

4.3. Символьный препроцессор на основе бэктрекинга
Мы уже отмечали, что одной из основных проблем, сдерживающих эффективное применение компьютеров в различных областях науки и техники, является традиционная, исторически сложившаяся технология решения прикладных задач на ЭВМ. Дело в том, что конечный пользователь, ставящий задачу и использующий результаты ее решения, обладая профессиональными знаниями, в общем случае не имеет необходимых знаний о способах использования вычислительной техники для решения его задачи. Посредником между ним и ЭВМ выступает системный аналитик и программист и уже после построения схемы решения происходит почти полное “отчуждение” конечного пользователя от дальнейшего процесса решения задачи. Разработанный и отлаженный программный продукт может дать результаты, не удовлетворяющие пользователя. Однако, при традиционной технологии внесение изменений потребует нового привлечения программистов и аналитиков, которые в соответствии с коррективами постановки задачи должны модифицировать программу, что обычно ничуть не проще разработки новой. После разработки, отладки и оформления программной системы как изделия она поступает к пользователям, но дальнейшая работа с ней не ограничивается решением прикладных задач. Если теоретически и можно предположить существование “безошибочной” программной системы (на практике такое случается крайне редко), то предусмотреть все последующие изменения в постановке задач и требований к их решению в большинстве случаев просто невозможно. Естественное развитие предметной области, условий в которых решается задача, неизбежно приводят к необходимости расширения функциональных возможностей реализованной программы. Таким образом, сопровождение программной системы, связанное с исправлением ошибок и модификацией, выполняется на протяжении всего ее жизненного цикла. Процесс сопровождения в традиционной технологии требует, по крайней мере, такого же количества ресурсов, как и разработка программы. В частности, удваивается число специалистов по программному обеспечению, обслуживающих потребности пользователей. В условиях неуклонного расширения сферы применения ЭВМ потребности в таких специалистах не могут быть реально удовлетворены. Сказанное выше и обуславливает необходимость изменения традиционной технологии использования ЭВМ.
Преодолеть рассмотренную выше кризисную ситуацию можно лишь привлечением конечного пользователя к непосредственному процессу решению его задач на ЭВМ, сопровождению программной системы, разработке прикладных программ. Это можно будет сделать только в том случае, когда между пользователем и ЭВМ будет существовать интеллектуальный интерфейс, позволяющий ставить задачи и получать результаты в терминах его предметной области, без знаний технологии программирования, операционных систем и иных программистских тонкостей. Каким же должен быть этот интерфейс?
Прямое использование пакетов прикладных программ (процедур с параметрами) требует от пользователя знаний программиста. С помощью чисто диалоговых средств достаточно сложную систему описать невозможно. Да и сам диалог предполагает наличие контролируемых ответов. Итак, необходим предметно ориентированный язык, чтобы пользователь описывал свою задачу и получал результаты ее решения ее в терминах области его деятельности. Создание спектра таких языков невозможно без средств автоматизации проектирования - систем построения трансляторов (СПТ). Одним из первых СПТ был генератор компиляторов XPL [12]. Автоматизацию построения трансляторов в ОС UNIX поддерживает программа LEX - генератор сканеров (лексических анализаторов) и программа YACC (Yet Another Compiler Compiler), предназначенная для построения синтаксических анализаторов контекстно-свободных языков.
Этим же целям служит и символьный препроцессор (СП) - программная система, разработанная и реализованная в Куйбышевском авиационном институте автором пособия в 1988 году сначала для PDP-11, а в 1990 году перенесенная и на IBM PC. Эта система использовалась для создания языков описания электротехнических схем, бортовых программно-аппаратных комплексов (СИМПАК), коммутируемых сетей с целью их имитации, исследования, оптимизации и отладки алгоритмов[9]. Упрощенный вариант этой системы до сих пор применяется в учебном процессе [8]. Данный параграф и посвящен описанию этой системы, одним из основных достоинств которой является компактность основных алгоритмов в силу их рекурсивной природы, отражающей рекурсивность КС-грамматик.
Общая схема и фазы функционирования символьного процессора показаны на рис. 4.5.
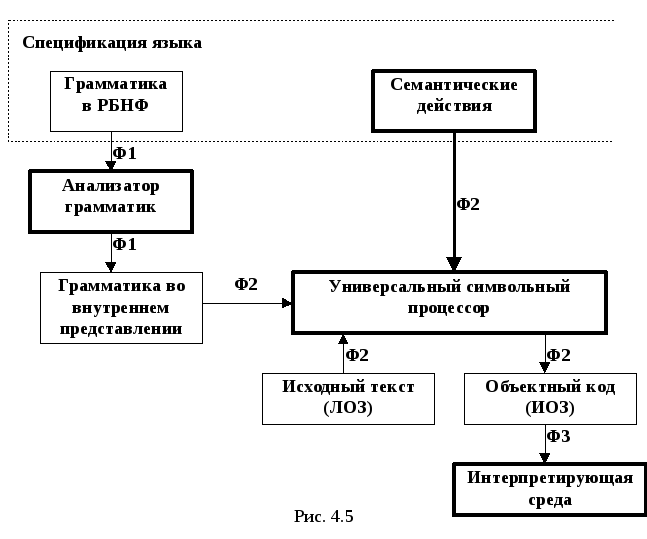
Н
 а
рисунке обрамления - обозначают
файлы с данными, а - программные
компоненты. Указывается также фаза
работы СП,
на которой используется та или иная
связь. Здесь:
а
рисунке обрамления - обозначают
файлы с данными, а - программные
компоненты. Указывается также фаза
работы СП,
на которой используется та или иная
связь. Здесь:
Ф1 - фаза анализа и перевода грамматики во внутреннее представление.
Ф2 - фаза трансляции исходного текста (лингвистического описания задачи (ЛОЗ)) в объектный код (информационный образ задачи (ИОЗ)).
Ф3 - фаза интерпретации (выполнения) объектного кода.
Принципы работы этих фаз поясняются в последующих разделах.