

1 Теоретическая часть
Дискретный вариационный ряд-это ряд распределения, в котором группы составлены по признаку, изменяющемуся прерывно, т.е. через определенное число единиц совокупности по дискретному признаку, принимающему только целые значения.
Для того, чтобы сформировать ряд и сгруппировать данные используют формулу Стерджесса.
 (1)
(1)
где n – число групп; N-число единиц совокупности.
Частоты-это численности отдельных вариантов или каждой группы вариационного ряда, т.е. это числа, показывающие как, часто встречаются те или иные варианты в ряду распределения.
Относительная частота – это отношение частоты к общему числу данных в ряду. Как правило, относительная частота выражается в процентах.
Для того чтобы построить относительную частоту необходимо каждый случай поделить на общее их количество.
 (2)
(2)
где fотн-относительная частота, f-частота, n-количество случаев.
Накопленные частоты определяются путем последовательного прибавления к частотам (или частностям) первой группы этих показателей последующих групп ряда распределения.
Полигон используется при изображении дискретных вариационных рядов. Для его построения в прямоугольной системе координат по оси абсцисс в одинаковом масштабе откладываются ранжированные значения варьирующего признака, а по оси ординат наносится шкала для выражения величины частот.
Средней величиной называют показатель, который характеризует обобщенное значение признака или группы признаков в исследуемой совокупности.
Существует несколько категорий средних величин. Они изображены на рисунке 1.
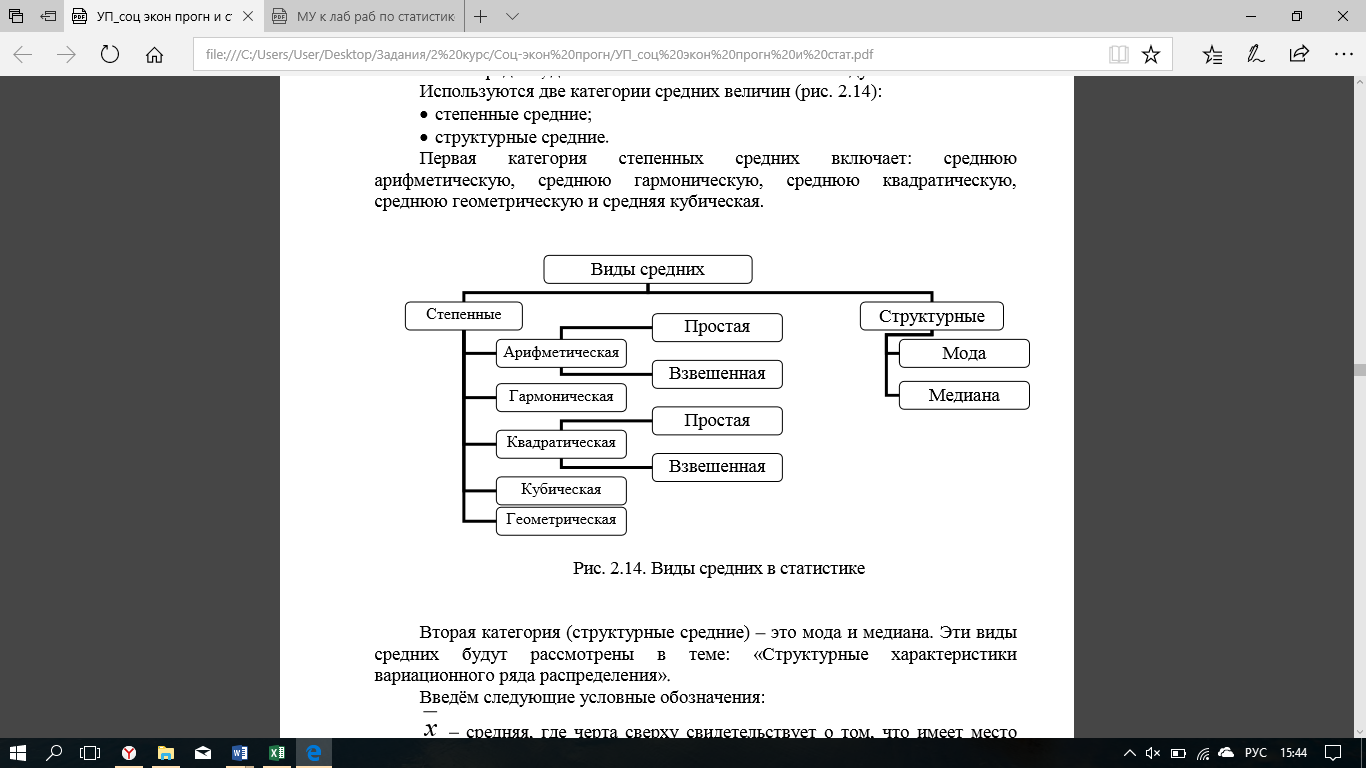
Рис. 1
Простая средняя считается по не сгруппированным данным. Взвешенная же наоборот.
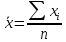 -простая
-простая
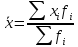 -взвешенная
(3)
-взвешенная
(3)
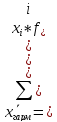 -
гармоническая
-
гармоническая
 -геометрическая
-геометрическая
Средняя по интервальному ряду считается по взвешенной средней.
Если исходные данные заданы в виде интервального ряда, то:
1) Закрывают открытые интервалы, приняв их равными ближайшим закрытым.
2) За значение осредняемого признака x берут середины интервалов и строят условный дискретный ряд распределения:
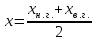 (4)
(4)
где хн.г и хв.г.-значение нижней и верхней границы интервала.
