

2. Простейшие способы моделирования данных
2.1. Зачем нужно моделировать данные
Моделирование данных это искусственное создание случайных данных, обладающих заданными свойствами. Для моделирования данных используются специальные компьютерные программы, которые называются генераторами данных.
Задача моделирования данных имеет очень важное значение при изучении дисциплины Компьютерный анализ данных. Зачем нужно моделирование данных? Моделирование данных необходимо для изучения и тестирования программного обеспечения, предназначенного для решения задач анализа данных.
Чаще всего исследователи при решении задач анализа данных используют стандартное программное обеспечение или специализированные пакеты по обработке данных. Программное обеспечение, как правило, включает целый ряд программ, процедур или функций анализа данных, представляющих собой программную реализацию известных в теории методов обработки данных. Для того чтобы использовать ту или иную программу обработки данных необходимо очень хорошо знать метод обработки, заложенный в ее основу. Однако знание теории не всегда гарантирует правильное использование программы. Необходимо еще знать устройство программы на уровне входа и выхода. Для этого служат описания программ. Описания программ далеко не всегда может быть правильно понято человеком, который впервые сталкивается с новым программным продуктом. Все-таки язык описания программ не так глубоко формализован, как строгий математический аппарат, описывающий метод исследования, во-вторых, все особенности использования программы их создатели и не в состоянии описать они не могут себе даже представить всех вариантов неправильного использования программы. Таким образом, исследователь перед использованием программы на реальных данных должен, убедиться в том все ли правильно он понимает в ее работе. Убедиться в этом пользователь может, решая примеры на данных, обладающих известными свойствами (модельных данных). Проблема изучения программных средств особенно остро стоит со сложными программами. Эта проблема еще усложняется, когда приходится иметь дело с англоязычным интерфейсом или переведенным на русский язык. При переводе специальной терминологии очень часто возникают неточности.
Поскольку предмет анализа данных состоит в изучении методов анализа и программного обеспечения, реализующих эти методы аппарат моделирования данных является необходимым инструментом для работы. Необходимость в модельных данных сохраняется при изучении любых вновь появляющихся программных продуктов. Поэтому студенту необходимы навыки моделирования данных. Более того, даже разработчики новых методов анализа данных и программного обеспечения к ним тоже не могут обойтись без таких данных. Да и любая программа, созданная пользователем для обработки реальных данных с использованием стандартного программного обеспечения вначале требует тестирования.
2.2. Моделирование данных с помощью функции слчис()
Моделирование случайных величин (данных), обладающих заданными свойствами производится на основе датчика случайных чисел. Случайные числа моделируют равномерное распределение случайной величины на интервале (0,1). В стандартном пакете EXCEL моделирование случайных чисел производится с помощью функции СЛЧИС(), которая входит в состав Математических функций. При выборе данной функции выводится диалоговое окно (рис. 2.1) в котором ничего не вводится, а просто нажимается кнопка ”ОК”. Окно содержит только информацию об особенностях работы программы.
Рис. 2.1. Диалоговое окно функции СЛЧИС()
Для того, чтобы создать последовательность чисел в таблице данных необходимо скопировать содержимое ячейки, содержащей функцию СЛЧИС() по столбцу (протянуть по столбцу). В диалоговом окне функции СЛЧИС() указано, что значение в ячейках, содержащих функцию СЛЧИС() изменяется при пересчете. Это означает, что при внесении любых изменений на листе EXCEL функция выдаст новое значение. Для некоторых задач моделирования данных такое свойство функции оказывается очень полезным. Но для решения примеров по апробации программного обеспечения необходимо иметь фиксированные значения. Для того, чтобы зафиксировать значения случайных чисел, полученных с помощью функции СЛЧИС() необходимо выполнить следующие действия:
после копирования функции методом протягивания не снимать выделения ячеек в столбце нажать пиктограмму “Копировать”;
выбрать в меню “Правка” команду “Специальная вставка”;
в открывшемся окне выбрать ”значения” (рис. 2.2) и нажать кнопку ”ОК”;
завершить всю операцию нажатием клавиши ”Enter” на клавиатуре.

Рис. 2.2. Диалоговое окно функции “Специальная вставка”
Смоделируем
две последовательности случайных чисел
и разместим их в первых двух столбцах
таблицы данных (рис. 2.3). Математическое
обозначение таких чисел будет
![]() и
и![]()
![]() .
Эти числа нам понадобятся для моделирования
других случайных величин.
.
Эти числа нам понадобятся для моделирования
других случайных величин.

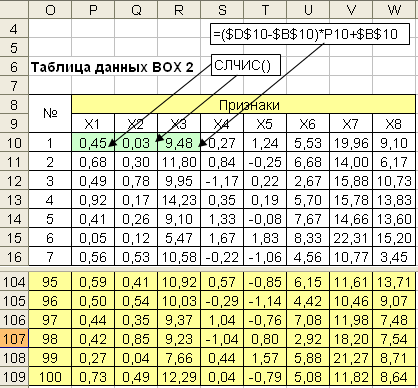
Рис. 2.3. Таблица данных ”объект-свойство”