

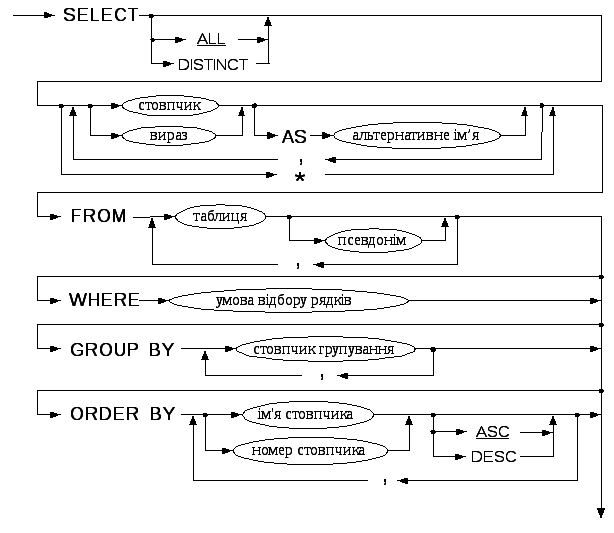
3.1. Групування записів
Інколи буває потрібно отримати агрегатні значення не для всього результуючого набору даних, а оремо для кожної із груп, які входять у цей результуючий набір.
Кожна група рядків характеризується однаковим значенням деякого стовпчика.
Приклад 12. Вивести загальну кількість відпущеного товару для кожного із видів товару.
Для розв’язку необхідно згрупувати відпуски товарів по назві товарів і обчислити суму кількостей відпуску для кожної групи. Для групування в операторі SELECT після секції WHERE додається секція GROUP BY. Якщо є секція ORDER BY, то секція GROUP BY записується після секції WHERE, але перед секцією ORDER BY.

Якщо є секція GROUP BY, то обов’язково потрібно, щоб один із стовпчиків результуючого набору даних представлявся агрегатною функцією, тобто щоб в секцію SELECT входив вираз, який містить агрегатну функцію. Групування відбувається по звичайним (неагрегатним) полям, тому для групування потрібно, щоб у секцію SELECT входило по крайній мірі одне неагрегатне поле. Групування буде відбуватися за однаковими значеннями у цьому неагрегатному стовпчику. Всі неагрегатні поля секції SELECT повинні бути вказані в секції GROUP BY.
SELECT V.Tovar, SUM (V.Kilkist) AS Vidp
FROM Vidpusk V
GROUP BY V.Tovar
|
Vidpusk |
|
Результат |
|||
|
Tovar |
... |
Kilkist |
→ |
Tovar |
Vidp |
|
шило |
... |
1 |
|
шило |
4 |
|
шило |
... |
3 |
|
мило |
2 |
|
мило |
... |
2 |
|
цукор |
3 |
|
цукор |
... |
1 |
|
|
|
|
цукор |
... |
2 |
|
|
|
Приклад 2. Вивести загальну вартість кожного відпущеного товару.
SELECT V.Tovar, SUM (V.Kilkist * T.Cina) AS Vart
FROM Vidpusk V, Tovary T
GROUP BY V.Tovar
Правила виконання SQL-запиту на вибірку із врахуванням секції GROUP BY:
-
Сформувати декартовий добуток таблиць, вказаних в секції FROM. Якщо в секції FROM вказана одна таблиця, то декартовим добутком буде вона сама.
-
Якщо є секція WHERE, то умову вказану в цій секції слід застосувати до кожного рядка таблиці, утвореної в результаті декартового добутку, і залишити лише ті рядки, для яких результат умови має значення TRUE. Рядки, для яких умова має значення NULL або FALSE відкидаються.
-
Якщо є секція GROUP BY, то потрібно розділити рядки, які залишились в результуючій таблиці на групи так, щоб рядки в кожній групі мали однакові значення у всіх стовпчиках групування одночасно.
Стовпчик групування – це той стовпчик, який визначає групу рядків. В межах групи всі рядки у стовпчику групування мають одне і те саме значення.

