

Тема 18 запоминающие устройства
1 Виды запоминающих устройств.
2 Запоминающие устройства на биполярных транзисторах.
3 Запоминающие устройства на полевых транзисторах.
1 Виды запоминающих устройств
Запоминающее устройство (ЗУ), или память,— это устройства, с помощью которого информация существует во времени, точнее, передается от одного момента к другому.
Направление передачи, совпадает с направлением движения реального времени: с движением вперед. Следовательно, ЗУ - это канал, который позволяет передать в будущее информацию, сгенерированную в настоящем. Все последовательностные схемы и компьютеры в том числе, обладают свойством запоминания, и это позволяет их выходам в данный момент зависеть от входов в предыдущие моменты. Этим свойством схемы обязаны запоминающим элементам, например триггерам. В центре нашего внимания будут структуры запоминающих устройств, состоящих из большого числа запоминающих элементов с некоторой регулярной структурой.
Организация запоминающего устройства определяет способы передачи информации в устройство и из него. Обычно информация передается порциями, состоящими из фиксированного числа битов и называемыми словами. ЗУ можно представлять себе в виде некоторого пространства, состоящего из множества идентифицируемых позиций для размещения слов.
В некоторых ЗУ на каждую такую позицию отводятся свои фиксированные запоминающие элементы. В этом случае местоположение запоминающих элементов однозначно определяет позицию слова, называемую ячейкой. В других ЗУ слова перемещаются относительна множества запоминающих элементов, сохраняя упорядоченность относительно друг друга. В этом случае позиция слова идентифицируется как временем, так и местоположением запоминающих элементов.
Во всех случаях, когда слово информации передается в ЗУ, оно помещается в некоторую конкретную позицию. Этот процесс называется записью в память. С другой стороны, когда информация передается из памяти, она также выбирается из некоторой конкретной позиции, (обычно информация в этой позиции сохраняется). Этот процесс называется считыванием из памяти.
Существуют различные способы выбора той позиции, для которой производится операция записи или чтения. Средства выбора позиции, и передачи информации в позицию или из нее образуют средства доступа (или выборки).
ЗУ делятся на два главных типа:
1 ЗУ с произвольным доступом и
2 ЗУ с последовательным доступом.
К первому типу относят ЗУ, в которых доступ к любой позиции требует примерно одного и того же времени. Другими словами, мы можем наугад выбрать позицию, и это не отразится на времени, которое затрачивается на чтение или запись.
Ко второму типу относят ЗУ, доступ к которым возможен лишь в определенном порядке. В последующих разделах мы рассмотрим ЗУ обоих названных типов.
Организация ЗУ с произвольным доступом
Память с произвольным доступом — это такое ЗУ, в котором элемент данных, запомненный в ячейке, может быть непосредственно считан. Время, необходимое для выборки данной ячейки, оказывается примерно тем же, что и для любой другой ячейки. Каждая ячейка содержит фиксированное число запоминающих элементов и имеет свой идентифицирующий номер. Идентифицирующий номер, состоящий из фиксированного числа битов, называется адресом ячейки. Наличие адресов позволяет различать ячейки при обращении к ним для выполнения операций записи и чтения.
В общем случае ЗУ с произвольным доступом состоит из нескольких блоков, или модулей. Для полупроводниковой памяти модули обычно реализуются в виде отдельных интегральных схем. Состав и функции внешних сигнальных линий выбираются с таким расчетом, чтобы облегчить работу в системе с шинной организацией связей. В число таких линий входят линии для задания адреса слова, к которому производится обращение, линии, по которым передаются данные в модуль или из модуля, и несколько управляющих линий, позволяющих задать нужную операцию (запись или чтение).
Существует довольно много разновидностей модулей с набором внешних сигналов, соответствующих различным типам шин, однако большинство модулей можно отнести к одной из двух основных моделей, показанных на рис. 1.
Различаются они только линиями данных. У модели на рис. 1(a) имеется лишь один комплект линий данных, по которым передаются как поступающие данные при записи, так и выдаваемые данные при чтении. Модель на рис. 1 (б) содержит два раздельных комплекта линий для поступающих и выдаваемых данных.

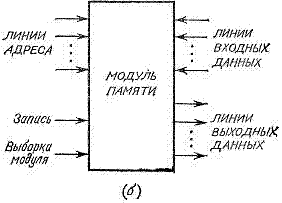
Рисунок 1 - Линии внешних сигналов в модулях памяти с произвольным доступом.
(а) Модуль с двунаправленными линиями данных.
(б) Модуль с раздельными линиями для поступающих и выдаваемых данных.
Обе модели имеют комплект адресных линий, сигналы на которых определяют ячейку, к которой осуществляется обращение для считывания или записи данных. В обеих моделях управляющая линия «запись» задает режим записи («запись»=1) или режим чтения («запись»=0). Наконец, управляющая линия «выборка модуля» в обоих случаях либо разрешает выполнение операций чтения/записи в данном модуле («выборка модуля» =1), либо запрещает ее выполнение («выборка модуля»=0).
Для того чтобы модули памяти, соответствующие любой из двух моделей, можно было включать в многомодульную систему ЗУ с шинной организацией, на линиях выдачи данных (т. е. на линиях данных в модели рис. 1(a) и на линиях выходных данных в модели на рис. 1(б)) используются вентили, допускающие монтажную логику. Модуль памяти любой модели выдает данные на выходные линии только при чтении; во всех остальных ситуациях этими линиями могут пользоваться другие модули памяти или устройства, подключенные к линиям. Это особенно важно для случая на рис. 1(a), поскольку при записи для передачи данных в ЗУ должны использоваться те же линии.
Состояние линий выходных данных, когда в модуле не выполняется чтение, конечно, зависит от типа монтажной логики. Например, для монтажного И на схемах ТТЛ с открытым коллектором состояние на свободной линии должно соответствовать логической 1, поскольку в данном случае 0 доминирует над 1 и, следовательно, другое устройство или модуль памяти сможет задать нужное ему состояние на линии. Для монтажного ИЛИ свободное состояние должно быть логическим 0. Для тристабильной монтажной логики свободное состояние — это, конечно, третье состояние с высоким импедансом, эквивалентное отсутствию соединения с линией. В любом случае линия выходных данных оказывается в свободном состоянии, когда либо подана логическая 1 на линию «запись», либо подан логический 0 на линию «выборка модуля».
Внутренняя организация ЗУ с произвольным доступом
Рассмотрев
внешние характеристики типичных модулей
памяти с произвольным доступом, перейдем
теперь к их внутренней организации.
Одна из возможных схем, позволяющая
выбирать нужную ячейку и осуществлять
передачу информации в нее или из нее,
представлена на рис. 2. В запоминающем
элементе для хранения одного бита слова
применяется асинхронный RS-триггер.
Помимо триггера, каждый запоминающий
элемент содержит вентили для передачи
информации между триггером и внутренними
линиями данных.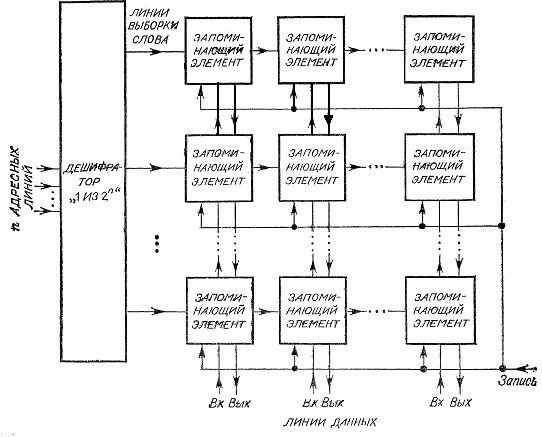
Рисунок 2 - Внутренняя организация памяти с произвольным доступом.
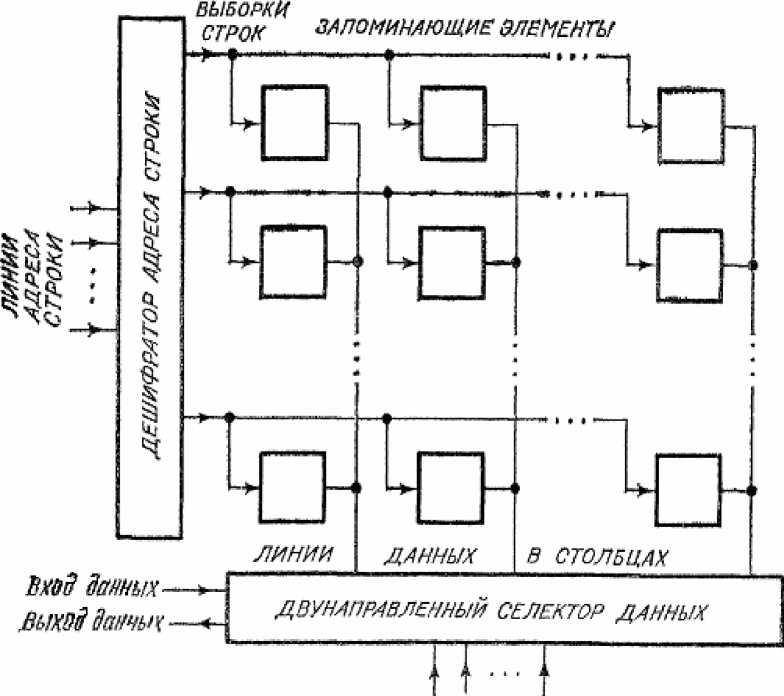
Одна из двух операций, чтение или запись, выполняется одновременно для всех элементов одной «строки». Каждая «строка» представляет собой ячейку для хранения слова и имеет свой адрес. Дешифратор «1 из 2n» служит для выбора ячейки по заданному адресу. На n входных линиях дешифратора возможны 2n комбинаций. Именно на них подается адрес нужной ячейки. Выходные 2n линий дешифратора называются линиями выборки слова. В зависимости от поданной на вход дешифратора комбинации какая-то одна линия выборки слова получает значение логической 1, а все остальные — логического 0. Каждая линия выборки слова используется как линия, разрешающая операцию чтения или записи во всех элементах строки.
В каждом столбце имеются по две внутренние линии: одна — для передачи данных в память (вход), а другая — из памяти (выход). Состояние линии «:выход» определяется состоянием запоминающего элемента в выбранной строке. Для этого выход триггера в каждом элементе логически умножается на сигнал «выборка слова», а логическая сумма всех результатов поступает в линию «:выход». Таким образом, чтение слова из памяти осуществляется подачей адреса нужного слова на вход дешифратора и наблюдением состояния на линиях «выход».
Линия «вход» каждого столбца используется для передачи информации в запоминающий элемент выбранной строки при выполнении операции записи. Это осуществляется с помощью двух вентилей И на каждый запоминающий элемент, которые при наличии сигналов «выборка слова» и «запись» передают сигнал из линии «вход» на вход S триггера, а его дополнение — на вход R. Таким образом, запись слова в память производится заданием адреса нужной ячейки на входе дешифратора, а записываемого слова — на линии «вход» и затем — логической 1 на управляющей линии «запись».
Нужно обратить внимание, что в приведенном выше описании фигурировали сигналы на линиях «запись», «вход» и «выход», являющиеся внутренними для модуля памяти. Эти сигналы связаны с внешними по отношению к модулю сигналами с помощью соответствующих вентилей и буферных схем. Такая связь может быть реализована различными способами в зависимости от требуемых внешних характеристик модуля.
Например, внешние характеристики модуля на рис. 1(a) можно получить с помощью схемы рис. 3. На ней три внешние линии: «запись», «выборка модуля» и «данные». Внутренний сигнал «запись» получается как И от внешних сигналов «запись» и «выборка модуля». Внутренние линии «вход данных» и «выход данных» для каждого бита в слове соединяются с внешней линией «данные» через входную буферную схему и тристабильный выходной формирователь, как показано на рисунке. Тристабильный формирователь управляется сигналом И от сигнала «выборка модуля» и инверсии сигнала «запись». Таким образом, внешняя линия данных работает как двунаправленная, подавая информацию на линию входа данных при записи и принимая информацию с линии выхода данных при чтении.
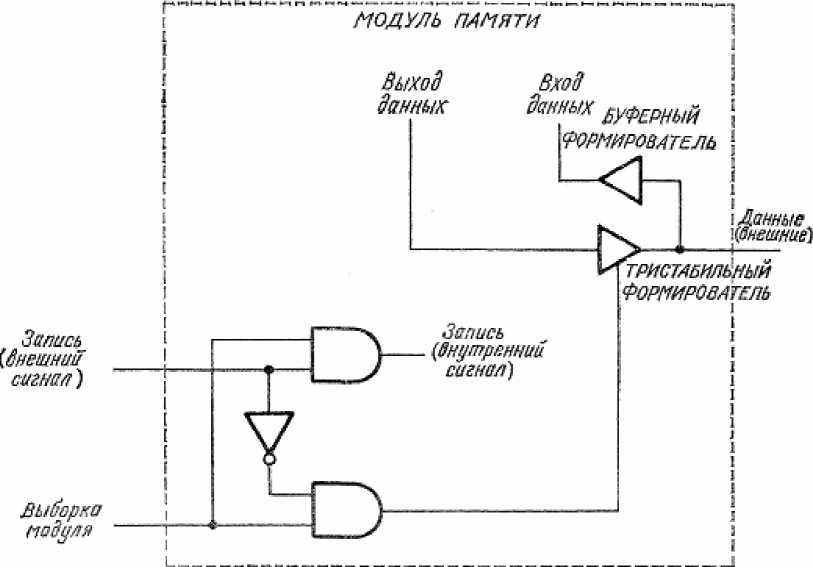
Рисунок 16 - Связь между внешними и внутренними сигналами в модуле памяти
2. Запоминающие устройства на биполярных транзисторах
Транзисторно-транзисторная логика — это одно из важнейших семейств логических элементов. Вентили этого семейства выполнены исключительно на биполярных транзисторах. Одна из возможных схем ТТЛ-вентиля представлена на рис. 3. Логические значения 0 и 1 соответствуют номинальным уровням потенциала 0В и +5 В. Как показано на рисунке, схему можно условно разделить на три части, рассмотренные нами в предыдущем разделе: комбинатор, восстановитель и буфер. Действие каждой из этих частей мы будем теперь изучать по отдельности.
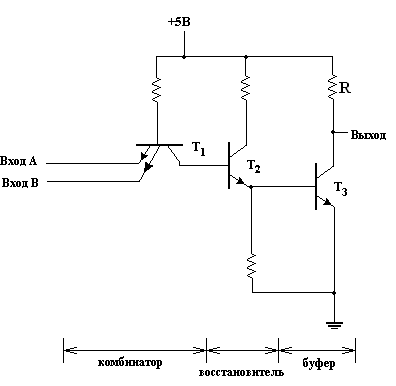
Рисунок 3 - ТТЛ-вентиль с нагрузочным резистором.
Комбинационная часть вентиля представлена многоэмиттерным транзистором Т1. На схеме показаны два эмиттера, но их может быть и больше. Каждый входной сигнал подается на свой эмиттер. Каждый эмиттер образует pn-переход с базой. При этом подразумевается, что если хотя бы один переход база-эмиттер имеет достаточное прямое смещение, то транзистор находится в проводящем состоянии, т. е. через вывод коллектора может протекать ток.
Поскольку на базу через резистор подается положительный потенциал, то переход база-эмиттер оказывается смещенным вперед всякий раз, когда потенциал соответствующего эмиттера близок к «нулевому», т. е. к потенциалу заземленной точки. Таким образом, транзистор будет находиться в проводящем состоянии, если хотя бы один эмиттер имеет низкий потенциал (логический 0). В этом случае через эмиттеры с низким потенциалом будет протекать заметный ток, обусловленный в основном током базы. Когда на все эмиттеры подается высокий потенциал (логическая 1), транзистор закрыт и ток во всех эмиттерах очень слабый.
Восстановительная часть вентиля состоит из транзистора Т2 и двух резисторов. База транзистора Т2 соединена с коллектором Т1, так что ток коллектора Т1 является током базы Т2. Когда транзистор Т1 комбинатора открыт, ток протекает от его коллектора к эмиттеру или эмиттерам, имеющим низкий потенциал. Направление этого тока противоположно тому, которое должен иметь ток базы транзистору Т2 для того, чтобы его переход база-эмиттер имел прямое смещение. Это означает, что всякий раз, когда транзистор Т1 открыт, транзистор Т2 закрыт.
В действительности заметней ток протекает от базы Т2 к коллектору Т1 лишь в течение коротких периодов, требующихся для того, чтобы Т2 перешел из насыщенного состояния в закрытое. Этот ток поддерживается уходящими из области базы Т2 зарядами, накопившимися за то время, пока транзистор Т2 находился в насыщенном состоянии. После того как Т2 оказывается закрытым, через его базу проходит лишь очень слабый ток.
С другой стороны, если транзистор Т1 закрыт, его переход база-коллектор смещен в прямом направлении, благодаря тому что к резистору базы приложен потенциал +5 В. Поэтому переход база-коллектор Т1 , как и любой pn-диод, имеющий прямое смещение, должен находиться в проводящем состоянии. Это в свою очередь обусловливает прямое смещение перехода база-эмиттер Т2, так что Т2 оказывается в насыщенном (проводящем состоянии). Каждое из этих двух противоположных состояний транзистора Т2 (отсечка и насыщение) наблюдается на самом деле для целого диапазона условий на входе. В этом смысле цепь транзистора Т2 действительно играет роль восстановителя сигнала.
Буферная часть вентиля состоит из транзистора Т3 и резистора. Потенциал базы Т3 управляется эмиттером транзистора Т2восстановителя. Когда транзистор Т2 находится в проводящем состоянии, потенциал его эмиттера принимает некоторое положительное значение между 0 и +5 В; конкретное значение зависит от двух резисторов в цепи восстановителя. Это в свою очередь приводит к тому, что переход база-эмиттер буферного транзистора Т3 имеет прямое смещение, вследствие чего транзистор Т3 оказывается открытым. В такой ситуации на выходе вентиля наблюдается потенциал, близкий к потенциалу «земли».
С другой стороны, когда транзистор Т2 восстановительной цепи не проводит, уровень потенциала на его эмиттере оказывается «нулевым». По этой причине переход база-эмиттер транзистора Т3 не будет иметь прямого смещения, и, следовательно, Т3 будет закрыт. В этой ситуаций благодаря резистору в коллекторной цепи буфера на выходе вентиля установится потенциал, близкий к потенциалу питания +5 В. Действительная величина потенциала на выходе зависит от падения напряжения на резисторе, которое обусловлено проходящим через этот резистор током нагрузки. Поведение рассмотренного нами ТТЛ-вентиля описано в табл. 1. Если заменить значения 0 В и 5 В соответственно на 0 и 1, то мы увидим, что табл. 1 описывает поведение логического вентиля, реализующего функцию И-НЕ. Если схема имеет лишь один эмиттер на входе, то такой вентиль является инвертором.
