

Типы связей таблиц.
Различают несколько типов связей реляционных таблиц:
1. один к одному (1:1)
2. один ко многим (1:М)
3. многие ко многим (М:М).
Связь один к одному (1:1) предполагает, что одной строке таблицы А соответствует не более одной строки таблицы В и наоборот.
|
|
|
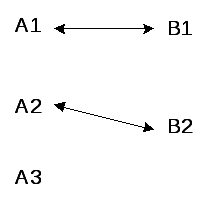
Например:
![]()
Каждый студент имеет определенный набор экзаменационных оценок в сессию.
Связь один ко многим (1:М) предполагает, что одной строке таблицы А соответствует 0, 1 и более строк таблицы В, но каждая строка таблицы В связана не более, чем с одной строкой таблицы В.
|
|
|

Например:
![]()
Установленный размер стипендии по результатам сдачи сессии может повторяться многократно для различных студентов.
Связь многие ко многим предполагает, что в каждый момент времени одной строке таблицы А соответствует 0, 1 и более строк таблицы В и наоборот.
|
|
|

Например:
![]()
Один студент обучается у многих преподавателей, один преподаватель обучает много студентов.
Пример связи 1:1:
ПОДРАЗДЕЛЕНИЕ (название, адрес)
РУКОВОДИТЕЛЬ (таб. номер, фамилия)
![]()
Пример связи 1:М:
ПОСТАВЩИК (№ счет-фактуры, дата счет-фактуры) (составной ключ)
КЛИЕНТ (ИНН, название)
![]()
Пример связи М:М
БАНК (БИК, название)
КЛИЕНТ (ИНН, название)
![]()
Лекция 6. Технология проектирования базы данных.
Рассмотрим технологию проектирования реляционной базы данных без использования аппарата алгебры отношений. Эта технология может быть использована для несложных баз данных, она также не гарантирует оптимальность решения и носит эвристический характер.
В этом случае технологию проектирования БД можно разделить на два этапа.
1-й этап. Разработка технического задания.
При подготовке технического задания составляют:
список исходных данных
список выходных данных, необходимых для управления своим предприятием
список выходных данных, которые он должен предоставлять в вышестоящие структуры (налоговые органы, системы статистического учета и т.д.)
2-й этап. Разработка структуры базы данных.
Работа начинается с создания генерального списка полей, который может включать в себя десятки и сотни полей.
Далее распределяют поля по базовым таблицам. На первом этапе распределение производят по функциональному признаку. Цель этого этапа – обеспечить, чтобы ввод данных в одну таблицу производился в рамках одного подразделения предприятия, а еще лучше на одном рабочем месте.
Рассмотрим это на примере. Допустим, что мы создаем базу данных для предметной области – обучение студентов в ВУЗе. Генеральный список полей показан на рисунке 29.
|
Номер личного дела |
Фами-лия |
Имя |
Отче- ство |
Дата рож- дения |
Пол |
Груп- па |
Оцен- ка1
|
Оцен- ка1
|
Оцен- ка1
|
Резуль- тат
|
Про-цент |
Рисунок 29.
Заполним таблицу данными (рисунок 30):
|
Номер личного дела |
Фамилия |
Имя |
Отче- ство |
Дата рож- дения |
Пол |
Груп- па |
Оцен- ка1
|
Оцен- ка2
|
Оцен- ка3
|
Резуль- тат
|
Про-цент |
|
100 |
Иванов |
Сергей |
Петрович |
01.02.95 |
М |
111 |
4 |
4 |
4 |
Хор |
100% |
|
101 |
Кузьмина |
Анна |
Олеговна |
03.08.93 |
Ж |
112 |
4 |
5 |
5 |
Отл |
200% |
|
102 |
Власова |
Инна |
Ивановна |
04.10.93 |
Ж |
111 |
5 |
5 |
5 |
Отл |
200% |
|
103 |
Шарапова |
Галина |
Игоревна |
05.11.93 |
Ж |
111 |
4 |
4 |
5 |
Хор |
100% |
|
104 |
Сидоров |
Иван |
Фомич |
12.12.94 |
М |
112 |
5 |
5 |
4 |
Отл |
200% |
Рисунок 30.
В результате разбиения по функциональному признаку получим две таблицы (рисунок 31):
СТУДЕНТ
-
Номер личного дела
Фами-лия
Имя
Отче-
ство
Дата
рож-
дения
Пол
Груп-
па
100
Иванов
Сергей
Петрович
01.02.95
М
111
101
Кузьмина
Анна
Олеговна
03.08.93
Ж
112
102
Власова
Инна
Ивановна
