подходящим образом
выбрать ![]() слов
длины 1,
слов
длины 1, ![]() слов
длины 2, вообще
слов
длины 2, вообще ![]() слов
длины
слов
длины ![]() или,
иными словами,
или,
иными словами, ![]() вершин
кодового дерева на первом,
вершин
кодового дерева на первом, ![]() -
на втором,
-
на втором, ![]() -
на
-
на ![]() -м
ярусе.
-м
ярусе.
Из
неравенства (6.4) при ![]() получаем
получаем ![]() ,
т. е. требуемое число не превосходит
общего числа вершин первого яруса.
Значит, на этом ярусе можно выбрать
какие-то
,
т. е. требуемое число не превосходит
общего числа вершин первого яруса.
Значит, на этом ярусе можно выбрать
какие-то ![]() вершин
в качестве концевых (
вершин
в качестве концевых (![]() равно
0, 1 или 2). Если это сделано, то из общего
числа вершин второго яруса (их
равно
0, 1 или 2). Если это сделано, то из общего
числа вершин второго яруса (их ![]() )
для построения кода можно использовать
лишь
)
для построения кода можно использовать
лишь ![]() .
Однако и этого числа вершин хватит, так
как из неравенства (6.4) при
.
Однако и этого числа вершин хватит, так
как из неравенства (6.4) при ![]() вытекает
вытекает
![]()
Аналогично,
при ![]() имеем неравенство:
имеем неравенство:
![]()
Правая
часть его вновь совпадает с допустимым
для построения префиксного
кода числом
вершин третьего яруса, если на первых
двух ярусах уже выбраны ![]() и
и ![]() кодовых
вершин. Значит, снова можно выбрать
кодовых
вершин. Значит, снова можно выбрать ![]() кодовых
вершин на третьем ярусе. Продолжая этот
процесс вплоть до
кодовых
вершин на третьем ярусе. Продолжая этот
процесс вплоть до ![]() ,
мы и получим требуемый код. Теорема
доказана.
,
мы и получим требуемый код. Теорема
доказана.
Докажем,
что если для длин ![]() кодовых
слов выполняется равен - равенство
кодовых
слов выполняется равен - равенство ![]() ,то
код является полным. Предположим
противное, то есть, что код не полный.
Тогда к нему можно добавить, по крайней
мере, одно кодовое
слово (длины
,то
код является полным. Предположим
противное, то есть, что код не полный.
Тогда к нему можно добавить, по крайней
мере, одно кодовое
слово (длины ![]() )
и получить новый префиксный
код,
для которого, с одной стороны,
)
и получить новый префиксный
код,
для которого, с одной стороны, ![]() ,
а с другой стороны, в силу теоремы
Крафта,
,
а с другой стороны, в силу теоремы
Крафта, ![]() Полученное
противоречие доказывает утверждение.
Полученное
противоречие доказывает утверждение.
Теоремы
Крафта доказаны для случая, когда
рассматриваются коды в алфавите ![]() .
Если кодовый алфавит содержит
.
Если кодовый алфавит содержит ![]() символов,
то аналогичным образом можно доказать,
что необходимым и достаточным условием
для существования префиксного
кода с
длинами слов
символов,
то аналогичным образом можно доказать,
что необходимым и достаточным условием
для существования префиксного
кода с
длинами слов ![]() является
выполнение неравенства
является
выполнение неравенства
![]()
Оказывается,
этому неравенству обязаны удовлетворять
и длины кодовых слов произвольного
однозначно декодируемого кода. Поэтому,
если существует однозначно декодируемый
код с длинами слов ![]() ,
то существует и префиксный
код с
теми же длинами слов.
,
то существует и префиксный
код с
теми же длинами слов.
Методы построения кодов. Код Фано
Один
из методов алфавитного кодирования был
предложен Фано. Схема кодирования по методу
Фано заключается в следующем. Предположим,
что кодируемые сообщения источника
(знаки исходного алфавита) располагаются
в последовательности ![]() так,
что соответствующие им вероятности не
возрастают, т. е.
так,
что соответствующие им вероятности не
возрастают, т. е. ![]() .
Рассмотрим разбиения последовательности
A 1, A2, …, AN на две подпоследовательности
.