Таблица 1 - Действие ТТЛ-вентиля, изображенного на рис. 3
|
А В |
Состояние Т1 Состояние Т2 Состояние Т3 |
Выход |
|
0 В 0 В 0 В 5 В 5 В 0 В 5 В 5 В |
Открыт Закрыт Закрыт Открыт Закрыт Закрыт Открыт Закрыт Закрыт Закрыт Открыт Открыт |
~5 В ~5 В ~5 В
~0 В |
Теперь вернемся опять к буферной части вентиля. Буфер должен быть способен пропустить ток, который необходим для правильной работы входных цепей подключенных к нему других вентилей. Существенный ток на входе ТТЛ-вентиля наблюдается лишь тогда, когда этот вход имеет низкий потенциал. В этом случае ток течет от входа управляемого вентиля к выходу управляющего вентиля. Рассмотренная нами буферная цепь удовлетворяет требованиям, предъявляемым к управляющему вентилю, если его буферный транзистор способен пропустить через себя суммарный ток, приходящий ото всех управляемых им входов, а также от своего коллекторного резистора.
Однако задержка распространения сигнала для такого вентиля будет большой из-за того, что для переключения от низкого потенциала на выходе к высокому при закрытом буферном транзисторе используется резистор. Между выходной линией вентиля и «землей» всегда образуется довольно ощутимая паразитная емкость. Эта емкость складывается не только из емкости монтажных соединений, но и из емкости на переходах транзисторов.
Паразитная емкость должна успеть зарядиться, прежде чем выход вентиля сможет перейти от низкого уровня потенциала к высокому. Ток заряда в основном течет через коллекторный резистор. Таким образом, потенциал на выходе растет экспоненциально с постоянной времени, определяемой сопротивлением резистора и паразитной емкостью. Переключение от высокого потенциала к низкому происходит значительно быстрее, поскольку емкость разряжается на землю через низкое сопротивление открытого транзистора.
3. Запоминающие устройства на полевых транзисторах.
Существует несколько семейств элементов на полевых транзисторах. Два широко известных семейства построены на основе n-МОП-технологии и p-МОП-технологии и используют соответственно n-канальные и р-канальные транзисторы. Третье семейство, построенное на основе КМОП-технологии, использует в одном вентиле как n-канальные, так и р-канальные транзисторы.
Логические элементы на n-канальных и p-канальных МОП-транзисторах обычно выполнены в виде схем с непосредственной связью. Это означает, что для реализации различных логических функций используется последовательное-параллельное соединение транзисторов, действующих как переключатели. Например, вентиль ИЛИ-НЕ с двумя входами можно построить путем параллельного соединения двух n-канальных нормально закрытых (работающих в режиме обогащения) МОП-транзисторов. Этот вентиль изображен на рис. 8.
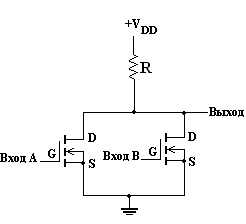
Рисунок 8 - Вентиль ИЛИ-НЕ с двумя входами, построенный на n-канальных нормально закрытых МОП-транзисторах.
Если к одному из транзисторов приложено положительное напряжение, он переходит в открытое состояние и образует тем самым путь низкого сопротивления между выходной линией и землей. В результате на выходе устанавливается низкий потенциал. С другой стороны, если к обоим транзисторам приложен потенциал земли, они будут закрыты. В этой ситуации через линию резистора R на выходе установится потенциал, приблизительно равный VDD , так как закрытые транзисторы имеют высокий импеданс. В рамках положительной логики вентиль на рис. 8 реализует логическую операцию ИЛИ-НЕ, потому что низкий уровень на выходе наблюдается тогда и только тогда, когда по крайней мере на один из входов подан высокий потенциал.
Если n-канальные нормально закрытые МОП-транзисторы соединить последовательно, как показано на рис. 9, то получится вентиль И-НЕ. В этом случае, лишь когда оба входа имеют высокий потенциал, последовательно соединенные транзисторы образуют путь со сравнительно низким сопротивлением между выходом и землей. Если хоти бы один вход имеет низкий потенциал, на выходе будет приблизительно VDD . Поскольку при последовательном соединении сопротивлении складываются, количество последовательно соединенных транзисторов ограничено.
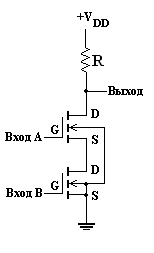
Рисунок 9 - Вентиль И-НЕ с двумя входами, построенный на n-канальных нормально закрытых МОП-транзисторах.
Устройство р-МОП-вентилей в основном аналогично n-МОП-схемам. Однако р-канальные МОП-транзисторы работают при отрицательном напряжении на затворе и стоке по отношению к истоку. Поэтому р-МОП-вентили, подобные изображенному на рис. 10 инвертору, имеют отрицательное питающее напряжение, и уровни потенциала на выходе у них отрицательные.
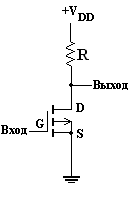
Рисунок 10 - p-МОП-инвертор.
МОП-транзисторы отличаются очень высоким сопротивлением для тока затвора, вследствие чего в статическом состоянии МОП-вентили практически не потребляют тока от управляющих ими схем. Это означает, что они имеют большой коэффициент разветвления по выходу. Наряду с этим они позволяют достичь сравнительно высокой плотности упаковки логических элементов в интегральной схеме. С другой стороны, емкости, образующиеся между затвором МОП-транзистора, истоком, стоком и подложкой, довольно значительны. Поэтому вентили на МОП-транзисторах отличаются меньшим быстродействием по сравнению с биполярными семействами—эти емкости должны успеть перезарядиться, прежде чем произойдет переключение. Кроме того, ток, перезаряжающий емкости, должен поступать от управляющего вентиля, что приводит к значительному увеличению рассеиваемой мощности при высокой частоте переключения.
ДВУМЕРНАЯ АДРЕСАЦИЯ
Недостаток рассмотренной схемы ЗУ произвольного доступа связан с большим размером адресного дешифратора. Например, при n = 10 адресный дешифратор должен иметь 210= 1024 выхода. Каждый выход должен быть соединен с запоминающим элементом в строке. Количество связей можно уменьшить, если часть функций дешифратора передать самому запоминающему элементу.
Чтобы показать, каким образом это может быть сделано, возьмем один столбец ЗУ с организацией, приведенной на рис. 2, и построим из него прямоугольную матрицу. При n=10 число запоминающих элементов равно 210. Можно построить матрицу размером 25х25 или в общем случае 2nx2n-m эту как показано на рис. 4. Каждый элемент исходного столбца теперь лежит на пересечении новых строки и столбца прямоугольной матрицы. Возьмем два дешифратора с n/2 входными и 2n/2 выходными линиями в каждом (будем считать, что n четно и матрица квадратная). При n=10 число 2n2 равно 32. Выходные линии одного дешифратора будут служить для выборки строки, а другого — для выборки столбца матрицы. Общее число выходных линий в дешифраторах при таком подходе равно 2n/2+2n/2=2n/2+1, что существенно меньше 2П линий при одном адресном дешифраторе.
ЗАПОМИНАЮЩИЕ ЭЛЕМЕНТЫ

Рисунок 4 - Двумерная адресация ЗУ с произвольным доступом.
В каждом запоминающем элементе должна выполняться операция И над линиями выборки строки и столбца. Эта операция даст логическую 1 только для одного элемента, находящегося на пересечении выбранных строки и столбца, и логический 0 для всех остальных элементов, поскольку для них либо сигнал выборки столбца, либо строки будет равен 0. Выходной сигнал вентиля И выполняет функции сигнала выборки бита, который разрешает чтение или запись в данном элементе.
Аналогичные двумерные матрицы нужны для всех остальных битов в слове. Матрицы можно считать лежащими в параллельных плоскостях. Оба адресных дешифратора работают сразу на все плоскости, таким образом, все биты ячейки адресуются одновременно. Полезно обратить внимание на то, что число выходных линий в дешифраторах при этом не увеличивается.
ЗУ С ВНУТРЕННЕЙ ДВУНАПРАВЛЕННОЙ ШИНОИ ДАННЫХ
Дальнейшее сжижение числа внутренних связей в модуле памяти с произвольным доступом можно получить за счет внутренних входных и выходных линий данных, показанных на рис. 2. Для этого обе линии данных каждого бита слова заменяются одной двунаправленной линией. При записи информация посылается по этой линии в выбранную ячейку. При чтении информация из выбранной ячейки выдается на эту же линию. Здесь вполне применима монтажная логика и методика ее использования. Применение монтажной логики позволяет получить еще и дополнительную экономию в связи с тем, что становятся ненужными вентили ИЛИ, присутствующие в каждом запоминающем элементе на схеме рис. 2 и связывающие все элементы столбца с выходной линией данных.
&Л/70ММНА ЮЩ. ИСХГ7е:М£МТ&Г
X
I
I
ь
ёФ в & «5, (Л а *■ х га
ё
I
ЛМРеСЛ СГОМБЦЛ
.^Я/Ит'Ь'С
Тф*Т
У7Р*НМИ
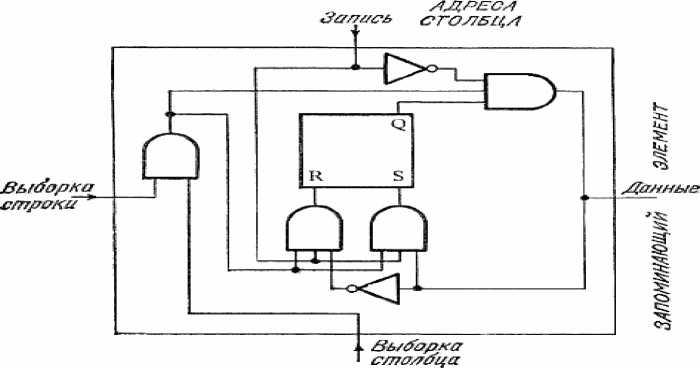
Рисунок 5 - ЗУ с двумерной адресацией и двунаправленной линией данных. Показана плоскость одного бита слов.
Такая схема модуля памяти приведена на рис. 5. На том же рисунке приведена логическая схема запоминающего элемента с изменениями, требующимися для двумерной адресации и для работы с одной двунаправленной линией данных. Сигнал «запись» определяет направление передачи по линии данных. Логическая 1 на линии «запись», как и прежде, разрешает передачу данных в запоминающий элемент выбранной ячейки. Логический 0 разрешает обратную передачу. Это обеспечивается наличием в каждом запоминающем элементе вентиля И, на входы которого подаются три сигнала: инверсия «записи», «выборка бита» и выход триггера. Здесь применяется специальный вентиль И, позволяющий получить монтажное ИЛИ. Соединение выходов вентилей И с линией данных дает монтажное ИЛИ этих выходов.
ВЫБОРКА СТОЛБЦА С ПОМОЩЬЮ СЕЛЕКТОРА ДАННЫХ
Последняя рассмотренная схема часто встречается в варианте, представленном на рис. 6. Как следует из рисунка, здесь также используется двумерная адресация запоминающих элементов. Однако, вместо того чтобы выделять выбранный столбец в самом запоминающем элементе, выделение столбца делается «на границе матрицы» в специальном двунаправленном селекторе данных. Строка выбирается обычным способом. Данные между элементами и селектором в, каждом столбце передаются по отдельным двунаправленным линиям.
линий
АДРЕСА
СТОЛБЦА
Запись
МШИ И
Рисунок 6 - Двумерная матрица для одного бита памяти с произвольным доступом при использовании селектора данных для выборки столбца.
При чтении по линиям, соответствующим столбцам, содержимое всех элементов строки посылается в селектор, а селектор уже выбирает бит одного, столбца в соответствии с заданным адресом и выдает этот бит на выходную линию данных. При записи селектор возбуждает линию только одного столбца, соответствующего заданному адресу, подавая в нее значение входной линии данных. Это значение доминирует над значением, которое выдает в линию элемент выбранной строки. Специальные схемы в запоминающем элементе осуществляют как доминирование («старшинство») поступающего извне значения, так и сохранение этого значения в запоминающем элементе выбранной строки. В результате достигается дальнейшее снижение числа соединений, поскольку с помощью одной линии на столбец выполняется и выборка столбца, и передача данных.
Рассмотренные схемы позволяют понять общие принципы работы запоминающих устройств с произвольным доступом. Они обладает возможностями как запоминать информацию в заданной ячейке, так и получать ее из заданной ячейки. Такие ЗУ называются ЗУ со считыванием и записью или оперативными ЗУ, сокращенно ОЗУ. Во многих ситуациях желательно получать информацию из заданных ячеек, не имея возможности изменить их содержимое. ЗУ такого типа называют постоянными ЗУ или, сокращенно, ПЗУ.
ЭЛЕКТРОННЫЕ СХЕМЫ ОПЕРАТИВНОЙ ПАМЯТИ
По способу хранения информации в запоминающих элементах полупроводниковые ОЗУ делятся на две основные категории:
статические и
динамические.
Статические элементы способны хранить информацию как угодно долго, пока подается электропитание. Все рассмотренные нами триггеры обладали этим свойством.
Динамические запоминающие элементы, напротив, способны хранить информацию только короткое время. Поэтому для сохранения информации ее нужно периодически обновлять, или, другими словами, регенерировать. В качестве динамического элемента, хранящего бит информации, можно воспользоваться заряженным конденсатором. Использование динамических элементов приводит к упрощению схем, снижению потребляемой мощности, а иногда и к повышению скорости работы.
Для обеих категорий оперативных ЗУ уже существует много различных электронных схем и еще больше, по-видимому, появится в будущем. Их разнообразие отражает не только разнообразие технологий (ТТЛ, МОП, КМОП, ЭСЛ и т. п.) и конструкций, но еще и разнообразие требований, предъявляемых к модулям памяти в отношении быстродействия, емкости, плотности упаковки логических элементов и потребляемой мощности.
Для иллюстрации мы выбрали и рассмотрим в этом разделе три типичных примера схем, хотя, конечно, из различных технических описаний можно получить детальные сведения о многих других вариантах ОЗУ. В качестве примеров мы выбрали статическое ОЗУ на ТТЛ-схемах, а также статическое и динамическое ОЗУ на МОП-схемах.
Статическое ОЗУ на ТТЛ-схемах
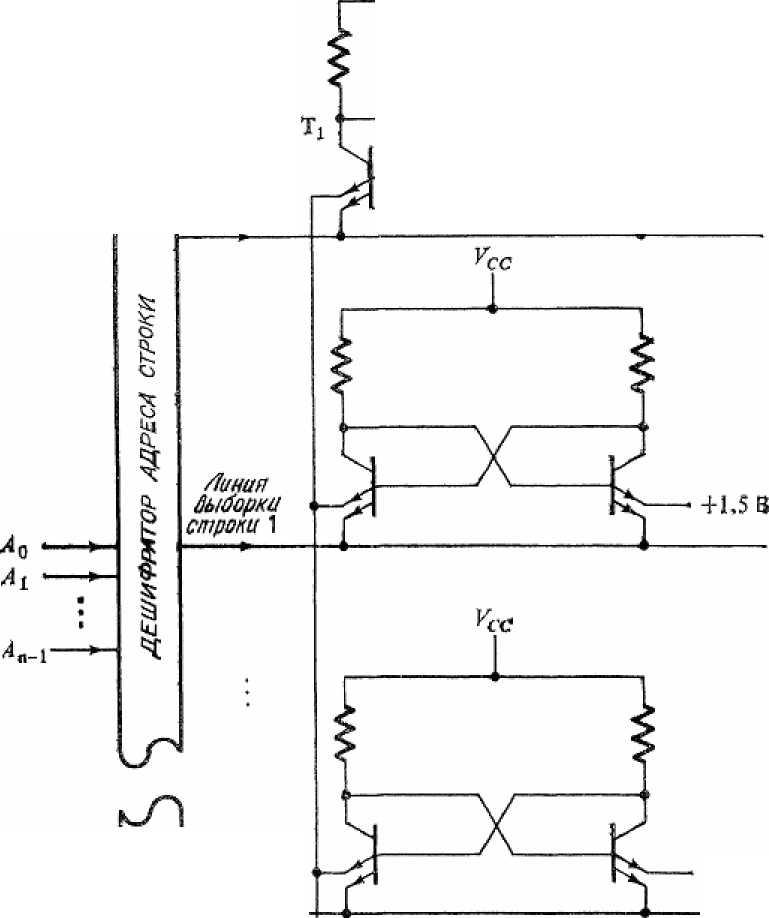
На рис. 20 показана конфигурация модуля статического ОЗУ на ТТЛ-схемах и электронная схема каждого запоминающего элемента. В схеме два транзисторных каскада, соединенных крест-накрест и способных находиться в двух устойчивых состояниях. В каждом транзисторе по два эмиттера, что позволяет осуществлять как хранение информации, так и выборку элемента. Такой транзистор открыт, т. е. проводит ток, если открыт (имеет прямое смещение) хотя бы один переход база-эмиттер.
Следовательно, состояние транзистора зависит от того из двух эмиттеров, на котором потенциал ниже.
1
X
+ 1.5 В
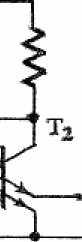
+1.5$
ДРУГИЕ
СТОЛБЦЫ
Пиния
ёыбарт
СЯфШ/О
АДРЕС
Линия Выборки строки 2*4
Замечание I Есаа эашшь=й,
та усихитет считывания Ланин номвтяьни тдВержвдвет
ванных на сваей входной ланш
Вшивные ванные
Рисунок 20 - Статическое ОЗУ на ТТЛ-схемах.
входные
ванные'
Запись
потенцией 1.5 В. Лвзтвшу содержимое счатыва&мога элемента не разрушает о я
Если строка, где находится рассматриваемый запоминающий элемент, не выбрана, то соответствующая линия выборки несет низкий потенциал, и он подается на нижние по схеме эмиттеры. В этом случае схема ведет себя, как обычная бистабильная схема, и сохраняет то состояние, в которое она была установлена раньше. А именно если транзистор Т открыт, то его коллектор и, следовательно, база транзистора Т2 имеют низкий потенциал. При этом Т2 окажется закрытым, что приведет к высокому потенциалу на его коллекторе и базе Т2.
Высокий потенциал на базе Т означает, что Т открыт, как и было предположено сначала. Таким образом, это состояние стабильно, т. е. самоподдерживается. В силу симметрии противоположное состояние, когда Т закрыт, а Т2 проводит, также стабильно. Легко видеть, что наша схема аналогична обычному триггеру, составленному из двух вентилей И-НЕ, соединенных крестообразно. Фактически каждый транзисторный каскад нашей схемы выполняет функцию двухвходового вентиля И-НЕ.
С другой стороны, если строка с данным элементом выбрана, то линия выборки и нижние эмиттеры транзисторов имеют высокий потенциал. Следовательно, проводимость транзистора будет зависеть от верхнего эмиттера. На верхний эмиттер транзистора Т2 подан фиксированный уровень 1.5 В. Поэтому состоянием схемы можно управлять, меняя потенциал верхнего эмиттера в транзисторе Т относительно уровня 1.5 В.
Если на линию данных подать низкий уровень, то Т станет проводящим. Это справедливо, так как потенциал коллектора Т2, равный потенциалу базы Т2, должен быть выше 1.5 В, и это гарантирует прямое смещение верхнего перехода база-эмиттер, достаточное, чтобы открыть транзистор Т . Проводимость Т приводит к низкому потенциалу на базе Т2 и к его закрытию. Это состояние схемы ассоциируется с логической
1.
В противоположное состояние схему можно привести, если оставить верхний эмиттер Т «свободным» (плавающим). В этом случае Т будет закрыт, что приведет к высокому потенциалу на его коллекторе и базе Т2. Следовательно, Т2 будет открыт. Это состояние ассоциируется с логическим 0.