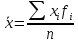 (5)
(5)
Медиана - это величина, которая соответствует варианту, находящемуся в середине ранжированного ряда.
Для нахождения медианы необходимо найти её порядковый номер по формуле
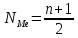 (6)
(6)
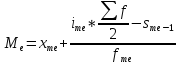 (7) Численное значение медианы
определяют по накопленным частотам в
дискретном ряду. Медианным называют
первый интервал, где сумма накопленных
частот превышает половину наблюдений
от общего числа всех наблюдений.
(7) Численное значение медианы
определяют по накопленным частотам в
дискретном ряду. Медианным называют
первый интервал, где сумма накопленных
частот превышает половину наблюдений
от общего числа всех наблюдений.
Модой называется наиболее часто встречающийся вариант или то значение признака, которое соответствует максимальной точке теоретической кривой распределения. В дискретном ряду мода-это вариант с наибольшей частотой.
При использовании показателя среднего линейного отклонения возникают определенные неудобства, связанные с тем, что приходится иметь дело не только с положительными, но и с отрицательными величинами. Таким образом появилось возведение всех отклонений во вторую степень, чтобы работать только с положительными величинами. Такими показателями стали среднее квадратическое отклонение σ и среднее квадратическое отклонение в квадрате σ2-дисперсия.
 (8)
(8)
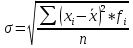 (9)
(9)
Среднее линейное отклонение вычисляется как средняя арифметическая (простая или взвешенная в зависимости от исходных данных) из абсолютных значение отклонений вариантов и среднего значения признака в совокупности. Среднее линейное отклонение дает обобщенную характеристику степени колеблемости признака в совокупности.
 (10)
(10)
Для целей сравнения колеблемости различных признаков в одного и того же признака в нескольких совокупностях представляют интерес показатели вариации, приведенные в относительных величинах. Относительные показатели вариации выражаются в процентах и определяют не только сравнительную оценку вариации, но и дают характеристику однородности совокупности.
Коэффициент осцилляции вычисляется как отношение размаха вариации к средней арифметической.
 (11)
(11)
Относительное линейное отклонение вычисляется как отношение среднего линейного отношения к средней арифметической.
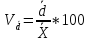 (12)
(12)
Коэффициент вариации вычисляется как отношение среднего квадратического отклонения к средней арифметической.
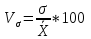 (13)
(13)
Для распределений, близких к нормальному, совокупность считается однородной, если коэффициент вариации не превышает 33 %.
Средняя величина только тогда отражает типичный уровень признака, когда она рассчитана по качественно однородной совокупности.
Проверка случайности колебаний уровней остаточной последовательности означает проверку гипотезы о правильности выбора вида тренда.
Обозначим протяженность самой длинной серии через Kmax, а общее число серий — через v. Выборка признается случайной, если выполняются следующие неравенства для 5%-го уровня значимости
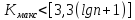 (14)
(14)
 (15)
(15)
Проверка соответствия распределения случайной компоненты нормальному закону распределения может быть произведена лишь приближенно с помощью исследования показателей асимметрии (γi) и эксцесса (γ2), так как временные ряды, как правило, не очень велики. При нормальном распределении показатели асимметрии и эксцесса некоторой генеральной совокупности равны нулю. Мы предполагаем, что отклонения от тренда представляют собой выборку из генеральной совокупности, поэтому можно определить только выборочные характеристики асимметрии и эксцесса и их ошибки.
 (16)
(16)
В этих формулах γ1 - выборочная характеристика асимметрии; γ2 - выборочная характеристика эксцесса; σγ1 и σγ2— соответствующие среднеквадратические ошибки.
Если одновременно выполняются следующие неравенства:
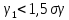 ;
;
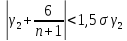 (17)
(17)
то гипотеза о нормальном характере распределения случайной компоненты принимается.
Проверка равенства математического ожидания случайной компоненты нулю, если она распределена по нормальному закону, осуществляется на основе t-критерия Стьюдента. Расчетное значение этого критерия задается формулой:
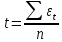 (18)
(18)
Проверка независимости значений уровней случайной компоненты, т.е. проверка отсутствия существенной автокорреляции в остаточной последовательности, может осуществляться по ряду критериев, наиболее распространенным из которых является d-критерий Дарбина-Уотсона. Расчетное значение этого критерия определяется по формуле:
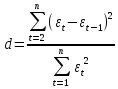
Точность модели характеризуется величиной отклонения выхода модели от реального значения моделируемой переменной (экономического показателя). Для показателя, представленного временным рядом, точность определяется как разность между значением фактического уровня временного ряда и его оценкой, полученной расчетным путем с использованием модели, при этом в качестве статистических показателей точности применяются следующие:
-
Среднеквадратическое отклонение
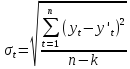 ,
где k-число
определяемых параметров (16)
,
где k-число
определяемых параметров (16)
-
Средняя относительная ошибка аппроксимации
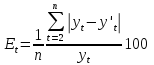 (17)
(17)
-
Коэффициент сходимости
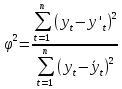 ,
где
n – количество уровней ряда; (18)
,
где
n – количество уровней ряда; (18)
y′
– оценка уровней ряда по модели; – среднеарифметическое значение уровней
ряда.
– среднеарифметическое значение уровней
ряда.
-
Коэффициент детерминации
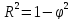
Условия точности моделей:
σt и Et должны быть минимальными;
ϕ2 и R2 должны стремиться соответственно к 0 и 1.
На основании указанных показателей можно сделать выбор из нескольких адекватных трендовых моделей экономической динамики наиболее точной, хотя может встретиться случай, когда по некоторому показателю более точна одна модель, а по-другому – другая.