Рассмотрим разбиения последовательности
A 1, A2, …, AN на две подпоследовательности ![]() и
и ![]() Каждое
такоеразбиение определяется
числом
Каждое
такоеразбиение определяется
числом ![]() ,
которое определяет, сколько элементов
исходной последовательности входит в
первую и вторую части разбиения.
Среди
,
которое определяет, сколько элементов
исходной последовательности входит в
первую и вторую части разбиения.
Среди ![]() разбиения
выберем такое, чтобы модуль разности
разбиения
выберем такое, чтобы модуль разности ![]() был
минимальным. Всем сообщениям из первой
части разбиения в качестве первого
знака кодового слова приписываем 0, а
сообщениям из второй части 1. По тому
же принципу каждая из полученных
подпоследовательностей снова разбивается
на две части, и это раз-биение
определяет значение второго
символа кодового слова. Процедура
продолжается до тех пор, пока все
множество не будет разбито на отдельные
сообщения. В результате каждому из
сообщений будет сопоставлено кодовое
слово из
нулей и единиц.
был
минимальным. Всем сообщениям из первой
части разбиения в качестве первого
знака кодового слова приписываем 0, а
сообщениям из второй части 1. По тому
же принципу каждая из полученных
подпоследовательностей снова разбивается
на две части, и это раз-биение
определяет значение второго
символа кодового слова. Процедура
продолжается до тех пор, пока все
множество не будет разбито на отдельные
сообщения. В результате каждому из
сообщений будет сопоставлено кодовое
слово из
нулей и единиц.
Описанную процедуру построения кода Фано на примере из пяти сообщений иллюстрирует следующая таблица.
|
Таблица 6.1. | |||||
|
Сообщения |
Вероятности сообщений |
Знаки кодовых слов |
Кодовое слово | ||
|
1-й знак |
2-й знак |
3-й знак | |||
|
|
0.4 |
0 |
0 |
|
00 |
|
|
0.15 |
1 |
|
01 | |
|
|
0.15 |
1 |
0 |
10 | |
|
|
0.15 |
1 |
0 |
110 | |
|
|
0.15 |
1 |
111 | ||
Понятно, что чем более вероятно сообщение, тем быстрее оно образует "самостоятельную" группу и тем более коротким словом оно будет закодировано. Это обстоятельство и обеспечивает высокую экономность кода Фано. Код, построенный для данного источника методом Фано, имеет среднюю длину кодового слова равную 2,3.
Код, построенный методом Фано, всегда является префиксным. Действительно, на первом шаге построения кода методом Фано множество сообщений источника разбивается на два подмножества. Все кодовые слова, соответствующие первому подмножеству, имеют однобуквенный префикс, состоящий из 0, а все слова, соответствующие второму подмножеству, имеют однобуквенныйпрефикс, состоящий из 1 (или наоборот). Поэтому ни одно слово, соответствующее какому-нибудь из сообщений из первого подмножества, не может быть префиксом ни для какого слова, соответствующего сообщению из второго подмножества. Аналогичная процедура разбиения применяется к каждому подмножеству сообщений с одинаковыми префиксами при добавлении нового знака к формируемым кодовым словам. При этом число подмножеств, на которые разбивается исходное множество сообщений источника (блоков разбиения), увеличивается. Важным свойством разбиений является то, что для кодовых слов, соответствующих сообщениям из разных блоков разбиения, имеются различные префиксы. Построение кода завершаетсяразбиением множества сообщений на блоки, содержащие по одному сообщению. Из-за отмеченного свойства разбиений ни однокодовое слово не является префиксом другого кодового слова, то есть построенный методом Фано код является префиксным.
Описанный
метод кодирования можно применять и в
случае произвольного алфавита
из ![]() символов,
с той лишь разницей, что на каждом шаге
следует производить разбиение на
символов,
с той лишь разницей, что на каждом шаге
следует производить разбиение на ![]() равновероятных
групп.
равновероятных
групп.