В каждом столбце на линию данных, подсоединенную к верхним эмиттерам всех транзисторов Т2, работает вентиль И-НЕ с открытым коллектором. На один вход этого вентиля подается сигнал с линии «входные данные», т. е. с источника бита, записываемого в рассматриваемом столбце, а на другой вход подается сигнал «запись». Если значение сигнала «запись» равно логической 1, то логическая 1 на линии «входные данные» дает низкий потенциал на выходе вентиля И-НЕ, что приводит выбранный запоминающий элемент в состояние 1; с другой стороны, при логическом 0 на линии «входные данные» выход вентиля остается «свободным» (плавающим), что приводит выбранный
запоминающий элемент в состояние 0.
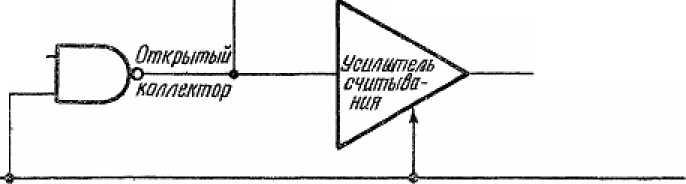
Если же на линии «запись» логический 0, то запись не должна производиться и ни один элемент не должен менять своего состояния. Более того, в этой ситуации может выполняться операция чтения. Для достижения обеих этих целей в каждом столбце предусмотрен специальный усилитель считывания, реагирующий на ток. Разрешающим сигналом для этого усилителя является логический 0 в линий «запись». Когда усилитель открыт, он поддерживает потенциал в линии данных для столбца близким к 1.5 В. Это обеспечивает неизменность состояния запоминающего элемента в выбранной строке, поскольку оба его верхних эмиттера имеют равные потенциалы. Более того, усилитель реагирует на наличие тока в линии данных столбца и выдает на линию «выходные данные» соответствующее напряжение.
Если транзистор Т1 в выбранном элементе проводит, что соответствует состоянию 1, ток идет через верхний эмиттер, поскольку на нижний эмиттер подан высокий потенциал. Этот ток, проходя через линию данных и усилитель считывания, даст логическую 1 на линии «:выходные данные». Если же выбранный элемент хранит 0, то Т не проводит, и отсутствие тока через усилитель устанавливает логический 0 в линии «выходные данные».
Подведем итоги. Чтобы выполнить операцию записи в рассматриваемом модуле памяти, прежде всего нужно задать адрес для выборки строки. Затем нужно установить логическую 1 на линии «запись» и подать записываемые данные на линию «входные данные». При этом элемент в выбранной строке примет состояние, соответствующее записываемым данным. Состояние элементов в невыбранных строках не изменится. Для выполнения операции чтения нужно поддерживать логический 0 на линии «запись» и задать адрес для выборки строки. Откликнется только элемент в выбранной строке. Состояние этого элемента будет определено по току транзистора Т . Соответствующее логическое значение при этом появится на линии «выходные данные».
Статическое ОЗУ на МОП-схемах
На рис. 21 показана некоторая конфигурация модуля статической памяти на МОП- схемах. Как и в предыдущем примере, каждый запоминающий элемент является бистабильной схемой, или триггером. В нем два соединенных крест-накрест транзисторных каскада, но транзисторы, естественно, не биполярные, аполевые, Транзисторы на рисунке нормально закрытые n-канальные (работающие в режиме обогащения), хотя выпускаются ЗУ и с другими типами транзисторов. Показанный на схеме нагрузочный резистор обычно реализуется также в виде транзистора по аналогии с тем, как это делалось для МОП-вентилей.
Основное отличие между схемами, изображенными на рис. 20 и 21, помимо различия в типах транзисторов, заключается в способе доступа к запоминающим элементам. В памяти с МОП-элементами для передачи информации к элементу и от элемента выбранной строки в каждом столбце используются две линии, работающие в противофазе, или парафазно. Элементы в столбцах подключаются к линиям данных через n-канальные, нормально закрытые МОП-транзисторы. Эти подключающие транзисторы выполняют функции двусторонних ключей в том смысле, что как ток, так и информация может течь в обоих направлениях. Это возможно, поскольку подложки транзисторов подсоединены к земле, а не к истоку. Когда на затвор подано достаточное положительное напряжение, между истоком и стоком возникает проводимость. Транзистор в этом случае проводит в обоих направлениях, поскольку симметрия транзистора позволяет истоку, и стоку при необходимости меняться ролями.
Затворы подключающих транзисторов соединены с соответствующими линиями выборки строк, которые, как и прежде, являются выходами адресного дешифратора. Следовательно, открытыми оказываются подключающие транзисторы только в выбранной строке, определенной поданным на дешифратор адресом. Таким образом обеспечивается связь между линиями данных и выбранными элементами в каждом столбце.
Запись осуществляется подачей низкого потенциала на одну из двух парафазных линий в каждом столбце в соответствии со значением на линии входных данных. Благодаря этому в запоминающем элементе выбранной строки устанавливается нужное состояние. Парафазные линии данных управляются МОП-транзисторами. Затворы этих транзисторов соединены с выходами вентилей И, определяющих условия, при которых транзисторы должны быть открыты. Линия «запись» соединена со входами обоих вентилей, а линия «входные данные» соединена с правым вентилем непосредственно, а с левым через инвертор.
Лшя
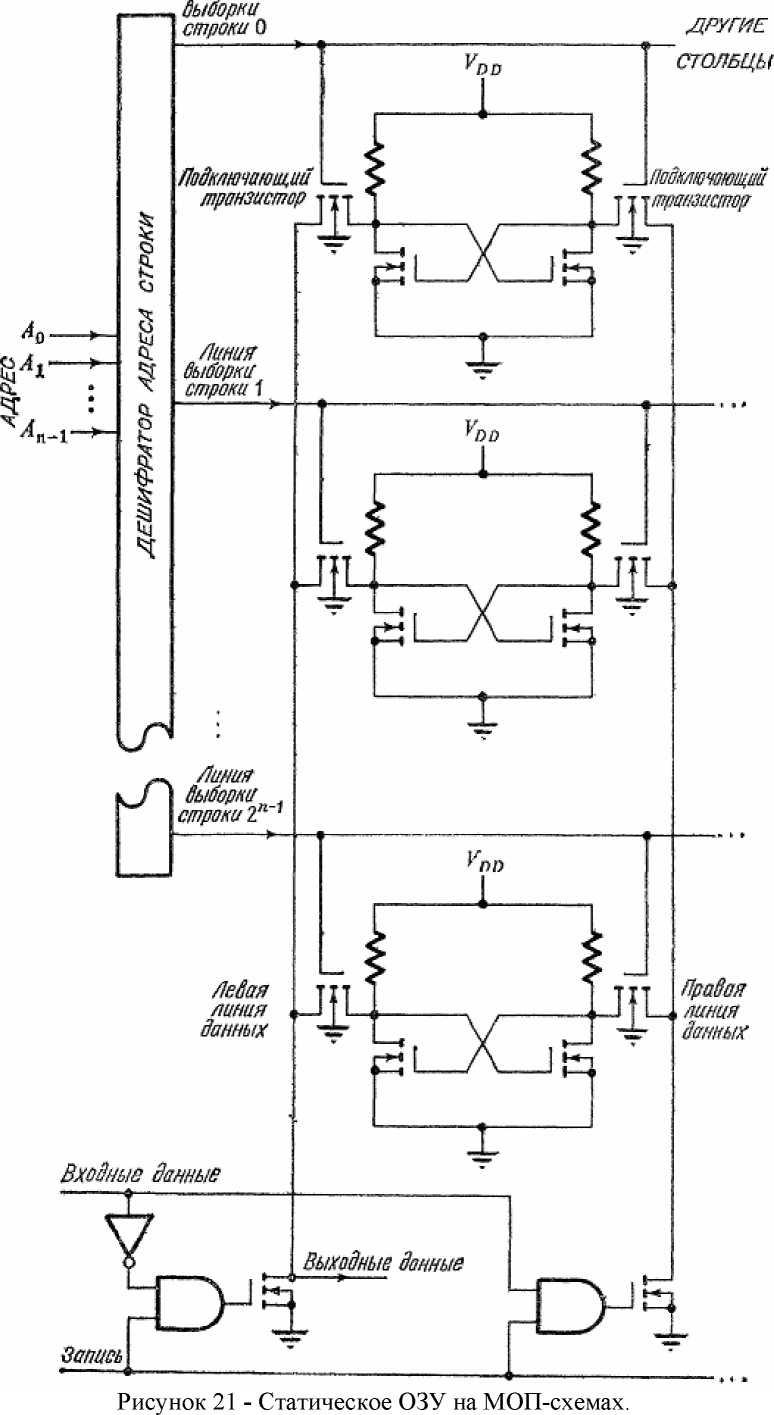
Таким образом, когда на линии «запись» логическая 1 и на линии «входные данные» логическая 1, на затворе правого транзистора будет высокий потенциал, и транзистор будет открыт. В результате правая половина запоминающего элемента окажется под низким потенциалом, а левая — под высоким. Это стабильное состояние соответствует запомненной логической 1. Если же на линии «входные данное» будет логический 0, а на линии «запись» — логическая 1, то открытым окажется левый транзистор, благодаря чему в выбранном запоминающем элементе устанавливается стабильное состояние, соответствующее логическому 0.
Если на линии «запись» логический 0, то оба управляющих транзистора закрыты, и состояние запоминающих элементов не меняется. На линиях данных в столбце при этом будут значения, соответствующие состоянию элемента в выбранной строке, поскольку подключающие транзисторы этого элемента открыты. В частности, значение на левой линии будет равно запомненному в элементе значению. Следовательно, операция чтения сводится к определению значения на левой линии, когда сигнал «запись» равен логическому 0.
Динамические ОЗУ на МОП-схемах
На рис. 22 показан модуль динамической памяти на МОП-схемах. В основе запоминающего элемента лежит конденсатор и один МОП-транзистор (Т2). На схеме конденсатор показан в виде отдельного прибора, включенного между затвором и истоком транзистора Т2, хотя фактически его функции и выполняет емкость затвор-подложка, которая существует и любом МОП-транзисторе за счет параллельного расположении электрода затвора по отношению к подложке. Хранение данных в таком запоминающем элементе связано с состоянием проводимости Т2, которое определяется зарядом конденсатора. Если заряд конденсатора обеспечивает достаточный положительный потенциал на затворе Т2 , то Т2 проводит. Это состояние ассоциируется с логическим 0 и не является самоподдерживающимся, поскольку конденсатор постепенно саморазряжается. Если же заряд конденсатора мал или отсутствует, то Т2 не проводит. Это состояние ассоциируется с логической 1 и является самоподдерживающимся.
Кроме конденсатора и транзистора Т2, в каждом запоминающем элементе присутствуют два транзистора для подключения элемента к линиям данных. В каждом столбце две такие линии: одна для записи данных в выбранный элемент («запись данных»), другая для считывания данных из выбранного элемента («чтение данных»). Транзистор Т2 выполняет функции двустороннего ключа для подключения линии «запись данных» к конденсатору элемента. Если Т2 активирован, то конденсатор можно зарядить или разрядить через эту линию. Транзистор Т3 подключает линию «чтение данных» к стоку Т2. Если Т3 открыт, то состояние запоминающего элемента опрашивается через линию «чтение данных». Управляются транзисторы Т1 и Т3 соответствующими линиями выборки строк от дешифратора адреса строки.
В процессе функционирования данные передаются на конденсатор элемента независимо от вида обращения, т. е. и при записи, и при чтении. При записи данные на конденсаторе поступают по линии «входные данные», и в этом случае они замещают, данные, которые были раньше. При чтении данные на конденсатор поступают от самого элемента по линии чтения. Таким образом, как можно видеть на рис. 22, при чтении возникает цепь обратной связи для данных.
Выбор данных, посылаемых на конденсатор, осуществляется селектором данных из четырех вентилей, работающим на линию «запись данных». Сигнал в линии «запись» управляет селектором, переключая его либо на «входные данные», либо на «чтение данных». Причем при любом источнике данных сигнал инвертируется, поскольку высокое напряжение на конденсаторе соответствует логическому 0, и это противоречит обычным соглашениям и отношении линий данных.
Линия
tlbtfopm

АДрЕС
Состояние проводимости транзистора Т2 в выбранном элементе преобразуется и напряжение на линии «чтение данных» при помощи нагрузочного резистора. Если Т2
проводит, что соответствует состояний 0, на линии будет низкий потенциал. В противном случае благодаря резистору линия будет под высоким потенциалом.
Как мы отмечали, состояние момента, хранящего логический 0, не является самоподдерживающимся, поскольку конденсатор из-за утечек постепенно разряжается. Через некоторое время заряд достигает такого уровня, что состояние становится неотличимым от состояний логической 1. До того как это произойдет, нужно регенерировать элемент, выполнив операцию чтения. Следовательно, модули динамической памяти требуют, чтобы каждая строка периодически регенерировались через определенный промежуток времени, Период регенерации обычно составляет несколько миллисекунд. Чтобы число строк было небольшим, в модулях динамической памяти обычно используется двумерная адресация и двунаправленный селектор выборки столбцов для разных слов. При таком подходе регенерация занимает меньше времени, поскольку регенерируются все слова в строке одновременно.
На практике в запоминающих устройствах, состоящих из нескольких модулей, процессом регенерации управляет специальная логическая схема. Эта схема циклически перебирает строки во всех модулях и регенерирует их. При этом, если модуль находится в процессе регенерации, могут возникнуть задержки при обращении к памяти от процессора.
По сравнению со статической памятью динамическая, очевидно, сложнее и требует больше внешних схем. Однако для некоторых приложений эти недостатки вполне окупаются целым рядом достоинств. Главное достоинство — это более высокая плотность упаковки информации (число битов на модуль) благодаря меньшему числу электронных компонентов в динамическом запоминающем элементе по сравнению со статическим. Второе преимущество связано с тем, что динамический запоминающий элемент не потребляет тока, за исключением тех относительно коротких отрезков времени, когда к нему обращаются. Благодаря этому резко снижается общая рассеиваемая ЗУ мощность. Довольно часто максимальная рассеиваемая мощность оказывается главным фактором, ограничивающим плотность упаковки запоминающих элементов, и в таких случаях динамическая память имеет несомненные преимущества.
3 ПРОГРАММИРУЕМЫЕ ЛОГИЧЕСКИЕ ИНТЕГРАЛЬНЫЕ СХЕМЫ
История развития программируемой логики начинается с появления программируемых постоянных запоминающих устройств (ППЗУ - Programmable Read Only Memory - PROM) в начале 70-х годов. Первое время PROM использовались исключительно для хранения данных, позже их стали применять для реализации логических функций. Неудобство использования PROM в качестве логических преобразователей заключается в том, что логические функции перед записью в PROM необходимо приводить к совершенной дизъюнктивной нормальной форме (СДНФ), кроме того, емкость PROM не позволяла реализовать функции большого числа переменных.
Специально для реализации систем булевых функций (СБФ) большого числа переменных были разработаны и с 1971 г. стали выпускаться промышленностью программируемые логические матрицы (ПЛМ - Programmable Logic Arrays - PLAs). Именно PLA можно считать первыми программируемыми логическими устройствами (Programmable Logic Devices - PLD). PLA получили очень широкое распространение в качестве универсальной элементной базы.
Совершенствование архитектуры PLA привело к появлению программируемых матриц логики (Programmable Array Logics - PALs), которые на долгие годы определили наиболее популярную архитектуру PLD. Первые PAL были разработаны фирмой Monolithic Memories в 1976 году. Позже фирма Monolithic Memories вошла в состав фирмы Advanced Micro Devices (AMD), которая начала производить PAL c 1977 года. Сейчас аббревиатура PAL является торговой маркой фирмы AMD.
С момента своего появления PAL стали успешно конкурировать с PLA и в настоящее время благодаря ряду присущих им положительных свойств практически полностью вытеснили программируемые пользователем PLA.
Дальнейшее совершенствование технологии производства интегральных схем, повышение степени интеграции, успехи в создании корпусов с большим числом внешних выводов в начале 90-х годов привели к возможности реализации на одном кристалле нескольких PAL, объединяемых программируемыми соединениями. Подобные архитектуры получили название сложных PLD (Complex PLD - CPLD), соответственно все разработанные ранее PLD стали называть стандартными PLD (Standart PLD - SPLD) или классическими PLD (Classic PLD).
Основу всех рассмотренных выше устройств составляют программируемые матрицы. Поэтому эти устройства еще называют программируемыми логическими устройствами, имеющими матричную структуру.
Параллельно с PLD также развивались архитектуры вентильных матриц (Gate Array - GA) или матриц логических ячеек (Logic Cell Array - LCA), в русскоязычной литературе получившие название базовых матричных кристаллов (БМК). Первые вентильные матрицы были полузаказными, т.е. программировались во время изготовления, что сдерживало их широкое практическое использование. Однако в 1985 году фирма Xilinx выпустила программируемую пользователем вентильную матрицу (Field Programmable Gate Array - FPGA). Это дало сильный толчок к широкому распространению вентильных матриц и конкуренции их с PLD.
В русскоязычной литературе нет четкого разделения между PLD, PAL, PLA, SPLD, CPLD и FPGA. Чаще всего все эти устройства называют программируемыми логическими интегральными схемами (ПЛИС). Кроме того, в русскоязычной литературе можно встретить следующую терминологию: программируемые логические устройства (ПЛУ) - для обозначения PLD, программируемые логические матрицы (ПЛМ) - для обозначения PLA, программируемые матрицы логики (ПМЛ) - для обозначения PAL,
программируемые логические интегральные схемы (ПЛИС) - для обозначения CPLD.
Таблица 5 - Тенденции развития CPLD и FPGA
|
Параметры |
1985 |
1990 |
1995 |
2000 |
|
Стоимость |
— |
>500$ |
<50$ |
<5$ |
|
Число вентилей |
800 |
5.000 |
50.000 |
500.000 |
|
Число выводов |
64 |
256 |
500 |
1000 |
|
Число транзисторов |
85k |
2M |
6M |
225M |
|
Задержка (min) |
40 нс |
15 нс |
3,5 нс |
1,5 нс |
В настоящее время наблюдается бурное развитие архитектур CPLD и FPGA (каждый год появляются новые поколения этих устройств), сближение их архитектур, приобретение ряда общих свойств, снижения стоимости, повышение быстродействия и функциональной мощности (табл.5). Анализ тенденции развития архитектур программируемой логики позволяет предположить, что в ближайшие пять лет основу элементной базы цифровых систем будут составлять CPLD и FPGA. Преимущество использования программируемой логики в цифровых системах становится особенно очевидным, когда необходимо быстро разработать опытный образец изделия или предполагаются частые корректировки проекта в процессе его разработки.
КЛАССИФИКАЦИЯ PLD
Прежде, чем рассматривать возможные классификации программируемой логики, покажем ее место в общей структуре элементной базы цифровых систем (рис.23). Все выпускаемые в настоящее время интегральные схемы (ИС - Integrated Circuits - ICs) можно разделить на два противоположных класса: стандартные (Standard Products) и специализированные (Application Specific Integrated Circuits - ASIC). Стандартные ИС, как правило, разрабатываются по инициативе производителя и выпускаются большими тиражами. Это микросхемы памяти, микропроцессорные комплекты и др. К ним также можно отнести элементы малой и средней степени интеграции: вентили, регистры, шифраторы, дешифраторы, мультиплексоры и т.д.
