

5.2.3. Проблемы построения грамматик предшествования
Из определения грамматик простого предшествования следует, что далеко не всякая КС–грамматика является грамматикой простого предшествования. В частности, в произвольной КС–грамматике может не выполняться условие однозначной обратимости. Наличие нескольких одинаковых правых частей в продукциях грамматики приведет к неоднозначности при свертке основ, а следовательно и алгоритма разбора по такой грамматике станет недетерминированным. Но это не фатальная проблема, так как нетрудно показать, что каждый КС–язык порождается по крайней мере одной обратимой КС–грамматикой.
Действительно, если в грамматике имеются правила вида: A и B , то одно из них, например B можно удалить, а все правила вида C B заменить парой правил: C и C B. Причем, последнее правило сохраняется только в том случае, если у нетерминала B есть и другая альтернатива, кроме B .
Пример 5.14. Рассмотрим фрагмент правил грамматики, определяющий синтаксис заголовка процедуры:
Заголовок проц. PROCEDURE имя проц. ( список параметров );
имя проц. идентификатор
список параметров идентификатор
идентификатор , список параметров
Устраним правило имя проц. идентификатор и в результате получим обратимую грамматику:
Заголовок проц. PROCEDURE идентификатор ( список параметров );
список параметров идентификатор
идентификатор , список параметров
Вторая проблема более существенна. Очень часто между двумя символами грамматики имеет место более одного отношения предшествования. Единственное, что мы можем тогда сделать, – это обработать и изменить грамматику так, чтобы обойти конфликт.
Обычно, наличие
двух отношений между символами грамматики
– это следствие рекурсии, в частности
левосторонней. Предположим, что в
грамматике существует некоторое правило
U
U...
. Если есть
другое правило вида V
...XU...
, то
одновременно X![]() U
и в силу
того, что U
L(U) ,
– X
будет
U.
Иногда можно избавиться от такого
конфликта, заменив правило
U
и в силу
того, что U
L(U) ,
– X
будет
U.
Иногда можно избавиться от такого
конфликта, заменив правило
V ... XU ...
парой правил:
V ... XU1 ... , U1 U ,
где U1
новый нетерминал. При этом получим, что
X![]() U1
и X
U. Такой
прием называют стратификацией
или разделением.
Заметим, что аналогично может решаться
и конфликт с отношениями
и
U1
и X
U. Такой
прием называют стратификацией
или разделением.
Заметим, что аналогично может решаться
и конфликт с отношениями
и
![]() при правосторонней
рекурсии.
при правосторонней
рекурсии.
Пример 5.15. Чтобы показать, как делается стратификация, воспользуемся привычной уже грамматикой арифметических выражений:
E ETETTT
T TMTMM
M (E)i
Из первой группы
правил следует, что ‘’
и ‘’![]() T,
а так как T
леворекурсивен,
получаем также, что ‘’
и ‘’
T.
Аналогичная проблема возникает и с
символами
‘(’
и ‘E’.
Без ущерба
для структуры цепочек языка изменим
заданную грамматику на следующую:
T,
а так как T
леворекурсивен,
получаем также, что ‘’
и ‘’
T.
Аналогичная проблема возникает и с
символами
‘(’
и ‘E’.
Без ущерба
для структуры цепочек языка изменим
заданную грамматику на следующую:
E ET1ET1T1T1
Т1 T
T TMTMM
M (E1)i
E1 E .
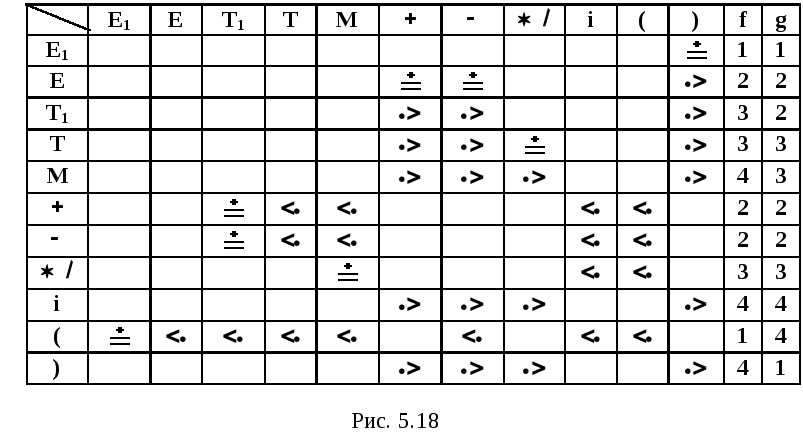
Начальным символом грамматики при этом станет E1, множество самых левых и самых правых символов для нетерминалов полученной грамматики представлено на рис. 5.17, а матрица и функции предшествования на рис. 5.18.

Этот пример может создать впечатления, что при стратификации изменения не столь значительны. Однако, если в грамматике 100 правил и более 100 символов (а так оно и есть в языках типа Паскаль), то даже искушенный специалист затратит немало времени на то, чтобы переделать такую грамматику в грамматику простого предшествования. В результате может измениться вся структура языка, не говоря о том, что грамматика станет неудобочитаемой. Кроме того, стратификация не всегда спасает, так как она часто приводит к конфликтам иного рода. Если одновременно для двух символов грамматики x и y выполняются отношения x y и x y, то лучший выход – применить другую технику.
Первопричина проблем метода простого предшествования состоит в том, что решения принимаются с учетом весьма ограниченного контекста возможной основы. В сущности, в каждом случае во внимание принимается только два соседних символа (не случайно грамматика простого предшествования называется грамматикой (1,1) предшествования). Если же рассматривать и другие символы или большее количество символов, то можно надеяться, что конфликтных ситуаций станет меньше.
Проиллюстрируем
это на примере сентенциальной формы
ETF
исходной
грамматики из примера 5.15. Поскольку
отношения
T
и ![]() T
противоречивы, мы не можем всего по двум
символам,
и
T
, сделать вывод о том является ли T
головой
основы или
и
T
одновременно входят в основу и нужно
выполнить сложение. Если же известно
два символа
и
или же три символа T,
то интуиция подскажет, что складывать
нельзя и следовательно символ
в основу не входит.
T
противоречивы, мы не можем всего по двум
символам,
и
T
, сделать вывод о том является ли T
головой
основы или
и
T
одновременно входят в основу и нужно
выполнить сложение. Если же известно
два символа
и
или же три символа T,
то интуиция подскажет, что складывать
нельзя и следовательно символ
в основу не входит.