Избыточность кодирования. Нижняя граница средней длины кодирования
Рассмотренные
ранее примеры показывают, что использование
кодов переменной длины позволяет
эффективнее кодировать сообщения по сравнению
с равномерным кодированием. Для получения
оценки минимально достижимой средней
длины кодового слова
рассмотрим избыточность кодирования ![]() ,
представляющую собой разность
,
представляющую собой разность ![]() между
средней длиной кодового слова при
кодировании источника S кодом c и энтропией.
Две следующие теоремы показывают,
какова нижняя
граница средней
длины кодирования и как близко можно
приблизиться к этой границе за счет
рационального выбора кодовых слов.
между
средней длиной кодового слова при
кодировании источника S кодом c и энтропией.
Две следующие теоремы показывают,
какова нижняя
граница средней
длины кодирования и как близко можно
приблизиться к этой границе за счет
рационального выбора кодовых слов.
Для
доказательства первой теоремы напомним
одно свойство логарифма, которое
заключается в том, что график
функции ![]() лежит
ниже касательной к ней в точке
лежит
ниже касательной к ней в точке ![]() ,
и следовательно, выполняется неравенство
,
и следовательно, выполняется неравенство ![]() .
Это свойство иллюстрирует рис.6.6.
.
Это свойство иллюстрирует рис.6.6.
Теорема. Для
произвольного источника ![]() и префиксного
кода
и префиксного
кода ![]() избыточность кодирования
неотрицательна, т. е.
избыточность кодирования
неотрицательна, т. е. ![]() .
.
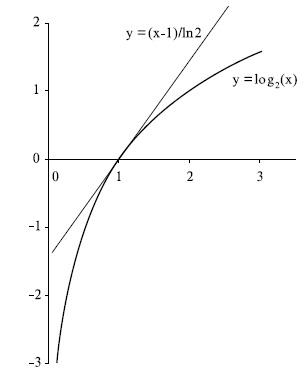
Рис. 6.6. График функции log2(x) и касательной к ней в точке x=1
Доказательство.
![]()
С
учетом отмеченного выше неравенства
для функции ![]() каждое
слагаемое можно оценить сверху следующим
образом:
каждое
слагаемое можно оценить сверху следующим
образом:
![]()
После суммирования получим
![]()
причем
последнее неравенство следует
из неравенства
Крафта (6.3)
для префиксного
кода и
равенства ![]() .
Таким образом,
.
Таким образом, ![]() ,
что доказывает утверждение теоремы.
,
что доказывает утверждение теоремы.
Из
доказанной теоремы следует,
что энтропия источника
является нижней границей средней длины
кодирования. Для источников, у которых
вероятности являются целыми отрицательными
степенями 2, эта граница достижима. Легко
проверить, что для источника с
распределением вероятностей ![]() средняя длина кодирования
равна 1,75 и совпадает с энтропией источника.
средняя длина кодирования
равна 1,75 и совпадает с энтропией источника.
Для
доказательства второй теоремы
потребуется функция ![]() ,
которая называется "потолок" и
определяется выражением
,
которая называется "потолок" и
определяется выражением ![]() .
Необходимые для доказательства свойства
этой функции легко следуют из ее графика,
показанного на рис.6.7,
и заключаются в выполнении неравенств
.
Необходимые для доказательства свойства
этой функции легко следуют из ее графика,
показанного на рис.6.7,
и заключаются в выполнении неравенств ![]() .
.
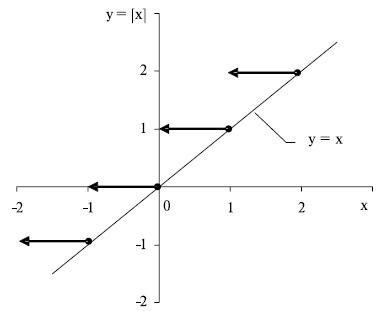
Рис. 6.7. График функции [x]
Теорема.
Для каждого источника ![]() найдется префиксный
код
найдется префиксный
код ![]() , избыточность которого
не превышает единицы, т. е.
, избыточность которого
не превышает единицы, т. е. ![]() .
.
Пусть ![]() ,
где
,
где ![]() функция "потолок".
Тогда
функция "потолок".
Тогда
![]()
Это
означает, что числа ![]() удовлетворяют неравенству
Крафта.