Однако, как бы не была широка номенклатура стандартных ИС, последние не могут охватить все потребности разработчиков цифровой техники. Поэтому значительный объем производства составляют специализированные ИС. Их принято делить на три класса: полностью заказные (Full Custom), полузаказные (Semi-Custom) и
программируемые пользователем(Field Programmable).

Рисунок 23 - Общая классификация современной элементной базы цифровых систем
Разработка полностью заказных ИС охватывает полный цикл проектирования. При этом наблюдается наибольшая степень использования площади кристалла и достигаются наилучшие характеристики устройства. Время разработки и подготовка производства полностью заказной ИС может составлять несколько лет, что влечет значительное удорожание изделия (рис.24), компенсируемое большими объемами его производства.
Стоимость __
Полностью заказные микросхемы
Стандартные
ячейки
Вентильные
матрицы
Программируемая логика
Стандартная
логика
Дни Недели Месяцы Годы Время
Рисунок 24 - Зависимость стоимости и времени разработки проекта от элементной базы
Базовые структуры полузаказных ИС производятся массовыми тиражами, а их специализация выполняется на последних этапах изготовления ИС. Это позволяет значительно снизить стоимость устройства. Однако, поскольку разработка полузаказных ИС неизбежно связана с передачей информации с описанием устройства от пользователя производителю, время разработки цифровых устройств (ЦУ) колеблется от нескольких недель до нескольких месяцев. Типичными представителями полузаказных ИС являются микросхемы стандартных ячеек (Standard Cells - SC) и вентильных матриц (Gate Arrays - GA).
Наибольшей оперативностью и гибкостью использования характеризуются ИС, программируемые пользователем. Стоимость и время разработки при этом минимальны. К недостаткам проектирования ЦУ на программируемых пользователем ИС следует отнести не всегда рациональное использование площади кристалла, отсутствие эффективных методов проектирования сложных устройств и др. Однако не смотря на указанные недостатки в настоящее время программируемые пользователем ИС считаются наиболее перспективной элементной базой. Это подтверждается многочисленными статистическими исследованиями и неизменным увеличением объема их производства.
В свою очередь программируемые пользователем ИС можно разделить на микропрограммные ИС и программируемую логику (ПЛИС), в соответствии с двумя основными подходами к проектированию ЦУ: микропрограммным и аппаратным. Первый подход предполагает построение ЦУ на базе некоторого универсального элемента (микропроцессора, микрокомпьютера, микроконтроллера и др.), который специализируется загружаемой в ОЗУ или зашиваемой в ППЗУ программой (микропрограммой). Недостатком такого подхода является невысокая скорость работы устройства, однако последнее может быть легко перенастроено на другой алгоритм работы путем замены программы в ОЗУ или в ППЗУ.
Характерной особенностью ПЛИС является возможность их настройки на заданный алгоритм функционирования путем изменения своей внутренней структуры. Проектирование ЦУ на основе ПЛИС заключается в определении настройки по заданным спецификациям и программировании микросхемы на специальном оборудовании, называемом программатором (programmer). Построенные на основе ПЛИС устройства отличает прежде всего высокая скорость работы, низкая стоимости и малые сроки проектирования. Первые промышленные ПЛИС характеризовались однократностью настройки, которая осуществлялась путем пережигания плавких перемычек (fuse-link). Однако с появлением перепрограммируемых ПЛИС с электрическим и ультрафиолетовым стиранием этот недостаток устраняется и по способу своего использования они ничем не уступают микропрограммным ИС.
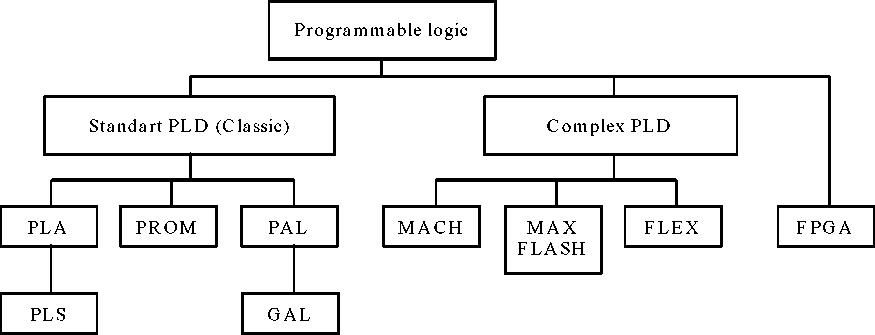
Рисунок 25 - Классификация PLD по структурной организации
В общем случае строгой границы между микропрограммными и логическими ИС нет, свидетельством чего могут служить программируемые пользователем контроллеры (Field Programmable Controller - FPC).
В настоящее время ПЛИС принято делить на три (рис. 25) больших класса: стандартные PLD (Standart PLD - SPLD) или классические PLD (Classic PLD), сложные PLD (Complex PLD - CPLD) и программируемые пользователем вентильные матрицы (Field Programmable Gate Array - FPGA).
Структуру большинства стандартных PLD условно можно представить в виде совокупности двух матриц взаимнортогональных проводников: матрицы И и матрицы ИЛИ. Входные сигналы обычно поступают на парафазные входы матрицы И, которая на ортогональных шинах позволяет реализовать любые конъюнкции входных переменных. Выходы матрицы И соединены со входами матрицы ИЛИ, которая на выходах реализует дизъюнкции поступающих сигналов. Совокупность выходных шин матрицы И и входных шин матрицы ИЛИ образует множество промежуточных шин PLD (product terms).
В зависимости от того, какая матрица программируется, матрица И или матрица ИЛИ, SPLD принято делить на три класса: программируемые логические матрицы (ПЛМ - Prgrammable Logic Arrays - PLAs), программируемые постоянные запоминающие устройства (ППЗУ - Programmable Read Only Memory - PROM) и программируемые матрицы логики (ПМЛ - Programmable Array Logics - PALs). В PLA (рис.26) программируются обе матрицы: матрица И и матрица ИЛИ. В PROM (рис.27) матрица И постоянно настроена на функции полного дешифратора. В структуре PAL (рис.28), наоборот, матрица ИЛИ имеет фиксированную настройку, а программируется только матрица И.

Рисунок 26 - Структура PLA
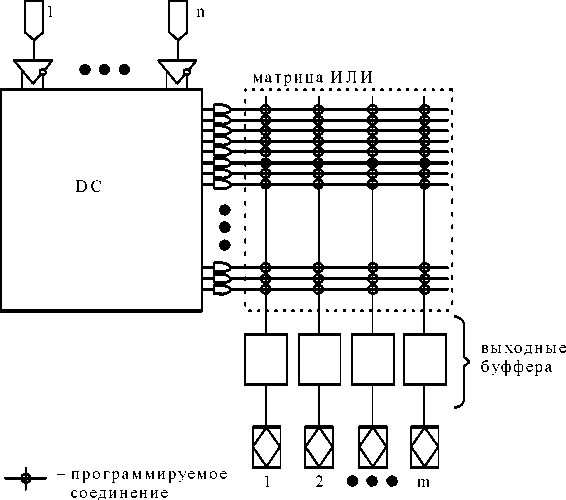
Рисунок 27- Структура PROM
У У
м ••• м
матрица ИЛИ
i Н ►
<1 IHI
1Н>
• • •
• • •
< И I 1 И I 1 И ►
JHt
< н У
<М1 IMI О-G'
(Ml
/А /Ч • • • /Ч
матрица И
МЯ
МЯ
МЯ
МЯ
выходные
буффера
(макро
ячейки)
с.
|
п |
|
п |
|
п |
|
п |
|
V |
|
V |
|
у |
|
V |
|
1 |
2 |
• • • |
m | |||
обратные связи
фиксированное соединение
^ программируемое соединение
Рисунок 28 - Структура PAL
Безусловно, приведенная классификация не охватывает всего разнообразия SPLD. Например, структуру, очень напоминающую PLA, имеют программируемые логические секвенсоры (Programmable Logic Sequencers - PLSs), и обобщенные матрицы логики (Generig Array Logics - GAL) подобны PAL.
Сложными PLD принято называть микросхемы высокой степени интеграции, структура которых представляет собой совокупность нескольких PAL, объединяемых программируемыми межсоединениями (рис.29). Многими фирмами выпускаются различные структуры CPLD. Например, фирма Advanced Micro Devices (AMD) свои CPLD назвала КМОП-макроматрицы высокой плотности (Macro Array CMOS High-density - MACH). Фирма Altera выпускает несколько видов CPLD: многократные матричные таблицы (Multiple Array Matrix - MAX) и FLASH-устройства, названные по способу перепрограммирования настраиваемых элементов.
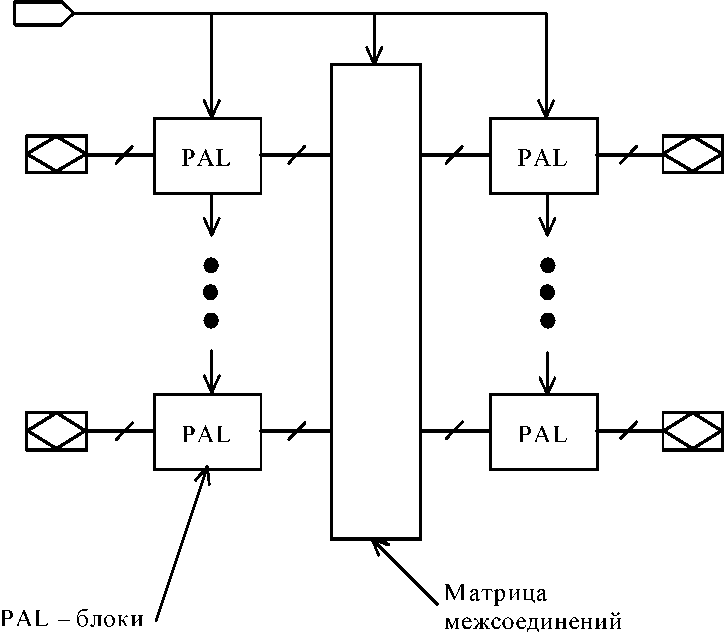
Рисунок 29 - Обобщенная структура CPLD
Дальнейшее развитие структура сложных PLD получила в микросхемах фирмы Altera, названных матрицами элементов гибкой логики (Flexible Logic Element MatriX - FLEX), обобщенная структура которых показана на рис.30. Здесь отсутствует привычная PAL-структура, а имеются блоки логических элементов, объединяемые в LAB-модули по 8 элементов в каждом. Трассировка соединений между LAB-модулями осуществляется с помощью программируемых каналов межсоединений.
Фактически структура FLEX-устройств очень напоминает структуру FPGA, выпускаемых фирмой Xilinx (рис.30). Основу FPGA составляет матрица логических элементов, между которыми располагается поле межсоединений. По краям кристалла находятся блоки ввода-вывода.
Все PLD можно также классифицировать по типу настраиваемого элемента (рис.31):
статическое ОЗУ (SRAM) - FPGA, FLEX, FLASH;
электрически стираемое программируемое ПЗУ (EEPROM) - MACH, MAX7000, MAX9000, SPLD;
перепрограммируемое ПЗУ с ультрафиолетовым стиранием (EPROM) - MAX5000, SPLD.
Число настроек элементов первого класса обычно не ограничивается. Для второго и третьего классов число перезаписей данных настройки обычно ограничивается значением 100 - 1000 раз. Электрически стираемые элементы автоматически стираются при каждом новом программировании. Под EPROM обычно понимают ПЗУ, стираемое ультрафиолетовым излучением. Поэтому перепрограммирование микросхем третьего класса связано с необходимостью выполнения операции ультрафиолетового стирания, которая длиться около часа.
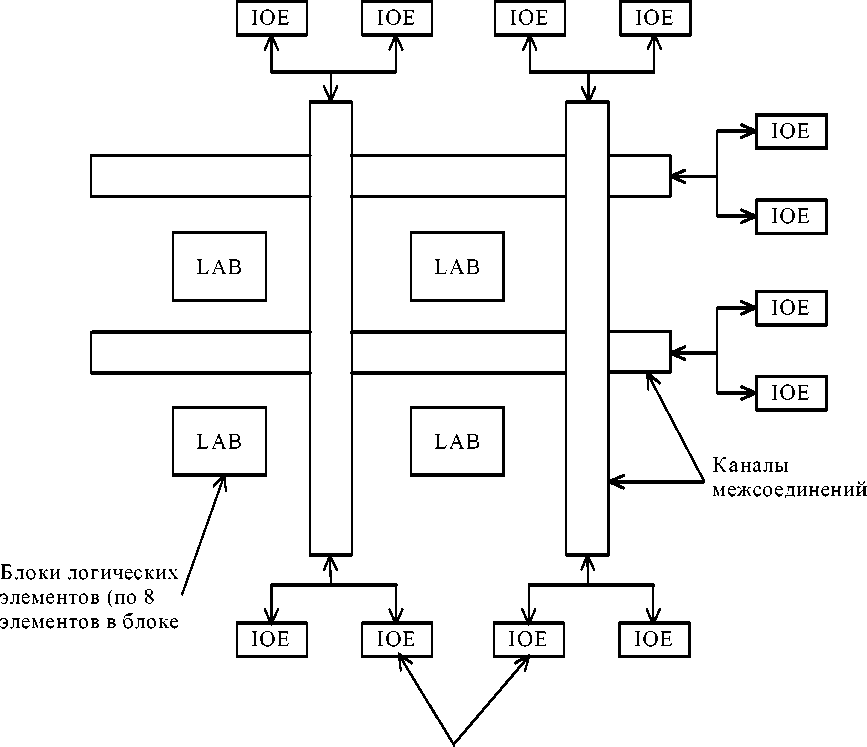
Элементы
ввода-вывода
Рисунок 30 - Обобщенная структура CPLD гибкой логики
Блоки

Рисунок 31 - Обобщенная структура FPGA XC2000, XC3000, XC4000
По количеству перепрограммирований PLD можно также разделить на многократно программируемые и однократно программируемые (One Time Programmable - OTP) (рис.32). Большинство PLD (как однократно, так и многократно настраиваемые) программируются самим пользователем во время эксплуатации (field). Однако, если проект тщательно отлажен и изделие производится массовыми тиражами, в нем могут применяться масочно программируемые PLD, настройка которых выполняется при их изготовлении.
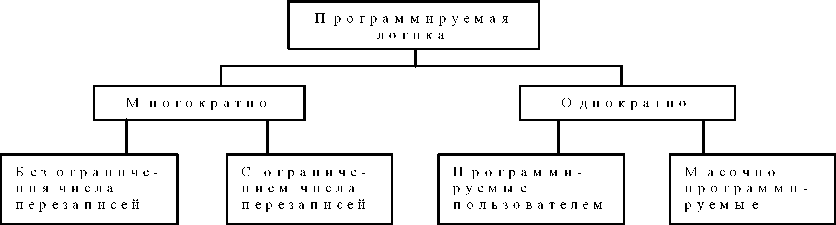
Рисунок 32 - Классификация программируемой логики по способу программирования

все SPLD, MAX FPGA
MACH FLASH
FLEX
Рисунок 33 - Классификация программируемой логики по времени прохождения сигнала
(задержки) с любого входа на любой выход
Еще одним важным критерием классификации PLD является предсказуемость задержки прохождения сигнала со входа на выход устройства (рис.33). Для всех SPLD и MACH-устройств задержка прохождения сигнала с любого входа на любой выход всегда постоянна. Поэтому при проектировании на этих устройствах можно не выполнять временное моделирование сигналов. Для MAX, FLASH и FLEX-устройств задержка переменная, но легко вычисляемая. Для FPGA задержка полностью зависит от пути, по которому проходит сигнал со входа на выход. При изменении трассировки межсоединений изменяются и задержки сигналов.
CPLD можно также разделять на устройства, требующие дополнительного оборудования для своего функционирования (FPGA, FLEX), и не требующие вспомогательного оборудования (все остальные CPLD и SPLD). Дополнительные устройства необходимы для выполнения начальной инициализации CPLD, настраиваемыми элементами которых являются статические ОЗУ. В качестве таких устройств могут выступать ОЗУ, ПЗУ, микроконтроллер, персональный компьютер и др.
В данном пункте были рассмотрены только основные способы классификации программируемой логики. Этот процесс можно было бы продолжить дальше, разделяя PLD на классы по степени обладания теми или иными свойствами. Но такая классификация мало полезна, поскольку свойств PLD достаточно много и часто микросхемы в пределах одного поколения и даже одной серии обладают различными свойствами. Поэтому ограничимся рассмотрением наиболее общих свойств, которые присущи различным PLD.
ОСНОВНЫЕ СВОЙСТВА PLD
PLD обладают рядом характерных особенностей, благодаря которым они получили такое широкое распространение и на сегодняшний день считаются наиболее перспективной элементной базой цифровых систем. Ограничимся простым перечислением основных свойств современных PLD, объединив их в следующие группы:
общие свойства PLD;
функциональные свойства PLD;
системные свойства PLD, имеющие значение при использовании PLD в составе цифровых систем;
свойства проектирования, проявляющиеся при разработке проекта.
Безусловно, абсолютно идеальной элементной базы не бывает, поэтому здесь
отмечаются и недостатки PLD.
Общие свойства PLD
Практически всем современным PLD присущи следующие общие свойства:
Низкая стоимость. Благодаря большим объемам производства, что обусловлено высоким спросом, стоимость PLD начинает приближаться к стоимости стандартных устройств.
Высокое быстродействие. Применение передовых технологий привело к снижению задержки прохождения сигнала через PLD до 3.5 ns и до 1 ns на один логический элемент для FPGA, что позволяет достигать частоты функционирования устройств до 250 MHz. Практически каждая микросхема PLD имеет несколько реализаций с градацией по быстродействию. Поэтому если высокое быстродействие не требуется, пользователь с целью экономии средств всегда может выбрать подходящую микросхему.
Высокая степень интеграции. PLD имеют достаточно регулярную структуру, что позволяет применять 0.5-микронную технологию и достигать до 100000 вентилей на кристалл, приближая их по степени интеграции к микросхемам памяти.
Функциональная мощность. Стандартные PLD могут заменять десятки корпусов “жесткой” логики, а сложные PLD - сотни корпусов “жесткой” логики, что позволяет реализовать на одной CPLD всю или некоторую часть цифровой системы, например, сопроцессор.
Универсальность. На одном и том же PLD можно строить различные функциональные узлы: комбинационные, регистровые, синхронные, асинхронные, арифметические и др.
Многократность программирования. В зависимости от технологии производства и типа настраиваемого элемента число перепрограммирований PLD может не ограничиваться или составлять 100 - 1000 раз. В то же время промышленностью выпускаются дешевые однократно настраиваемые и масочно программируемые PLD.
Высокий процент выхода годных изделий. Благодаря передовым технологиям и хорошей тестируемости PLD отличаются исключительной надежностью, что для большинства PLD выражается в 100% выходе годных изделий после программирования.
Защита информации от считывания. Все современные PLD имеют бит защиты, установка которого препятствует считыванию настройки PLD. Бит защиты сбрасывается только при перезаписи всей информации о настройке PLD.
