

рой; средства отладки программ, а также перемещения наборов данных с од- них носителей на другие и т.д.
Прикладное программное обеспечение – это совокупность прикладных программ, реализующих функции обработки данных, связанные с конкрет- ной областью применения вычислительной системы. В системах автоматиза- ции проектирования, например, радиоэлектронной аппаратуры, прикладные программы могут обеспечивать, например, анализ функционирования элек- тронных схем, размещение ЭРЭ (электро-радиоэлементов) по конструктивам (например, печатным платам), разводку соединений на них и т.д., а в автома- тизированных системах управления производством могут обеспечивать ка-
лендарное и оперативное планирование производства на предприятии и в его низовых производственных подразделениях, учет и анализ производствен- ной деятельности и т.д.
К прикладным программным средствам вычислительных систем при- мыкают также наборы данных, рассматриваемые как особая составляющая, называемая информационным программным обеспечением.
Наборы данных снабжаются адресами, с помощью которых программы отражаются к соответствующим наборам и их элементам. Поэтому одни и те же наборы данных могут использоваться разными прикладными программа- ми.
Наборы данных, как правило, организуются в виде специальных струк- тур, а именно – баз и банков данных, а выборка, модификация и добавление данных производится с использованием специальных программ, называемых системами управления базами и банками. Организация данных в таких фор- мах обеспечивает независимость прикладных программ от логической и фи- зической организации баз и банков данных, в результате чего изменения в прикладных программах не влекут за собой изменений баз и банков, а реор- ганизация баз и банков не требует несения изменений в прикладные про- граммы, оперирующие с данными.
В общем и целом рассмотренные принципы структурной организации вычислительных систем, их технических средств и программного обеспече-
ния потребовали разработки способов параллельной обработки информации и некоторых уточнений таких способов, разработанных ранее для одиночных ЭВМ.
Способы организации параллельной обработки информации
Остановимся на наиболее существенных из них. Таких способов три:
1.Совмещение во времени различных этапов решения разных задач.
2.Одновременное решение различных задач или частей одной задачи.
3.Конвейерная обработка информации.
Рассмотри их в указанной последовательности.
1. Совмещение во времени различных этапов решения разных задач. Этот способ реализует метод мультипрограммной обработки информа-
ции, который нашел широкое применение в вычислительной технике, при- чем, даже в однопроцессорных ЭВМ.
15

Мультипрограммная обработка
Процесс решения любой задачи сводится к последовательности реали- зации этапов процессорной обработки, ввода-вывода данных и обращения к запоминающим устройствам. При этом одна задача в каждый конкретный момент времени обрабатывается, как правило, только одним устройством ЭВМ или вычислительной системы, а остальные устройства для решения этой задачи не используются. Поэтому такие устройства в это время можно использовать для решения других задач и этим ускорить их решение.
Режим обработки данных, при котором в ЭВМ или вычислительной системе могут одновременно и параллельно решаться несколько задач, назы- вается мультипрограммной обработкой или мультипрограммированием.
Понятно, что цель использования этого режима решения – повышение производительности вычислителя.
Число задач, способных одновременно обрабатываться в нем, называ- ется уровнем мультипрограммирования. Этот уровень влияет и на произво- дительность ЭВМ или вычислительной системы, и на время получения отве- та. Покажем это на следующей диаграмме (рис. 10).
Рис. 10
На ней приведены аппроксимированные зависимости производитель- ности системы «α» и среднего времени ответа «U» от уровня мультипро- граммирования «М». В однопрограммном режиме работы (М=1) производи- тельность системы равна «α1», а время ответа – «U1». С увеличением уровня мультипрограммирования «М» увеличивается вероятность того, что все большее число устройств будет одновременно занято решением задач. Из графика видно, что при М<М* производительность системы «α» растет, а время ответа «U», если и изменяется в сторону увеличения, то незначитель- но. Однако при уровне мультипрограммирования М=М* возникает ситуа-
16

ция, когда дальнейшее увеличение числа задач почти не приводит к росту производительности (точка «α*»). Это говорит о почти полной загрузке уст- ройств системы и ее насыщении. Кроме того, при М>M* начинает резко воз- растать время ответа «U», поскольку все большее число задач ожидает мо- мента высвобождения устройств. Правда время ответа «U» при этом не стре- мится к бесконечности, т.к. вычислительная система всегда функционирует в стационарном режиме с постоянным числом задач «М», находящихся в ее памяти. Значение «М*» называется точкой насыщения мультипрограммной смеси, а также точкой насыщения системы и зависит в первую очередь от числа устройств, которые в составе системы могут функционировать парал- лельно. Чем большее число таких устройств, тем больше «М*». Кроме того, на значение «α*» существенно влияют свойства задач, связанные с числом устройств вычислителя, используемых при их решении. Из рассмотренного вытекает, что работа конкретной ЭВМ или вычислительной системы не эф- фективна при уровне мультипрограммирования М>M*, поскольку произво- дительность почти не увеличивается, а время ответа стремительно возраста- ет. В принципе «α» и «U» связаны между собой следующей зависимостью:
α = МU
Эта зависимость называется формулой Литтла и является фундамен- тальным законом теории массового обслуживания.