Тогда из теоремы Крафта следует, что
найдется префиксноекодирование
удовлетворяют неравенству
Крафта.
Тогда из теоремы Крафта следует, что
найдется префиксноекодирование ![]() ,
такое что
,
такое что ![]() .
Оценим избыточность этого
кодирования
.
Оценим избыточность этого
кодирования
![]()
Теорема доказана.
Данная теорема гарантирует, что для любого источника найдется префиксный код со средней длиной кодирования, превышающейэнтропию не более чем на 1.
Оптимальное кодирование, свойства оптимальных кодов, построение оптимальных кодов методом Хафмена
Для практических целей представляет интерес нахождение для каждого источника префиксного кода с минимальной средней длиной кодирования.
Определение. Префиксное кодирование ![]() называется
оптимальным для источника
называется
оптимальным для источника ![]() ,
если для каждого префиксного кодирования
c источника
,
если для каждого префиксного кодирования
c источника ![]() справедливо неравенство
справедливо неравенство ![]() .
.
Для каждого источника существует оптимальный код, поскольку множество префиксных кодов источника с избыточностью, меньшей либо равной 1, не пусто и конечно. Один источник может иметь несколько оптимальных кодов с разными наборами длин кодовых слов.
Пусть
буквы алфавита ![]() источника
источника ![]() имеют
вероятности появления
имеют
вероятности появления ![]() ,
длины кодовых слов
,
длины кодовых слов ![]() при
использовании кода
при
использовании кода ![]() равны
равны ![]() .
Рассмотрим некоторые свойства оптимального
кодирования, для того чтобы, опираясь
на эти свойства, сформулировать процедуру
нахождения оптимального кода.
.
Рассмотрим некоторые свойства оптимального
кодирования, для того чтобы, опираясь
на эти свойства, сформулировать процедуру
нахождения оптимального кода.
Свойство
1.
Для оптимального кода из ![]() следует,
что
следует,
что ![]() .
.
Для
доказательства предположим противное,
т. е. что для оптимального кода
существуют ![]() и
и ![]() ,
такие что
,
такие что ![]() и
и ![]() .
Построим новый код, поменяв местами
кодовые слова рассматриваемого
оптимального кода для
.
Построим новый код, поменяв местами
кодовые слова рассматриваемого
оптимального кода для ![]() -ой
и
-ой
и ![]() -ой
букв алфавита.Разность между
средней длиной
-ой
букв алфавита.Разность между
средней длиной ![]() кодирования
оптимальным кодом и средний
длиной
кодирования
оптимальным кодом и средний
длиной ![]() построенного
кода имеет вид
построенного
кода имеет вид
![]()
что противоречит оптимальности рассматриваемого кода.
Свойство
2. Существует
оптимальный код источника ![]() ,
для которого
,
для которого
![]()
причем два последних слова имеют максимальную длину и отличаются только в последнем знаке.
Предположим, что в оптимальном коде не существует двух слов максимальной длины. Это значит, существует только одно словомаксимальной длины. Если это самое длинное слово сократить на один последний знак, а другие кодовые слова оставить неизменными, то получится новый код, который, во-первых, будет префиксным (нет второго слова, которое отличается в последнем знаке), и, во-вторых, средняя длина кодирования будет меньше. Это противоречит предположению о существовании в оптимальном коде только одного слова максимальной длины. Таким образом, в оптимальном коде существует, по крайней мере, два кодовых слова максимальной длины.
Докажем, что какие-то два слова максимальной длины отличаются только в последнем знаке. Опять предположим противное, то есть любые два слова максимальной длины отличаются не только в последнем знаке. В этой ситуации можно повторить описанную выше процедуру укорачивания одного из слов максимальной длины и получить в результате новый префиксный код с меньшей средней длиной кодирования, что противоречит оптимальности исходного кода.
Опираясь
на рассмотренные свойства, можно
построить оптимальный для заданного
источника ![]() код
с использованием двух процедур: сжатия
источника и расщепления кода. Смысл
первой процедуры заключается в том, что
исходный источник последовательно
заменяется на более простой (содержащий
на 1 меньше знаков) источник. Применение
процедуры сжатия заканчивается, когда
будет получен простейший источник с
двумя знаками, оптимальное кодирование которого
очевидно. Процедура расщепления кода
предназначена для построения из
оптимального кода более простого
источника оптимального кода того
источника, из которого процедурой сжатия
был получен простой источник.
