

2.1.1. Типы структур данных
Структуризация данных базируется на использовании концепций "агрегации" и "обобщения". Один из первых вариантов структуризации данных был предложен Ассоциацией по языкам обработки данных (Conference on Data Systems Languages, CODASYL) (рис. 2.1).

Рис.2.1 Композиция структур данных по версии CODASYL
Элемент данных – наименьшая поименованная единица данных, к которой СУБД может обращаться непосредственно и с помощью которой выполняется построение всех остальных структур. Для каждого элемента данных должен быть определён его тип.
Агрегат данных – поименованная совокупность элементов данных внутри записи, которую можно рассматривать как единое целое. Агрегат может быть простым (включающим только элементы данных, рис. 2.2,а) и составным (включающим наряду с элементами данных и другие агрегаты, рис. 2.2,б).

Рис.2.2 Примеры агрегатов: а) простой и б) составной агрегат
Запись – поименованная совокупность элементов данных или эле-ментов данных и агрегатов. Запись – это агрегат, не входящий в состав никакого другого агрегата; она может иметь сложную иерархическую структуру, поскольку допускается многократное применение агрегации. Различают тип записи (её структуру) и экземпляр записи, т.е. запись с конкретными значениями элементов данных. Одна запись описывает свойства одной сущности ПО (экземпляра). Иногда термин "запись" за-меняют термином "группа".
Пример записи, содержащей сведения о сотруднике, приведён на рис. 2.3.

Рис.2.3 Пример записи типа СОТРУДНИК
Эта запись имеет несколько элементов данных (Номер пропуска, Должность, Пол и т.д.) и три агрегата: простые агрегаты ФИО и Адрес и повторяющийся агрегат Телефоны. (Повторяющийся агрегат может включаться в запись произвольное число раз).
Среди элементов данных (полей записи) выделяются одно или несколько ключевыхполей. Значения ключевых полей позволяют классифицировать сущность, к которой относится конкретная запись. Ключи с уникальными значениями называютсяпотенциальными. Каждый ключ может представлять собой агрегат данных. Один из ключей назначается первичным, остальные являются вторичными. Первичный ключидентифицирует экземпляр записи, его значение должно быть уникальным и обязательным для записей одного типа. Для примера на рис. 2.3 потенциальными ключами являются поля № пропуска и Паспорт, а первичным ключом целесообразнее выбрать поле № пропуска, т.к. оно явно занимает меньше памяти, чем паспортные данные.
Набор (или групповое отношение) – поименованная совокупность записей, образующих двухуровневую иерархическую структуру. Каждый тип набора представляет собой связь между двумя или несколькими типами записей. Для каждого типа набора один тип записи объявляется владельцем набора, остальные типы записи объявляются членами набора. Каждый экземпляр набора должен содержать только один экземпляр записи типа владельца и столько экземпляров записей типа членов набора, сколько их связано с владельцем. Для группового отношения также различают тип и экземпляр.
Групповые отношения удобно изображать с помощью диаграммы Бахмана, которая названа так по имени одного из разработчиков сетевой модели данных. Диаграмма Бахмана – это ориентированный граф, вершины которого соответствуют группам (типам записей), а дуги – групповым отношениям (рис. 2.4).
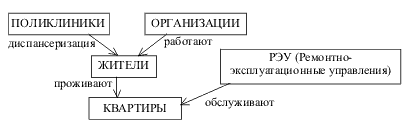
Рис. 2.4 Пример диаграммы Бахмана для фрагмента БД "Город"
Здесь запись типа ПОЛИКЛИНИКА является владельцем записей типа ЖИТЕЛЬ и они связаны групповым отношением диспансеризация. Запись типа ОРГАНИЗАЦИЯ также является владельцем записей типа ЖИТЕЛЬ и они связаны групповым отношениемработают. Записи типа РЭУ и типа ЖИТЕЛЬ являются владельцами записей типаКВАРТИРА с отношениями соответственно обслуживают и проживают. Таким образом, запись одного и того же типа может быть членом одного отношения и владельцем другого.
База данных – поименованная совокупность экземпляров групп и групповых отношений. Это самый высокий уровень структуризации данных.