Рассмотрим другие способы параллельной обработки информации. 2. Одновременное решение различных задач или частей одной задачи
Реализация этого способа возможна только при наличии в вычислителе нескольких процессоров.
При его реализации используются некоторые особенности задач или потоков задач, что позволяет осуществлять тот или иной тип параллелизма. Мы с вами рассмотрим три типа параллелизма, отражающие те или иные особенности задач или потоков задач.
а) Естественный параллелизм независимых задач Этот параллелизм заключается в том, что в вычислительную систему
поступает непрерывный поток не связанных между собой задач, т.е. решение любой задачи из этого потока не зависит от результатов решения других за- дач. В этом случае используется несколько процессоров, каждый из которых решает свою собственную задачу. Все процессоры ведут процесс одновре- менно и параллельно. Поэтому весь поток задач решается за существенно бо- лее короткое время, чем потребовалось бы для их решения при одном про- цессоре.
Поэтому данный тип параллелизма существенно повышает производи- тельность вычислительной системы.
б) Параллелизм независимых ветвей Суть этого параллелизма заключается в том, что при решении большой
и сложной задачи могут быть выделены независимые ее части, на каждую из которых разрабатываются свои ветви программы, которые при наличии не-
17

скольких процессоров могут выполняться параллельно и независимо друг от друга. Подчеркиваю, реализация этого типа параллелизма возможна только при независимых ветвях программы. Двумя независимыми ветвями про- граммы считаются такие, при реализации которых в каждый данный момент выполняются следующие условия:
-ни одна из входных для ветви программы величин не является вы- ходной величиной другой ветви программы (отсутствие функциональных связей);
-для обеих ветвей программы не должна производиться запись в од- ни и те же ячейки памяти (отсутствие связей по использованию одних и тех же полей ОЗУ);
-условия выполнения одной ветви не зависят от результатов или при- знаков, полученных при выполнении другой ветви (независимость по управ- лению);
-обе ветви должны выполняться по разным блокам программы (про- граммная независимость).
Рис. 11
18
Хорошее представление о параллелизме независимых ветвей дает ярусно-параллельная форма программы. Рассмотрим пример создания такой формы в виде следующего графа (рис. 11).
Программа представлена как совокупность ветвей, расположенных в нескольких уровнях или ярусах. Кружками с цифрами внутри обозначены ветви программы. Длина ветви или время реализации представляется циф- рой, стоящей около кружка. Стрелками показаны входные данные и выход- ные, т.е. результаты обработки. Входные данные обозначаются символом «Х», выходные – символом «Y».
Символы «Х» имеют нижние цифровые индексы, обозначающие номе- ра входных величин, символы «Y» имеют цифровые индексы и внизу, и вверху: цифра вверху соответствует ветви программы, при выполнении кото- рой получен данный результат , а цифра внизу означает порядковый номер результата, полученного при реализации данной ветви программы.
Изображенная нами в таком виде форма программы содержит 14 вет- вей, расположенных на 5 ярусах.
Ветви каждого яруса не связаны друг с другом, т.е. результаты реше- ния какой-либо ветви данного яруса не являются входными данными для другой ветви этого же яруса. На таком же графе могут быть изображены и связи по управлению, и связи по памяти. В этом случае граф позволит на- глядно показать все полностью независимые ветви программы. Однако, для простоты рисунка у нас их нет (т.к. мы рассматриваем принцип). Примем, что длина «i»-ой ветви представляется числом временных единиц «ti», кото- рые требуются для ее исполнения (у нас это цифры около кружков). Тогда нетрудно подсчитать, что для исполнения всей программы одним процессо- ром потребуется время:
N =14
Т = åti = 375 единиц времени
i=1
Если представить, что программа выполняется двумя процессорами, работающими независимо друг от друга, то время решения задачи естествен- но сократится. Однако, это время будет различным в зависимости от после- довательности выполнения независимых ветвей. Покажем это, для чего рас- смотрим три варианта:
Вариант 1. Процессор №1 выполняет ветви 1-4-5-9-13, а процессор №2
– ветви 2-6-3-7-8-11-12-14. При этом процессор №1 затрачивает 145 единиц времени, а процессор №2 – 230. Ориентируемся на большее время.