код
с использованием двух процедур: сжатия
источника и расщепления кода. Смысл
первой процедуры заключается в том, что
исходный источник последовательно
заменяется на более простой (содержащий
на 1 меньше знаков) источник. Применение
процедуры сжатия заканчивается, когда
будет получен простейший источник с
двумя знаками, оптимальное кодирование которого
очевидно. Процедура расщепления кода
предназначена для построения из
оптимального кода более простого
источника оптимального кода того
источника, из которого процедурой сжатия
был получен простой источник.
Процедура
сжатия источника заключается
в переходе от источника ![]() с
алфавитом из п знаков
с
алфавитом из п знаков ![]() упорядоченных
в порядке невозрастания соответствующих
им вероятностей
упорядоченных
в порядке невозрастания соответствующих
им вероятностей ![]() ,
к источнику
,
к источнику ![]() с
алфавитом из
с
алфавитом из ![]() знака
знака![]() и
вероятностями
и
вероятностями ![]() при
при ![]() и
и ![]() .
.
Операцию
сжатия источника ![]() будем
обозначать через
будем
обозначать через ![]() Фактически,
при сжатии первые
Фактически,
при сжатии первые ![]() знака
остаются неизменными, а два последних,
наименее вероятных знака заменяются
на некоторый новый знак с вероятностью,
равной сумме вероятностей двух заменяемых
знаков.
знака
остаются неизменными, а два последних,
наименее вероятных знака заменяются
на некоторый новый знак с вероятностью,
равной сумме вероятностей двух заменяемых
знаков.
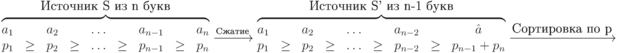
Применяя
сжатие к источнику ![]() ,
получим новый источник
,
получим новый источник ![]() ,
применяя затем процедуру сжатия
к
,
применяя затем процедуру сжатия
к ![]() получим
получим ![]() .
Действуя подобным образом
.
Действуя подобным образом ![]() раза,
построим последовательность
источников
раза,
построим последовательность
источников ![]() ,
, ![]() .
.
Алфавит источника ![]() состоит
только из двух знаков, поэтому найти
оптимальный код для этого источника не
составляет труда. Одно из слов кодируется
знаком 0, а другое - знаком 1. Это особенно
важно потому, что, используя оптимальный
код для источника
состоит
только из двух знаков, поэтому найти
оптимальный код для этого источника не
составляет труда. Одно из слов кодируется
знаком 0, а другое - знаком 1. Это особенно
важно потому, что, используя оптимальный
код для источника ![]() и
последовательность кодов
и
последовательность кодов ![]() ,
можно найти оптимальный код для исходного
источника
,
можно найти оптимальный код для исходного
источника ![]() .
.
Для
построения оптимального кода источника ![]() ,
содержащего на один знак больше, чем
источник
,
содержащего на один знак больше, чем
источник ![]() ,
необходимо выполнить процедуру
расщепления кода.
,
необходимо выполнить процедуру
расщепления кода.
Пусть имеем источник
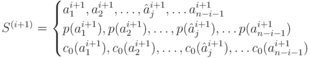
И
оптимальный код ![]()
Через ![]() обозначен
тот знак алфавита источника
обозначен
тот знак алфавита источника ![]() ,
который заменил два знака с минимальными
вероятностями источника
,
который заменил два знака с минимальными
вероятностями источника ![]() при
его сжатии.
при
его сжатии.
Процедура
расщепления заключается
в использовании оптимального
кода ![]() источника
источника ![]() для
построения оптимального кода для
источника
для
построения оптимального кода для
источника ![]() .
Она заключается в следующем: знакам
алфавита источника
.