Сброс регистров при включении питания. Это свойство позволяет однозначно определять начальное состояние скрытых элементов памяти при синтезе последовательностных устройств и отказаться от процедуры инициализации в начале работы устройства.
Предзагрузка регистров. В дополнение к свойству 9 PLD допускают предварительную загрузку внутренних регистров определенными значениями. Это позволяет осуществить процедуру инициализации последовательностных устройств путем перевода их в некоторое состояние. Однако на практике данное свойство чаще используется для тестирования PLD и проверки поведения устройства в запрещенных (illegal) состояниях с помощью программатора в процессе настройки PLD.
Совместимость по входам и выходам с TTL-логикой. Большинство PLD, выполненных по технологиям, отличным от TTL, остаются совместимыми с TTL-логикой по коэффициентам расширения входов и выходов, по уровням напряжений и др.
Разнообразие корпусов PLD. Одна и та же микросхема PLD может быть упакована в различные типы корпусов: штыревые - DIP, планарные - SOIC, PGA, PQFP, TQFP, J-lead и др. Следует, однако, заметить, что параметры одной и той же микросхемы в разных корпусах могут различаться (число логических входов и выходов, число внутренних регистров и т. д.).
Функциональные свойства PLD
Отметим некоторые наиболее общие функциональные свойства PLD, которые, в основном, определяются возможностями программируемых выходных макроячеек.
Все входы матрицы И являются парафазными. Сигналы, поступающие на вход матрицы И, как с внешних выводов, так и по цепям обратных связей, всегда представляются в прямом и инверсном значении. Это позволяет не заботиться о формировании сигнала определенной полярности.
Выходные макроячейки имеют цепи обратной связи с матрицей И. Практически все выходные макроячейки PLD имеют цепи обратной связи с матрицей И, причем некоторые PLD имеют по две обратные связи. Это позволяет, с одной стороны, более эффективно использовать возможности макроячеек (например, для реализации внутренней логики и для приема входных сигналов), а, с другой стороны, широко применять факторизационные методы синтеза.
PLD позволяют реализовать конъюнкции большого числа переменных. Для SPLD число переменных в конъюнкции ограничивается числом входов в матрицу И (даже для простейших SPLD это значение равняется 16). Некоторые CPLD для этой цели содержат специальные цепи каскадирования. После применения теоремы деМоргана это же свойство может применяться и для реализации дизъюнкции большого числа переменных.
Все выходы современных PLD имеют управляемый буфер с тремя состояниями. Этот буфер может использоваться как по своему прямому назначению - для отключения от внешней шины, так и для расширения возможностей PLD - использование двунаправленного вывода в качестве входа. Кроме того, благодаря тому, что управление буфером также программируется, каждый двунаправленный вывод PLD в один момент времени может использоваться в качестве входа, а в другой - в качестве выхода.
Программируемая полярность выходов. Большинство SPLD, а CPLD - все, позволяют программировать полярность каждого выхода: выходной сигнал может формироваться в прямой или инверсной логике.
Программирование регистрового или комбинационного выхода. Для большинства SPLD и всех CPLD выходная макроячейка содержит триггер для образования регистрового выхода (например, для синхронизации формируемых выходных сигналов). При необходимости триггер может обходиться для реализации комбинационного выхода.
Программирование типа запоминающего элемента. В случае регистрового выхода по умолчанию принимается D-триггер в качестве запоминающего элемента. Однако многие PLD позволяют программировать тип запоминающего элемента: D, T, JK, SR триггер или защелку.
Наличие отдельных входов для разрешения выходов OE и сигналов глобальной синхронизации триггеров CLK.
Перечисляемые ниже свойства присущи большинству, но не всем PLD.
Наличие в выходной макроячейке вентиля “Исключающее ИЛИ”. Для реализации определенных функций полезным является наличие в выходной макроячейке вентиля “Исключающее ИЛИ”.
Асинхронное управление каждым триггером. Для построения разнообразных асинхронных устройств имеется возможность программировать асинхронные сигналы установки (preset), сброса (reset) и синхронизации (clock) каждого триггера.
Асинхронное управление третьим состоянием каждого выхода.
Изменяемое число промежуточных шин (product terms), подключаемых к одной макроячейке.
Буферизация входных сигналов с помощью регистров или защелок.
Наличие нескольких входов для сигналов синхронизации и разрешения выходов.
Возможность выбора для каждого запоминающего элемента (триггера или защелки) сигнала синхронизации от любого внешнего вывода.
Возможность выбора для каждого выхода сигнала разрешения выхода от любого внешнего вывода.
Отметим некоторые специфические свойства отдельных CPLD.
Наличие схем быстрого переноса для эффективной реализации сумматоров и счетчиков (FLEX).
Наличие схем каскадирования для эффективной реализации логических функций большого числа переменных (FLEX).
Наличие арифметическо-логического устройства (АЛУ - ALU) в каждой макроячейке (XC7200).
Наличие внутреннего ОЗУ (FLEX, FLASH, FPGA).
Возможность подсоединения большого числа промежуточных шин матрицы И к одной макроячейке (MAX).
Наличие внутренней трехстабильной шины (XC4000).
Программное управление скоростью формирования выходного сигнала (MAX,
FLEX).
Следует, однако, отметить, что, с одной стороны, перечисленные свойства не охватывают всех функциональных возможностей современных PLD, а, с другой стороны, одновременно всеми свойствами не обладает ни одна PLD. Поэтому при рассмотрении вопроса о возможности применения некоторой микросхемы следует внимательно изучить ее характерные особенности.
Системные свойства PLD
Остановимся на рассмотрении свойств PLD, которые имеют важное значение при их использовании в составе цифровой системы.
Наличие бита Turbo. Бит Turbo устанавливается во время программирования. При значении бита Turbo ON обеспечивается максимальное быстродействие PLD при номинальной потребляемой мощности. При значении бита Turbo OFF обеспечивается минимальная потребляемая мощность PLD при номинальном быстродействии.
Режим пониженного энергопотребления. Некоторые PLD имеют независимый от бита Turbo режим пониженного энергопотребления. При программировании этого режима обеспечивается исключительно низкий ток потребления на низких частотах функционирования устройства. Режим пониженного энергопотребления может программироваться для всего устройства, для отдельных PAL-блоков и даже для каждой отдельной макроячейки.
Наличие нескольких бит защиты. Отдельные PLD не ограничиваются одним битом защиты от считывания информации о настройке, а имеют несколько таких бит для повышения степени защиты информации.
Возможность перенастройки во время функционирования системы. CPLD, в которых в качестве настраиваемых элементов используются SRAM, программируются при каждом включении питания. Время программирования составляет менее, чем 100 ms. При необходимости перенастройку CPLD можно осуществлять и во время функционирования всей системы, что позволяет строить различные адаптивные системы.
5.0- или 3.3- вольтное функционирование. Некоторые CPLD могут настраиваться на 5.0 или 3.3 вольтное значение входных и выходных сигналов. Отдельные CPLD допускают подобную настройку для каждого вывода.
Поддержка стандарта JTAG (Joint Test Action Group). CPLD, поддерживающие JTAG-стандарт, позволяют выполнять тестирование методом граничного сканирования (Boundary-Scan Testing - BST) в соответствии с требованиями IEEE Std. 1149.1-1990, перенастройку в схеме (In-Circuit Reconfigurability - ICR) и программирование в системе (In-System Programmability - ISP).
Поддержка стандарта PCI (Peripheral Component Interconnect - PCI).
Программирование режима пониженного “шума” формируемых выходных сигналов. При включении данного режима несколько снижается быстродействие устройства, однако формируемые выходные сигналы отличаются исключительной “чистотой”, что позволяет не применять специальные системные средства для понижения шумов формируемых сигналов. Отдельные CPLD позволяют программировать этот режим для каждого вывода.
Свойства проектирования
Одной из главных причин широкого применения PLD является удобство их применения. Это стало возможным благодаря ряду специфических свойств.
Малое время проектирования. Например, после разработки проекта средней сложности на концептуальном уровне, время ввода проекта может составить менее одного часа, синтез - 5-30 минут, моделирование - около двух часов и программирование - 2 минуты. В результате общее время разработки проекта на PLD составляет около 3.5 часов.
Наличие развитых программных и аппаратных средств проектирования на основе PLD. Имеющиеся программные средства проектирования удовлетворяют очень широкому кругу пользователей. Они могут быть дорогими (с широкими возможностями) и дешевыми (с ограниченными возможностями); ориентированными для использования на рабочих станциях и на простейших персональных компьютерах; предоставляющие широкий перечень решаемых проектных задач и решающие только отдельные специфические задачи и т.д.
Аналогично производителями предлагается широкий набор аппаратных средств для проектирования на основе PLD: от простейших пользовательских программаторов, ориентированных на ограниченную номенклатуру PLD одной фирмы, до универсальных высокопроизводительных промышленных программирующих систем, позволяющих выполнять операцию настройки PLD без участия человека.
Простота разработки проекта на основе PLD. Для разработки проекта на основе PLD достаточно описать его функционирование на одном из входных языков используемого программного средства, выполнить автоматизированный синтез (компиляцию), произвести функциональное и/или временное моделирование и настроить PLD с помощью программатора.
Простота внесения в проект изменений. Изменения в проект на основе PLD вносятся исключительно просто: для этого достаточно перепрограммировать PLD.
Упрощается этап конструкторского проектирования. Это достигается за счет:
уменьшения числа корпусов системы;
уменьшения числа внешних соединений;
упрощения разводки схемы, поскольку большинство выводов PLD можно считать логически эквивалентными между собой.
Повышается надежность системы. Кроме уменьшения числа корпусов и внешних соединений, повышению надежности проектов способствует улучшенное функциональное и временное моделирование PLD. Более того, PLD, поддерживающие JTAG-стандарт, могут включаться в общую цепочку проекта для тестирования элементов схемы по JTAG- стандарту.
Упрощается отладка проекта. В процессе проектирования каждая отдельная микросхема PLD может тестироваться как на логическом уровне с помощью программного обеспечения, так и на физическом уровне с помощью программатора. Некоторые программаторы позволяют тестировать PLD в реальном масштабе времени, т.е. на рабочей частоте устройства.
Отладка всего проекта в целом упрощается за счет поддержки большинством CPLD JTAG-стандарта, причем в цепочку граничного сканирования могут включаться произвольные элементы (не обязательно PLD).
Многообразие способов ввода проекта. Современные программные средства проектирования на основе PLD предлагают следующие способы ввода проекта:
текстовый (заданием таблицы истинности, описанием функционирования конечного автомата, на языке VHDL и др.)
схемный;
в виде временной диаграммы;
Кроме того, в одном проекте допускается сочетание разнообразных способов ввода, возможно также иерархическое описание проекта.
Многообразие методов синтеза. В современных программных средствах проектирования на основе PLD реализовано большое количество различных методов синтеза. Это методы минимизации булевых функций, библиотеки параметризированных функциональных блоков, а также методы декомпозиции сложных проектов на отдельные PAL-блоки.
Многообразие методов моделирования и тестирования. Реализованные в программных средствах методы моделирования позволяют выполнять функциональное и временное моделирование; выявление в CPLD путей сигналов, критичных к скорости формирования; автоматическое формирование тестовых последовательностей для тестирования в JTAG-стандарте и др.
Разнообразие способов программирования. PLD могут настраиваться и тестироваться с помощью программатора, непосредственно на плате во время инициализации системы, перенастраиваться в процессе функционирования системы.
Недостатки PLD
Отметим некоторые недостатки и ограничения использования, характерные для современных PLD.
SPLD имеют относительно небольшое число промежуточных шин, связанных с одним выходом (макроячейкой).
PLD имеют ограниченное время хранения записанной информации (настройки). Обычно гарантированное время сохранения настройки составляет 20 лет.
Невозможность использования в средах с повышенным излучением (радиационным, электромагнитным, ультрафиолетовым и др.).
ВЫБОР АРХИТЕКТУРЫ PLD
В настоящее время многими фирмами (Altera, AMD, Atmel, Intel, Texas Instruments, Xilinx и др.) выпускается большое разнообразие PLD. Поэтому выбор подходящей архитектуры является далеко не тривиальной задачей. Эта проблема становится особенно важной, когда приходится выбирать PLD в качестве элементной базы длительного пользования (на несколько лет). Здесь приходится учитывать большое разнообразие различных факторов, зачастую противоречивых. В данном параграфе предпринята попытка определить основные критерии, которыми следует руководствоваться при выборе подходящей архитектуры PLD.
В технической документации практически всех производителей PLD описываются методики выбора микросхемы с требуемой архитектурой. К сожалению, все эти методики касаются изделий только одной конкретной фирмы, а на рынке, как правило, имеются PLD нескольких различных фирм. С другой стороны, сравнение общих параметров PLD различных производителей, таких как число выводов, регистров, быстродействие, стоимость и др., обычно не позволяет сделать определенный выбор, поскольку эти параметры для большинства микросхем одинаковы. Поэтому выбор элементной базы следует делать исходя из более специфичных особенностей проекта и возможностей PLD удовлетворения этим особенностям.
Дело в том, что современные PLD обладают очень широкой гаммой возможностей и значительной функциональной мощностью, поэтому выбор более дорогой и сложной микросхемы, особенно последних поколений, позволяет удовлетворить практически всем требованиям проекта. Но это достигается не путем учета специфики проекта и выбора соответствующей архитектуры PLD, а путем черезмерного задействования ресурсов мощной PLD.
Прежде всего следует отнести проект к одному из следующих классов:
проект реализуется на одной PLD;
проект реализуется совокупностью однотипных PLD;
проект реализуется совокупностью разнотипных PLD;
проект реализуется совокупностью разнотипных PLD с использованием других микросхем.
В первом случае выбор PLD особых проблем не вызывает, главное, чтобы функциональной мощности PLD хватило для реализации всего проекта. Во втором случае главным критерием выбора PLD является минимизация общего числа корпусов схемы и минимизация числа связей между ними. В третьем случае кроме минимизации элементов и числа связей между ними необходимо предусмотреть согласование всех элементов системы между собой по уровням напряжений сигналов, нагрузочных способностей и др. Для этого лучше всего использовать микросхемы одной и той же фирмы, изготовленные по одинаковой технологии. В четвертом случае последнее требование выполнить едва ли возможно, поэтому вопросы согласования элементов между собой выступают на первое место.
Затем для каждой части проекта выбирается архитектура подходящей PLD. Главными критериями здесь являются:
функциональные особенности;
специфические требования;
системные требования;
стоимость.
При определении функциональных особенностей следует отметить следующие моменты:
преимущественная функциональная ориентация схемы (комбинационная или последовательностная, синхронная или асинхронная, арифметическая, функциональный узел, произвольная логика и т. д.);
сложность проекта (число входов, выходов, двунаправленных выводов, внутренних регистров и др.);
сложность реализуемых логических функций (число переменных, число различных элементарных конъюнкций в дизъюнктивной нормальной форме, допустимо ли скобочное представление функции, наличие общих фактор-функций, использование операции “Исключающее ИЛИ” и др.);
типы используемых триггеров;
необходимость буферизация входных и выходных сигналов;
требования к синхронизации регистров (число сигналов синхронизации, их характер);
требования к временной задержке формируемых выходных сигналов (постоянная, переменная, допустимая величина разброса и др.);
требования по быстродействию (минимальная величина задержки и максимальная частота функционирования).
Определение специфических требований заключается в ответе на следующие вопросы:
необходимы схемы быстрого переноса (для реализации сумматоров и счетчиков);
необходимы схемы каскадирования (для реализации функций большого числа переменных);
использование функциональных элементов типа памяти, АЛУ и др.
При определении системных требований указываются системные свойства, которым должна удовлетворять PLD, главными из которых являются:
уровни напряжений сигналов (5 или 3.3 вольта);
возможность перенастройки во время функционирования;
способ тестирования PLD и всего проекта в целом;
наличие специальных системных средств защиты от шумов (в случае их отсутствия и опасности появления шумов следует использовать возможности PLD по формированию “чистых” сигналов за счет потери быстродействия);
необходимость поддержки JTAG и PCI стандартов;
требования к потребляемой мощности и др.
При определении стоимости следует учитывать следующие моменты:
стоимость PLD;
для PLD, настраиваемыми элементами которых являются SRAM, стоимость дополнительного оборудования, устанавливаемого на плату (ПЗУ, ОЗУ, микропроцессор, микроконтроллер, разъем и др.);
стоимость программного и аппаратного обеспечения, необходимого для разработки проекта на данном типе PLD;
стоимость услуг сторонних организаций (проектирующих центров) в случае обращения к ним для разработки проекта;
стоимость сертификации и сопровождения проекта.
Отметим, что перечисленные характеристики частей проекта не охватывают всего разнообразия факторов, необходимость учета которых может возникнуть при выборе архитектуры PLD.
После определения всех или части перечисленных свойств проекта можно приступить к выбору подходящих микросхем PLD. Здесь можно руководствоваться следующими подходами:
все определенные свойства проекта (его части) должны покрываться возможностями PLD;
следует оставлять 20-40% ресурсов PLD для будущих корректировок и развития проекта;
в случае одинаковых функциональных возможностей желательно использовать PLD более поздних поколений (для предотвращения опасности прекращения выпуска микросхем более ранних поколений);
если разные части проекта требуют различных архитектур PLD, следует выбирать микросхемы, обладающие максимальным количеством общих свойств (это предоставляет возможность распределенной реализации частей проекта);
следует отдавать предпочтение CPLD и микросхемам с большей степенью интеграции, поскольку для них характерным является минимальная стоимость одного вентиля и внешнего вывода.
МЕТОДИКА ПРОЕКТИРОВАНИЯ НА ОСНОВЕ PLD
Методика проектирования на основе PLD включает в себя четыре основных последовательно выполняемых этапа:
ввод исходных данных для проектирования;
выполнение синтеза (компиляция) отдельных частей проекта и всего проекта в целом;
моделирование проекта;
программирование и тестирование PLD.
Приведенная методика носит общий характер и в ряде случаев может изменяться и корректироваться. Так, при реализации проекта на CPLD, обязательным этапом синтеза является подгонка (fitting) проекта, т.е. вложение скомпилированного проекта в заданную структуру CPLD.
В общем случае разработка сложных иерархических проектов на PLD ничем не отличается от известных подходов к проектированию цифровых систем. Здесь возможно проектирование как “сверху вниз”, так и “снизу вверх”, использование библиотек стандартных блоков и функциональных узлов, а также заимствование опыта предыдущих разработок.
Разработка проектов на PLD выполняется с помощью программных средств автоматизированного проектирования. Известные пакеты автоматизированного проектирования на PLD (PALASM, CUPL, ABEL) решают только задачи функциональнологического проектирования, а для решения задач конструкторского проектирования, как правило, имеют информационную связь (на уровне файлов) с соответствующими пакетами (OrCAD, P-CAD). С другой стороны, наличие схемного ввода некоторых пакетов (MAX+PLUSII, Synario) позволяет непосредственно вводить проекты, разработанные на элементах “жесткой” логики в системах конструкторского проектирования.
Остановимся более подробно на рассмотрении основных этапов методики проектирования на основе PLD.
Ввод проекта
Ввод проекта заключается в описании одним из способов машинного представления всех частей проекта. Различные пакеты имеют различные способы ввода, но наиболее распространенными являются следующие - текстовый, схемный и в виде временных диаграмм.
