

Понятие пропускной способности и латентности
Основными характеристиками быстродействия сети являются латентность и пропускная способность. Предположим, что на двух процессорах вычислительной системы работают два процесса, между которыми с помощью сети пересылаются сообщения. В передаче информации, кроме аппаратных устройств, участвует и ПО, например реализация интерфейса передачи сообщений MPI.
Пропускная способность сети определяется количеством информации, передаваемой между узлами сети в единицу времени (N байт в секунду). Реальная пропускная способность снижается программным обеспечением за счет передачи служебной информации.
Латентностью (задержкой) называется время, затрачиваемое программным обеспечением и устройствами сети на подготовку к передаче информации по данному каналу. Полная латентность складывается из программной и аппаратной составляющих.
Различают следующие виды пропускной способности сети:
1. пропускная способность однонаправленных пересылок ("точка-точка", uni-directional bandwidth), равная максимальной скорости, с которой процесс на одном узле может передавать данные другому процессу на другом узле.
2. пропускная способность двунаправленных пересылок (bidirectional bandwidth), равная максимальной скорости, с которой два процесса могут одновременно обмениваться данными по сети.
Методы измерения пропускной способности и латентности
Для измерения пропускной способности однонаправленных пересылок ("точка-точка") процесс с номером 0 посылает процессу с номером 1 сообщение длины L байт. Процесс 1, приняв сообщение от процесса 0, посылает ему ответное сообщение той же длины. Используются блокирующие вызовы MPI. Эти действия повторяются N раз с целью минимизировать погрешность за счет усреднения. Процесс 0 измеряет время T, затраченное на все эти обмены. Пропускная способность R определяется по формуле R=2NL/T.
Для измерения пропускной способности двунаправленных обменов используются неблокирующие вызовы MPI. При этом производится измерение времени, затраченного процессом 0 на передачу сообщения процессу 1 и прием ответа от него, при условии, что процессы начинают передачу информации одновременно после точки синхронизации.
Латентность измеряется как время, необходимое на передачу сигнала или сообщения нулевой длины. Для снижения влияния погрешности и низкого разрешения системного таймера (очень малые времена округляются до 0) важно повторить операцию посылки сигнала и получения ответа большое число раз. Таким образом, если время на N итераций пересылки сообщений нулевой длины туда и обратно составило T сек., то латентность измеряется как s=T/(2N).
4. Цели и задачи параллельной обработки данных. Основные принципы выполнения параллельных вычислений на общей и распределенной памяти. SMP-системы, их преимущества и недостатки. Параллельные вычисления с передачей сообщений.
Цель параллельных вычислений - ускорить выполнение алгоритма за счет совмещения выполнения множества вычислительных операций над данными. Параллельный алгоритм должен:
1. при использовании интерфейса передачи данных выполнять:
а) оптимальное распределение данных по процессам,
б) эффективный обмен данными,
в) по возможности обеспечить равномерную вычислительную нагрузку процессоров.
2. при использовании без обменных средств распараллеливания выделить блоки алгоритма, в которых возможно выполнить параллельные вычисления, обращаясь к разным областям общей памяти.
Создавать параллельные программы стало возможно с появлением в операционных системах механизма порождения потоков или нитей (threads), называемых еще легковесными процессами (light-weight process). Нить - это независимый поток управления, выполняемый в контексте некоторого процесса совместно с другими нитями или процессами. Нити имеют общее адресное пространство, но разные потоки команд. В простейшем случае, процесс состоит из одной нити. Однако, если эти потоки (процессы) совместно используют некоторые ресурсы, например область памяти, то при обращении к этим ресурсам они должны синхронизовать свои действия. Многолетний опыт программирования с использованием явных операций синхронизации показал, что такой стиль "параллельного" программирования порождает серьезные проблемы при написании, отладке и сопровождении параллельных программ.
С появлением симметричных мультипроцессорных систем (SMP), отношение к разработке параллельных программ претерпело существенные изменения. В SMP системах физически присутствуют несколько процессоров, которые имеют равные права и скорость обращения к совместно используемой памяти. Наиболее распространенным интерфейсом для создания параллельных приложений на общей памяти является OpenMP. Интерфейс OpenMP является стандартом для программирования на SMP-системах, в него входит описание набора директив компилятора, переменных среды выполнения программ и ряд процедур. OpenMP является без обменным средством распараллеливания и идеально подходит для программ, где выполняемые вычисления обращаются к разным (не пересекающимся) областям общей памяти, например, программ с “большими” по числу итераций циклами.
Достоинством организации параллельных вычислений на ВС с общей памятью, является использование без обменных средств распараллеливания, что значительно увеличивает производительность параллельного приложения при правильном обращении к общей памяти.