Она заключается в следующем: знакам
алфавита источника ![]() ,
перешедшим в
,
перешедшим в ![]() без
изменения, назначаются кодовые слова
совпадающих с ними знаков источника
без
изменения, назначаются кодовые слова
совпадающих с ними знаков источника ![]() ;
двум наименее вероятным знакам алфавита
источника
;
двум наименее вероятным знакам алфавита
источника ![]() ,
замененным в процессе сжатия на знак
,
замененным в процессе сжатия на знак ![]() ,
сопоставляют кодовые слова
,
сопоставляют кодовые слова ![]() и
и ![]() .
.
Слово ![]() в
оптимальном коде источника
в
оптимальном коде источника ![]() ,
содержащем
,
содержащем ![]() знаков,
"расщепляется", путем добавления
(конкатенации) знаков 0 и 1, на 2 слова в
кодовом множестве для источника
знаков,
"расщепляется", путем добавления
(конкатенации) знаков 0 и 1, на 2 слова в
кодовом множестве для источника ![]() ,
содержащем
,
содержащем ![]() знаков.
знаков.
Средняя длина ![]() кода
источника
кода
источника ![]() и
средняя длина
и
средняя длина ![]() кода,
полученного из него расщеплением,
связаны соотношением
кода,
полученного из него расщеплением,
связаны соотношением ![]() .
Действительно,
.
Действительно,
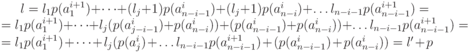
Докажем,
что получающийся в результате расщепления
код является оптимальным для источника ![]() .
.
Предположим
противное, т. е. что существует другой
оптимальный код ![]() для
того же источника
для
того же источника ![]() со
средней длиной кодирования
со
средней длиной кодирования ![]() ,
меньшей, чем
,
меньшей, чем ![]() ,
т. е.
,
т. е. ![]() .
В соответствии со свойством 2 оптимальный
код содержит два слова максимальной
длины, отличающиеся в последнем знаке
и соответствующие двум наименьшим
вероятностям источника
.
В соответствии со свойством 2 оптимальный
код содержит два слова максимальной
длины, отличающиеся в последнем знаке
и соответствующие двум наименьшим
вероятностям источника ![]() .
Обозначим эти два слова через
.
Обозначим эти два слова через ![]() и
и ![]() .
Из этого кода для источника
.
Из этого кода для источника ![]() можно
построить код
можно
построить код ![]() для
источника
для
источника ![]() ,
в котором последнее кодовое
слово получается
отбрасыванием последнего знаки из
слов
,
в котором последнее кодовое
слово получается
отбрасыванием последнего знаки из
слов ![]() и
и ![]() .
Средняя длина
.
Средняя длина ![]() кода
кода ![]() связана
со средней длиной
связана
со средней длиной ![]() кода
кода ![]() соотношением
соотношением ![]() .
Из этого соотношения, из соотношения
.
Из этого соотношения, из соотношения ![]() и
из предположения, что
и
из предположения, что ![]() ,
следует, что
,
следует, что ![]() .
Это противоречит оптимальности кода
для источника
.
Это противоречит оптимальности кода
для источника ![]() .
.
Таким
образом, используя процедуру расщепления,
строится оптимальный код для источника,
который ранее был преобразован процедурой
сжатия в более простой источник. Повторяя
эту процедуру необходимое количество
раз, можно будет найти оптимальный код
для исходного источника ![]() .
.
Описанный метод оптимального кодирования был предложен в 1952 г. Д. Хафменом и называется его именем. В общем случае, когда для кодирования используется алфавит из более чем двух букв, метод Хафмена рассмотрен в [32].
Рассмотрим
процесс построения оптимального кода
на примере источника из пяти сообщений
с вероятностями ![]() .
Построение кода показано на следующем
рисунке.
.
Построение кода показано на следующем
рисунке.

Стрелками
показаны шаги сжатия источника. В левой
части каждого столбца показано
распределение вероятностей источника.
В правой части каждого столбца,
соответствующего одному из источников,
показаны кодовые слова. Построение кода
начинается с простейшего источника ![]() ,
который кодируется двумя однобуквенными
словами 0 и 1.
,
который кодируется двумя однобуквенными
словами 0 и 1.
В данном случае средняя длина кодирования для оптимального кода, построенного методом Хафмена, составляет 2,2. Это меньше, чем средняя длина кода, построенного ранее методом Фано для того же источника.