Текстовый ввод предполагает описание проекта (части проекта) на некотором исходном языке используемого программного средства в виде текстового файла. Наибольшее распространение получили языки исходного описания пакетов PALASM, CUPL и ABEL, которые с незначительными изменениями повторяются в других пакетах. Текстовый файл исходного описания проекта, как правило, включает заголовок, определение переменных и назначение им соответствующих выводов PLD, а также описание функционирования устройства в виде логических уравнений, алгоритма функционирования, таблицы истинности или конечного автомата. Иногда в исходный файл описания проекта включаются тестовые вектора для моделирования проекта.
Схемный ввод осуществляется с помощью графического редактора используемого программного средства. Для удобства ввода принципиальных схем больших проектов графический редактор, как правило, содержит библиотеки стандартных элементов жесткой логики (например, серии 74XX), а также библиотеку параметризированных функциональных узлов (вентилей, шифраторов, дешифраторов, мультиплексоров, демультиплексоров, триггеров, регистров, счетчиков и т.д.).
Ввод проекта в виде временной диаграммы осуществляется с помощью графического редактора. Вначале определяются переменные (сигналы) проекта, а затем описывается поведение устройства в виде временной диаграммы.
Некоторые пакеты поддерживают ввод проекта на языке VHDL и других языках проектирования (HDL, DDL и др.), но для этого, как правило, необходима дополнительная программа.
Отдельные пакеты также допускают ввод иерархических проектов, причем в одном проекте допускается сочетание разнообразных способов ввода. Сложный иерархический проект не обязательно сразу вводить целиком. Проект можно вводить и компилировать по ветвям дерева иерархии.
Синтез проекта
Автоматизированный синтез простых проектов фактически заключается в компиляции исходного описания проекта во внутреннее представление используемого программного средства (абсолютный файл) и/или JEDEC-файл для настройки PLD. В последующем абсолютный файл используется для моделирования. Многие пакеты также позволяют формировать файлы для связи проекта с другими пакетами функциональнологического и конструкторского проектирования. Задачи оптимизации, решаемые на этом этапе, сводятся к минимизации логических функций, управляющих выходными макроячейками PLD.
Сложности могут возникать при синтезе конечных автоматов из-за недостатка промежуточных шин для реализации функций возбуждения элементов памяти. Поскольку коды состояний задаются пользователем, можно применить специальные методы рационального кодирования внутренних состояний.
Специфические свойства архитектуры PLD предоставляют новые возможности при синтезе комбинационных и последовательностных схем. Важное место среди методов синтеза на PLD цифровых устройств, математической моделью которых является конечный автомат, занимают методы синтеза одноуровневых схем, поскольку они обладают наибольшим быстродействием. Благодаря своей блочной структуре, CPLD оказались удобными для построения сложных иерархических и параллельных устройств. При построении микропроцессорных систем для согласования сигналов между различными микросхемами часто используются простейшие функциональные узлы, такие как инверторы, вентили, триггеры, регистры и др. Совокупность подобных элементов получила название логики склеивания (glue logic). PLD получили очень широкое распространение при реализации логики склеивания, причем в качестве элементов этой логики могут выступать простые функциональные узлы как комбинационного, так и регистрового типа.
Синтез сложных проектов на CPLD дополнительно требует специальной программы, называемой упаковщиком (fitter), которая выполняет “подгонку” проекта (fitting) в заданную структуру CPLD. При синтезе сложных проектов следует планировать 20-40% использования ресурсов CPLD для возможности корректировок и эффективной работы упаковщика. Проект рекомендуется создавать путем выполнения ряда итераций: вначале реализуется ядро проекта, а затем добавляется остальная логика до полного проекта. При этом обеспечивается лучшее решение по упаковке проекта и наиболее рациональное назначение сигналов внешним выводам.
Большие проекты могут разбиваться на отдельные PAL-блоки как автоматически, так и указываться пользователем с помощью директив. Пользователем также могут указываться назначение сигналов отдельным выводам. Если после указаний пользователя проект не может быть упакован в заданное устройство, программа запрашивает возможность альтернативных решений (компромиссов): переназначение выводов,
оптимизацию типов триггеров, повторное прохождение сигналов через устройство и др.
Рекомендуется первоначальную упаковку проекта выполнять предоставлением программе наибольших возможностей, а затем конкретизировать назначение выводов. После получения некоторого решения проект может быть оптимизирован для наиболее рационального использования ресурсов CPLD с целью их освобождения для реализации другой логики.
Моделирование проекта
Моделирование проекта на PLD может осуществляться как на логическом, так и на физическом уровне. При моделировании на логическом уровне работоспособность проекта проверяется на основании математических моделей PLD и выполняется программным обеспечением без участия конкретной микросхемы. На физическим уровне проверяется реальное функционирование проекта с использованием уже запрограммированных PLD.
Логическое моделирование делится на функциональное и временное (временной анализ). Функциональное моделирование выполняется программным обеспечением на основании тестовых векторов входных и выходных сигналов проекта. Тестовые вектора могут задаваться в файле исходного описания проекта или находиться в отдельном файле. Некоторые пакеты допускают задание тестовых векторов в виде временных диаграмм. При логическом моделировании возможно решение следующих задач:
определение выходных значений по заданным входным воздействиям;
сравнение вычисленных выходных значений с эталонными;
моделирование неисправностей устройства.
Временное моделирование выполняется на временных моделях PLD и заключается в определении времени прохождения и формирования различных сигналов. Результаты временного моделирования могут также представляться в виде временных диаграмм.
Кроме того с помощью отдельной программой, называемой временным анализатором, производится анализ, позволяющий обнаружить пути сигналов, критичные по скорости. Оптимизация путей распространения сигналов позволяет повысить быстродействие всего проекта.
Моделирование проекта на физическом уровне (тестирование на программаторе) осуществляется после настройки PLD. Для этого в файл, содержащий информацию о настройке PLD и управляющий работой программатора, добавляется информация для тестирования устройства. Последняя может быть получена на основании тестовых векторов и результатов функционального моделирования. Причем здесь возможно моделирование в реальном масштабе времени, в том числе на предельной частоте работы PLD.
CPLD, поддерживающие JTAG-стандарт, могут тестироваться непосредственно на плате методом граничного сканирования. Для этого программным обеспечением на основании тестовых векторов создаются тестовые последовательности в JTAG-стандарте. При этом допускается тестирование
одного CPLD;
цепочки CPLD;
цепочки всех устройств проекта (в том числе и CPLD), поддерживающих JTAG-стандарт.
Программирование PLD
Программирование PLD заключается в его настройке на заданный алгоритм функционирования. Стандартные PLD программируются с помощью программаторов. Технологии программирования (последовательности подаваемых сигналов, уровни напряжений и др.) могут существенно отличаться даже для одних и тех же PLD, но производимых различными фирмами. Поэтому важное значение имеет использование только сертифицированных программаторов, рекомендуемых фирмами-изготовителями PLD.
CPLD, в которых настраиваемым элементом является SRAM, конфигурируются всякий раз, при включении питания. Процесс конфигурирования состоит из двух частей: загрузки данных и обнуления всех регистров. Данные о настройке CPLD могут поступать от управляющего компьютера, микропроцессора, ПЗУ, ОЗУ, других CPLD. Форма передаваемых данных может быть как последовательная, так и параллельная. Имеется также ряд режимов программирования, когда CPLD выступает в качестве активного устройства (само управляет процессом загрузки данных), и в качестве пассивного устройства (другое устройство управляет процессом загрузки данных).
Как правило, фирмы-изготовители CPLD выпускают специализированные ППЗУ для программирования CPLD. В такие ППЗУ с помощью программатора записывается информация о настройке CPLD и они устанавливаются на плате вместе с CPLD. С целью минимизации площади платы для передачи данных между ППЗУ и CPLD используется последовательный интерфейс, а CPLD выступает в качестве активного устройства.
Некоторые CPLD, поддерживающие JTAG-стандарт, могут программироваться на плате, используя сигналы JTAG-стандарта. Для этого на границе платы устанавливается специальный разъем для передачи сигналов управления процессом программирования. Несколько CPLD на одной плате могут объединяться в цепочки, но в каждый момент времени допускается программирование только одного CPLD.
ОБЛАСТИ ПРИМЕНЕНИЯ PLD
PLD хорошо себя зарекомендовали в качестве универсальной элементной базы. Рассмотрим конкретные примеры использования PLD, приводимые в литературе фирмами-изготовителями PLD и производителями программного обеспечения для проектирования на основе PLD.
Таблица 6 - Стандартные функциональные узлы, реализуемые на PLD
|
Комбинационные |
Последовательностные |
|
Легко реализуемые на PLD | |
|
Шифраторы |
Регистры |
|
Дешифраторы |
Сдвиговые регистры |
|
Мультиплексоры |
Двоичные счетчики |
|
Демультиплексоры |
Счетчики по модулю |
|
Компараторы A=B |
Счетчики Грея |
|
Сумматоры |
Счетчики Джонсона |
|
Инкременторы |
Асинхронные счетчики |
|
Декременторы |
Делители частоты |
|
Преобразователи кодов |
Полиномиальные счетчики |
|
Приоритетные шифраторы |
Двоичные счетчики |
|
Требующие каскадной реализации на CPLD | |
|
Мультиплексоры |
Счетчики по модулю |
|
Демультиплексоры |
Счетчики Грея |
|
Компараторы |
Счетчики Джонсона |
|
Сумматоры с параллельным переносом |
|
|
Преобразователи кода Грея в двоичный код |
|
На классических PLD можно легко реализовать ряд стандартных комбинационных и последовательностных узлов цифровых систем (табл.6). Отдельные функциональные узлы большой размерности требуют каскадной реализации на стандартных PLD или на сложной PLD.
Необходимость построения стандартных функциональных узлов на PLD может возникать по следующим причинам:
отсутствие необходимой номенклатуры;
нестандартные размеры узла;
большая размерность узла;
необходимость специального управления узлом;
требования схемотехники по согласованию напряжений уровней сигналов, временных задержек, улучшения помехозащищенности и др.;
улучшение временных параметров узла: постоянная задержка с любого входа на любой выход ;
необходимость реализации нескольких разнотипных узлов в одном корпусе;
необходимость тестирования по JTAG-стандарту;
минимизация числа корпусов схемы и др.
Особенно часто PLD используются при построении специализированных микропроцессорных систем:
для управления микропроцессорной системой;
для управления памятью;
для реализации отдельных функциональных узлов МПС;
для реализации шинного интерфейса;
в видеосистемах;
в других приложения микропроцессорных систем;
а также в качестве “логики склеивания” (glue logic), например, для реализации интерфейса микропроцессора с другими устройствами.
Кроме того, PLD широко используется в:
системах цифровой обработке сигналов;
системах телекоммуникации;
а также самых разнообразных приложениях автоматики и электроники.
ОСНОВНЫЕ СТРУКТУРЫ CPLD
Все архитектуры рассматриваемых CPLD можно представить в виде пяти структур, приведенных на рис.34.
Структура на рис.34,а представляет собой “классическую” сложную CPLD: совокупность PAL-блоков (Programmable Array Logic), объединяемых матрицей переключений SM. Основные функциональные преобразования выполняются в PAL- блоках, а матрица переключений служит для передачи сигналов между PAL-блоками. Каждый PAL-блок имеет свое множество двунаправленных выводов (на рис. 34 не показаны), по которым поступают обрабатываемые сигналы. Кроме того, имеются специализированные (dedicated) входы, которые связаны с матрицей переключений и со всеми PAL-блоками. Эти входы обычно используются для глобальных сигналов установки, сброса и синхронизации триггеров, а также для глобальных сигналов разрешения выходов.
При возрастании числа PAL-блоков трудно обеспечить необходимые соединения между ними без значительного увеличения размеров матрицы переключений. В структуре на рис.34,б матрица переключений представлена в виде глобальной шины GI и нескольких локальных шин LI (семейство MACH5). Здесь все PAL-блоки объединены в сегменты по четыре PAL-блока в каждом сегменте. Локальные шины обеспечивают соединения между PAL-блоками одного сегмента, а глобальная шина - между сегментами PAL-блоков.
Для повышения гибкости в назначении внутренней логики внешним выводам фирмой Altera предложена структура, изображенная на рис.34,в. Здесь основные функциональные блоки организованы в виде матрицы логических элементов и названы LAB-модулями. Между строками и столбцами LAB-модулей расположены горизонтальные и вертикальные каналы трассировки. LAB-модули связаны с горизонтальными каналами, но имеется возможность передачи сигналов с горизонтальных каналов на вертикальные и наоборот. Элементы ввода-вывода подсоединяются к концам как горизонтальных, так и вертикальных каналов.
В структуре на рис.34,г (семейство XC9500) все обрабатываемые сигналы дважды проходят через матрицу переключений SM, при вводе и при выводе, для обеспечения 100% соединений между PAL-блоками и блоками ввода-вывода (IOB). Однако данная структура не гарантирует постоянной задержку прохождения сигнала с любого входа на
любой выход, поскольку задержка будет зависеть от способа настройки соответствующей макроячейки.

«67^»
PAL
~г
••• I
JtL
PAL
т
I •••
_Y_
LI
LI
GI
|
|
|
PAL |
|
|
| |
|
LI |
|
V |
|
|
|
PAL |
|
|
|
<7^
PAL
T
<7*>
^22
|
PAL |
|
|
|
|
| |
|
1 1 V |
|
LI |
|
PAL |
|
|
|
|
|
PAL
t
<7*»
IOE IOE IOE IOE IOE IOE
iT n n
SM
<7*> PAL
У У I
|
|
|
|
|
| ||||
|
LAB |
|
|
EAB |
|
|
LAB | ||
|
|
|
| ||||||
|
| ||||||||
|
|
|
|
|
| ||||
|
LAB |
|
|
|
EAB |
|
|
|
LAB |
|
|
|
|
|
| ||||
IIOE |<- | IOE |<- I IOE |«- | IOE |«- | IOE |<- | IOE |«-
|
-H IOE | |
£2— |
|
->| IOE | |
• •• |
|
4 IOE | |
£2— |
|
-H IOE | |
|
|
-H IOE | |
г) |
|
-H IOE | |
|
<7^
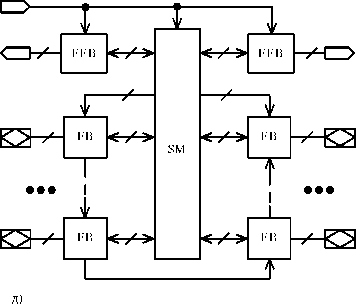
IOE IOE IOE IOE IOE IOE
Рисунок 34 - Основные структуры CPLD
Структура на рис.34,д представляет специализированное семейство XC7300 фирмы Xilinx, предназначенное для построения арифметических вычислителей. Она содержит два типа функциональных блоков: быстрые FFB и повышенной функциональной мощности FB. Блоки FB реализуют арифметические операции, а на блоках FFB строятся конечные автоматы для управления вычислительными процессами.
Функциональные преобразователи
Основными функциональными преобразователями большинства CPLD являются PAL-подобные блоки, состоящие их двух матриц: матрицы И и матрицы ИЛИ, причем программируется только матрица И, а матрица ИЛИ имеет фиксированную настройку. Пара матриц И и ИЛИ позволяет вычислять булевы функции, представленные в дизъюнктивной нормальной форме (ДНФ). Выходные сигналы PAL-блоков формируются с помощью программируемых макроячеек, имеющих обратные связи с матрицей И. Обычно макроячейка включает вентиль ИЛИ (часть матрицы ИЛИ), регистр и элементы для ее программирования. Отметим, что в MAX-устройствах PAL-блоки названы LAB- модулями.
В устройствах FLEX-логики в качестве функциональных преобразователей выступают LAB-модули (Logic Array Block), содержащие множество логических элементов, объединяемых локальной шиной межсоединений. Каждый логический элемент включает функциональный генератор (Look-Up Table - LUT), который может программно настраиваться на табличную реализацию любой функции определенного числа переменных. При таком подходе к реализации логических вычислений отпадает необходимость в матрицах И и ИЛИ, благодаря чему экономится площадь кристалла и появляется возможность усложнения структуры логических элементов.
Функциональной мощности LAB-модулей часто бывает недостаточно для реализации сложных функций, поэтому в структуру устройств FLEX 10K введены EAB- модули (Embedded Array Block). EAB-модуль может настраиваться на табличную реализацию общих мегафункций проекта, например, умножения, корректировки ошибок, векторных операций и др. Эти функции затем используются вместе с обычной логикой, реализуемой в L AB-модулях, для построения целых систем на одном FLEX-устройстве: микроконтроллеров, специализированных процессоров, систем цифровой обработки сигналов, телекоммуникации и др. При необходимости EAB-модуль может использоваться как статическое ОЗУ в различных конфигурациях: 265х8, 512х4, 1024х2 и 2048х1. Для построения ОЗУ большого размера несколько EAB-модулей объединяются вместе.
Некоторые CPLD обеспечивают дополнительные логические преобразования. Так, устройства FLASH и FLEX 10K имеют программируемую опцию выхода “открытый сток” (open-drain), использование которой вместе с внешним питающим резистором позволяет реализовать дополнительную функцию ИЛИ. В устройствах семейства XC9500 матрица переключений позволяет реализовать функцию И большого числа переменных. Возможности матрицы переключений еще более развиты в устройствах семейства XC7300. Здесь матрица переключений, кроме обеспечения 100% соединений между функциональными блоками, позволяет реализовать функции И, ИЛИ, И-НЕ и ИЛИ-НЕ большого числа переменных. Последнее свойство матрицы переключений носит название “SMART switch”.
Кроме рассмотренных основных логических преобразователей CPLD также допускают функциональную обработку сигналов в макроячейках (логических элементах).
Обеспечение соединений между функциональными блоками
Для большинства CPLD соединения между PAL-блоками осуществляется с помощью матрицы переключений. В идеальном случае матрица переключений обеспечивает 100% соединений между любыми PAL-блоками. Данное свойство выполняется для сравнительно простых устройств MAX7000, FLASH-логики, XC7300 и XC9500, а также для устройств семейства MACH5. Для других устройств семейств MACH и семейств MAX не гарантируется 100% разводка сигналов между функциональными блоками, поэтому в некоторых случаях приходится преобразовывать проект для уменьшения числа связей между PAL-блоками.
С возрастанием сложности устройства данное свойство выполнить становится все труднее ввиду значительной площади, занимаемой на кристалле матрицей переключений. В устройствах семейства MACH5 (рис.34,б) эта проблема решается за счет введения двухуровневой матрицы переключений: глобальной матрицы GI и локальных матриц LI. Локальные матрицы обеспечивают соединения между группами PAL-блоков, называемыми сегментами, а глобальная матрица выполняет соединения сигналов между сегментами.
В CPLD со структурой на рис.34,в фактически имеется два уровня межсоединений. Глобальные соединения обеспечивают каналы трассировки, а на нижнем уровне находятся локальные шины LAB-модулей. Локальные шины гарантируют 100%-ю разводку любых сигналов внутри LAB-модуля, а на глобальном уровне обеспечение соединений зависит от ресурсов каналов трассировки, которые различны для устройств различных семейств.
Каналы трассировки в структуре на рис.34,в, кроме обеспечения соединений между LAB-модулями, служат также для подвода сформированных сигналов к внешним выводам и от внешних выводов к внутренней логике (в других структурах CPLD внешние выводы подсоединяются непосредственно к функциональным блокам). Поэтому от возможностей каналов трассировки во многом зависит успех реализации проекта на заданном устройстве.