Вариант 2. Процессор №1 выполняет ветви 1-4-5-9-10-11-13, а процес- сор №2 – ветви 2-6-3-7-8-12-14. При этом процессор №1 затрачивает 160 единиц времени, а процессор №2 – 215. Ориентируемся тоже на большее время.
19
Вариант 3. Процессор №1 выполняет ветви 1-4-8-12-11-13, а процессор №2 – ветви 2-5-6-3-7-9-10-14. При этом процессор №1 затрачивает 175 еди- ниц времени, а процессор №2 – 200. Ориентируемся тоже на большее время.
Таким образом, все варианты показывают, что двухпроцессорная сис- тема существенно сокращает время решения задачи: вместо 375 единиц вре- мени результат выдается в первом варианте через 230, во втором – через 215, и в третьем – через 200 единиц времени, т.е. в последнем варианте время ре- шения задачи уменьшается в 1, 875 раза. При этом выигрыш во времени ко- леблется в зависимости от последовательности выполнения ветвей програм- мы каждым процессором и в зависимости от готовности данных перед нача- лом выполнения каждой ветви, что существенно для того чтобы не было про- стоев процессоров или они были бы минимальны.
Таким образом, для того чтобы с помощью нескольких процессоров решить большую задачу, имеющую независимые параллельные ветви, за ми- нимальное время, необходима соответствующая организация процесса реше- ния. Это возможно осуществить, когда известна достаточно точно длитель- ность выполнения каждой ветви.
На практике это бывает известно крайне редко, поэтому организация оптимального графика работы является достаточно сложной процедурой. Все это приводит в конечном счете к тому, что выигрыш в производительности вычислительной системы может оказаться неоптимальным (например, в на- шем случае вместо 1,875 раза можно получить 1,63 раза для варианта №1).
Но все равно выигрыш в производительности всегда получается и довольно неплохой.
Рассмотрим третий, последний, тип параллелизма.
в) Параллелизм объектов или данных Этот тип параллелизма имеет место тогда, когда по одной и той же
программе должна обрабатываться некоторая совокупность данных, посту- пающих в систему одновременно. Это могут быть, например, задачи обра- ботки сигналов от радиолокационной станции аэродрома, которая ведет це- лый ряд самолетов, взлетевших и идущих на посадку. Другой пример – обра- ботка информации от датчиков, измеряющих одновременно один и тот же параметр и установленных на нескольких однотипных объектах.
Если при этом под каждый самолет или датчик выделить свой отдель- ный процессор, то время решения потока задач будет существенно меньше, чем при одном процессоре, выделенном для решения всего потока задач. При этом чем больше процессоров будет иметь вычислительная система, тем больше будет ее производительность.
3. Конвейерная обработка информации
Это третий рассматриваемый нами способ организации параллельной обработки информации. Он может быть реализован даже в системе с одним процессором. При этом способе образуется своего рода конвейер обработки. Проиллюстрируем это следующим примером. Пусть операцию сложения
20
двух чисел с плавающей запятой А·2х+В·2y=С·2xνy можно разделить на четы- ре последовательно исполняемых этапа или шага:
-(СП) – сравнение порядков;
-(ВП) – выравнивание порядков или сдвиг мантиссы с меньшим по- рядком для выравнивания с мантиссой с большим порядком;
-(СМ) – сложение мантисс;
-(НР) – нормализация результата.
В соответствии с этим вместо единого процессора предусматриваются четыре операционных блока СП, ВП, СМ и НР, соединенных последователь-
но и реализующих четыре перечисленных этапа или шага операции сложения
(рис. 12).
Время выполнения каждого этапа или шага приведено внутри контура каждого блока (в скобках) равно соответственно 60, 100, 140 и 100 нсек:
Рис. 12
Таким образом, операция сложения будет выполняться последователь- ностью операционных блоков СП, ВП, СМ и НР за время 400 нсек (60+100+140+100=400 нсек). Далее еще предположим, что существует задача сложения двух векторов А и В, содержащих по «n» элементов или операндов с плавающей запятой. Очевидно, для решения этой задачи потребуется сло- жить два числа:
А+В=[аi·2х]+[b·2y]=[ci·2 xνy],
Утверждается, что выполнить эти операции возможно на устройстве (рис. 12), организовав обработку данных следующим образом.
