

КОНСПЕКТ ЛЕКЦИЙ КОДЭИ
.pdfГрафик функции ошибки E(w)
12.03.13 |
Доцент С.Т. Касюк |

При коррекции весов методом наискорейшего спуска возможна ситуация, когда алгоритм попадет в точку экстремума, где производная равна 0. Тогда величина коррекции весов также будет w = 0. На следующем шаге алгоритм останется в точке, где производная равна 0, поэтому ситуация повторится и т. д. Проще говоря, алгоритм «забуксует» в точке экстремума, и коррекция весов остановится. Чтобы выйти из этого состояния, можно запустить обучение заново.
12.03.13 |
Доцент С.Т. Касюк |

Коэффициент скорости
Величину шага коррекции веса на каждой итерации обучения часто называют скоростью обучения, которая определяется значением производной функции ошибки.
12.03.13 |
Доцент С.Т. Касюк |

Кроме производной, на скорость обучения влияет дополнительный параметр — коэффициент скорости обучения η, лежащий в диапазоне от 0 до 1. Он подбирается экспериментально.
12.03.13 |
Доцент С.Т. Касюк |

Если коэффициент скорости обучения велик (η≈1), то скорость обучения определяется только производной функции ошибки. При уменьшении коэффициента возникает эффект «торможения» процесса: шаг коррекции уменьшается в соответствии со значением коэффициента. Например, при η = 0,5 каждый шаг коррекции уменьшается в два раза.
12.03.13 |
Доцент С.Т. Касюк |
При подборе η руководствуются следующей логикой. Если задать его значение большим, например 0,8 или 0,9, то такой шаг коррекции весов приведет к ускорению процесса обучения
— для достижения оптимума потребуется меньшее число итераций, но при этом несколько снизится точность настройки на оптимум. Если задать малый коэффициент скорости обучения (0,1-0,2), то время, требуемое для обучения, возрастет, но увеличится и ожидаемая точность настройки на оптимум.
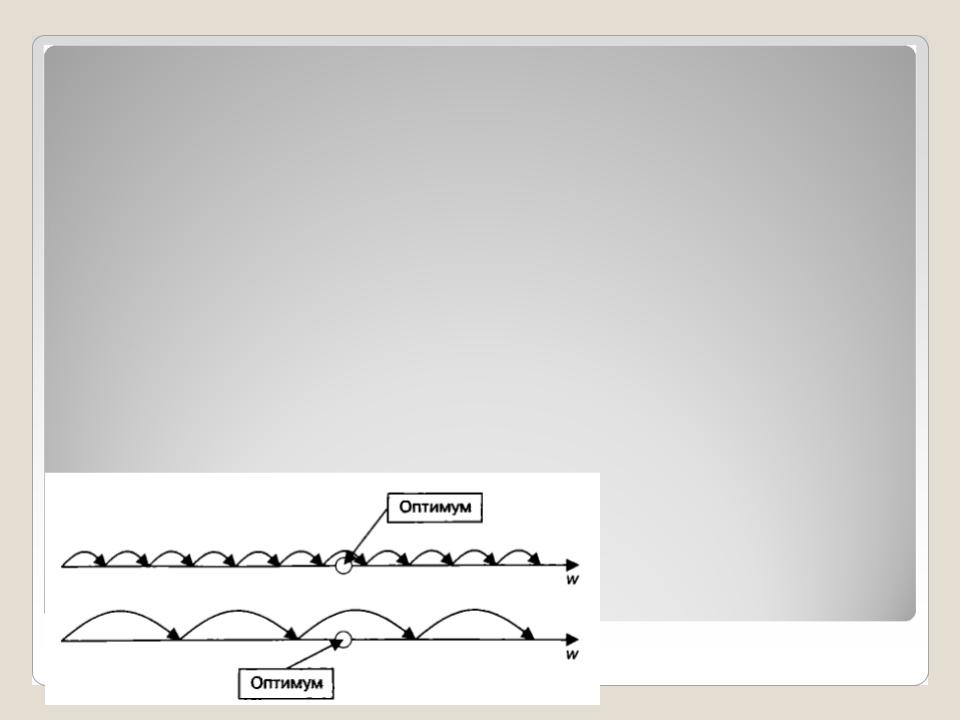
Подбор
коэффициента
обучения
Доцент С.Т. Касюк
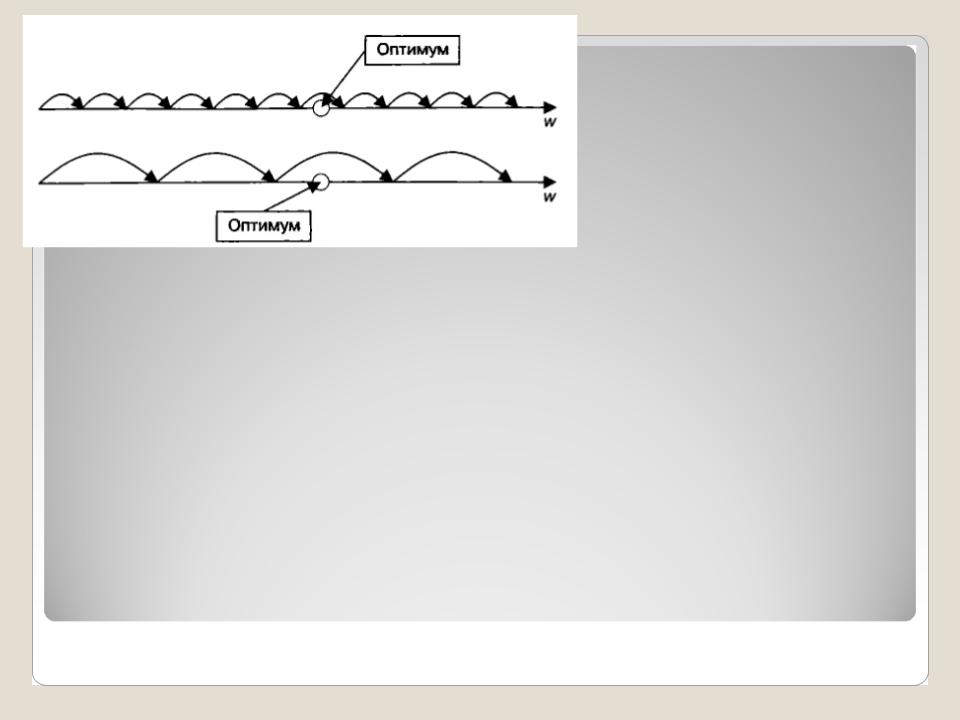
Подбор
коэффициента
обучения
На верхнем графике, где шаг обучения мал, для достижения точки оптимума требуется шесть шагов, но при этом точность настройки на оптимум будет высокой. На нижнем графике, где шаг большой, оптимум будет достигнут всего за три шага, но точность при этом уменьшится. Наиболее распространенным градиентным алгоритмом обучения для нейронной сети является алгоритм обратного распространения ошибки.
12.03.13 |
Доцент С.Т. Касюк |