В общем случае обеспечение соединений между функциональными блоками и между внутренней логикой и внешними выводами является достаточно сложной задачей, которая решается с помощью программы, называемой упаковщиком (fitter). В некоторых случаях указание разработчиком рекомендаций по декомпозиции логики проекта для реализации в отдельных функциональных блоках способствует успешному решению задачи.
При разработке на CPLD быстродействующих проектов важное значение имеют временные параметры. Во всех устройствах фирмы Advanced Micro Devices (AMD) любой сигнал со входа или цепи обратной связи может пройти на выход только через матрицу переключений. Благодаря этому сохраняется постоянной задержка формируемых сигналов. Данное свойство реализовано за счет снижения быстродействия и использования дополнительных ресурсов CPLD. Поэтому в устройствах других производителей концепция фирмы AMD не поддерживается и задержки выходных сигналов могут быть различными для разных сигналов. Подобная проблема неизбежно усложняет проектирование, требуя выполнения временного анализа. В некоторых случаях для решения данной проблемы приходится прибегать к синхронизации выходных сигналов путем их буферизации в регистрах.
Соотношение числа триггеров и внешних выводов
Отношение числа триггеров к числу внешних выводов иногда выступает в качестве грубой меры функциональной мощности CPLD: чем оно больше, тем функциональная мощность микросхемы выше. Триггеры CPLD, в основном, используются для реализации регистровой логики, буферизации входных и выходных сигналов, а также для реализации внутренней (промежуточной) регистровой логики, например, памяти автомата. Большое число триггеров по отношению к числу внешних выводов особенно важно при построении таких функциональных узлов, как счетчики и регистры.
Поскольку в структурах на рис.34,а, рис.34,б и рис.34,д одна макроячейка соответствует одному внешнему выводу, можно предположить, что число триггеров в этих структурах будет кратно числу внешних выводов. Это предположение подтверждается для всех MACH-устройств, FLASH-логики и семейства XC7300: один триггер на вывод для FLASH-логики, MACH1, MACH3 и XC7300; два триггера на вывод для MACH2 и MACH5; три триггера на вывод для MACH4. Исключение составляют семейства MAX5000 и MAX7000. Здесь наблюдается тенденция возрастания отношения числа триггеров к числу внешних выводов с увеличением сложности устройства. При этом отдельные макроячейки не имеют связи с внешними выводами, а используются для реализации внутренней логики.
В CPLD со структурами на рис.34,в и рис.34,г нет жесткой зависимости числа макроячеек от числа внешних выводов. Однако и для этих устройств (MAX9000, FLEX- логика и XC9500) наблюдается тенденция опережающего роста триггеров по отношению к числу внешних выводов с увеличением сложности устройства.
При задействовании триггера макроячейки в стандартных PLD для реализации внутренних функций, например, памяти автомата, внешний вывод, как правило, остается не используемым. Данная проблема в CPLD решается несколькими способами:
введением в макроячейку дополнительного скрытого (buried) триггера для реализации внутренней логики (MACH2,4,5);
введением в структуру PAL-блока скрытых, т.е. непосредственно не связанных с внешними выводами, макроячеек (FLASH, MAX5000, MAX7000);
“регистровой упаковкой” (register packing), когда макроячейка имеет два выхода; в случае реализации комбинационной логики один выход используется для формирования функции, а второй - для задействования регистра в цепи обратной связи (MAX9000, FLEX 10K) и др.
Назначение промежуточных шин макроячейкам
Выходы матрицы И называются промежуточными шинами. Они подсоединяются к макроячейкам. Число q промежуточных шин, связанных с одной макроячейкой ограничивает количество элементарных конъюнкций (слагаемых) в дизъюнктивной нормальной форме реализуемой функции. Большое значение q требует значительного увеличения площади кристалла, занимаемого матрицей И, что приводит к удорожанию CPLD и снижению быстродействия устройства. Малое значение q не позволяет реализовать функции, имеющие в ДНФ большое число слагаемых.
Имеется два основных способа назначения промежуточных шин матрицы И выходным макроячейкам: с помощью распределителя (allocator) и с помощью
расширителей (expanders).
С каждой макроячейкой обычно связано некоторое среднее число промежуточных шин (4-5). Если часть или все шины некоторой макроячейки не используются, с помощью распределителя они могут быть назначены другим, обычно соседним макроячейкам. Для этого промежуточные шины матрицы И разбиваются на группы, называемые кластерами, по 2, 3, 4 или 5 шин в каждой группе. Распределитель промежуточных шин оперирует кластерами, переназначая неиспользуемые кластеры тем макроячейкам, которым требуется большее число промежуточных шин.
Расширители делятся на параллельный (parallel) и общий или совместно используемый (shared). Параллельный расширитель позволяет с небольшой задержкой последовательно объединять по ИЛИ промежуточные шины неиспользуемых макроячеек и назначать их требуемой макроячейке. Общий расширитель представляет собой совокупность промежуточных шин, которые одновременно могут использоваться несколькими макроячейками одного PAL-блока. Имеется два способа организации общего расширителя, когда расширитель составляют отдельные, не подсоединенные ни к одной макроячейке промежуточные шины PAL-блока, и когда одна промежуточная шина каждой макроячейки, если она не используется, считается промежуточной шиной общего расширителя.
В устройствах FLEX-логики отсутствует матрица И, поэтому нет понятия промежуточных шин. Однако к каждому логическому элементу от локальной шины подводятся сигналы по отдельным линиям, которые условно можно назвать промежуточными шинами. Для устройств семейства FLEX8000 таких линий 10, 4 их которых служат для подвода обрабатываемых сигналов, а 6 - для сигналов управления. В устройствах семейства FLEX 10K таких линий 11, на один сигнал управления больше.
Макроячейки CPLD
Обычно макроячейки CPLD содержат вентиль ИЛИ, триггер, называемый часто регистром, логику управления и программируемые цепи передачи сигналов. Вентиль ИЛИ содержат все рассматриваемые CPLD, за исключением FLEX-логики, причем в макроячейках устройств семейства XC7300 находится целых три вентиля ИЛИ.
Концепция совокупности двух матриц хорошо себя зарекомендовала при реализации систем булевых функций, представленных в дизъюнктивной нормальной форме. Однако для некоторых функциональных узлов (сумматоры, компараторы, счетчики и др.) получаются слишком сложные логические уравнения и их реализация двумя матрицами не эффективна. Для повышения функциональной мощности в макроячейки CPLD наряду с вентилем ИЛИ и регистром часто вводятся дополнительные элементы, такие как вентиль “исключающее ИЛИ” (MAX, MACH3,4, XC9500), схемы сравнения для реализации компаратора (FLASH), арифметическо-логические устройства (FLEX, XC7300), цепи переноса (FLEX, XC7300) и каскадирования (FLEX). Кроме того, каждое арифметическо-логическое устройство кроме выполнения арифметических операций может работать как функциональный генератор для табличного вычисления логических функций.
На функциональные возможности макроячеек определенное значение также оказывает число обратных связей и точки их подсоединений: вход триггера, выход триггера (инверсный выход триггера) внешний вывод и др. Число обратных связей макроячеек разное для различных CPLD: одна - для MAX9000 и FLEX; две - для
MAX5000 и FLASH; три - для MAX7000, MACH и XC7300. Кроме того, обратные связи устройств MACH2,4,5 могут содержать дополнительный регистр.
Обычно при реализации комбинационной логики триггер обходится и остается незадействованным. С целью повышения степени использования ресурсов макроячейки в устройствах семейств MAX9000 и FLEX 10K имеют два выхода. В этом случае при реализации комбинационной логики один выход служит для формирования выходной функции, а второй выход подключается к цепи обратной связи для использования регистра для реализации скрытой (внутренней) регистровой логики, например, памяти автомата. Подобное свойство носит название регистровой упаковки (register packing).
Устройства семейства XC7300 специально спроектированы для реализации арифметических функций. Поэтому в состав макроячеек этих устройств дополнительно введено одноразрядное арифметическо-логическое устройство (АЛУ), которое также может использоваться в качестве функционального генератора. Кроме того, в XC7300 имеется кольцевая цепь переноса, которая охватывает все макроячейки устройства.
В логических элементах FLEX-логики отсутствуют вентили ИЛИ, но имеется 4- входовой функциональный генератор, который позволяет очень быстро вычислить любую функцию четырех переменных. Данный функциональный генератор имеет четыре режима работы: нормальный, арифметический, реверсивного счетчика и очищаемого счетчика. Все логические элементы FLEX-логики также содержат цепь переноса и цепь каскадирования. Цепь переноса служит для реализации переносов при арифметических вычислениях, а цепь каскадирования предназначена для реализации функций большого числа переменных.
Регистры макроячеек
В качестве регистров макроячеек CPLD используются триггеры различного типа. Основным типом триггера является D-триггер, его поддерживают все CPLD. Другие типы триггеров получаются либо путем программирования, либо путем эмуляции на основе D- триггера, в последнем случае для эмуляции других типов триггеров часто используется вентиль “исключающее ИЛИ”.
Таким образом в устройствах семейства XC7300 (FB-блоки) применяются только D-триггеры; в семействах MACH1,2, XC7300 (FFB-блоки) и XC9500 - D или T триггеры; в остальных CPLD в качестве регистров могут использоваться D, T, JK или SR триггеры. Кроме того, в устройствах семейств XC7300 (FB-блоки), MACH2,3,4,5 и MAX5000 регистры могут работать в режиме прозрачной защелки (latchs).
В случае реализации комбинационной логики макроячейки всех CPLD допускают возможность программирования путей для обхода триггера сформированным сигналом. В устройствах семейства XC7300 (FB-блоки) для этого используется программный перевод триггера в режим прозрачной защелки.
Выбор типа триггера влияет на сложность логических функций, управляющих входами триггера. Путем выбора подходящего типа триггера в некоторых случаях удается упростить проект и “вложить” его в структуру CPLD с меньшими функциональными возможностями.
Сигналы управления триггеров делятся на глобальные, общие для всего устройства или PAL-блока, и локальные, формируемые непосредственно в макроячейке.
Глобальные сигналы управления регистрами обычно используются для общего управления всем проектом или его отдельными частями. Глобальные сигналы могут поступать со специальных входов по отдельным цепям, обеспечивающих минимальный “перекос” и большой коэффициент расширения по входам; формироваться с помощью генератора синхросигналов на основании внешних опорных синхросигналов (семейства MACH3,4) или формироваться на промежуточных шинах матрицы И.
Локальные сигналы служат для индивидуального управления триггером, а также для построения асинхронных и апериодических проектов. Локальные сигналы как правило, формируются на промежуточных шинах матрицы И, подсоединяемых к макроячейке.
С целью экономии общих ресурсов трассировки CPLD для управления триггерами следует стремиться максимально использовать выделенные входы и специальные цепи глобальных сигналов управления.
Триггеры рассматриваемых CPLD могут управляться следующими глобальными сигналами:
синхронизации GCLK;
сброса GCLR (кроме семейств MAX5000 и XC7300);
установки GPRN (кроме MAX-устройств и семейства XC7300); а также локальными сигналами:
синхронизации CLK (кроме устройств семейств MACH1,2);
сброса CLR (кроме устройств семейств MACH1,2);
установки PRN(кроме устройств семейств MACH1,2).
Триггеры CPLD семейств MAX7000 и FLEX 10K дополнительно могут управляться локальным сигналом разрешения синхронизации ENA.
Назначение внутренней логики внешним выводам
В идеальном CPLD любой сформированный внутренней логикой сигнал может быть назначен любому внешнему выводу. Это свойство дает целый ряд преимуществ:
можно параллельно выполнять разработку логики CPLD и конструкции печатной платы;
все внешние выводы общего назначения можно считать логически эквивалентными между собой, что значительно упрощает решение задач трассировки печатной платы будущего устройства;
исключительно просто вносятся изменения в проект, связанные с переназначением сигналов, и др.
Названное свойство выполняется только для сравнительно простых CPLD семейства XC9500. Это достигается благодаря снижению быстродействия (формируемые сигналы дважды проходят через матрицу переключений) и увеличению размеров матрицы переключений, что неизбежно связано с удорожанием всего устройства и также ведет к снижению быстродействия.
В устройствах со структурой на рис.34,а каждая макроячейка жестко связана с определенным внешним выводом. В общем случае возможно переназначение сигналов в пределах одного PAL-блока путем его перепрограммирования. Однако не все макроячейки одного PAL-блока эквивалентны между собой:
крайние макроячейки могут иметь различное число промежуточных шин, по сравнению с внутренними макроячейками;
цепи переноса и каскадирования могут не связывать крайние макроячейки и др.
Передача логического сигнала внешнему выводу, принадлежащему другому PAL- блоку, в устройствах со структурой на рис.34,а связана с необходимостью задействования ресурсов матрицы переключений и макроячейки другого PAL-блока.
В устройствах семейств MACH3,4 для упрощения назначения внутренних сигналов внешним выводам служит матрица переключения выходов, которая позволяет назначить в пределах одного и того же PAL-блока любой сформированный сигнал любому внешнему выводу. Однако введение в структуру PAL-блока дополнительной матрицы переключений снижает общее быстродействие устройства.
В устройствах семейства MACH5 (рис.34,б) назначение сигналов PAL-блоков внешним выводам в пределах одного и того же сегмента упрощается благодаря наличию локальной матрицы переключений. Однако назначение сигнала внешнему выводу из другого сегмента будет требовать задействования ресурсов глобальной матрицы переключений, локальных матриц данного и другого сегментов, а также макроячейки PAL-блока другого сегмента.
В устройствах семейств MAX9000 и FLEX-логики со структурой на рис.34,в нет жесткой зависимости между формируемыми сигналами и внешними выводами. Здесь назначение внутренней логики конкретному выводу полностью определяется ресурсами каналов трассировки. В некоторых случаях, когда каналы трассировки заняты, передача сигналов может осуществляться путем задействования свободных логических элементов LAB-модулей.
Управление входными и выходными сигналами
Обрабатываемые с помощью CPLD входные сигналы и формируемые выходные сигналы поступают в устройство и выводятся из него, как правило, с помощью двунаправленных выводов общего назначения. В некоторых CPLD в качестве входов могут также использоваться специальные (dedicated) входы.
Большинство CPLD имеют традиционные для PLD комбинационные парафазные входы. Однако устройства семейств MAX9000 и FLEX-логики допускают буферизацию входных сигналов в регистрах, а семейств MACH4 и XC7300 в регистрах или защелках.
Для большинства CPLD выходной буфер не выполняет никаких логических преобразований сигналов, а служит лишь для согласования с внешними схемотехническими требованиями: приведению сигналов к необходимым уровням
напряжений, увеличения мощности и др.
Выходные буферы всех CPLD позволяют управлять третьим высокоипедансным состоянием для отключения от внешней шины. Сигналы разрешения выходов могут быть как глобальными GOE (MAX7000, MAX9000, MACH1,2, FLEX-логика), так и локальными OE (MAX5000, MAX9000, MACH3,4, FLEX-логика). В случае локального управления выходным буфером вывод в один момент времени может быть входом, а в другой - выходом. Данное свойство может, например, использоваться при построении сдвиговых регистров.
Выходные буферы устройств семейств MAX5000, MAX7000, MACH1,2,3, XC7300 и XC9500 комбинационные, а семейств MAX9000, MACH4,5 и FLEX-логики содержат регистр. Регистры выходных буферов устройств семейства MAX9000 и FLEX-логики могут синхронизироваться глобальными или локальными сигналами синхронизации. Кроме того, для семейств MAX9000 и FLEX 10K допускается локальный сигнал разрешения синхронизации ENA.
Выходные буферы некоторых CPLD допускают программное управление:
открытым стоком (open-drain) для FLASH и FLEX 10K;
скоростью нарастания/спада сигнала (slew-rate) для MAX7000, MAX9000, FLEX-логики и XC9500;
подсоединением неиспользуемых выводов к “земле” для уменьшения системного “шума” (XC9500);
градацией соотношения скорость/мощность (MACH5) и др.
Кроме того, выходные буферы последних поколений CPLD удовлетворяют ряду схемотехнических стандартов таких, как PCI (подсоединения периферийных компонент), BST (тестирования граничным сканированием), ISP (программирования в системе), ICR (перенастройки в системе) и др.
ПРОГРАММИРУЕМЫЕ ПОЛЬЗОВАТЕЛЕМ ВЕНТИЛЬНЫЕ МАТРИЦЫ (FPGA)
Общее описание
Программируемые пользователем вентильные матрицы (Field Programmable Gate Arrays - FPGA) впервые были разработаны фирмой Xilinx в 1985 году. Фирма Xilinx свои FPGA иногда называет матрицами логических ячеек (МЛЯ - Logic Cell Array - LCA). В отличие от вентильных матриц, программируемых с помощью масок во время изготовления, FPGA программируются пользователем. Настраиваемыми элементами в FPGA являются программируемые мультиплексоры. Настройка FPGA на заданное функционирование выполняется всякий раз перед началом ее работы. Необходимая для этого программа настройки предварительно записывается в ПЗУ (ОЗУ). Сразу после включения питания выполняется загрузка информации из ПЗУ и осуществляется автоматическая инициализация FPGA (для этого FPGA содержит необходимые логические схемы). Допускается также выполнение настройки FPGA под управлением микропроцессора или микроконтроллера.
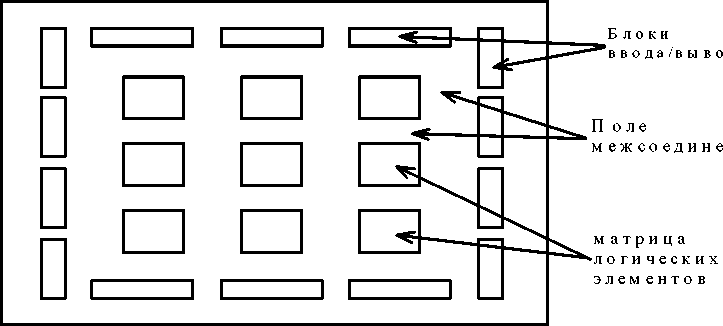
Рисунок 35 - Обобщенная структура FPGA XC2000, XC3000, XC4000
FPGA имеет типичную структуру вентильной матрицы (рис.35). В центре FPGA находится матрица настраиваемых логических блоков (Configurable Logic Blocks - CLBs), пространство между которыми заполнено программируемыми межсоединениями (Programmable Interconnects-PIs), состоящими из горизонтальных и вертикальных каналов. По краям кристалла для согласования уровней внутренних сигналов FPGA с внешними выводами расположены блоки ввода-вывода (БВВ) (Input/Output Blocks-IOBs).
Блоки ввода-вывода
Блоки ввода-вывода (БВВ) необходимы для согласования внутренних и внешних уровней логических сигналов, усиления сигналов до необходимой нагрузочной способности, защиты внутренних цепей FPGA от электрических повреждений и др. В рассматриваемых FPGA блоки ввода-вывода могут программироваться для согласования либо с ТТЛ, либо с CMOS уровнями сигналов.
