

Лабораторная работа №3 Характеристики рассеяния данных
Одна из причин проведения статистического анализа заключается в необходимости учитывать влияние на исследуемый экономический показатель случайных факторов (возмущений), которые приводят к разбросу (рассеянию) данных. Решение задач, в которых присутствует разброс данных, связано с риском, поскольку даже при использовании всей доступной информации нельзя точно предугадать, что же произойдет в будущем. Для адекватной работы в таких ситуациях целесообразно понимать природу риска и уметь определять степень рассеяния набора данных. Существуют три числовые характеристики, описывающие меру рассеяния: стандартное отклонение, размах и коэффициент вариации (изменчивости). В отличие от типических показателей (среднее, медиана, мода), характеризующих центр, характеристики рассеяния показывают, насколько близко к этому центру располагаются отдельные значения набора данных.
Стандартное отклонение: самая распространенная характеристика
Стандартное отклонение (среднее квадратическое отклонение) является мерой случайных отклонений значений данных от среднего.
Если все величины в наборе данных одинаковы, например
5,5; 5,5; 5,5; 5,5; 5,5; 5,5,
то среднее будет
иметь значение
![]() ,
а стандартное отклонение S=0.
Это указывает на отсутствие разброса
данных.
,
а стандартное отклонение S=0.
Это указывает на отсутствие разброса
данных.
В реальной жизни большинство данных характеризуется рассеянием, т.е. отдельные значения располагаются на некотором расстоянии от среднего. Например, значениями ставки доходности акций (в %) четырех компаний, выбранных случайным образом, являются:
43,0; 17,7; 8,7; –47,4
Средняя ставка
доходности акций в этом случае также
равна
![]() ,
однако отдельные значения данных
существенно отличаются от среднего.
Так, например, первая ставка превышает
среднюю ставку на 37,5% (отклонение от
среднего равно
,
однако отдельные значения данных
существенно отличаются от среднего.
Так, например, первая ставка превышает
среднюю ставку на 37,5% (отклонение от
среднего равно
![]() ),
а последняя ставка оказывается ниже
среднего на 52,9%, поскольку величина
отклонения от среднего отрицательна
(
),
а последняя ставка оказывается ниже
среднего на 52,9%, поскольку величина
отклонения от среднего отрицательна
(![]() ).
).
Использовать стандартное отклонение как обобщающую характеристику рассеяния, просто усреднив отклонения данных нельзя, потому что часть отклонений окажется положительной, а другая часть – отрицательной, и, вследствие этого, результат усреднения может оказаться равным нулю. Чтобы избавиться от отрицательного знака, применяют стандартный прием: сначала вычисляют дисперсию как сумму квадратов отклонений, поделенную на (n–1), а затем из полученного значения извлекают квадратный корень. Формула для вычисления стандартного отклонения выглядит следующим образом:

Замечание 1. Дисперсия не несет никакой дополнительной информации по сравнению со стандартным отклонением, однако ее сложнее интерпретировать, т. к. она выражается в «единицах в квадрате» (например, в «долларах в квадрате»), в то время как стандартное отклонение выражено в привычных для нас единицах (например, в долларах).
Замечание 2. Приведенная выше формула предназначена для расчета стандартного отклонения по выборке и более точно называется выборочное стандартное отклонение. При расчете стандартного отклонения генеральной совокупности (обозначается символом ) производят деление на n. Величина выборочного стандартного отклонения получается несколько больше (т. к. делят на n–1), что обеспечивает поправку на случайность самой выборки.
В случае, когда набор данных имеет нормальное распределение, стандартное отклонение приобретает особый смысл. На рисунке, представленном ниже, по обе стороны от среднего сделаны отметки на расстоянии одного, двух и трех стандартных отклонений соответственно.
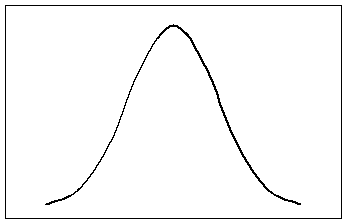