-
Для кожного рядка, що залишився, або для кожної групи рядків потрібно обчислити значення кожного елемента зі списку полів секції SELECT і утворити один рядок таблиці результатів запиту, при цьому при будь-якому звертанні до стовпчика береться значення стовпчика для біжучого рядка або групи рядків. Якщо є секція GROUP BY, то в якості аргументу агрегатної функції використовується значення стовпчика із всіх рядків, які входять у групу. Якщо ж секції GROUP BY немає, то використовується значення стовпчика із усіх рядків таблиці результату запиту.
-
Якщо в секції SELECT є слово DISTINCT, то потрібно вилучити із таблиці результатів запиту всі рядки дублікати.
-
Якщо є секція ORDER BY, то потрібно відсортувати результати запиту.
SQL дозволяє групувати результати запиту на основі кількох стовпчиків. Наприклад, потрібно згрупувати замовлення по працівниках та клієнтах.
Задано таблицю Zamovlennia
|
Zamovlennia |
|||
|
Pracivnyk |
Klient |
Kilkist |
... |
|
… |
… |
… |
… |
Приклад 13. Обчислити загальну кількість замовленого товару для кожного клієнта і для кожного працівника.
SELECT Pracivnyk, Klient, SUM (Kilkist)
FROM Zamovlennia
GROUP BY Pracivnyk, Klient
Є дуже велике обмеження в стандарті SQL: навіть при групуванні по двом стовпчикам стандарт SQLзабезпечує лише один рівень групування.
|
Pracivnyk |
Klient |
SUM (Kilkist) |
|
|
|
|
Даний запит генерує лише підсумковий рядок для кожної пари працівник-клієнт. В стандарті SQL не можна створити групи і підгрупи з двома або більшою кількістю рівнів підсумкових результатів. Найкраще, що можна зробити в стандарті SQL – це відсортувати дані так, щоб рядки в таблиці результатів запиту розміщувалися в потрібному порядку.
Для більшості СУБД при використанні секції GROUP BY сортування виконується автоматично, але цей автоматичний порядок сортування можна змінити за допомогою секції ORDER BY.
Приклад 14. Підрахувати загальну кількість замовленого товару по кожному клієнту для кожного працівника і відсортувати результати запиту, в першу чергу, по клієнтам, а вже потім по працівникам.
а) SELECT Pracivnyk, Klient, SUM (Kilkist)
FROM Zamovlennia
GROUP BY Pracivnyk, Klient
ORDER BY Klient, Pracivnyk
б) ) SELECT Klient, Pracivnyk, SUM (Kilkist)
FROM Zamovlennia
GROUP BY Klient, Pracivnyk
Запит б) в стандарті SQL впорядковує результати спочатку по клієнтам, а потім по працівникам. Саме тому в стандарті SQL секція ORDER BY в цьому випадку необов’язкова.
Якщо ж СУБД реалізує впорядкування при групуванні інакше ніж це описано в стандарті SQL, то секція ORDER BY повинна бути обов’язково.
За допомогою одного SQL-запиту в стандарті SQL неможливо отримати як детальні, так і проміжні підсумкові результати. Для того, щоб отримати детальні результати з підсумками по групам потрібно написати програму, яка обчислює ці проміжні підсумкові результати.
Стовпчики групування повинні бути фізичними стовпчиками таблиць вказаних у секції FROM. Не можна групувати рядки на основі обчислювальних стовпчиків. Крім того, є обмеження на список полів SELECT: всі елементи цього списку повинні мати одне й те саме значення для кожної групи рядків. А це означає, що елементом списку полів SELECT може бути: 1) константа; 2) агрегатна функція; 3) стовпчик групування; 4) вираз, який складається із вищевказаних елементів.
На практиці у список полів SELECT запиту з групуванням завжди входить стовпчик групування і агрегатна функція.
Якщо секція SELECT не містить агрегатної функції, то цей запит можна зробити простішим за допомогою директиви DISTINCT без використання секції GROUP BY.
Якщо ж в секцію SELECT не включати стовпчик групування, то не можна буде визначити, до якої саме групи належить кожний рядок таблиці результатів запиту.
Коли в стовпчику групування містяться значення NULL, то виникають додаткові ускладнення: якщо значення стовпчика невідоме, то до якої саме групи його слід віднести. В секції WHERE при порівнянні двох значень NULL результат буде NULL, а не TRUE, тобто два значення NULL у секції WHERE не вважаються однаковими. Якщо таке правило застосувати у секції GROUP BY, то це приведе до того, що кожний рядок із значенням NULL в стовпчику групування буде занесений в окрему групу, яка складається із одного єдиного цього рядка. Тому в стандарті SQL визначається, що два значення NULL в секції GROUP BY співпадають.
(NULL = NULL) → TRUE
Тобто якщо два рядки мають значення NULL в однакових стовпчиках групування та співпадаючі значення у всіх інших стовпчиках групування, то вони заносяться в одну й ту ж групу.
Приклад 15.
|
People |
||
|
Name |
Hair |
Eyes |
|
Оксана Віра Надя Ігор Галя Іра Євгенія Марія Юра Марина Світлана Люба |
коричневе NULL NULL NULL NULL коричневе коричневе коричневе коричневе коричневе біле біле |
сині сині сині NULL NULL NULL NULL NULL NULL карі сині сині |
SELECT Hair, Eyes, COUNT (*)
FROM People
GROUP BY Hair, Eyes
|
Hair |
Eyes |
COUNT (*) |
|
коричневе NULL NULL коричневе коричневе біле |
сині сині NULL NULL карі сині |
1 2 2 4 1 2 |