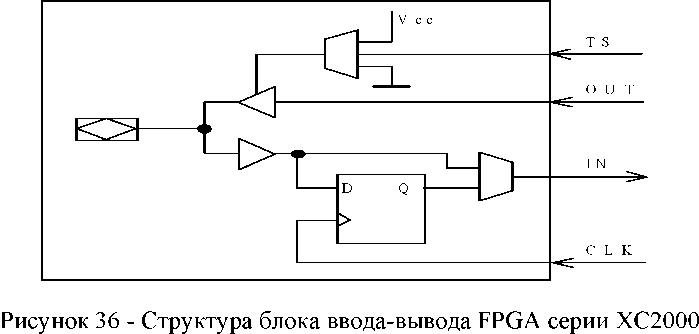
Структура БВВ серии XC2000 показана на рис.36. Он содержит цепи для согласования уровней сигналов, два программируемых мультиплексора, D-триггер и цепи управления. Путем программирования входной сигнал IN с внешнего вывода во внутренние цепи FPGA может поступать либо непосредственно, либо через D-триггер. В свою очередь выход OUT может быть отключен от блока ввода-вывода (OFF), постоянно включен (ON), либо его третье состояние может управляться сигналом TS, формируемом во внутренних цепях FPGA. Выход и вход блока ввода-вывода связаны цепью обратной связи. Поэтому если вывод не используется, то соответствующий ему блок ввода-вывода можно задействовать в реализуемой FPGA схеме в качестве элемента памяти или буфера внутренних сигналов.
Цепи согласования уровней сигналов обеспечивают на внешнем выводе силу тока до 4 mA. D-триггеры всех блоков ввода-вывода синхронизируются общим сигналом CLK. Сброс триггеров осуществляется во время инициализации при включении питания, а также во время функционирования низким уровнем общего входа RESET.

Рисунок 37 - Структура блока ввода-вывода FPGA серии XC3000
Блок ввода-вывода FPGA серии XC3000 (рис.37) организован аналогично. Дополнительно он содержит D-триггер для выходного буфера, причем входные и выходные триггера синхронизируются разными сигналами: CK1 и CK2 . Во внутренние цепи FPGA из блока ввода-вывода поступают одновременно два входных сигнала: прямой IN1 и буферизированный IN2 . Предусмотрена возможность программировать полярность выходного сигнала (OUT INVERT) и сигнала, управляющего третьим состоянием (3- STATE INVERT), возможен также обход сигналом OUT выходного буфера (OUTPUT SELECT). Режим SLEW RATE позволяет несколько снизить скорость передачи выходных сигналов, что уменьшает амплитуду пиков и системных шумов. Добавлена также возможность включать нагрузочное сопротивление для неиспользуемых "плавающих" выводов (PASSIVE PULL UP) с целью уменьшения шумов.
|
S |
LEW |
|
R |
ATE |
О
о
S3
O U T
о
С]
С]
I N 1
I N 2
к
о
CLK
|
D Q |
|
|
| ||||
|
|
O u tp u t |
| |||||
|
> |
b u ffe r |
Input | |||||
|
|
|
b u ffe r | |||||
|
P A |
S |
S |
I V |
E | |||
|
P U |
L |
L |
U |
P / | |||
|
PUL |
L |
D |
O |
W N | |||
V cc
Q
о
DELAY
![]()
Рисунок 38 - Блок ввода-вывода FPGA серии XC4000
Блок ввода-вывода FPGA серии XC4000 показан на рис.38. В нем добавлена возможность прохождения входного сигнала через элемент задержки на несколько наносекунд для согласования с сигналом синхронизации (последний перед тем, как попасть в БВВ, должен пройти через глобальный буфер). Каждый из двух сигналов IN1 и IN2 может либо непосредственно поступать во внутренние цепи FPGA, либо проходить через буфер. Кроме того, добавлена возможность инвертировать сигнал синхронизации выходного регистра. Сила тока на внешнем выводе может достигать 12 mA, а на двух выводах, соединенным монтажным И - 24 mA. Неиспользуемые ("плавающие") выводы
могут подсоединяться как к цепи питания VCC (PASSIVE PULL UP), так и к "земле" (PASSIVE PULL DOWN).
Настраиваемые логические блоки
Настраиваемые логические блоки (CLB) предназначены для реализации логических функций, определяемых пользователем. Настройка каждого CLB определяется программированием функциональной таблицы (Look-Up Table). В общем случае CLB включает программируемую комбинационную схему (КС), элементы памяти и цепи управления. Сброс элементов памяти всех настраиваемых логических блоков может выполняется либо во время инициализации, либо в процессе функционирования подачей сигнала низкого уровня на вход RESET.
Структура настраиваемого логического блока серии XC2000 показана на рис.39. CLB имеет четыре логических входа общего назначения A, B, C и D, синхровход K и два выхода X и Y. КС может настраиваться на три конфигурации: для реализации любой булевой функции четырех переменных (рис.40); двух функций трех переменных (рис.41) динамически выбираемых двух функций трех переменных (рис.42). Последняя конфигурация является специальным случаем формы двух функций, в которой вход B динамически выбирается между двумя таблицами функций. Этот динамический выбор позволяет реализовать некоторые функции пяти переменных.
G
A
B
C
C C
S
F
D
D Q
![]()
D
![]()
D
Л
K
CC - функциональный преобразователь
Рисунок 39 - Структура универсального логического блока FPGA серии XC2000
A
F
Рисунок 40 - Конфигурация комбинационной схемы FPGA серии XC2000 для реализации
любой функции четырех переменных
Рисунок 41 - Конфигурация комбинационной схемы FPGA серии XC2000 для реализации
любых двух функций трех переменных
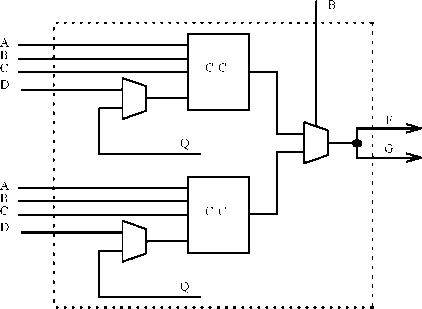
Рисунок 42 - Конфигурация комбинационной схемы FPGA серии XC2000 для реализации
выбора двух функций трех переменных
В качестве переменных всех реализуемых логических функций могут выступать сигналы A, B, C и D, а также выход Q элемента памяти. Элемент памяти может управляться либо асинхронно сигналами установки S и сброса R, либо синхронно. В случае синхронного управления тактирующие импульсы могут поступать со входа общей синхронизации K или с выхода комбинационной схемы G. Выходы X и Y являются полностью взаимозаменяемыми, что может использоваться для оптимизации трассировки.
Настраиваемый логический блок для FPGA серии XC3000 (рис.43) включает два элемента памяти (на каждый выход) и соответственно две цепи обратной связи. Число логических входов общего назначения в нем увеличено до пяти, что позволяет в первой конфигурации реализовать любую функцию пяти переменных, во второй конфигурации - любые две функции четырех переменных и в третьей конфигурации - некоторые функции семи переменных.
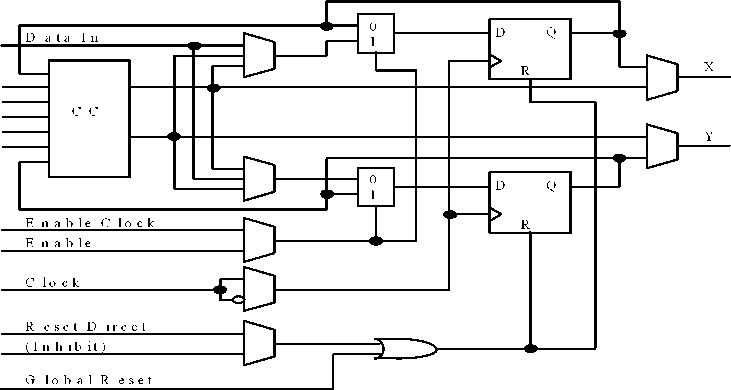
A
B
C
D
E
E C
“ 1 ”
Рисунок 43 - Структура универсального логического бока FPGA серии XC3000
K
Каждый настраиваемый логический блок FPGA серии XC4000 (рис.44) содержит пару D-триггеров и два независимых 4-входовых функциональных генератора F и G , которые могут формировать на своих выходах F' и G' любые булевы функции переменных F1,...,F4 и G1,...,G4 соответственно. Третий функциональный генератор H реализует любую функцию трех переменных F', G' и внешней переменной H1 . Всего CLB FPGA серии XC4000 содержит 13 входов и 4 выхода.
C 1 C 2 C3 C 4
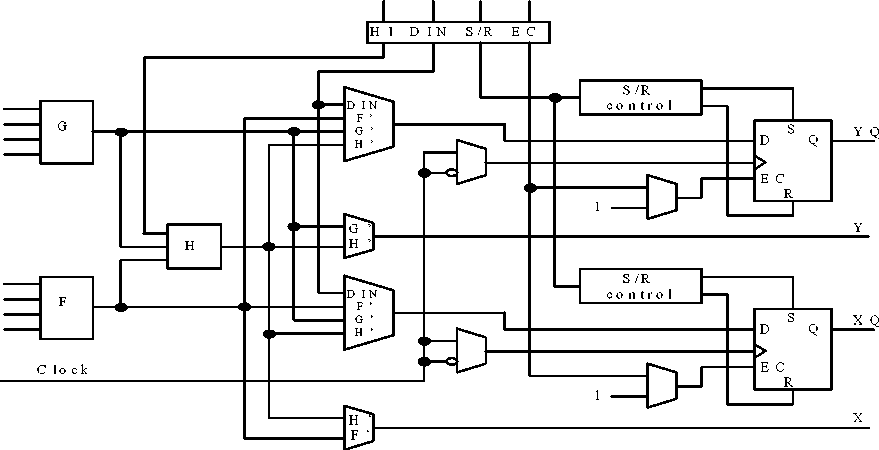
G 4 G 3 G 2 G 1
F 4 F 3 F 2 F 1
Рисунок 44 - Структура универсального логического бока FPGA серии XC4000
K
Сигналы от функциональных генераторов на выход CLB могут поступать двумя путями: F' и H' могут подсоединяться к выходу X, а G' и H' - к выходу Y. Таким образом CLB FPGA серии XC4000 может реализовать:
две независимых функции четырех переменных;
любую одну функцию пяти переменных;
любую функцию четырех переменных вместе с некоторой функцией пяти переменных;
некоторые функции девяти переменных.
Элементы памяти CLB управляются общим входом синхронизации K и входом разрешения синхронизации EC. Третий управляющий вход S/R может программироваться для асинхронной установки или сброса независимо для каждого триггера. На вход триггеров могут поступать значения сигналов F', G' и H' или значение сигнала DIN с прямого входа CLB.
G 4 G 3
G 2
C IN 1 C IN 2
F 4 F 3 B 0 F 2 A 0 F 1
Рисунок 45 - Схема быстрого переноса XC4000
1 G 1
Программируемые мультиплексоры CLB управляются четырьмя внешними сигналами C1,...,C4, которые могут произвольным образом коммутироваться с внутренними сигналами H1, DIN, C/R и EC. Дополнительно функциональные генераторы FPGA серии XC4000 содержат специальную логику для быстрого формирования сигналов арифметического переноса (рис.45). Кроме того, функциональные генераторы можно использовать как быстрое ОЗУ 16x2 или 32x2 (рис.46). Линии F1-F4 и G1-G4 в этом случае являются адресными входами, линии DIN и S/R - линиями данных, а линия H1 - линией разрешения чтения/записи. Если конфигурируется ОЗУ 32x2, линия D1 становится пятым адресным входом, а линия D0 - входом данных. Время чтения ОЗУ составляет 5 ns, а записи - 6 ns.
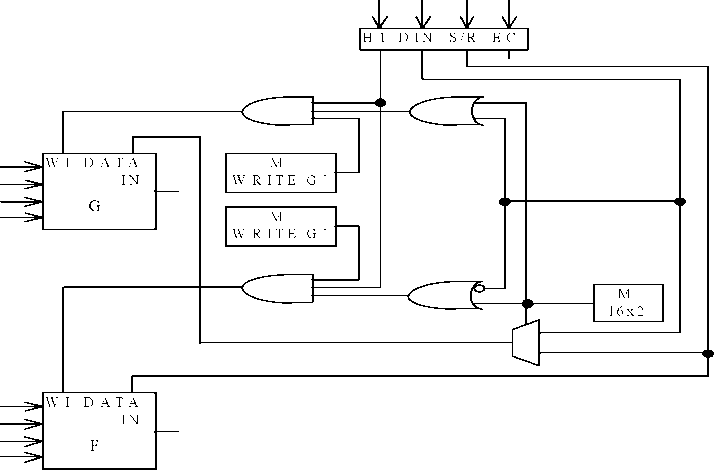
G 4 G 3 G 2
G 4
G 3 G 2 G 1
F 4 F 3 F 2 F 1
Рисунок 46 - Использование таблиц истинности функциональных преобразователей в
качестве ОЗУ
G1
Использование CLB в качестве ОЗУ представляет новые возможности для проектирования на основе FPGA таких устройств, как регистровые матрицы, регистры состояний, индексные регистры, контроллеры DMA, сдвиговые регистры, буферы очередей, буферы стеков и др.
Программируемые межсоединения
Программируемые межсоединения (Programmable Interconnect) включают три типа коммуникаций:
основные межсоединения (General Purpose Interconnect);
длинные линии (Long Lines);
непосредственные соединения (Direct Interconnect).
Основные соединения состоят из вертикальных и горизонтальных коммуникационных каналов (КК), образуемых металлическими проводниками, называемыми сегментами. В местах пересечения каналов располагаются программируемые коммутационные матрицы (ПКМ) (Programmable Switching Matrix), которые могут выполнять соединения любого вертикального сегмента с горизонтальным и наоборот. В FPGA серии XC2000 вертикальные коммуникационные каналы содержат пять сегментов, а горизонтальные - четыре. В FPGA серии XC3000 и вертикальные, и горизонтальные каналы содержат по пять сегментов. К любому сегменту некоторого коммуникационного канала могут подключаться любые выводы смежных с этим каналом настраиваемых логических блоков, а также блоков ввода-вывода.
Для обеспечения передачи сигналов на большие расстояния (в пределах FPGA) каждый вертикальный канал содержит три, а горизонтальный - две (для серии FPGA XC2000 - одну), длинных линии. Длинные линии не проходят через коммутационные матрицы, и длинные линии также могут присоединяться к выводам смежных с ними блоков.
Прямые соединения обеспечивают объединение выводов соседних логических блоков, при этом ресурсы коммуникационных каналов не используются. Для FPGA серии XC2000 накладываются некоторые ограничения на непосредственные соединения. Так, выход X может быть подсоединен только ко входам C или D логического блока, расположенного выше, и ко входам A или B нижнего блока. Выход Y можно подсоединить только ко входу B логического блока, расположенного справа. Фрагмент коммуникационного поля FPGA серии XC2000 показан на рис.47.
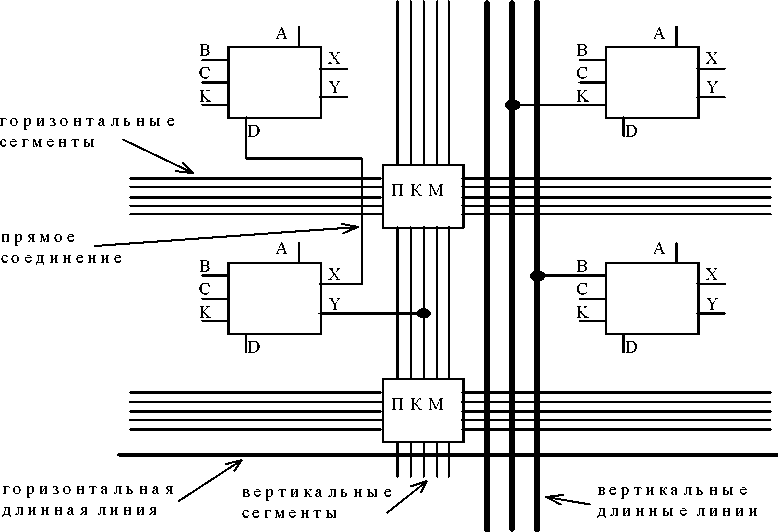
Рисунок 47 - Фрагмент программируемых межсоединений МЛЯ серии XC2000
Для обеспечения синхронной работы с малыми временными разбежками FPGA содержит специальные буферы, подсоединяемые к длинным линиям. В левом верхнем углу FPGA находится буфер, управляющий глобальной цепью, которая доступна всем входам синхронизации настраиваемых логических блоков и блоков ввода-вывода. В правом нижнем углу FPGA находится буфер, который может управлять альтернативной цепью синхронизации. В FPGA серии XC4000 горизонтальные и вертикальные длинные линии могут разрываться посередине, образуя две независимые цепи.
Начиная с серии XC3000 дополнительно сверху и снизу каждого ряда настраиваемых логических блоков располагаются по одной внутренней шине (Internal Busses), которые позволяют реализовать логические функции большого числа переменных. Для управления внутренними шинами каждый смежный CLB имеет пару буферов с тремя состояниями. Благодаря постоянной "подпитке" на внутренней шине можно реализовать функцию И большого числа переменных (рис.48) или мультиплексор (рис.49).

В FPGA серии XC4000 входы и выходы CLB расположены со всех четырех сторон, что предоставляет больше возможностей для трассировки (рис.50). Основные межсоединения FPGA серии XC4000 состоят из линий одинарной длины и линий двойной длины. Линии одинарной длины аналогичны основным межсоединениям предыдущих серий FPGA. Линии двойной длины предназначены для уменьшения задержек сигналов в коммуникационных матрицах. С этой целью в линиях двойной длины коммуникационные матрицы устанавливаются через два ряда CLB (рис.51).
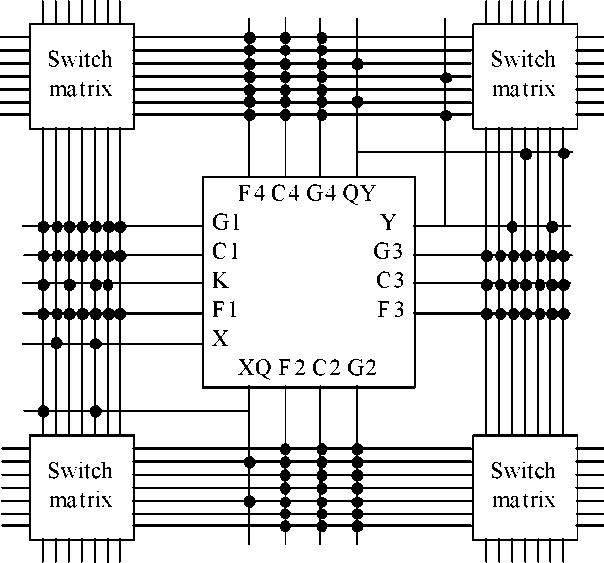
Рисунок 50 - Типичное подсоединение универсального логического блока FPGA
серии XC4000
Ж
Ж
{Ь
-о
-о
CLB
CLB
О-
о-
о
О
о
|
|
|
|
|
|
|
| |
|
C L B |
|
|
C L B | ||||
|
|
|
|
| ||||
|
|
|
|
|
| |||
|
|
|
|
|
| |||
|
|
|
|
|
| |||
|
Т |
|
|
| ||||
о
О
f
Рисунок 51 - Линии двойной длинны FPGA серии XC4000