66,7%
95%

99,7%
И з
рисунка видно, что примерно 66,7% (две
трети) всех значений находятся в пределах
одного стандартного отклонения по обе
стороны от среднего значения, 95% значений
окажутся в пределах двух стандартных
отклонений от среднего и почти все
данные (99,7%) будут находиться в пределах
трех стандартных отклонений от среднего
значения. Это свойство стандартного
отклонения для нормально распределенных
данных называется «правилом двух
третей». В некоторых ситуациях, например
при анализе контроля качества продукции,
часто устанавливают такие пределы,
чтобы в качестве заслуживающей внимание
проблемы рассматривались те результаты
наблюдений (0,3%), которые отстоят от
среднего на расстоянии большем, чем три
стандартных отклонения. К сожалению,
если данные не подчиняются нормальному
распределению, то описанное выше правило
применять нельзя. В настоящее время
существует ограничение, называемое
правилом Чебышева, которое можно
применять к ассиметричным (скошенным)
распределениям.
з
рисунка видно, что примерно 66,7% (две
трети) всех значений находятся в пределах
одного стандартного отклонения по обе
стороны от среднего значения, 95% значений
окажутся в пределах двух стандартных
отклонений от среднего и почти все
данные (99,7%) будут находиться в пределах
трех стандартных отклонений от среднего
значения. Это свойство стандартного
отклонения для нормально распределенных
данных называется «правилом двух
третей». В некоторых ситуациях, например
при анализе контроля качества продукции,
часто устанавливают такие пределы,
чтобы в качестве заслуживающей внимание
проблемы рассматривались те результаты
наблюдений (0,3%), которые отстоят от
среднего на расстоянии большем, чем три
стандартных отклонения. К сожалению,
если данные не подчиняются нормальному
распределению, то описанное выше правило
применять нельзя. В настоящее время
существует ограничение, называемое
правилом Чебышева, которое можно
применять к ассиметричным (скошенным)
распределениям.
|
Задание 1. |
Вычислить и проанализировать стандартное отклонение дневной прибыли на фондовой бирже. |
Размеры прибыли на фондовой бирже меняются каждый день. В таблице 1 представлена динамика изменений дневной прибыли на бирже, зафиксированной в рабочие дни за период от 31 июля по 9 октября 1987 года.
Таблица 1. Динамика изменения дневной прибыли на бирже
|
Дата |
Дневная прибыль |
Дата |
Дневная прибыль |
Дата |
Дневная прибыль |
|
1 |
-0,006 |
17 |
0,009 |
33 |
0,012 |
|
2 |
-0,004 |
18 |
-0,015 |
34 |
-0,004 |
|
3 |
0,008 |
19 |
-0,006 |
35 |
0,002 |
|
4 |
0,011 |
20 |
0,002 |
36 |
-0,008 |
|
5 |
-0,001 |
21 |
0,011 |
37 |
-0,010 |
|
6 |
0,017 |
22 |
0,013 |
38 |
-0,013 |
|
7 |
0,017 |
23 |
0,002 |
39 |
0,009 |
|
8 |
-0,004 |
24 |
-0,018 |
40 |
-0,020 |
|
9 |
0,008 |
25 |
-0,014 |
41 |
-0,003 |
|
10 |
-0,002 |
26 |
-0,001 |
42 |
-0,001 |
|
11 |
0,006 |
27 |
-0,001 |
43 |
0,017 |
|
12 |
-0,017 |
28 |
-0,013 |
44 |
0,001 |
|
13 |
0,004 |
29 |
0,030 |
45 |
-0,000 |
|
14 |
0,015 |
30 |
0,007 |
46 |
-0,035 |
|
15 |
0,001 |
31 |
-0,007 |
47 |
0,001 |
|
16 |
-0,005 |
32 |
0,001 |
48 |
-0,014 |
-
Откройте программу Excel. Щелкните на кнопке Сохранить на Панели быстрого доступа. В появившемся диалоговом окне откройте папку Статистика ххх и задайте имя файлу Характеристики рассеяния.xlsх. Зашифруйте файл, задав пароль.
-
На Листе1 в ячейке A1 задайте метку Дневная прибыль, а в диапазон A2:A49 введите данные из Таблицы 1.
-
В ячейку D1 введите метку Среднее. В ячейке D2 вычислите среднее, используя статистическую функцию СРЗНАЧ. Уменьшите разрядность полученного результата до четвертого знака после запятой.
-
В ячейку D4 введите метку Стандартное отклонение. В ячейке D5 вычислите стандартное отклонение, используя статистическую функцию СТАНДОТКЛОН. Уменьшите разрядность полученного результата до четвертого знака после запятой.