04.10.93
Ж
111
103
Шарапова
Галина
Игоревна
05.11.93
Ж
111
104
Сидоров
Иван
Фомич
12.12.94
М
112
СЕССИЯ
-
Номер личного дела
Оцен-
ка1
Оцен-
ка1
Оцен-
ка1
Резуль-
тат
Про-цент
100
4
4
4
Хор
100%
101
4
5
5
Отл
200%
102
5
5
5
Отл
200%
103
4
4
5
Хор
100%
104
5
5
4
Отл
200%
Рисунок 31.
В данном случае это означает, что списки студентов ВУЗА формируются на одном рабочем месте, например, в отделе кадров, а результаты сессии фиксируются на другом рабочем месте, например в деканате.
Наметив столько таблиц, сколько подразделений в предприятии, приступают к дальнейшему делению таблиц. Критерием необходимости деления является факт множественного повторения значения данных в различных записях. Отметим, что в таблице СТУДЕНТ такой факт отсутствует. В таблице СЕССИЯ в поле Результат наблюдается повтор данных. Это свидетельствует о том, что таблицу СЕССИЯ следует поделить на две связанные таблицы (Рисунок 32).
СЕССИЯ
-
Номер личного дела
Оцен-
ка1
Оцен-
ка1
Оцен-
ка1
Резуль-
тат
100
4
4
4
Хор
101
4
5
5
Отл
102
5
5
5
Отл
103
4
4
5
Хор
104
5
5
4
Отл
СТИПЕНДИЯ
-
Резуль-
тат
Про-цент
Хор
100%
Отл
200%
Отл
200%
Хор
100%
Отл
200%
Рисунок 32.
В каждой из таблиц намечают ключевое поле. В качестве такого поля выбирают поле, в котором данные повторяться не могут. Если такого поля нет, пытаются найти составной ключ, состоящий из нескольких полей. Если в таблице нет никаких полей, которые можно было бы использовать как ключ, следует ввести дополнительное поле – Код. Поле Код имеет тип – счетчик. Оно уникально пронумерует все записи и не может содержать повторяющихся значений. Это поле будет являться ключом таблицы. Для нашего примера ключевым полем таблицы СТУДЕНТ является поле – НОМЕР, которое повторяться не может. В таблице СТИПЕНДИЯ ключевым полем является поле РЕЗУЛЬТАТ. Ключевым полем в таблице СЕССИЯ является поле НОМЕР, которое выступает в роли первичного ключа. В таблице СЕССИЯ имеется еще внешний ключ РЕЗУЛЬТАТ, который введен для обеспечения ее связи с таблицей СТИПЕНДИЯ.
Затем таблицы связывают. Наиболее распространенными являются связи 1:1 и 1:М. Связи между таблицами организуются на основе общего поля. Связь 1:1предполагает, что это поле является ключевым в обеих связываемых таблицах. При связи 1:М общее поле в одной таблице должно быть обязательно ключевым, то есть на стороне 1 должно выступать ключевое поле, содержащее уникальные неповторяющиеся значения. Значения на стороне М могут повторяться.
Для нашего примера связи на схеме данных и будут выглядеть следующим образом (Рисунок 33):
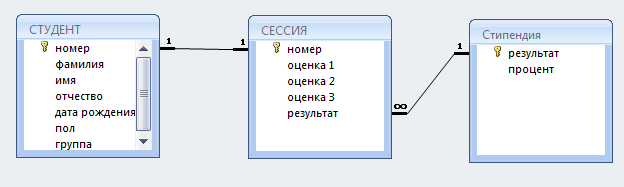
Рисунок 33.
Знак «бесконечность» соответствует стороне М.
Рассмотрим пример. Допустим, что при создании БД о поставках товаров мы получили три таблицы (рисунок 34):
СОТРУДНИКИ
|
Код сотрудника |
Фамилия |
Имя |
Отчество |
Должность |
Домашний телефон |
Табельный номер |
Дата рождения |
ПОСТАВЩИКИ
|
Код поставщика |
Название поставщика |
Обращаться к |
ТОВАРЫ
|
Код товара |
Код сотрудника |
Код поставщика |
Заказано |
цена |
Рисунок 34.
В таблице СОТРУДНИКИ в качестве ключевого поля введено поле Код сотрудника, так как в таблице не обнаружено ни простого, ни составного ключа. Аналогичная ситуация сложилась и в таблице ПОСТАВЩИКИ, поэтому в ней тоже введено ключевое поле Код поставщика.
В таблице ТОВАРЫ по той же причине ключевым полем (первичным ключом) является поле Код товара. Кроме того, в этой таблице имеются два внешних ключа: Код сотрудника и Код поставщика, которые служат для связи с таблицей СОТРУДНИКИ и таблицей ПОСТАВЩИКИ, соответственно.
Схема данных будет иметь вид, показанный на рисунке 35.

Рисунок 35.