Алгоритм обратного распространения ошибки
Алгоритм обратного распространения ошибки
(error back propagation, BackProp) представляет собой градиентный алгоритм обучения многослойного персептрона, основанный на минимизации среднеквадратической ошибки выходов сети. Алгоритм был предложен в 1974 г. П. Дж. Вербосом, а в 1986 г. его развили Д. Румельхарт и Р. Вильяме. Появление алгоритма дало дополнительный толчок развитию нейросетевых технологий.
12.03.13 |
Доцент С.Т. Касюк |

Основная идея алгоритмов обучения с учителем, к которым относится и BackProp, заключается в том, что на основе разности между желаемым и целевым выходами сети можно вычислить выходную ошибку сети. Цель определения выходной ошибки — управление процессом обучения нейронной сети, то есть корректировки весов еѐ межнейронных связей для минимизации функции ошибки.
12.03.13 |
Доцент С.Т. Касюк |

Корректировка весов сети делается по правилу Видроу-Хоффа. Каждый нейрон в сети получает возбуждение от вектора входных значений, производит их взвешенное суммирование и преобразует полученную сумму с помощью активационной функции. Выходная ошибка сети формируется на нейронах выходного слоя. Но это не означает, что погрешность работы сети обусловлена только выходными нейронами. Свой вклад в результирующую ошибку вносит каждый скрытый нейрон. Тогда для него может быть указана ошибка δ = d — у, где d — желаемое выходное значение, a w — реальное выходное значение.
12.03.13 |
Доцент С.Т. Касюк |