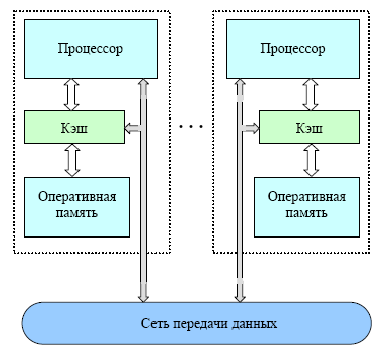 Недостатком организации параллельных
вычислений на ВС с общей памятью,
является доступ разных процессоров к
общим данным и обеспечение, в этой связи,
однозначности значений данных (cache
coherence problem), т.е. необходимость выполнения
явной синхронизации для обеспечения
безопасного доступа к данным.
Недостатком организации параллельных
вычислений на ВС с общей памятью,
является доступ разных процессоров к
общим данным и обеспечение, в этой связи,
однозначности значений данных (cache
coherence problem), т.е. необходимость выполнения
явной синхронизации для обеспечения
безопасного доступа к данным.
Передача сообщений является универсальным механизмом при выполнении параллельных вычислений и может выполняться как на SMP, так и на массивно-параллельных системах (massively parallel processor or MPP), примером которых являются кластерные вычислительные системы.
Кластерные системы − это более распространенный вариант MPP–систем, где также используется принцип передачи сообщений. В настоящее время в качестве вычислительных узлов используются двух или четырехпроцессорные SMP-серверы. Каждый узел работает под управлением своей копии операционной системы, в качестве которой чаще всего используются стандартные операционные системы: Linux, NT, Solaris и т.п. Состав и мощность узлов может меняться в рамках одного кластера, давая возможность создавать неоднородные системы.
Для кластерных систем в соответствии с сетевым законом Амдаля характеристики коммуникационных сетей имеют принципиальное значение. Коммуникационные сети имеют две основные характеристики: латентность − время начальной задержки при посылке сообщений и пропускную способность сети, определяющую скорость передачи информации по каналам связи. При выполнении функции передачи данных, прежде чем покинуть процессор, последовательно выполняется набор операций, определяемый особенностями программного обеспечения и аппаратуры. Наличие латентности определяет и тот факт, что максимальная скорость передачи по сети не может быть достигнута на сообщениях с небольшой длиной.
Достоинства организации параллельных вычислений на распределенной памяти:
1. Использование распределенной памяти упрощает задачу создания мультипроцессорных вычислительных систем.
2. Каждый процесс обладает собственными ресурсами и выполняется в собственном адресном пространстве, таким образом, данные, находящиеся на каждом процессе защищены от неконтролируемого доступа.
3. Универсальность, т.к. алгоритмы с передачей сообщений могут выполняться на большинстве сегодняшних суперкомпьютеров.
4. Легкость отладки. Отладка параллельных программ все еще остается сложной задачей. Однако процесс отладки происходит легче в программах с передачей сообщений. Это связано с тем, что самая распространенная причина ошибок заключается в неконтролируемой перезаписи данных в памяти. Модель с передачей сообщений, явно управляет обращением к памяти, и, тем самым, облегчает локализацию ошибочного чтения или записи в память.
Недостатки организации параллельных вычислений на распределенной памяти:
1. Каждый процессор вычислительной системы может использовать только свою локальную память, поэтому для доступа к данным, располагаемым на других процессорах, необходимо явно выполнять операции передачи сообщений (message passing operations).
2. Проблема эффективного использования распределенной памяти приводят к существенному повышению сложности параллельных вычислений.
Современные вычислительные системы представляют собой распределенные SMP узлы. При такой архитектуре можно использовать два варианта выполнения параллельных программ. Процесс – это программная единица, у которой имеется собственное адресное пространство и одна или несколько нитей. Процессор − фрагмент аппаратных средств, способный к выполнению программы. Если в кластере используются SMP–узлы, то для организации вычислений возможны два варианта:
1. на каждом вычислительном SMP узле порождается отдельный процесс. Процессы внутри узла обмениваются сообщениями через разделяемую память.
2. каждый вычислительный SMP узел захватывается монопольно одним процессом, внутри которого выполняется распараллеливание в модели "общей памяти", например с помощью директив OpenMP.
Оптимальным для параллельного выполнения программ в алгоритмах задач достаточно выделять только крупные независимые части расчетов, что, упрощает построение параллельных методов вычислений и уменьшает потоки передаваемых данных между процессорами кластера.
Однако, организация взаимодействия вычислительных узлов при помощи передачи сообщений обычно приводит к значительным временным задержкам, что накладывает дополнительные ограничения на тип разрабатываемых параллельных алгоритмов и программ.
Поэтому использование смешанного механизма распараллеливания на общей и распределенной памяти является наиболее эффективным при выполнении параллельных вычислений на современных высокопроизводительных вычислительных системах.