Рис. 13
21

После того, как блок СП выполнит свою часть операции над первой парой операндов, он передает ее результат в следующий блок ВП, а в блок СП будет загружена вторая пара операндов. На следующем шаге блок ВП
передает результат выполнения своей части операции в блок СМ и начнет обрабатывать результат, полученный от обработки второй пары операндов в блоке СП и т.д. Временную диаграмму этого процесса можно представить, воспользовавшись следующей таблицей (рис. 13).
Для того, чтобы не создавать очереди операндов на обработку, причем также, что время обработки на каждом шаге одинаково и равно максималь- ному значению времени в блоке (СМ), т.е. τ=140 нс. В результате этого полу- чим конвейер из четырех операционных блоков, на выходе которого первый результат будет получен через 140 нсек.
Таким образом, если бы не было конвейера из четырех блоков, а ис- пользовался бы единый процессор, то каждый результат сложения из него выдавался бы через 400 нсек. При наличии конвейера выдача каждого (начи- ная со второго) результата происходит через 140 нсек (см. таблицу рис. 14).
Рис. 14
Нетрудно заметить, что чем длиннее цепочка данных на входе и чем на большее число этапов разбивается операция, тем более высокий прирост производительности можно получить. В нашем примере (рис. 14) при четы- рех этапах уже на цепочке из семи входных пар операндов получается выиг- рыш в производительности в два раза.
Таким образом, конвейерное выполнение арифметических операций оказывается выгодным и обеспечивает существенное повышение производи- тельности.
Кроме арифметических операций идея конвейера может быть распро- странена и на выполнение команд. При этом цикл выполнения команды так- же разбивается на ряд этапов или шагов, например:
-формирование адреса команды (ФАК);
-выборка команды памяти (ВК);
-расшифровка кода операции (РКО);
-формирование адреса операнда (ФАО);
-выборка операнда из памяти (ВО);
-арифметическая или логическая операция (АЛО).
При этом в устройстве управления предусматриваются блоки, которые независимо друг от друга и параллельно могут выполнять все указанные эта-
22
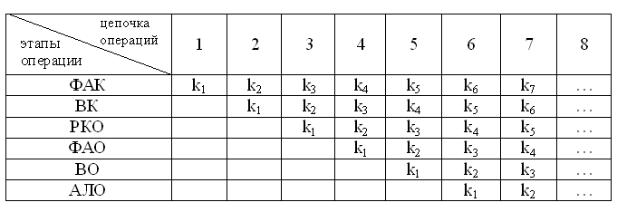
пы. Временная диаграмма этого процесса может быть представлена следую- щей таблицей на рис. 15.
Рис. 15
При этом для простоты рассуждения время выполнения каждого этапа также принимается одинаковым. Таким образом, если в конвейере арифме- тических операций происходит параллельная обработка целого ряда пар опе- рандов, то в конвейере команд происходит совмещение во времени целого ряда операций, на которые разбито выполнение команды. Это позволяет так-
же существенно увеличить производительность такой конвейерной ЭВМ или вычислительной системы.
К сожалению, на практике на конвейере команд невозможно получить такой же прямой выигрыш в производительности, как при конвейере ариф- метических операций. Связано это с наличием в программах условных пере- ходов, которые нарушают работу конвейера и приводят к его «холостым» пробегам, когда по выработанному в команде ki признаку результата надо перейти к выполнению не ki+1-й команды, а к совершенно другой, например, km, что вызывает необходимость очистки всех блоков и загрузки их другой операцией. Эта работа несколько снижает производительность вычисли- тельной системы. Правда в реальных системах в настоящее время применя- ются различные приемы, позволяющие определять признак условного пере- хода возможно раньше, однако, совсем исключить его влияние на повышение производительности не удается. Тем не менее, даже в этом случае выигрыш в производительности конвейерного процессора команд получается значитель- ным, так как в грамотно разработанных программах условные переходы можно свести к минимуму. При этом выигрыш в производительности полу- чается тем больше, чем длиннее участки программы без условных переходов, и чем больше независимых этапов можно выделить при выполнении коман- ды. В вычислительных системах, как правило, используется не один процес- сор или ЭВМ, а несколько. При этом во всех них реализуются и конвейеры арифметических операций, и конвейеры команд. Поэтому вычислительные системы содержат несколько (а иногда много) параллельно работающих кон- вейеров, что позволяет получить очень высокую производительность систе-
23